 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mass Segmentation in Automated 3-D Breast Ultrasound Using Dual-Path U-net
Sep 17, 2021
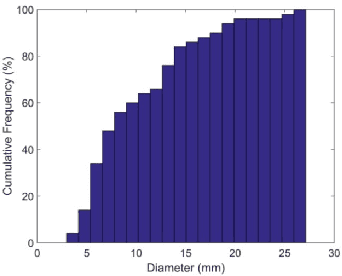

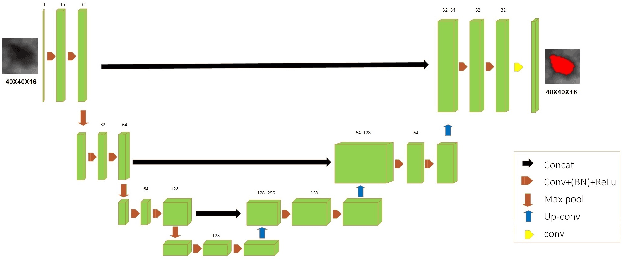
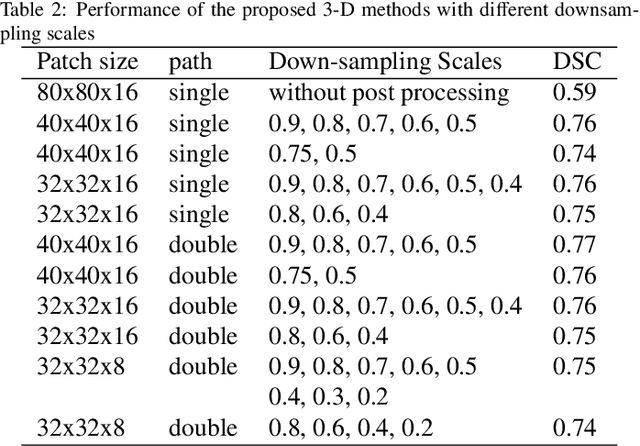
Automated 3-D breast ultrasound (ABUS) is a newfound system for breast screening that has been proposed as a supplementary modality to mammography for breast cancer detection. While ABUS has better performance in dense breasts, reading ABUS images is exhausting and time-consuming. So, a computer-aided detection system is necessary for interpretation of these images. Mass segmentation plays a vital role in the computer-aided detection systems and it affects the overall performance. Mass segmentation is a challenging task because of the large variety in size, shape, and texture of masses. Moreover, an imbalanced dataset makes segmentation harder. A novel mass segmentation approach based on deep learning is introduced in this paper. The deep network that is used in this study for image segmentation is inspired by U-net, which has been used broadly for dense segmentation in recent years. The system's performance was determined using a dataset of 50 masses including 38 malign and 12 benign lesions. The proposed segmentation method attained a mean Dice of 0.82 which outperformed a two-stage supervised edge-based method with a mean Dice of 0.74 and an adaptive region growing method with a mean Dice of 0.65.
Decision Tree Learning with Spatial Modal Logics
Sep 17, 2021
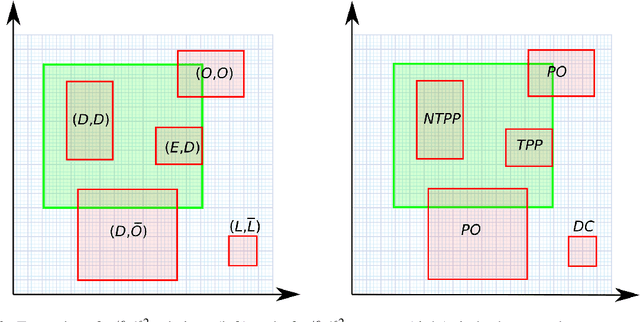
Symbolic learning represents the most straightforward approach to interpretable modeling, but its applications have been hampered by a single structural design choice: the adoption of propositional logic as the underlying language. Recently, more-than-propositional symbolic learning methods have started to appear, in particular for time-dependent data. These methods exploit the expressive power of modal temporal logics in powerful learning algorithms, such as temporal decision trees, whose classification capabilities are comparable with the best non-symbolic ones, while producing models with explicit knowledge representation. With the intent of following the same approach in the case of spatial data, in this paper we: i) present a theory of spatial decision tree learning; ii) describe a prototypical implementation of a spatial decision tree learning algorithm based, and strictly extending, the classical C4.5 algorithm; and iii) perform a series of experiments in which we compare the predicting power of spatial decision trees with that of classical propositional decision trees in several versions, for a multi-class image classification problem, on publicly available datasets. Our results are encouraging, showing clear improvements in the performances from the propositional to the spatial models, which in turn show higher levels of interpretability.
