 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OpenDenoising: an Extensible Benchmark for Building Comparative Studies of Image Denoisers
Oct 18, 2019
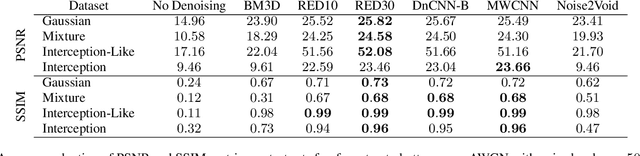
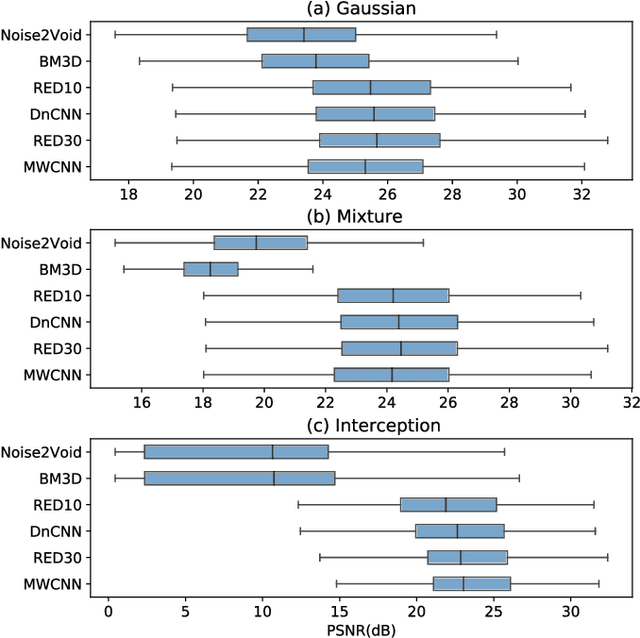

Image denoising has recently taken a leap forward due to machine learning. However, image denoisers, both expert-based and learning-based, are mostly tested on well-behaved generated noises (usually Gaussian) rather than on real-life noises, making performance comparisons difficult in real-world conditions. This is especially true for learning-based denoisers which performance depends on training data. Hence, choosing which method to use for a specific denoising problem is difficult. This paper proposes a comparative study of existing denoisers, as well as an extensible open tool that makes it possible to reproduce and extend the study. MWCNN is shown to outperform other methods when trained for a real-world image interception noise, and additionally is the second least compute hungry of the tested methods. To evaluate the robustness of conclusions, three test sets are compared. A Kendall's Tau correlation of only 60% is obtained on methods ranking between noise types, demonstrating the need for a benchmarking tool.
Multimodal Self-Supervised Learning for Medical Image Analysis
Dec 11, 2019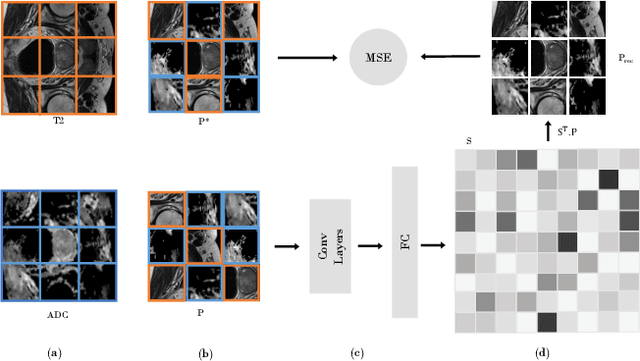
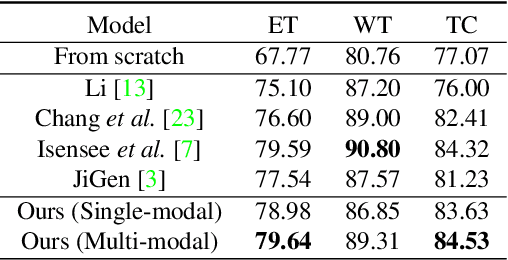
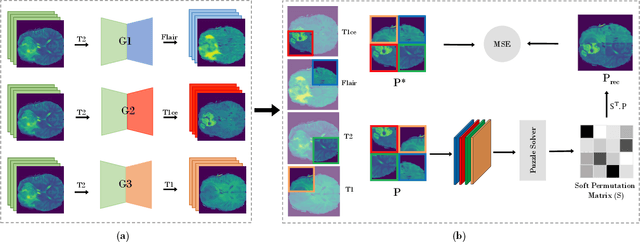
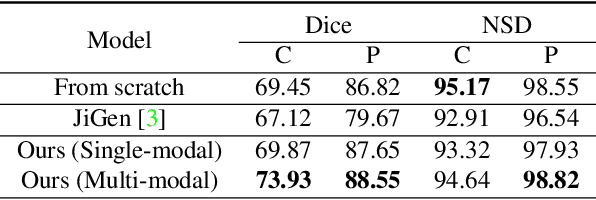
In this paper, we propose a self-supervised learning approach that leverages multiple imaging modalities to increase data efficiency for medical image analysis. To this end, we introduce multimodal puzzle-solving proxy tasks, which facilitate neural network representation learning from multiple image modalities. These representations allow for subsequent fine-tuning on different downstream tasks. To achieve that, we employ the Sinkhorn operator to predict permutations of puzzle pieces in conjunction with a modality agnostic feature embedding. Together, they allow for a lean network architecture and increased computational efficiency. Under this framework, we propose different strategies for puzzle construction, integrating multiple medical