 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Click to Move: Controlling Video Generation with Sparse Motion
Aug 19, 2021
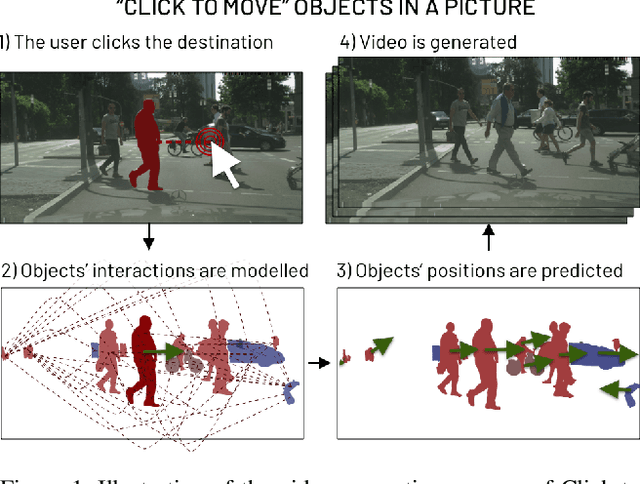
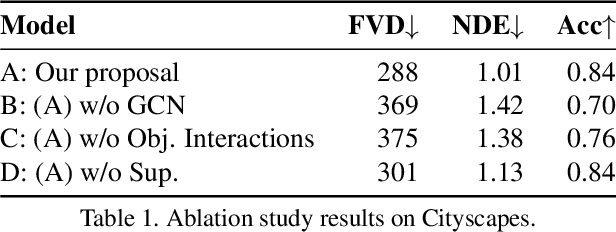
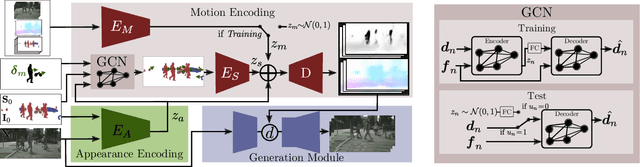
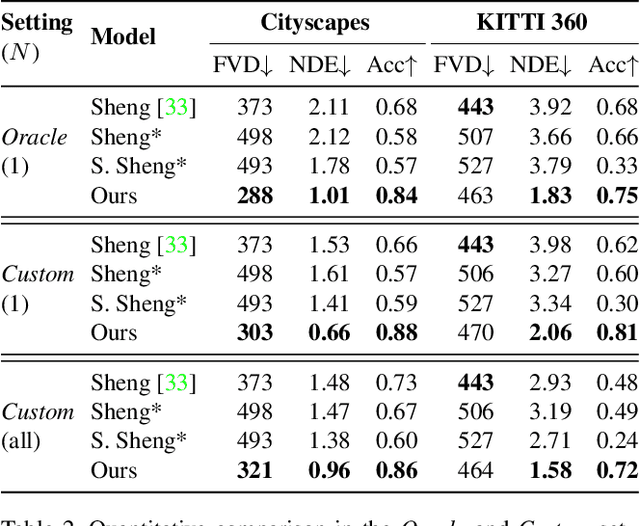
This paper introduces Click to Move (C2M), a novel framework for video generation where the user can control the motion of the synthesized video through mouse clicks specifying simple object trajectories of the key objects in the scene. Our model receives as input an initial frame, its corresponding segmentation map and the sparse motion vectors encoding the input provided by the user. It outputs a plausible video sequence starting from the given frame and with a motion that is consistent with user input. Notably, our proposed deep architecture incorporates a Graph Convolution Network (GCN) modelling the movements of all the objects in the scene in a holistic manner and effectively combining the sparse user motion information and image features. Experimental results show that C2M outperforms existing methods on two publicly available datasets, thus demonstrating the effectiveness of our GCN framework at modelling object interactions. The source code is publicly available at https://github.com/PierfrancescoArdino/C2M.
Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild
Jul 30, 2020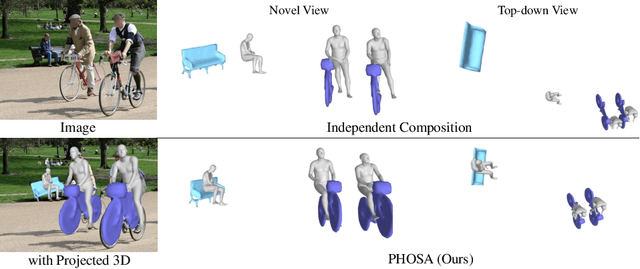
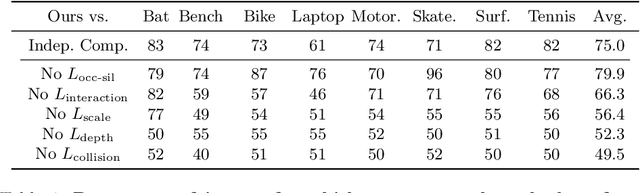
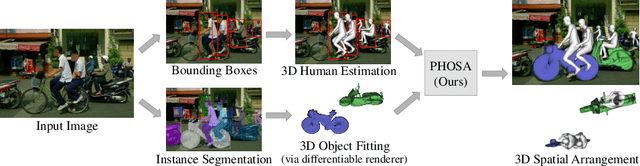
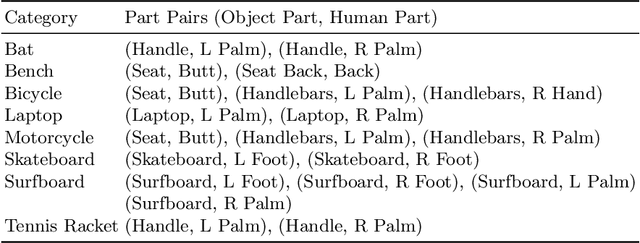
We present a method that infers spatial arrangements and shapes of humans and objects in a globally consistent 3D scene, all from a single image in-the-wild captured in an uncontrolled environment. Notably, our method runs on datasets without any scene- or object-level 3D supervision. Our key insight is that considering humans and objects jointly gives rise to "3D common sense" constraints that can be used to resolve ambiguity. In particular, we introduce a scale loss that learns the distribution of object size from data; an occlusion-aware silhouette re-projection loss to optimize object pose; and a human-object interaction loss to capture the spatial layout of objects with which humans interact. We empirically validate that our constraints dramatically reduce the space of likely 3D spatial configurations. We demonstrate our approach on challenging, in-the-wild images of humans interacting with large objects (such as bicycles, motorcycles, and surfboards) and handheld objects (such as laptops, tennis rackets, and skateboards). We quantify the ability of our approach to recover human-object arrangements and outline remaining challenges in this relatively domain. The project webpage can be found at https://jasonyzhang.com/phosa.