* In Proceedings GandALF 2021, arXiv:2109.07798. This is partially dedicated to Alice
Deep Optimized Multiple Description Image Coding via Scalar Quantization Learning
Jan 12, 2020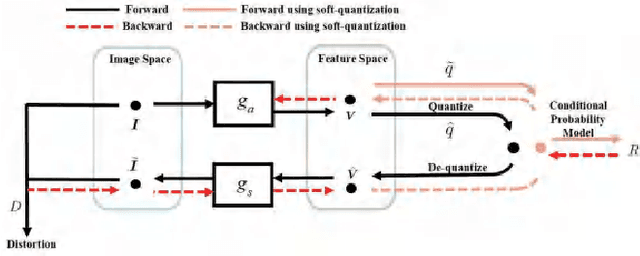

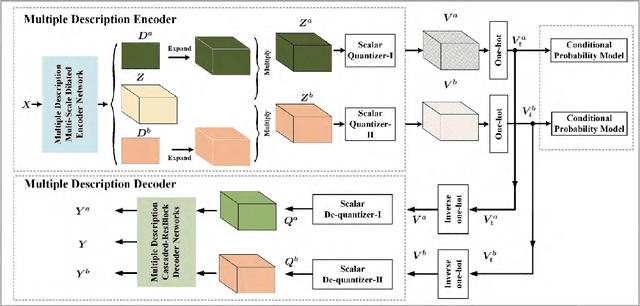
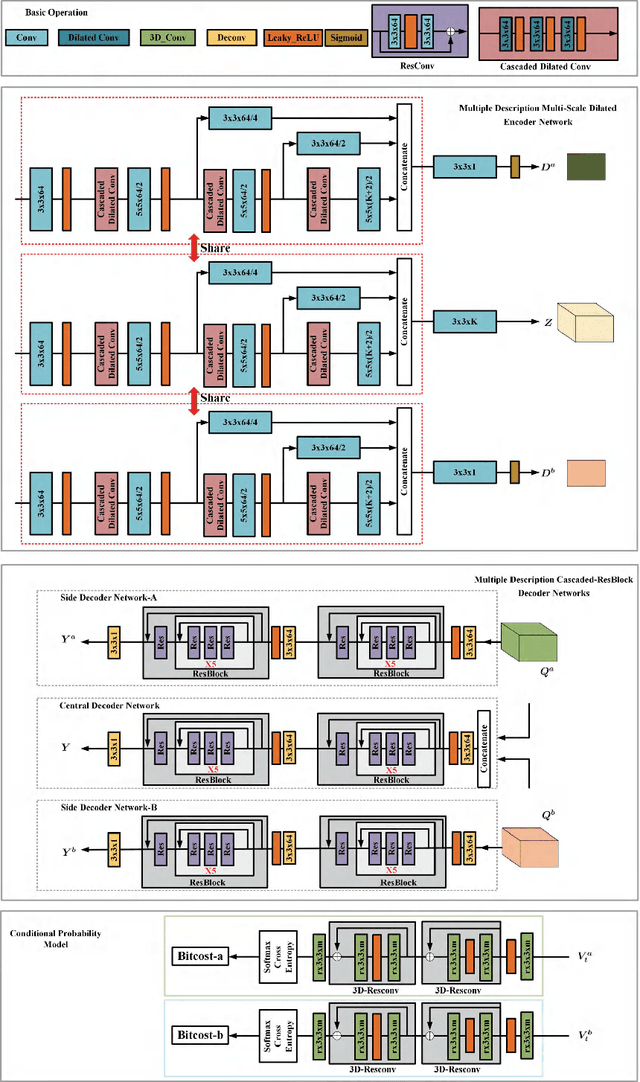
In this paper, we introduce a deep multiple description coding (MDC) framework optimized by minimizing multiple description (MD) compressive loss. First, MD multi-scale-dilated encoder network generates multiple description tensors, which are discretized by scalar quantizers, while these quantized tensors are decompressed by MD cascaded-ResBlock decoder networks. To greatly reduce the total amount of artificial neural network parameters, an auto-encoder network composed of these two types of network is designed as a symmetrical parameter sharing structure. Second, this autoencoder network and a pair of scalar quantizers are simultaneously learned in an end-to-end self-supervised way. Third, considering the variation in the image spatial distribution, each scalar quantizer is accompanied by an importance-indicator map to generate MD tensors, rather than using direct quantization. Fourth, we introduce the multiple description structural similarity distance loss, which implicitly regularizes the diversified multiple description generations, to explicitly supervise multiple description diversified decoding in addition to MD reconstruction loss. Finally, we demonstrate that our MDC framework performs better than several state-of-the-art MDC approaches regarding image coding efficiency when tested on several commonly available datasets.