imaging modalities, with varying levels of puzzle complexity. We benchmark these strategies in a range of experiments to assess the gains of our method in downstream performance and data-efficiency on different target tasks. Our experiments show that solving puzzles interleaved with multimodal content yields more powerful semantic representations. This allows us to solve downstream tasks more accurately and efficiently, compared to treating each modality independently. We demonstrate the effectiveness of the proposed approach on two multimodal medical imaging benchmarks: the BraTS and the Prostate semantic segmentation datasets, on which we achieve competitive results to state-of-the-art solutions, at a fraction of the computational expense. We also outperform many previous solutions on the chosen benchmarks.
Benefiting from Multitask Learning to Improve Single Image Super-Resolution
Jul 29, 2019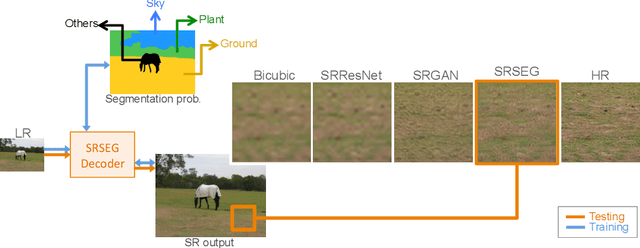
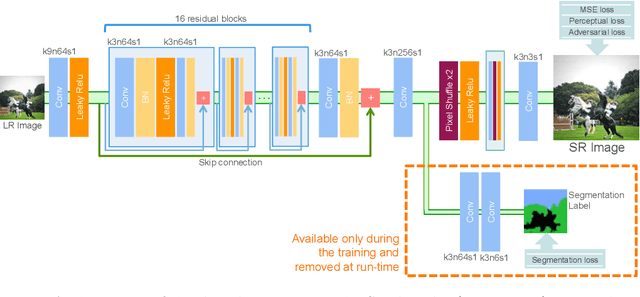
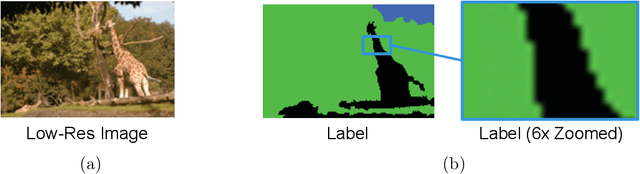
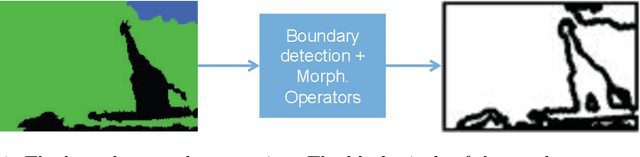
Despite significant progress toward super resolving more realistic images by deeper convolutional neural networks (CNNs), reconstructing fine and natural textures still remains a challenging problem. Recent works on single image super resolution (SISR) are mostly based on optimizing pixel and content wise similarity between recovered and high-resolution (HR) images and do not benefit from recognizability of semantic classes. In this paper, we introduce a novel approach using categorical information to tackle the SISR problem; we present a decoder architecture able to extract and use semantic information to super-resolve a given image by using multitask learning, simultaneously for image super-resolution and semantic segmentation. To explore categorical information during training, the proposed decoder only employs one shared deep network for two task-specific output layers. At run-time only layers resulting HR image are used and no segmentation label is required. Extensive perceptual experiments and a user study on images randomly selected from COCO-Stuff dataset demonstrate the effectiveness of our proposed method and it outperforms the state-of-the-art methods.
