 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
How Much Can CLIP Benefit Vision-and-Language Tasks?
Jul 13, 2021
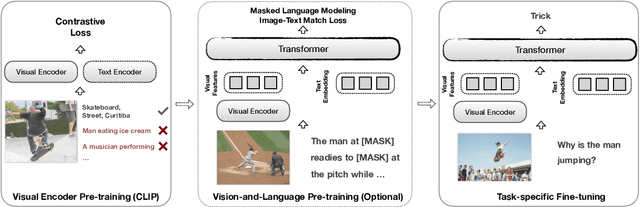
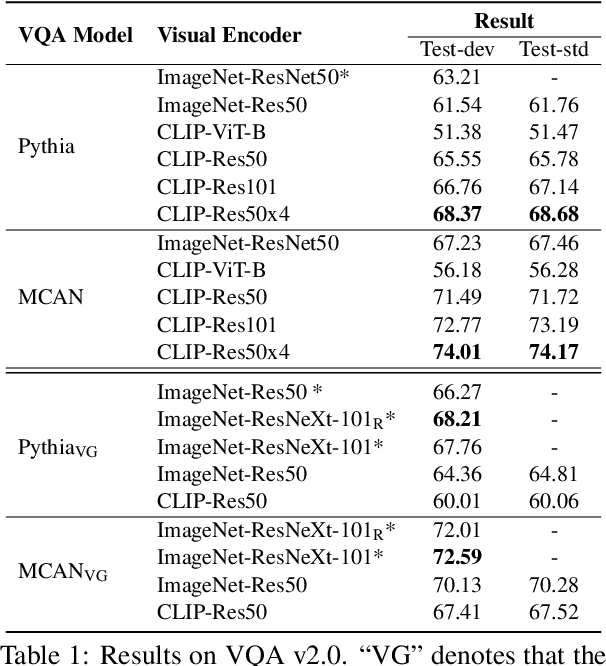
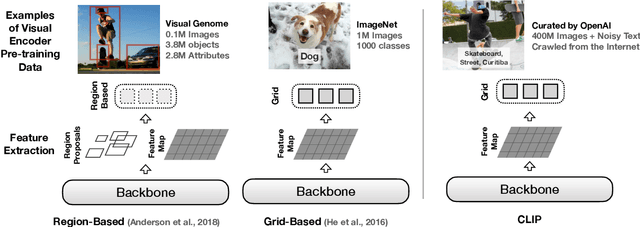
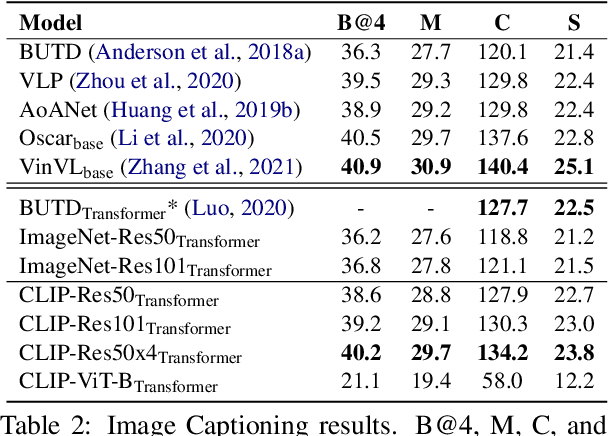
Most existing Vision-and-Language (V&L) models rely on pre-trained visual encoders, using a relatively small set of manually-annotated data (as compared to web-crawled data), to perceive the visual world. However, it has been observed that large-scale pretraining usually can result in better generalization performance, e.g., CLIP (Contrastive Language-Image Pre-training), trained on a massive amount of image-caption pairs, has shown a strong zero-shot capability on various vision tasks. To further study the advantage brought by CLIP, we propose to use CLIP as the visual encoder in various V&L models in two typical scenarios: 1) plugging CLIP into task-specific fine-tuning; 2) combining CLIP with V&L pre-training and transferring to downstream tasks. We show that CLIP significantly outperforms widely-used visual encoders trained with in-domain annotated data, such as BottomUp-TopDown. We achieve competitive or better results on diverse V&L tasks, while establishing new state-of-the-art results on Visual Question Answering, Visual Entailment, and V&L Navigation tasks. We release our code at https://github.com/clip-vil/CLIP-ViL.