Is Attention Better Than Matrix Decomposition?
Sep 09, 2021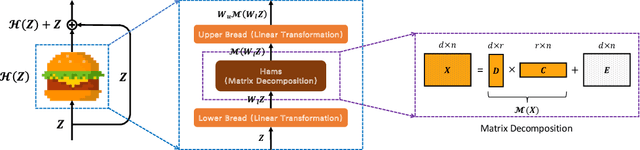

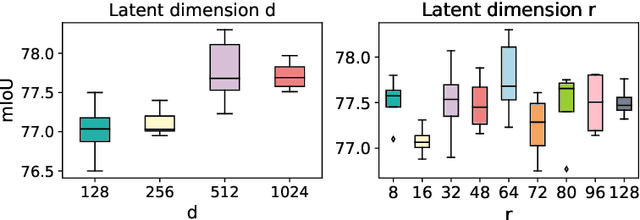
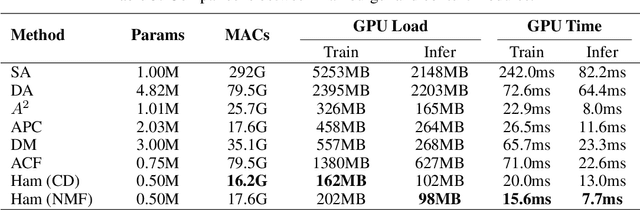
As an essential ingredient of modern deep learning, attention mechanism, especially self-attention, plays a vital role in the global correlation discovery. However, is hand-crafted attention irreplaceable when modeling the global context? Our intriguing finding is that self-attention is not better than the matrix decomposition (MD) model developed 20 years ago regarding the performance and computational cost for encoding the long-distance dependencies. We model the global context issue as a low-rank recovery problem and show that its optimization algorithms can help design global information blocks. This paper then proposes a series of Hamburgers, in which we employ the optimization algorithms for solving MDs to factorize the input representations into sub-matrices and reconstruct a low-rank embedding. Hamburgers with different MDs can perform favorably against the popular global context module self-attention when carefully coping with gradients back-propagated through MDs. Comprehensive experiments are conducted in the vision tasks where it is crucial to learn the global context, including semantic segmentation and image generation, demonstrating significant improvements over self-attention and its variants.