Video Coding for Machine: Compact Visual Representation Compression for Intelligent Collaborative Analytics
Oct 18, 2021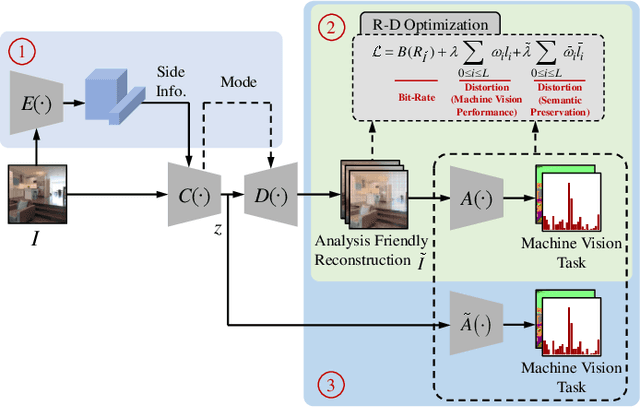
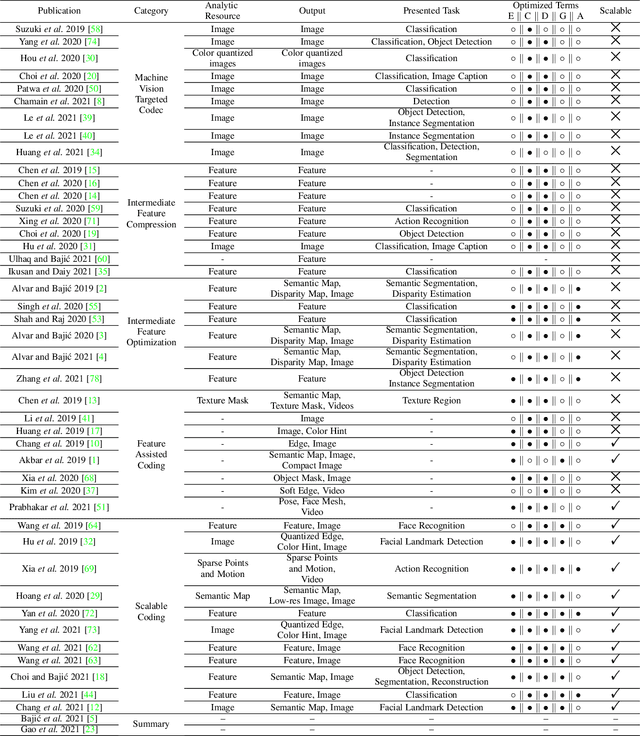
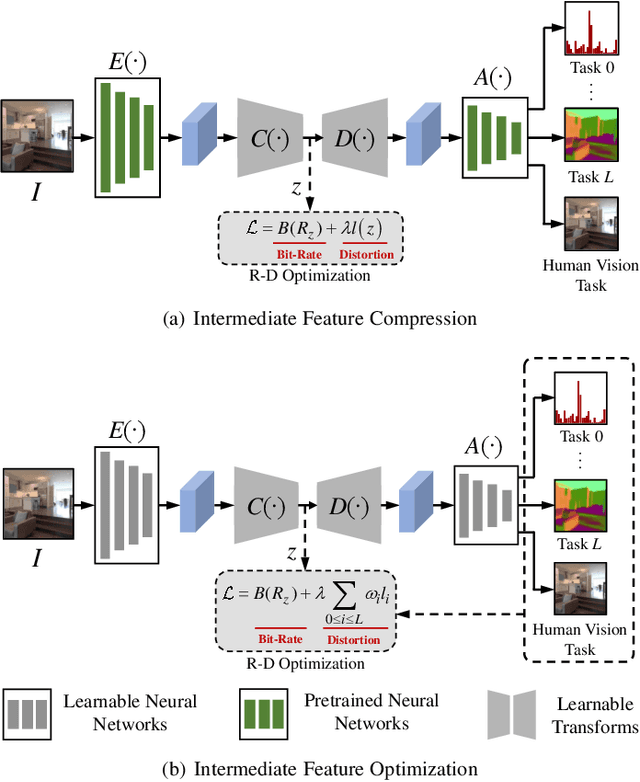
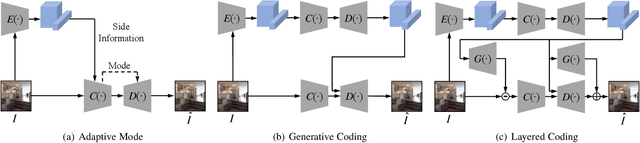
Video Coding for Machines (VCM) is committed to bridging to an extent separate research tracks of video/image compression and feature compression, and attempts to optimize compactness and efficiency jointly from a unified perspective of high accuracy machine vision and full fidelity human vision. In this paper, we summarize VCM methodology and philosophy based on existing academia and industrial efforts. The development of VCM follows a general rate-distortion optimization, and the categorization of key modules or techniques is established. From previous works, it is demonstrated that, although existing works attempt to reveal the nature of scalable representation in bits when dealing with machine and human vision tasks, there remains a rare study in the generality of low bit rate representation, and accordingly how to support a variety of visual analytic tasks. Therefore, we investigate a novel visual information compression for the analytics taxonomy problem to strengthen the capability of compact visual representations extracted from multiple tasks for visual analytics. A new perspective of task relationships versus compression is revisited. By keeping in mind the transferability among different machine vision tasks (e.g. high-level semantic and mid-level geometry-related), we aim to support multiple tasks jointly at low bit rates. In particular, to narrow the