 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Autoencoding of Dropout Patterns
Oct 03, 2023We propose a generative model termed Deciphering Autoencoders. In this model, we assign a unique random dropout pattern to each data point in the training dataset and then train an autoencoder to reconstruct the corresponding data point using this pattern as information to be encoded. Since the training of Deciphering Autoencoders relies solely on reconstruction error, it offers more stable training than other generative models. Despite its simplicity, Deciphering Autoencoders show comparable sampling quality to DCGAN on the CIFAR-10 dataset.
Image Super-Resolution with Deep Dictionary
Jul 19, 2022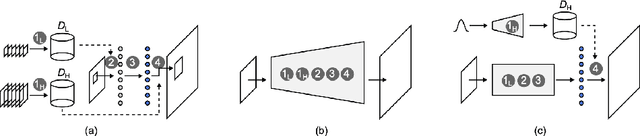
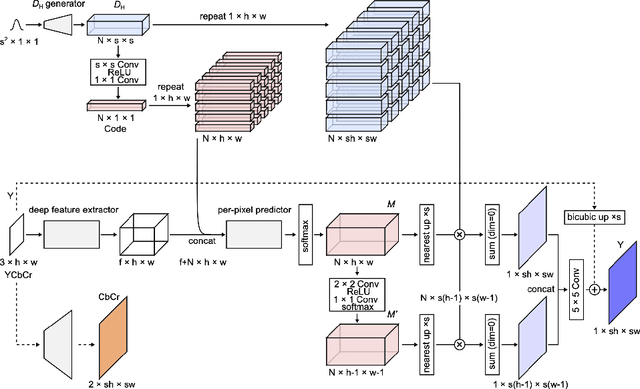
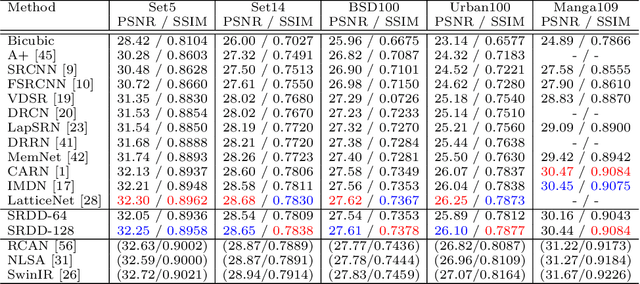
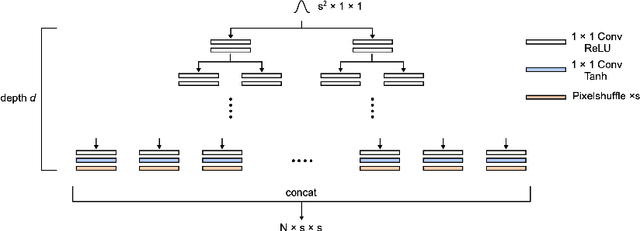
Since the first success of Dong et al., the deep-learning-based approach has become dominant in the field of single-image super-resolution. This replaces all the handcrafted image processing steps of traditional sparse-coding-based methods with a deep neural network. In contrast to sparse-coding-based methods, which explicitly create high/low-resolution dictionaries, the dictionaries in deep-learning-based methods are implicitly acquired as a nonlinear combination of multiple convolutions. One disadvantage of deep-learning-based methods is that their performance is degraded for images created differently from the training dataset (out-of-domain images). We propose an end-to-end super-resolution network with a deep dictionary (SRDD), where a high-resolution dictionary is explicitly learned without sacrificing the advantages of deep learning. Extensive experiments show that explicit learning of high-resolution dictionary makes the network more robust for out-of-domain test images while maintaining the performance of the in-domain test images.
