 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign2Ground: Weakly Supervised Phrase Grounding Guided by Image-Caption Alignment
Paper and Code
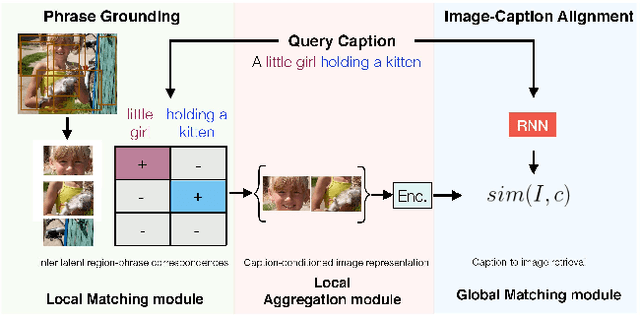
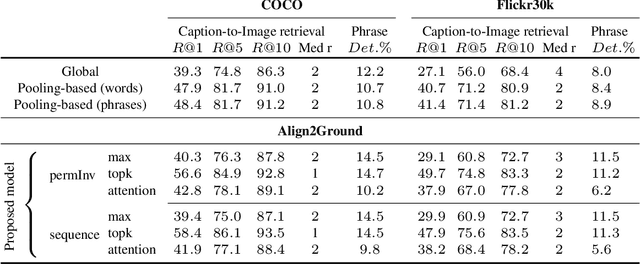

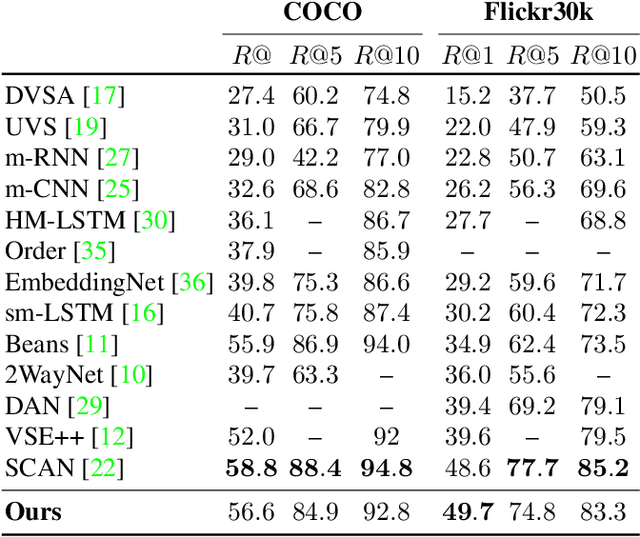
We address the problem of grounding free-form textual phrases by using weak supervision from image-caption pairs. We propose a novel end-to-end model that uses caption-to-image retrieval as a `downstream' task to guide the process of phrase localization. Our method, as a first step, infers the latent correspondences between regions-of-interest (RoIs) and phrases in the caption and creates a discriminative image representation using these matched RoIs. In a subsequent step, this (learned) representation is aligned with the caption. Our key contribution lies in building this `caption-conditioned' image encoding which tightly couples both the tasks and allows the weak supervision to effectively guide visual grounding. We provide an extensive empirical and qualitative analysis to investigate the different components of our proposed model and compare it with competitive baselines. For phrase localization, we report an improvement of 4.9% (absolute) over the prior state-of-the-art on the VisualGenome dataset. We also report results that are at par with the state-of-the-art on the downstream caption-to-image retrieval task on COCO and Flickr30k datasets.