dimensionality gap between neural network generated features extracted from pixels and a variety of machine vision features/labels (e.g. scene class, segmentation labels), a codebook hyperprior is designed to compress the neural network-generated features. As demonstrated in our experiments, this new hyperprior model is expected to improve feature compression efficiency by estimating the signal entropy more accurately, which enables further investigation of the granularity of abstracting compact features among different tasks.
Decoupled Contrastive Learning
Oct 13, 2021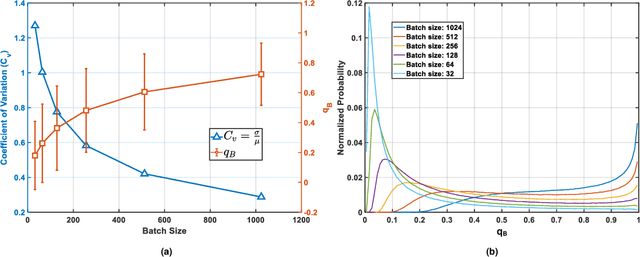
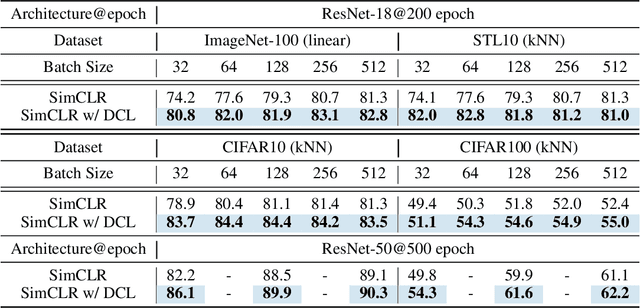
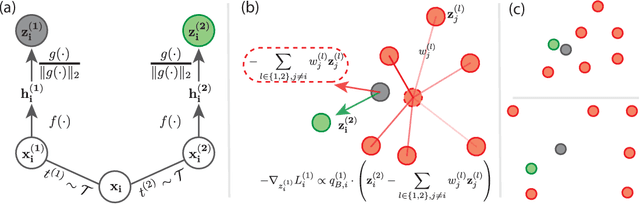

Contrastive learning (CL) is one of the most successful paradigms for self-supervised learning (SSL). In a principled way, it considers two augmented ``views'' of the same image as positive to be pulled closer, and all other images negative to be pushed further apart. However, behind the impressive success of CL-based techniques, their formulation often relies on heavy-computation settings, including large sample batches, extensive training epochs, etc. We are thus motivated to tackle these issues and aim at establishing a simple, efficient, and yet competitive baseline of contrastive learning. Specifically, we identify, from theoretical and empirical studies, a noticeable negative-positive-coupling (NPC) effect in the widely used cross-entropy (InfoNCE) loss, leading to unsuitable learning efficiency with respect to the batch size. Indeed the phenomenon tends to be neglected in that optimizing infoNCE loss with a small-size batch is effective in solving