Single-Image Lens Flare Removal
Nov 26, 2020
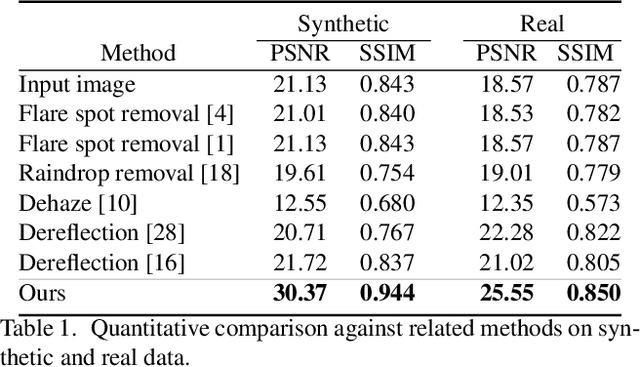
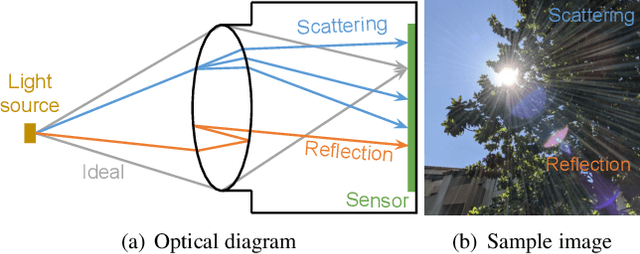
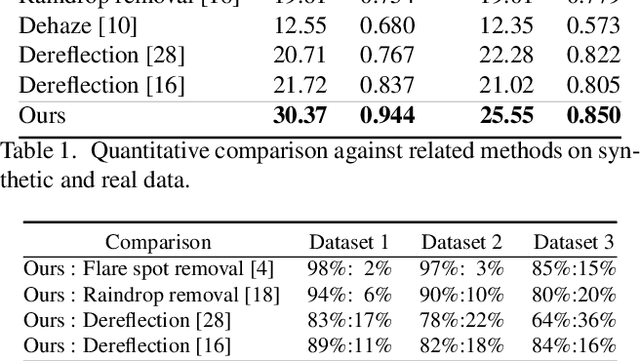
Lens flare is a common artifact in photographs occurring when the camera is pointed at a strong light source. It is caused by either multiple reflections within the lens or scattering due to scratches or dust on the lens, and may appear in a wide variety of patterns: halos, streaks, color bleeding, haze, etc. The diversity in its appearance makes flare removal extremely challenging. Existing software methods make strong assumptions about the artifacts' geometry or brightness, and thus only handle a small subset of flares. We take a principled approach to explicitly model the optical causes of flare, which leads to a novel semi-synthetic pipeline for generating flare-corrupted images from both empirical and wave-optics-simulated lens flares. Using the semi-synthetic data generated by this pipeline, we build a neural network to remove lens flare. Experiments show that our model generalizes well to real lens flares captured by different devices, and outperforms start-of-the-art methods by 3dB in PSNR.