Predicting Driver Self-Reported Stress by Analyzing the Road Scene
Sep 27, 2021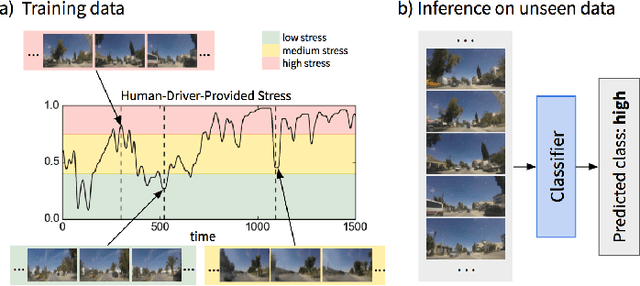
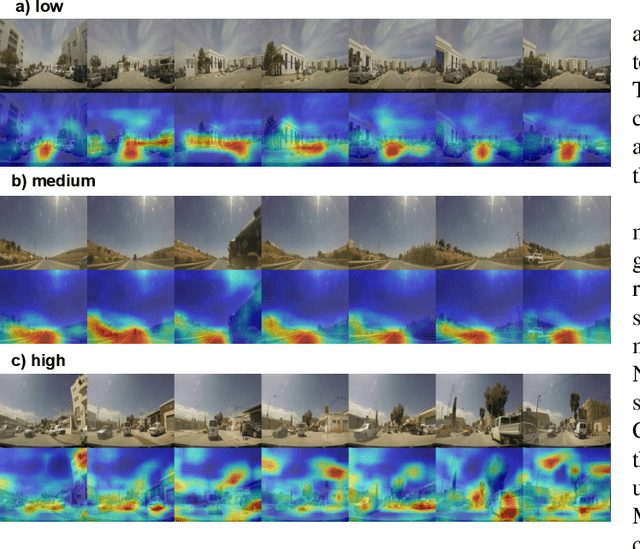
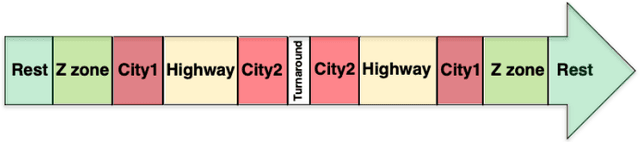
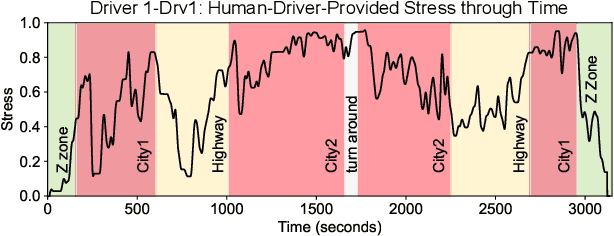
Several studies have shown the relevance of biosignals in driver stress recognition. In this work, we examine something important that has been less frequently explored: We develop methods to test if the visual driving scene can be used to estimate a drivers' subjective stress levels. For this purpose, we use the AffectiveROAD video recordings and their corresponding stress labels, a continuous human-driver-provided stress metric. We use the common class discretization for stress, dividing its continuous values into three classes: low, medium, and high. We design and evaluate three computer vision modeling approaches to classify the driver's stress levels: (1) object presence features, where features are computed using automatic scene segmentation; (2) end-to-end image classification; and (3) end-to-end video classification. All three approaches show promising results, suggesting that it is possible to approximate the drivers' subjective stress from the information found in the visual scene. We observe that the video classification, which processes the temporal information integrated with the visual information, obtains the highest accuracy of $0.72$, compared to a random baseline accuracy of $0.33$ when tested on a set of nine drivers.
