 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2CAD: Text to 3D CAD Generation via Technical Drawings
Nov 09, 2024The generation of industrial Computer-Aided Design (CAD) models from user requests and specifications is crucial to enhancing efficiency in modern manufacturing. Traditional methods of CAD generation rely heavily on manual inputs and struggle with complex or non-standard designs, making them less suited for dynamic industrial needs. To overcome these challenges, we introduce Text2CAD, a novel framework that employs stable diffusion models tailored to automate the generation process and efficiently bridge the gap between user specifications in text and functional CAD models. This approach directly translates the user's textural descriptions into detailed isometric images, which are then precisely converted into orthographic views, e.g., top, front, and side, providing sufficient information to reconstruct 3D CAD models. This process not only streamlines the creation of CAD models from textual descriptions but also ensures that the resulting models uphold physical and dimensional consistency essential for practical engineering applications. Our experimental results show that Text2CAD effectively generates technical drawings that are accurately translated into high-quality 3D CAD models, showing substantial potential to revolutionize CAD automation in response to user demands.
CNC-Net: Self-Supervised Learning for CNC Machining Operations
Dec 15, 2023CNC manufacturing is a process that employs computer numerical control (CNC) machines to govern the movements of various industrial tools and machinery, encompassing equipment ranging from grinders and lathes to mills and CNC routers. However, the reliance on manual CNC programming has become a bottleneck, and the requirement for expert knowledge can result in significant costs. Therefore, we introduce a pioneering approach named CNC-Net, representing the use of deep neural networks (DNNs) to simulate CNC machines and grasp intricate operations when supplied with raw materials. CNC-Net constitutes a self-supervised framework that exclusively takes an input 3D model and subsequently generates the essential operation parameters required by the CNC machine to construct the object. Our method has the potential to transformative automation in manufacturing by offering a cost-effective alternative to the high costs of manual CNC programming while maintaining exceptional precision in 3D object production. Our experiments underscore the effectiveness of our CNC-Net in constructing the desired 3D objects through the utilization of CNC operations. Notably, it excels in preserving finer local details, exhibiting a marked enhancement in precision compared to the state-of-the-art 3D CAD reconstruction approaches.
ICF-SRSR: Invertible scale-Conditional Function for Self-Supervised Real-world Single Image Super-Resolution
Jul 24, 2023Single image super-resolution (SISR) is a challenging ill-posed problem that aims to up-sample a given low-resolution (LR) image to a high-resolution (HR) counterpart. Due to the difficulty in obtaining real LR-HR training pairs, recent approaches are trained on simulated LR images degraded by simplified down-sampling operators, e.g., bicubic. Such an approach can be problematic in practice because of the large gap between the synthesized and real-world LR images. To alleviate the issue, we propose a novel Invertible scale-Conditional Function (ICF), which can scale an input image and then restore the original input with different scale conditions. By leveraging the proposed ICF, we construct a novel self-supervised SISR framework (ICF-SRSR) to handle the real-world SR task without using any paired/unpaired training data. Furthermore, our ICF-SRSR can generate realistic and feasible LR-HR pairs, which can make existing supervised SISR networks more robust. Extensive experiments demonstrate the effectiveness of the proposed method in handling SISR in a fully self-supervised manner. Our ICF-SRSR demonstrates superior performance compared to the existing methods trained on synthetic paired images in real-world scenarios and exhibits comparable performance compared to state-of-the-art supervised/unsupervised methods on public benchmark datasets.