Progressive Generative Adversarial Networks for Medical Image Super resolution
Feb 06, 2019
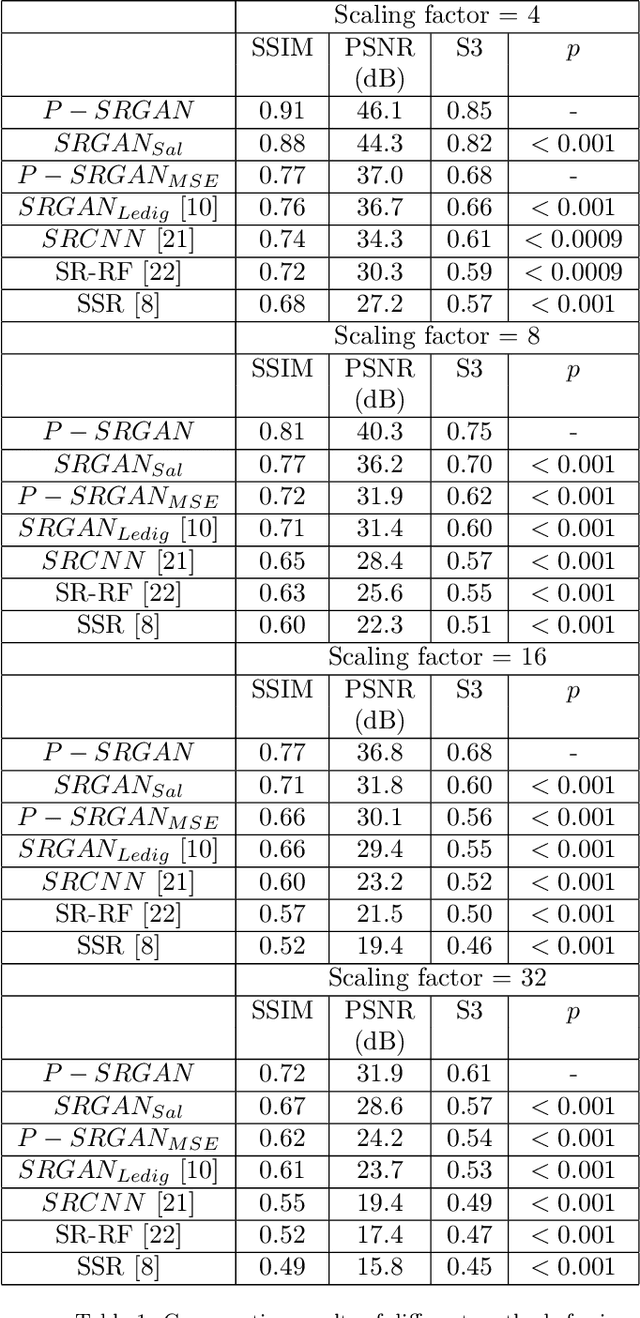

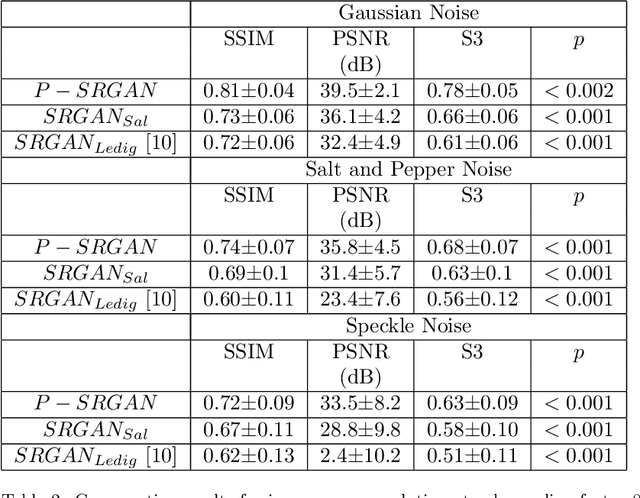
Anatomical landmark segmentation and pathology localization are important steps in automated analysis of medical images. They are particularly challenging when the anatomy or pathology is small, as in retinal images and cardiac MRI, or when the image is of low quality due to device acquisition parameters as in magnetic resonance (MR) scanners. We propose an image super-resolution method using progressive generative adversarial networks (P-GAN) that can take as input a low-resolution image and generate a high resolution image of desired scaling factor. The super resolved images can be used for more accurate detection of landmarks and pathology. Our primary contribution is in proposing a multistage model where the output image quality of one stage is progressively improved in the next stage by using a triplet loss function. The triplet loss enables stepwise image quality improvement by using the output of the previous stage as the baseline. This facilitates generation of super resolved images of high scaling factor while maintaining good image quality. Experimental results for image super-resolution show that our proposed multistage P-GAN outperforms competing methods and baseline GAN.