easier SSL tasks. By properly addressing the NPC effect, we reach a decoupled contrastive learning (DCL) objective function, significantly improving SSL efficiency. DCL can achieve competitive performance, requiring neither large batches in SimCLR, momentum encoding in MoCo, or large epochs. We demonstrate the usefulness of DCL in various benchmarks, while manifesting its robustness being much less sensitive to suboptimal hyperparameters. Notably, our approach achieves $66.9\%$ ImageNet top-1 accuracy using batch size 256 within 200 epochs pre-training, outperforming its baseline SimCLR by $5.1\%$. With further optimized hyperparameters, DCL can improve the accuracy to $68.2\%$. We believe DCL provides a valuable baseline for future contrastive learning-based SSL studies.
Self-supervised Learning with Local Attention-Aware Feature
Aug 01, 2021
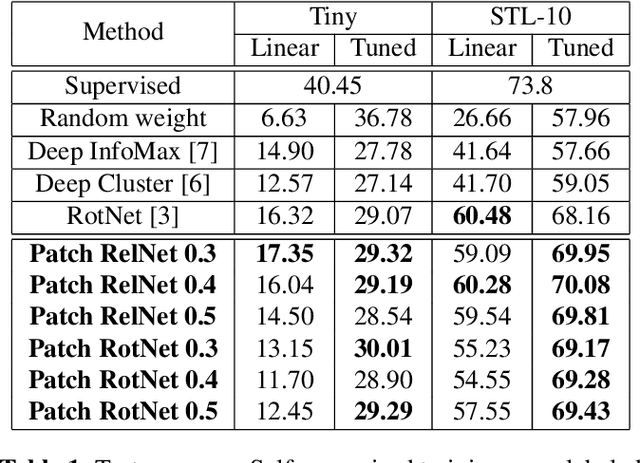
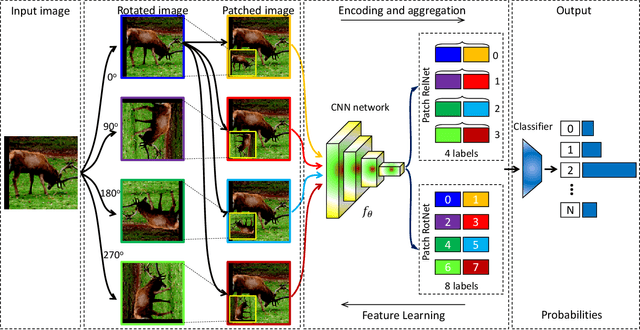
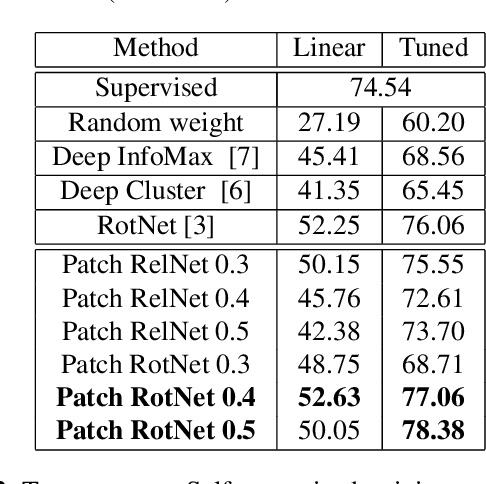
In this work, we propose a novel methodology for self-supervised learning for generating global and local attention-aware visual features. Our approach is based on training a model to differentiate between specific image transformations of an input sample and the patched images. Utilizing this approach, the proposed method is able to outperform the previous best competitor by 1.03% on the Tiny-ImageNet dataset and by 2.32% on the STL-10 dataset. Furthermore, our approach outperforms the fully-supervised learning method on the STL-10 dataset. Experimental results and visualizations show the capability of successfully learning global and local attention-aware visual representations.