MetaPose: Fast 3D Pose from Multiple Views without 3D Supervision
Aug 10, 2021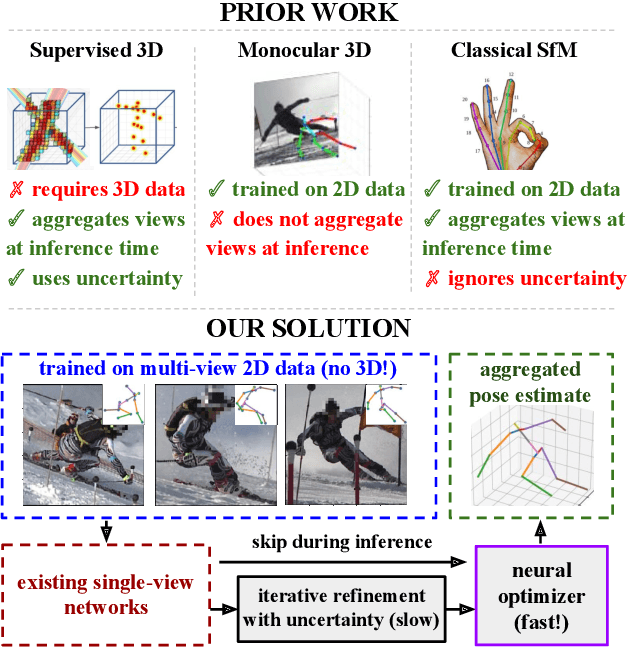
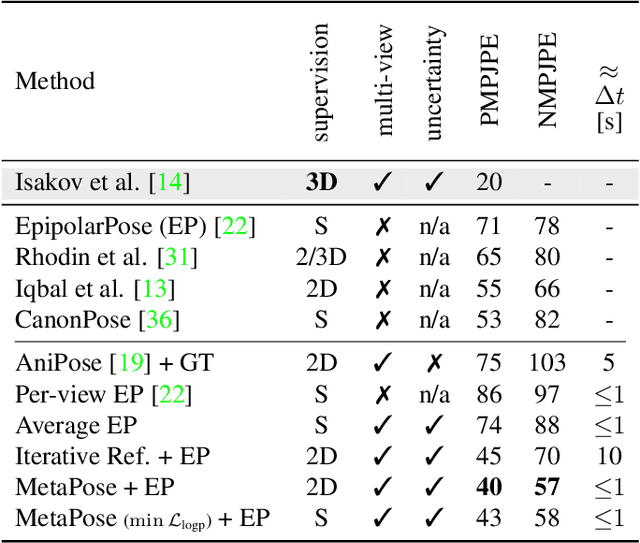
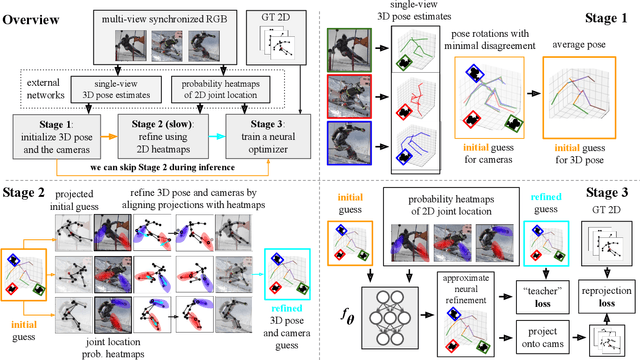
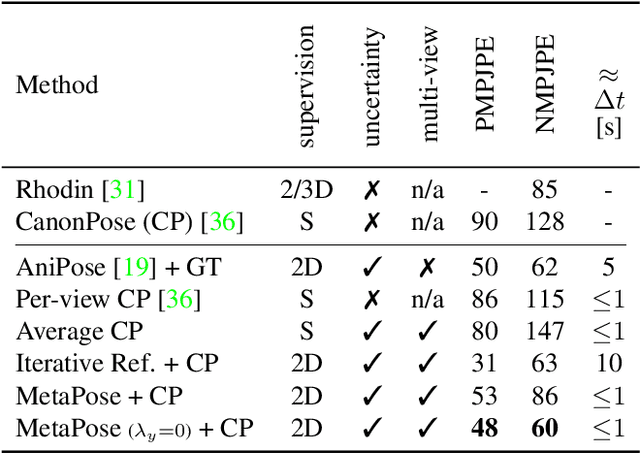
Recently, huge strides were made in monocular and multi-view pose estimation with known camera parameters, whereas pose estimation from multiple cameras with unknown positions and orientations received much less attention. In this paper, we show how to train a neural model that can perform accurate 3D pose and camera estimation, takes into account joint location uncertainty due occlusion from multiple views, and requires only 2D keypoint data for training. Our method outperforms both classical bundle adjustment and weakly-supervised monocular 3D baselines on the well-established Human3.6M dataset, as well as the more challenging in-the-wild Ski-Pose PTZ dataset with moving cameras. We provide an extensive ablation study separating the error due to the camera model, number of cameras, initialization, and image-space joint localization from the additional error introduced by our model.