3DIAS: 3D Shape Reconstruction with Implicit Algebraic Surfaces
Aug 19, 2021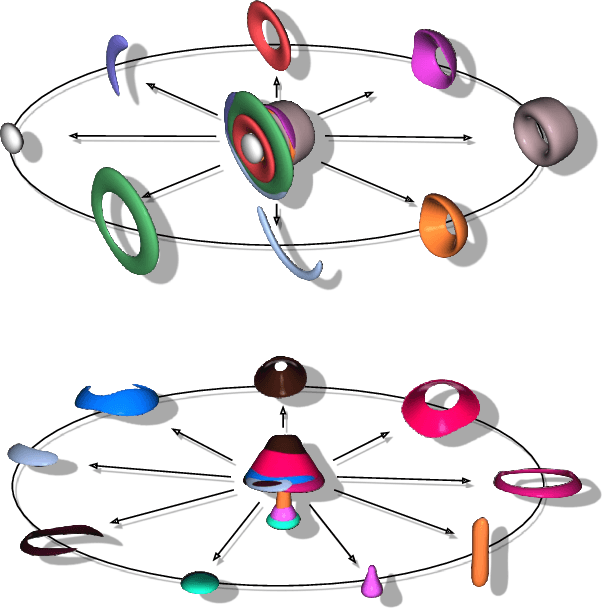
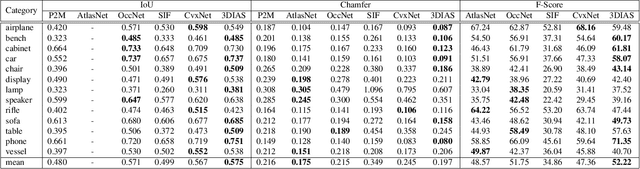
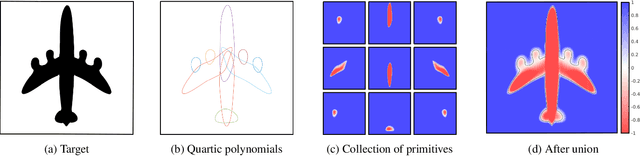

3D Shape representation has substantial effects on 3D shape reconstruction. Primitive-based representations approximate a 3D shape mainly by a set of simple implicit primitives, but the low geometrical complexity of the primitives limits the shape resolution. Moreover, setting a sufficient number of primitives for an arbitrary shape is challenging. To overcome these issues, we propose a constrained implicit algebraic surface as the primitive with few learnable coefficients and higher geometrical complexities and a deep neural network to produce these primitives. Our experiments demonstrate the superiorities of our method in terms of representation power compared to the state-of-the-art methods in single RGB image 3D shape reconstruction. Furthermore, we show that our method can semantically learn segments of 3D shapes in an unsupervised manner. The code is publicly available from https://myavartanoo.github.io/3dias/ .
Fast and Flexible Image Blind Denoising via Competition of Experts
Nov 20, 2019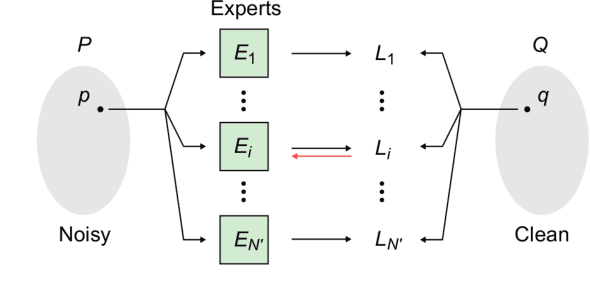
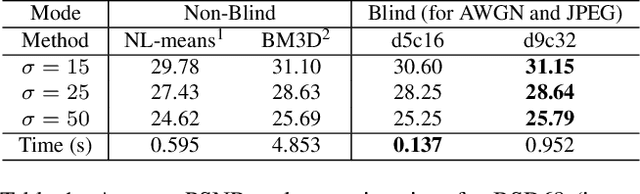
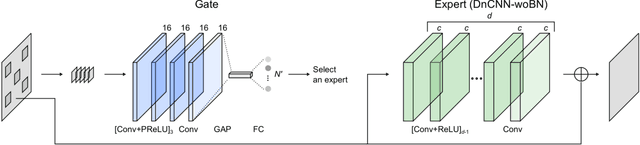
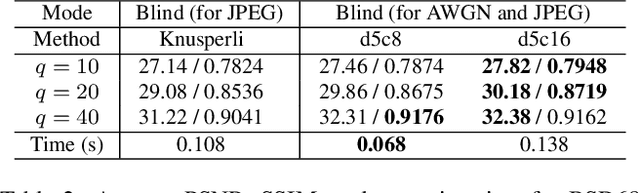
Fast and flexible processing are two essential requirements for a number of practical applications of image denoising. Current state-of-the-art methods, however, still require either high computational cost or limited scopes of the target. We introduce an efficient ensemble network trained via a competition of expert networks, as an application for image blind denoising. We realize automatic division of unlabeled noisy datasets into clusters respectively optimized to enhance denoising performance. The architecture is scalable, can be extended to deal with diverse noise sources/levels without increasing the computation time. Taking advantage of this method, we save up to approximately 90% of computational cost without sacrifice of the denoising performance compared to single network models with identical architectures. We also compare the proposed method with several existing algorithms and observe significant outperformance over prior arts in terms of computational efficiency.