ACL-SPC: Adaptive Closed-Loop system for Self-Supervised Point Cloud Completion
Mar 17, 2023Point cloud completion addresses filling in the missing parts of a partial point cloud obtained from depth sensors and generating a complete point cloud. Although there has been steep progress in the supervised methods on the synthetic point cloud completion task, it is hardly applicable in real-world scenarios due to the domain gap between the synthetic and real-world datasets or the requirement of prior information. To overcome these limitations, we propose a novel self-supervised framework ACL-SPC for point cloud completion to train and test on the same data. ACL-SPC takes a single partial input and attempts to output the complete point cloud using an adaptive closed-loop (ACL) system that enforces the output same for the variation of an input. We evaluate our proposed ACL-SPC on various datasets to prove that it can successfully learn to complete a partial point cloud as the first self-supervised scheme. Results show that our method is comparable with unsupervised methods and achieves superior performance on the real-world dataset compared to the supervised methods trained on the synthetic dataset. Extensive experiments justify the necessity of self-supervised learning and the effectiveness of our proposed method for the real-world point cloud completion task. The code is publicly available from https://github.com/Sangminhong/ACL-SPC_PyTorch
CVF-SID: Cyclic multi-Variate Function for Self-Supervised Image Denoising by Disentangling Noise from Image
Mar 29, 2022
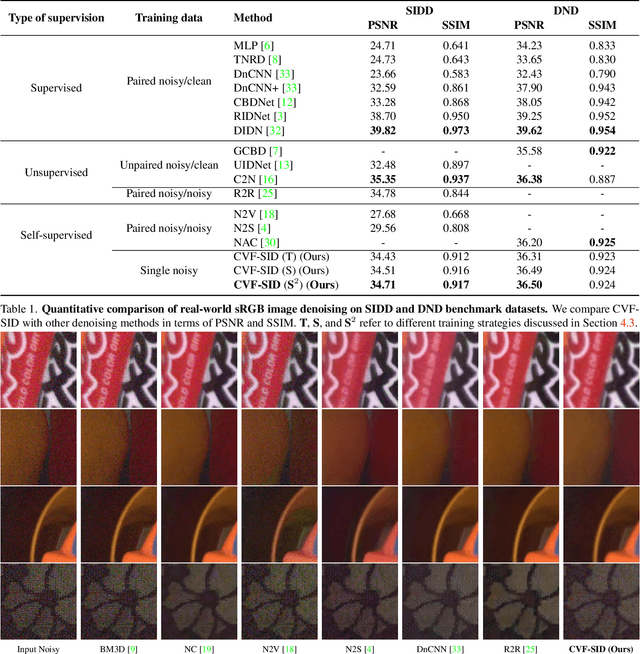
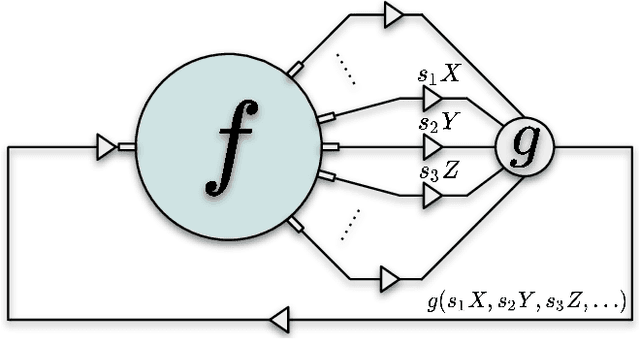
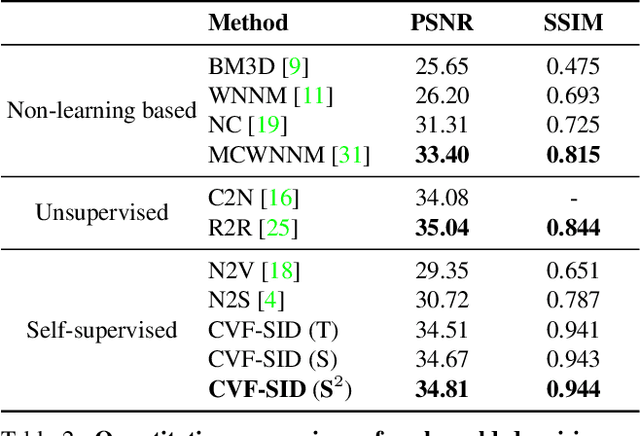
Recently, significant progress has been made on image denoising with strong supervision from large-scale datasets. However, obtaining well-aligned noisy-clean training image pairs for each specific scenario is complicated and costly in practice. Consequently, applying a conventional supervised denoising network on in-the-wild noisy inputs is not straightforward. Although several studies have challenged this problem without strong supervision, they rely on less practical assumptions and cannot be applied to practical situations directly. To address the aforementioned challenges, we propose a novel and powerful self-supervised denoising method called CVF-SID based on a Cyclic multi-Variate Function (CVF) module and a self-supervised image disentangling (SID) framework. The CVF module can output multiple decomposed variables of the input and take a combination of the outputs back as an input in a cyclic manner. Our CVF-SID can disentangle a clean image and noise maps from the input by leveraging various self-supervised loss terms. Unlike several methods that only consider the signal-independent noise models, we also deal with signal-dependent noise components for real-world applications. Furthermore, we do not rely on any prior assumptions about the underlying noise distribution, making CVF-SID more generalizable toward realistic noise. Extensive experiments on real-world datasets show that CVF-SID achieves state-of-the-art self-supervised image denoising performance and is comparable to other existing approaches. The code is publicly available from https://github.com/Reyhanehne/CVF-SID_PyTorch .