Differential Diagnosis of Frontotemporal Dementia and Alzheimer's Disease using Generative Adversarial Network
Sep 12, 2021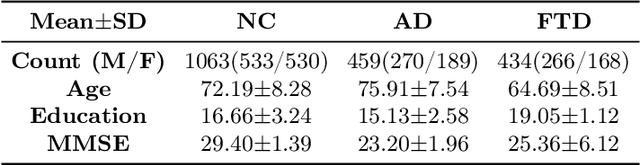
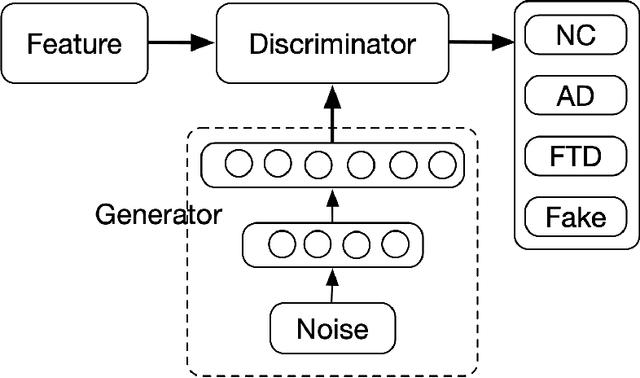
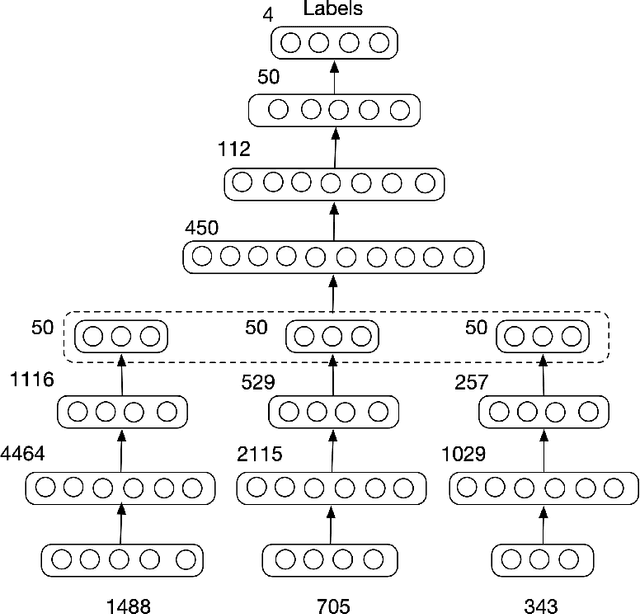
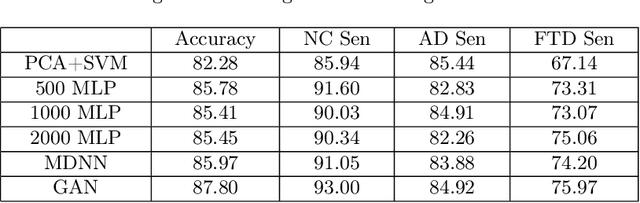
Frontotemporal dementia and Alzheimer's disease are two common forms of dementia and are easily misdiagnosed as each other due to their similar pattern of clinical symptoms. Differentiating between the two dementia types is crucial for determining disease-specific intervention and treatment. Recent development of Deep-learning-based approaches in the field of medical image computing are delivering some of the best performance for many binary classification tasks, although its application in differential diagnosis, such as neuroimage-based differentiation for multiple types of dementia, has not been explored. In this study, a novel framework was proposed by using the Generative Adversarial Network technique to distinguish FTD, AD and normal control subjects, using volumetric features extracted at coarse-to-fine structural scales from Magnetic Resonance Imaging scans. Experiments of 10-folds cross-validation on 1,954 images achieved high accuracy. With the proposed framework, we have demonstrated that the combination of multi-scale structural features and synthetic data augmentation based on generative adversarial network can improve the performance of challenging tasks such as differentiating Dementia sub-types.