Automatic techniques for cochlear implant CT image analysis
Sep 23, 2019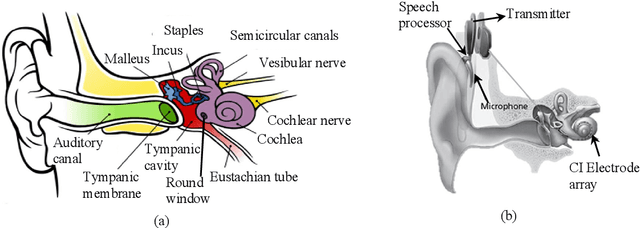
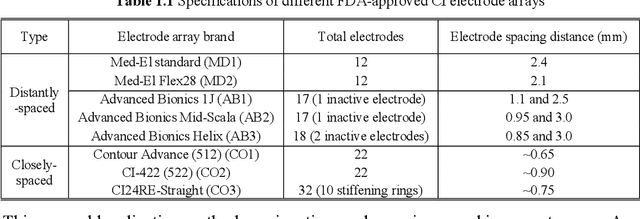
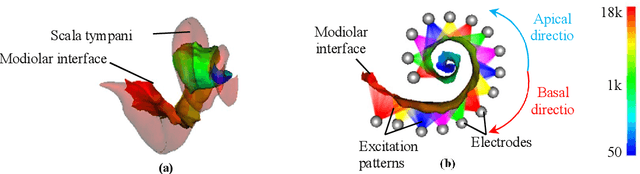
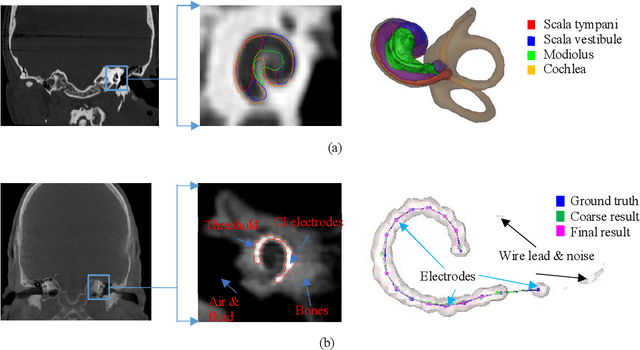
The goals of this dissertation are to fully automate the image processing techniques needed in the post-operative stage of IGCIP and to perform a thorough analysis of (a) the robustness of the automatic image processing techniques used in IGCIP and (b) assess the sensitivity of the IGCIP process as a whole to individual components. The automatic methods that have been developed include the automatic localization of both closely- and distantly-spaced CI electrode arrays in post-implantation CTs and the automatic selection of electrode configurations based on the stimulation patterns. Together with the existing automatic techniques developed for IGCIP, the proposed automatic methods enable an end-to-end IGCIP process that takes pre- and post-implantation CT images as input and produces a patient-customized electrode configuration as output.
Image-based Vehicle Re-identification Model with Adaptive Attention Modules and Metadata Re-ranking
Jul 03, 2020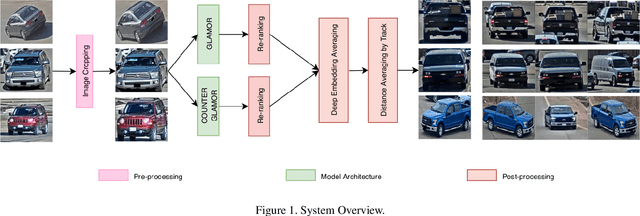
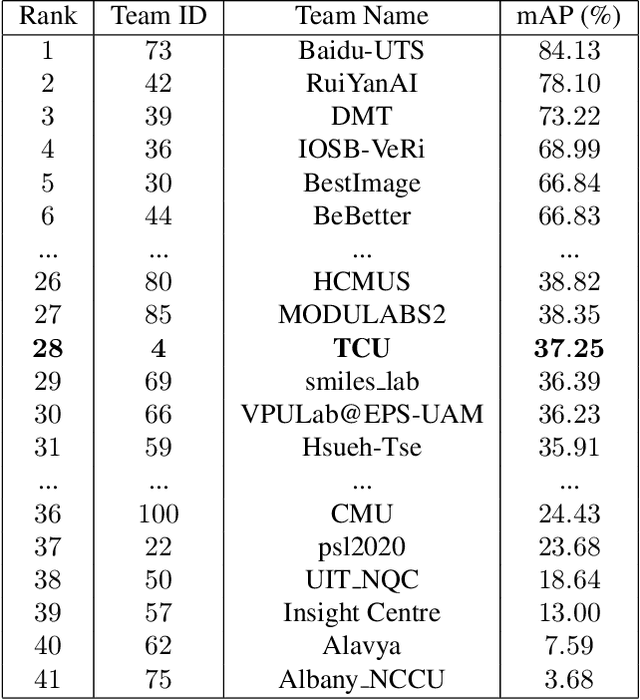

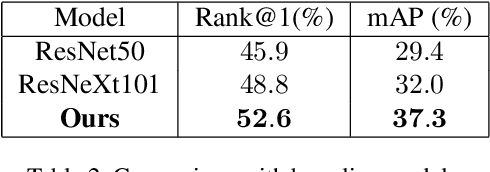