Moving SLAM: Fully Unsupervised Deep Learning in Non-Rigid Scenes
May 05, 2021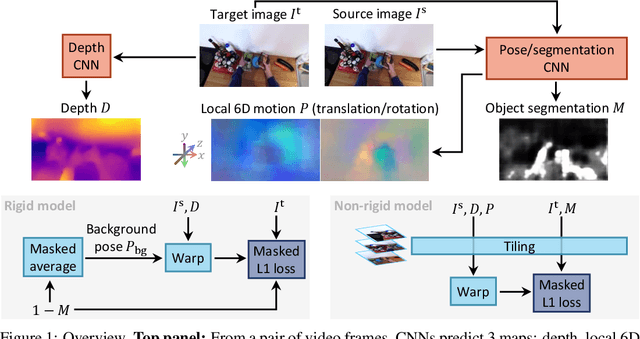
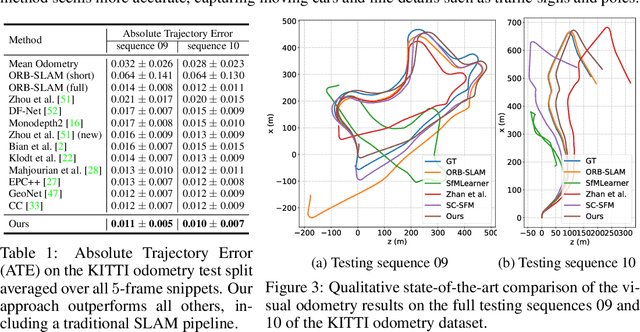
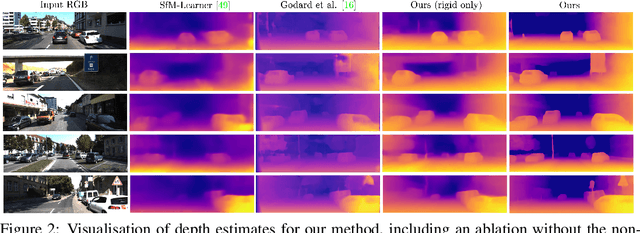
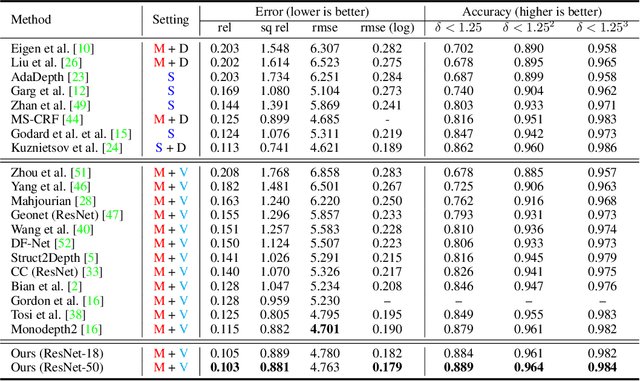
We propose a method to train deep networks to decompose videos into 3D geometry (camera and depth), moving objects, and their motions, with no supervision. We build on the idea of view synthesis, which uses classical camera geometry to re-render a source image from a different point-of-view, specified by a predicted relative pose and depth map. By minimizing the error between the synthetic image and the corresponding real image in a video, the deep network that predicts pose and depth can be trained completely unsupervised. However, the view synthesis equations rely on a strong assumption: that objects do not move. This rigid-world assumption limits the predictive power, and rules out learning about objects automatically. We propose a simple solution: minimize the error on small regions of the image instead. While the scene as a whole may be non-rigid, it is always possible to find small regions that are approximately rigid, such as inside a moving object. Our network can then predict different poses for each region, in a sliding window. This represents a significantly richer model, including 6D object motions, with little additional complexity. We establish new state-of-the-art results on unsupervised odometry and depth prediction on KITTI. We also demonstrate new capabilities on EPIC-Kitchens, a challenging dataset of indoor videos, where there is no ground truth information for depth, odometry, object segmentation or motion. Yet all are recovered automatically by our method.