Artificial Intelligence-Based Image Classification for Diagnosis of Skin Cancer: Challenges and Opportunities
Dec 05, 2019
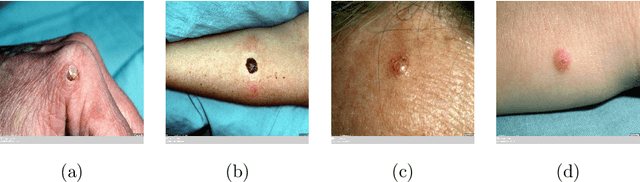
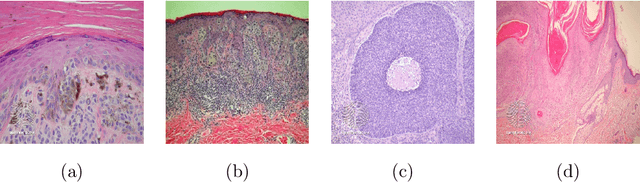
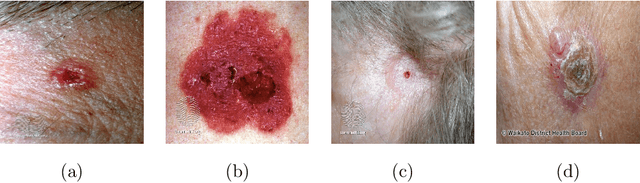
Recently, there has been great interest in developing Artificial Intelligence (AI) enabled computer-aided diagnostics solutions for the diagnosis of skin cancer. With the increasing incidence of skin cancers, low awareness among a growing population, and a lack of adequate clinical expertise and services, there is an immediate need for AI systems to assist clinicians in this domain. A large number of skin lesion datasets are available publicly, and researchers have developed AI-based image classification solutions, particularly deep learning algorithms, to distinguish malignant skin lesions from benign lesions in different image modalities such as dermoscopic, clinical, and histopathology images. Despite the various claims of AI systems achieving higher accuracy than dermatologists in the classification of different skin lesions, these AI systems are still in the very early stages of clinical application in terms of being ready to aid clinicians in the diagnosis of skin cancers. In this review, we discuss advancements in the digital image-based AI solutions for the diagnosis of skin cancer, along with some challenges and future opportunities to improve these AI systems to support dermatologists and enhance their ability to diagnose skin cancer.
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
Mar 31, 2021
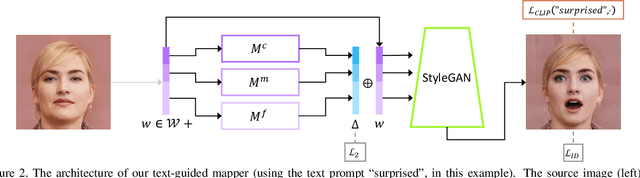


Inspired by the ability of StyleGAN to generate highly realistic images in a variety of domains, much recent work has focused on understanding how to use the latent spaces of StyleGAN to manipulate generated and real images. However, discovering semantically meaningful latent manipulations typically involves painstaking human examination of the many degrees of freedom, or an annotated collection of images for each desired manipulation. In this work, we explore leveraging the power of recently introduced Contrastive Language-Image Pre-training (CLIP) models in order to develop a text-based interface for StyleGAN image manipulation that does not require such manual effort. We first introduce an optimization scheme that utilizes a CLIP-based loss to modify an input latent vector in response to a user-provided text prompt. Next, we describe a latent mapper that infers a text-guided latent manipulation step for a given input image, allowing faster and more stable text-based manipulation. Finally, we present a method for mapping a text prompts to input-agnostic directions in StyleGAN's style space, enabling interactive text-driven image manipulation. Extensive results and comparisons demonstrate the effectiveness of our approaches.