Vehicle Re-identification is a challenging task due to intra-class variability and inter-class similarity across non-overlapping cameras. To tackle these problems, recently proposed methods require additional annotation to extract more features for false positive image exclusion. In this paper, we propose a model powered by adaptive attention modules that requires fewer label annotations but still out-performs the previous models. We also include a re-ranking method that takes account of the importance of metadata feature embeddings in our paper. The proposed method is evaluated on CVPR AI City Challenge 2020 dataset and achieves mAP of 37.25% in Track 2.
N15News: A New Dataset for Multimodal News Classification
Aug 30, 2021
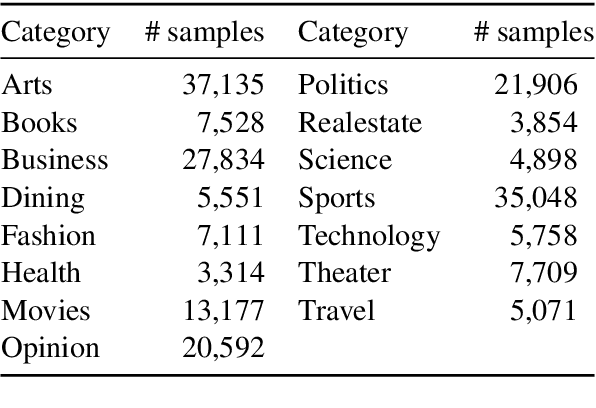
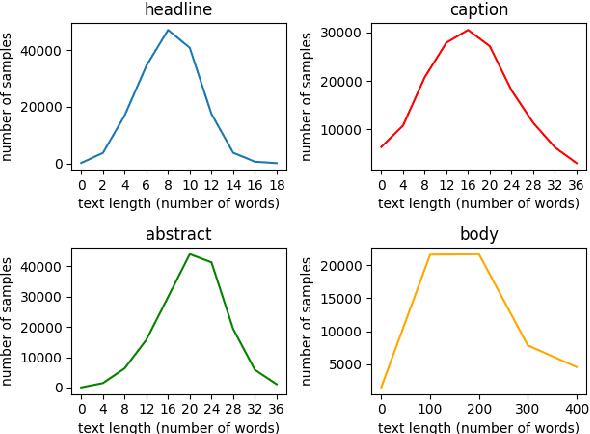

Current news datasets merely focus on text features on the news and rarely leverage the feature of images, excluding numerous essential features for news classification. In this paper, we propose a new dataset, N15News, which is generated from New York Times with 15 categories and contains both text and image information in each news. We design a novel multitask multimodal network with different fusion methods, and experiments show multimodal news classification performs better than text-only news classification. Depending on the length of the text, the classification accuracy can be increased by up to 5.8%. Our research reveals the relationship between the performance of a multimodal classifier and its sub-classifiers, and also the possible improvements when applying multimodal in news classification. N15News is shown to have great potential to prompt the multimodal news studies.