Single Image Deraining: From Model-Based to Data-Driven and Beyond
Dec 16, 2019

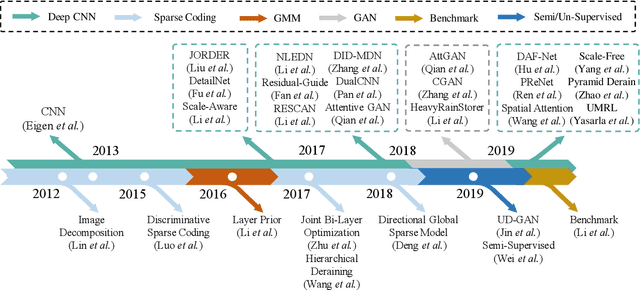
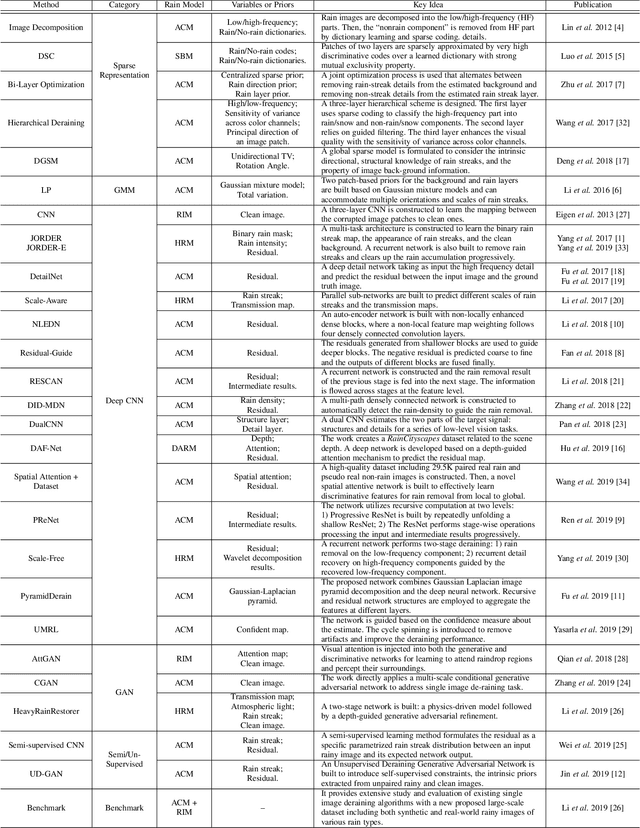
Rain removal or deraining methods attempt to restore the clean background scenes from images degraded by rain streaks and rain accumulation (or rain veiling effect). The early single-image deraining methods employ optimization methods on a cost function, where various priors are developed to represent the properties of rain and background-scene layers. Since 2017, single-image deraining methods step into a deep-learning era. They are built on deep-learning networks, i.e. convolutional neural networks, recurrent neural networks, generative adversarial networks, etc., and demonstrate impressive performance. Given the current rapid development, this article provides a comprehensive survey of deraining methods over the last decade. The rain appearance models are first summarized, and then followed by the discussion on two categories of deraining approaches: model-based and data-driven approaches. For the former, we organize the literature based on their basic models and priors. For the latter, we discuss several ideas on deep learning, i.e., models, architectures, priors, auxiliary variables, loss functions, and training datasets. This survey presents milestones in cuttingedge single-image deraining methods, reviews a broad selection of previous works in different categories, and provides insights on the historical development route from the model-based to data-driven methods. It also summarizes performance comparisons quantitatively and qualitatively. Beyond discussing existing deraining methods, we also discuss future directions and trends.