Learning by example: fast reliability-aware seismic imaging with normalizing flows
Apr 13, 2021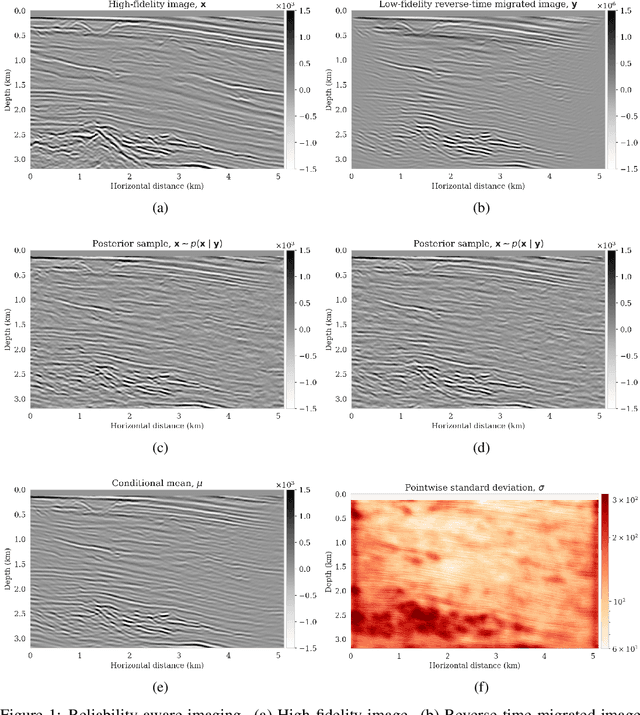
Uncertainty quantification provides quantitative measures on the reliability of candidate solutions of ill-posed inverse problems. Due to their sequential nature, Monte Carlo sampling methods require large numbers of sampling steps for accurate Bayesian inference and are often computationally infeasible for large-scale inverse problems, such as seismic imaging. Our main contribution is a data-driven variational inference approach where we train a normalizing flow (NF), a type of invertible neural net, capable of cheaply sampling the posterior distribution given previously unseen seismic data from neighboring surveys. To arrive at this result, we train the NF on pairs of low- and high-fidelity migrated images. In our numerical example, we obtain high-fidelity images from the Parihaka dataset and low-fidelity images are derived from these images through the process of demigration, followed by adding noise and migration. During inference, given shot records from a new neighboring seismic survey, we first compute the reverse-time migration image. Next, by feeding this low-fidelity migrated image to the NF we gain access to samples from the posterior distribution virtually for free. We use these samples to compute a high-fidelity image including a first assessment of the image's reliability. To our knowledge, this is the first attempt to train a conditional network on what we know from neighboring images to improve the current image and assess its reliability.
Interpreting Medical Image Classifiers by Optimization Based Counterfactual Impact Analysis
Apr 03, 2020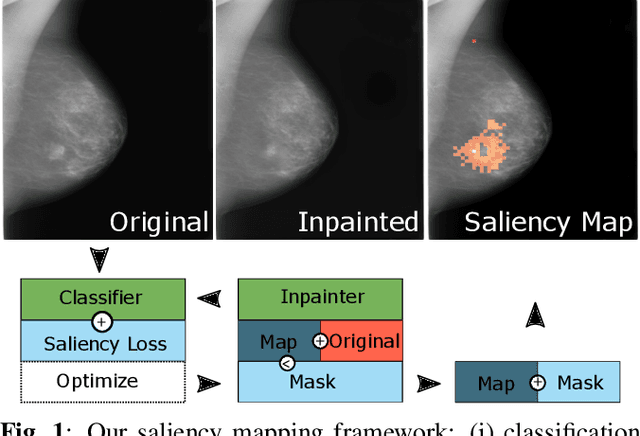
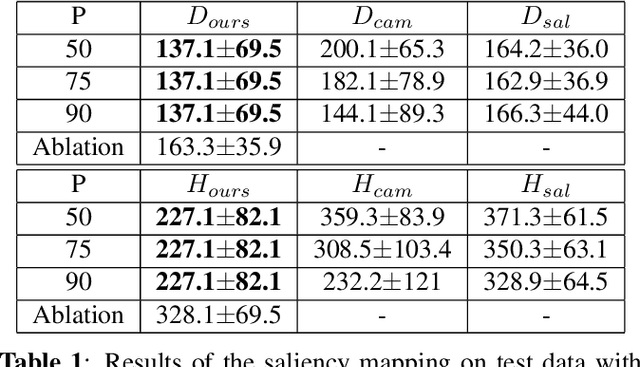
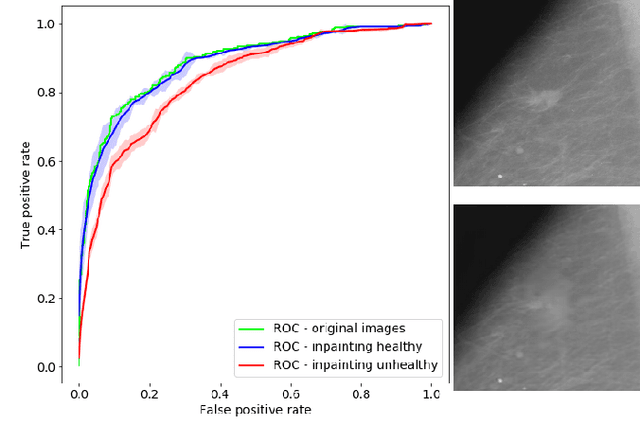
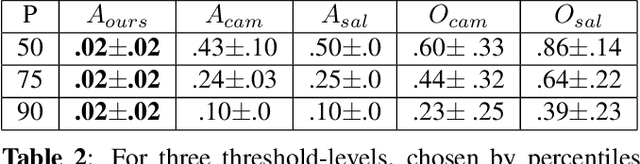
Clinical applicability of automated decision support systems depends on a robust, well-understood classification interpretation. Artificial neural networks while achieving class-leading scores fall short in this regard. Therefore, numerous approaches have been proposed that map a salient region of an image to a diagnostic classification. Utilizing heuristic methodology, like blurring and noise, they tend to produce