Unpaired Image Super-Resolution using Pseudo-Supervision
Feb 26, 2020

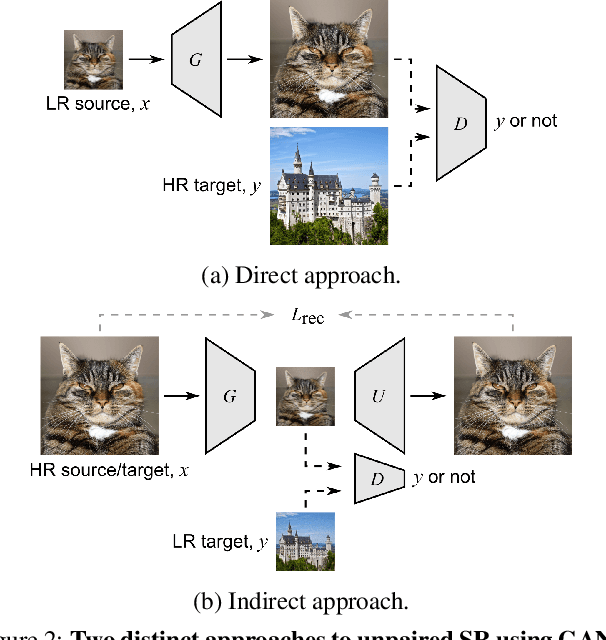
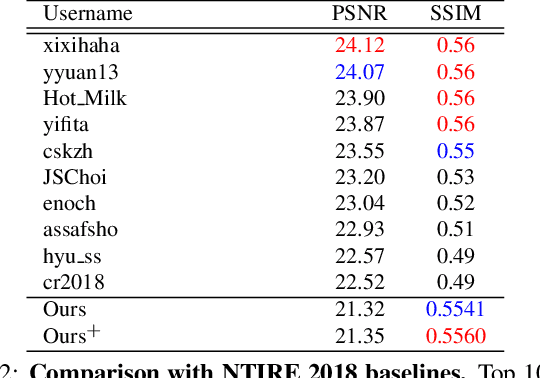
In most studies on learning-based image super-resolution (SR), the paired training dataset is created by downscaling high-resolution (HR) images with a predetermined operation (e.g., bicubic). However, these methods fail to super-resolve real-world low-resolution (LR) images, for which the degradation process is much more complicated and unknown. In this paper, we propose an unpaired SR method using a generative adversarial network that does not require a paired/aligned training dataset. Our network consists of an unpaired kernel/noise correction network and a pseudo-paired SR network. The correction network removes noise and adjusts the kernel of the inputted LR image; then, the corrected clean LR image is upscaled by the SR network. In the training phase, the correction network also produces a pseudo-clean LR image from the inputted HR image, and then a mapping from the pseudo-clean LR image to the inputted HR image is learned by the SR network in a paired manner. Because our SR network is independent of the correction network, well-studied existing network architectures and pixel-wise loss functions can be integrated with the proposed framework. Experiments on diverse datasets show that the proposed method is superior to existing solutions to the unpaired SR problem.
Fast and Flexible Image Blind Denoising via Competition of Experts
Nov 20, 2019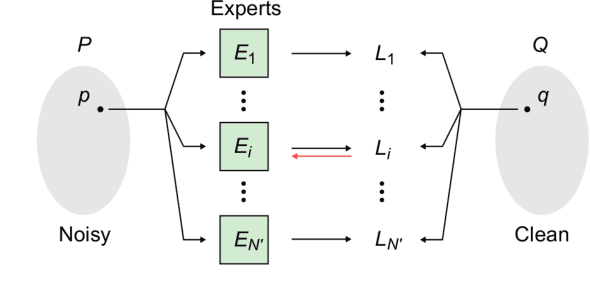
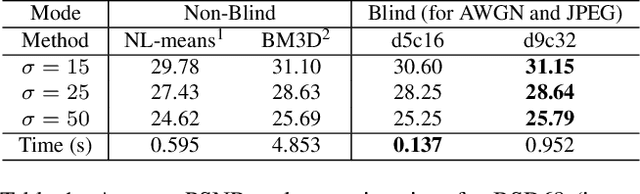
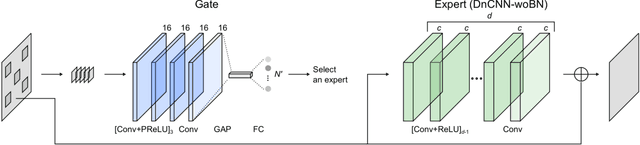
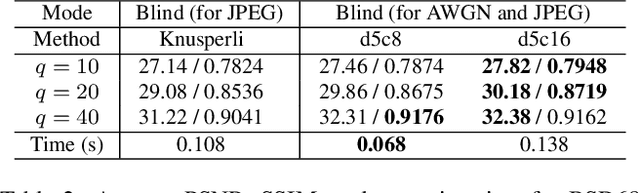
Fast and flexible processing are two essential requirements for a number of practical applications of image denoising. Current state-of-the-art methods, however, still require either high computational cost or limited scopes of the target. We introduce an efficient ensemble network trained via a competition of expert networks, as an application for image blind denoising. We realize automatic division of unlabeled noisy datasets into clusters respectively optimized to enhance denoising performance. The architecture is scalable, can be extended to deal with diverse noise sources/levels without increasing the computation time. Taking advantage of this method, we save up to approximately 90% of computational cost without sacrifice of the denoising performance compared to single network models with identical architectures. We also compare the proposed method with several existing algorithms and observe significant outperformance over prior arts in terms of computational efficiency.