StructureFlow: Image Inpainting via Structure-aware Appearance Flow
Aug 11, 2019
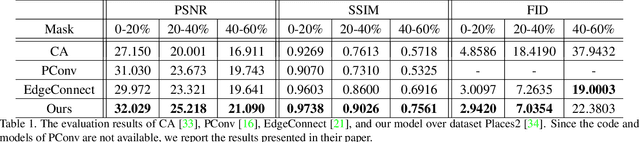
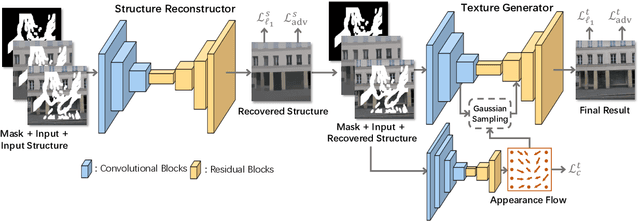
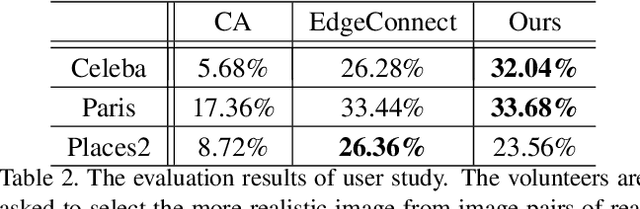
Image inpainting techniques have shown significant improvements by using deep neural networks recently. However, most of them may either fail to reconstruct reasonable structures or restore fine-grained textures. In order to solve this problem, in this paper, we propose a two-stage model which splits the inpainting task into two parts: structure reconstruction and texture generation. In the first stage, edge-preserved smooth images are employed to train a structure reconstructor which completes the missing structures of the inputs. In the second stage, based on the reconstructed structures, a texture generator using appearance flow is designed to yield image details. Experiments on multiple publicly available datasets show the superior performance of the proposed network.
Using Videos to Evaluate Image Model Robustness
Apr 24, 2019
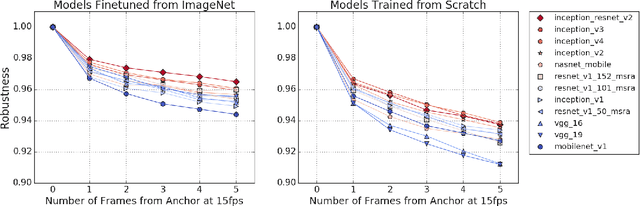
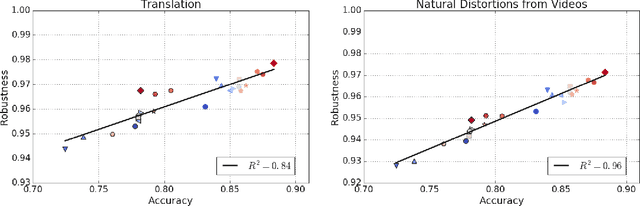
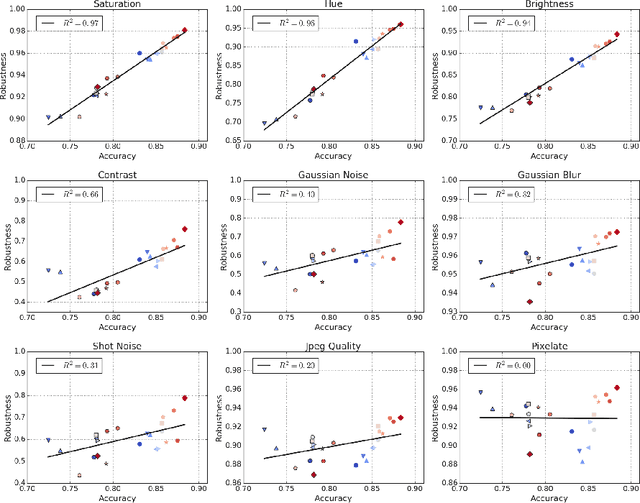
Human visual systems are robust to a wide range of image transformations that are challenging for artificial networks. We present the first study of image model robustness to the minute transformations found across video frames, which we term "natural robustness". Compared to previous studies on adversarial examples and synthetic distortions, natural robustness captures a more diverse set of common image transformations that occur in the natural environment. Our study across a dozen model architectures shows that more accurate models are more robust to natural transformations, and that robustness to synthetic color distortions is a good proxy for natural robustness. In examining brittleness in videos, we find that majority of the brittleness found in videos lies outside the typical definition of adversarial examples (99.9\%). Finally, we investigate training techniques to reduce brittleness and find that no single technique systematically improves natural robustness across twelve tested architectures.