diffuse, sometimes misleading results, hindering their general adoption. In this work we overcome these issues by presenting a model agnostic saliency mapping framework tailored to medical imaging. We replace heuristic techniques with a strong neighborhood conditioned inpainting approach, which avoids anatomically implausible artefacts. We formulate saliency attribution as a map-quality optimization task, enforcing constrained and focused attributions. Experiments on public mammography data show quantitatively and qualitatively more precise localization and clearer conveying results than existing state-of-the-art methods.
Learning from Small Samples: Transformation-Invariant SVMs with Composition and Locality at Multiple Scales
Sep 28, 2021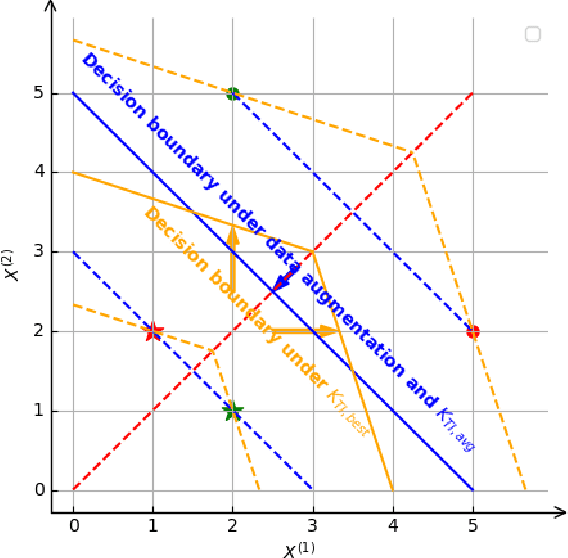
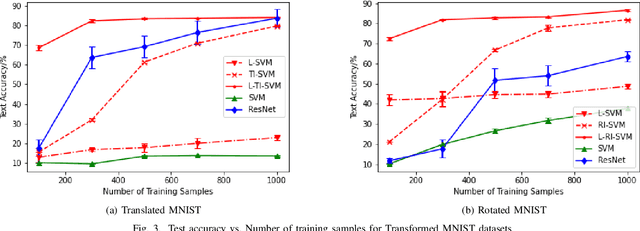

Motivated by the problem of learning when the number of training samples is small, this paper shows how to incorporate into support-vector machines (SVMs) those properties that have made convolutional neural networks (CNNs) successful. Particularly important is the ability to incorporate domain knowledge of invariances, e.g., translational invariance of images. Kernels based on the \textit{minimum} distance over a group of transformations, which corresponds to defining similarity as the \textit{best} over the possible transformations, are not generally positive definite. Perhaps it is for this reason that they have neither previously been experimentally tested for their performance nor studied theoretically. Instead, previous attempts have employed kernels based on the \textit{average} distance over a group of transformations, which are trivially positive definite, but which generally yield both poor margins as well as poor performance, as we show. We address this lacuna and show that positive definiteness indeed holds \textit{with high probability} for kernels based on the minimum distance in the small training sample set regime of interest, and that they do yield the best results in that regime. Another important property of CNNs is their ability to incorporate local features at multiple spatial scales, e.g., through max pooling. A third important property is their ability to provide the benefits of composition through the architecture of multiple layers. We show how these additional properties can also be embedded into SVMs. We verify through experiments on widely available image sets that the resulting SVMs do provide superior accuracy in comparison to well-established deep neural network (DNN) benchmarks for small sample sizes.