The First Airborne Experiment of Sparse Microwave Imaging: Prototype System Design and Result Analysis
Oct 20, 2021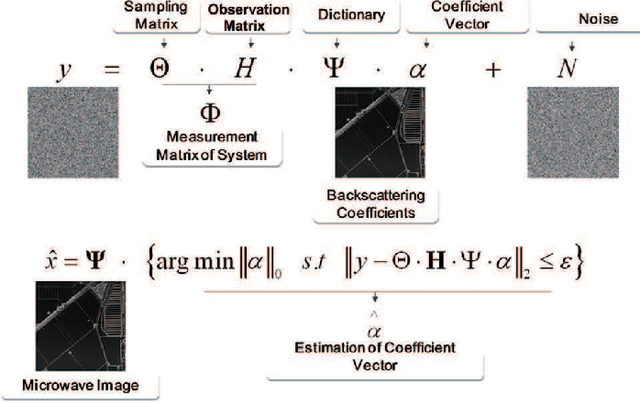
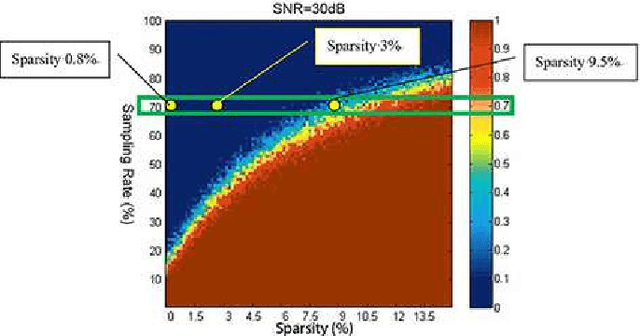


In this paper we report the first airborne experiments of sparse microwave imaging, conducted in September 2013 and May 2014, using our prototype sparse microwave imaging radar system. This is the first reported imaging radar system and airborne experiment that specially designed for sparse microwave imaging. Sparse microwave imaging is a novel concept of radar imaging, it is mainly the combination of traditional radar imaging technology and newly developed sparse signal processing theory, achieving benefits in both improving the imaging quality of current microwave imaging systems and designing optimized sparse microwave imaging radar system to reduce system sampling rate towards the sparse target scenes. During recent years, many researchers focus on related topics of sparse microwave imaging, but rarely few paid attention to prototype system design and experiment. We introduce our prototype sparse microwave imaging radar system, including its system design, hardware considerations and signal processing methods. Several design principles should be considered during the system designing, including the sampling scheme, antenna, SNR, waveform, resolution, etc. We select jittered sampling in azimuth and uniform sampling in range to balance the system complexity and performance. The imaging algorithm is accelerated $\ell_q$ regularization algorithm. To test the prototype radar system and verify the effectiveness of sparse microwave imaging framework, airborne experiments are carried out using our prototype system and we achieve the first sparse microwave image successfully. We analyze the imaging performance of prototype sparse microwave radar system with different sparsities, sampling rates, SNRs and sampling schemes, using three-dimensional phase transit diagram as the evaluation tool.
Character Spotting Using Machine Learning Techniques
Jul 28, 2021
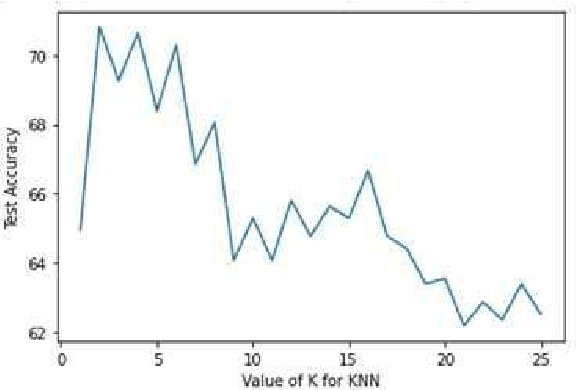
This work presents a comparison of machine learning algorithms that are implemented to segment the characters of text presented as an image. The algorithms are designed to work on degraded documents with text that is not aligned in an organized fashion. The paper investigates the use of Support Vector Machines, K-Nearest Neighbor algorithm and an Encoder Network to perform the operation of character spotting. Character Spotting involves extracting potential characters from a stream of text by selecting regions bound by white space.