WebQA: Multihop and Multimodal QA
Sep 01, 2021
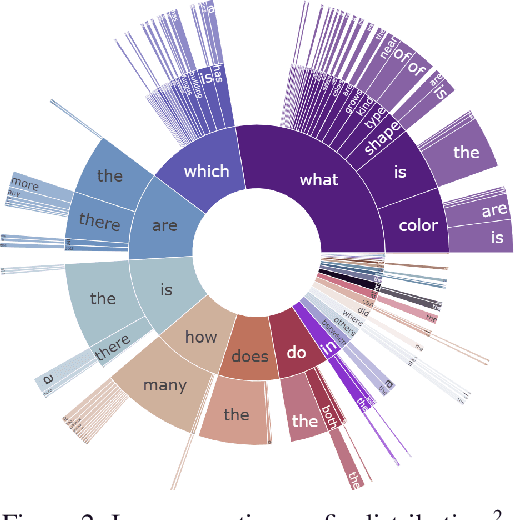


Web search is fundamentally multimodal and multihop. Often, even before asking a question we choose to go directly to image search to find our answers. Further, rarely do we find an answer from a single source but aggregate information and reason through implications. Despite the frequency of this everyday occurrence, at present, there is no unified question answering benchmark that requires a single model to answer long-form natural language questions from text and open-ended visual sources -- akin to a human's experience. We propose to bridge this gap between the natural language and computer vision communities with WebQA. We show that A. our multihop text queries are difficult for a large-scale transformer model, and B. existing multi-modal transformers and visual representations do not perform well on open-domain visual queries. Our challenge for the community is to create a unified multimodal reasoning model that seamlessly transitions and reasons regardless of the source modality.
Multi-concept adversarial attacks
Oct 19, 2021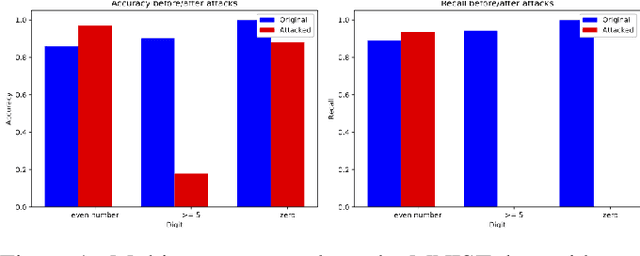
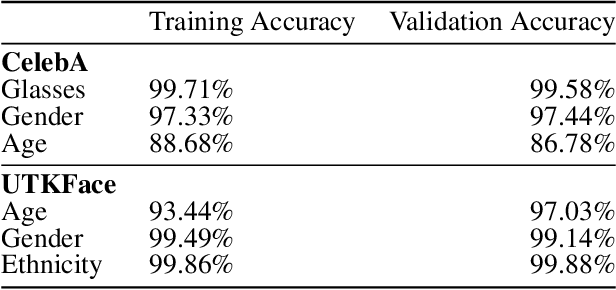

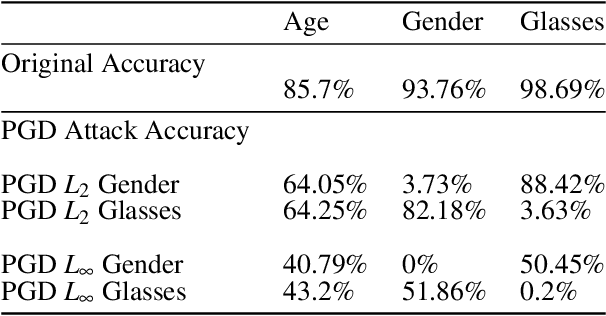
As machine learning (ML) techniques are being increasingly used in many applications, their vulnerability to adversarial attacks becomes well-known. Test time attacks, usually launched by adding adversarial noise to test instances, have been shown effective against the deployed ML models. In practice, one test input may be leveraged by different ML models. Test time attacks targeting a single ML model often neglect their impact on other ML models. In this work, we empirically demonstrate that naively attacking the classifier learning one concept may negatively impact classifiers trained to learn other concepts. For example, for the online image classification scenario, when the Gender classifier is under attack, the (wearing) Glasses classifier is simultaneously attacked with the accuracy dropped from 98.69 to 88.42. This raises an interesting question: is it possible to attack one set of classifiers without impacting the other set that uses the same test instance? Answers to the above research question have interesting implications for protecting privacy against ML model misuse. Attacking ML models that pose unnecessary risks of privacy invasion can be an important tool for protecting individuals from harmful privacy exploitation. In this paper, we address the above research question by developing novel attack techniques that can simultaneously attack one set of ML models while preserving the accuracy of the other. In the case of linear classifiers, we provide a theoretical framework for finding an optimal solution to generate such adversarial examples. Using this theoretical framework, we develop a multi-concept attack strategy in the context of deep learning. Our results demonstrate that our techniques can successfully attack the target classes while protecting the protected classes in many different settings, which is not possible with the existing test-time attack-single strategies.