Zero-Shot Open Set Detection by Extending CLIP
Sep 10, 2021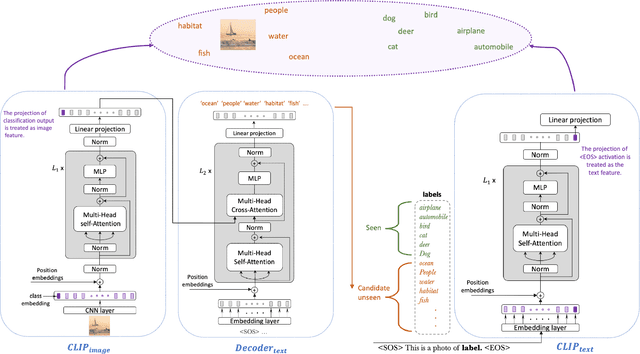
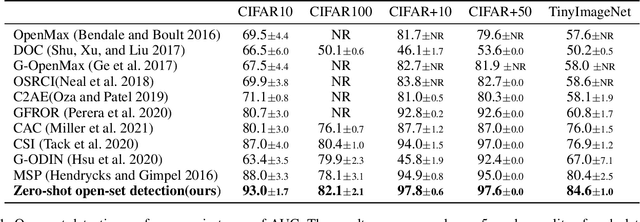
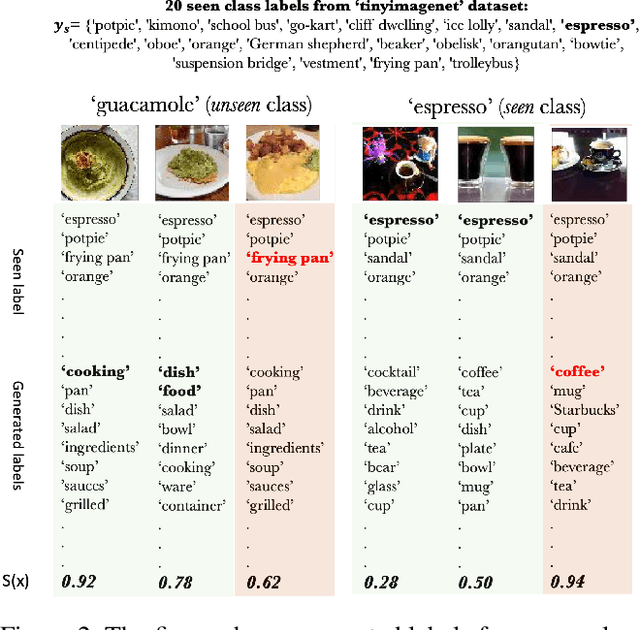
In a regular open set detection problem, samples of known classes (also called closed set classes) are used to train a special classifier. In testing, the classifier can (1) classify the test samples of known classes to their respective classes and (2) also detect samples that do not belong to any of the known classes (we say they belong to some unknown or open set classes). This paper studies the problem of zero-shot open-set detection, which still performs the same two tasks in testing but has no training except using the given known class names. This paper proposes a novel and yet simple method (called ZO-CLIP) to solve the problem. ZO-CLIP builds on top of the recent advances in zero-shot classification through multi-modal representation learning. It first extends the pre-trained multi-modal model CLIP by training a text-based image description generator on top of CLIP. In testing, it uses the extended model to generate some candidate unknown class names for each test sample and computes a confidence score based on both the known class names and candidate unknown class names for zero-shot open set detection. Experimental results on 5 benchmark datasets for open set detection confirm that ZO-CLIP outperforms the baselines by a large margin.