PolyNet: Polynomial Neural Network for 3D Shape Recognition with PolyShape Representation
Oct 15, 2021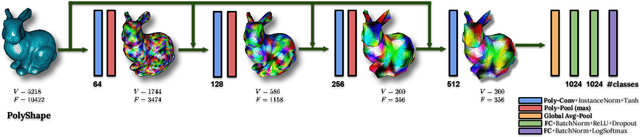
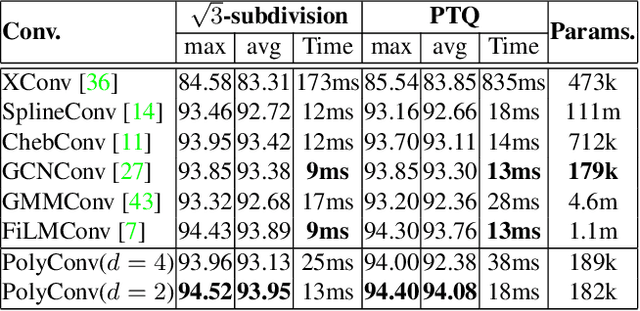
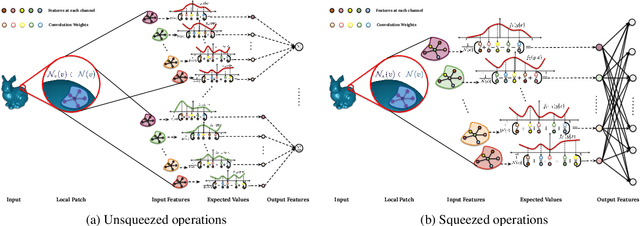
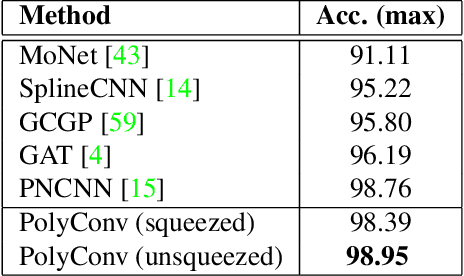
3D shape representation and its processing have substantial effects on 3D shape recognition. The polygon mesh as a 3D shape representation has many advantages in computer graphics and geometry processing. However, there are still some challenges for the existing deep neural network (DNN)-based methods on polygon mesh representation, such as handling the variations in the degree and permutations of the vertices and their pairwise distances. To overcome these challenges, we propose a DNN-based method (PolyNet) and a specific polygon mesh representation (PolyShape) with a multi-resolution structure. PolyNet contains two operations; (1) a polynomial convolution (PolyConv) operation with learnable coefficients, which learns continuous distributions as the convolutional filters to share the weights across different vertices, and (2) a polygonal pooling (PolyPool) procedure by utilizing the multi-resolution structure of PolyShape to aggregate the features in a much lower dimension. Our experiments demonstrate the strength and the advantages of PolyNet on both 3D shape classification and retrieval tasks compared to existing polygon mesh-based methods and its superiority in classifying graph representations of images. The code is publicly available from https://myavartanoo.github.io/polynet/.
3DIAS: 3D Shape Reconstruction with Implicit Algebraic Surfaces
Aug 19, 2021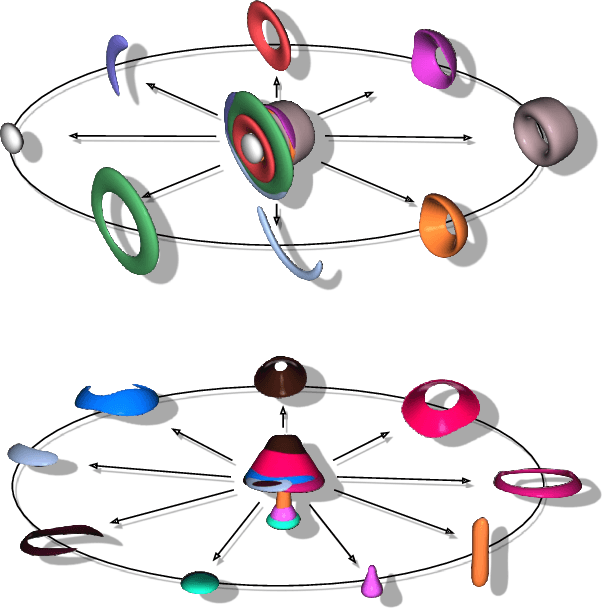
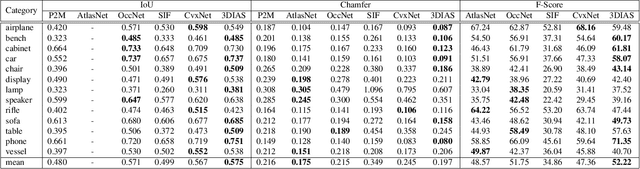
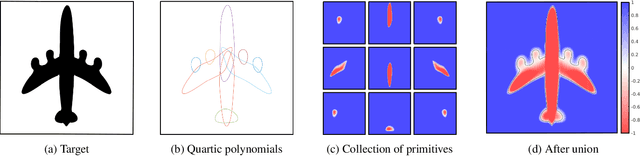

3D Shape representation has substantial effects on 3D shape reconstruction. Primitive-based representations approximate a 3D shape mainly by a set of simple implicit primitives, but the low geometrical complexity of the primitives limits the shape resolution. Moreover, setting a sufficient number of primitives for an arbitrary shape is challenging. To overcome these issues, we propose a constrained implicit algebraic surface as the primitive with few learnable coefficients and higher geometrical complexities and a deep neural network to produce these primitives. Our experiments demonstrate the superiorities of our method in terms of representation power compared to the state-of-the-art methods in single RGB image 3D shape reconstruction. Furthermore, we show that our method can semantically learn segments of 3D shapes in an unsupervised manner. The code is publicly available from https://myavartanoo.github.io/3dias/ .