Text-based Person Search in Full Images via Semantic-Driven Proposal Generation
Sep 27, 2021
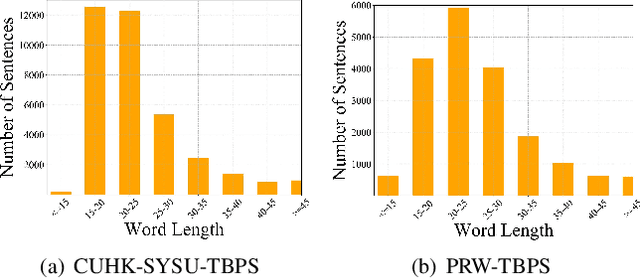

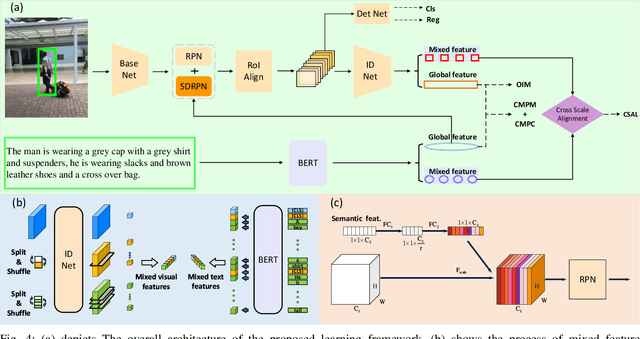
Finding target persons in full scene images with a query of text description has important practical applications in intelligent video surveillance.However, different from the real-world scenarios where the bounding boxes are not available, existing text-based person retrieval methods mainly focus on the cross modal matching between the query text descriptions and the gallery of cropped pedestrian images. To close the gap, we study the problem of text-based person search in full images by proposing a new end-to-end learning framework which jointly optimize the pedestrian detection, identification and visual-semantic feature embedding tasks. To take full advantage of the query text, the semantic features are leveraged to instruct the Region Proposal Network to pay more attention to the text-described proposals. Besides, a cross-scale visual-semantic embedding mechanism is utilized to improve the performance. To validate the proposed method, we collect and annotate two large-scale benchmark datasets based on the widely adopted image-based person search datasets CUHK-SYSU and PRW. Comprehensive experiments are conducted on the two datasets and compared with the baseline methods, our method achieves the state-of-the-art performance.
Compatible and Diverse Fashion Image Inpainting
Feb 04, 2019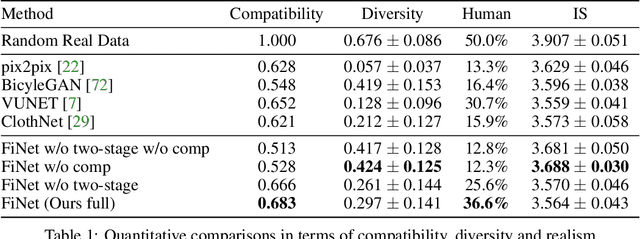
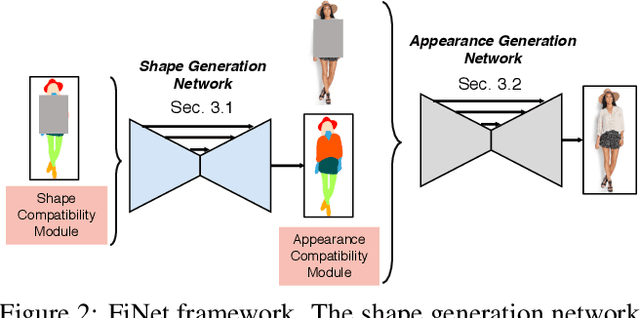
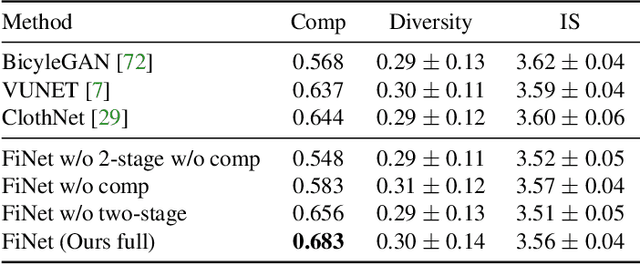
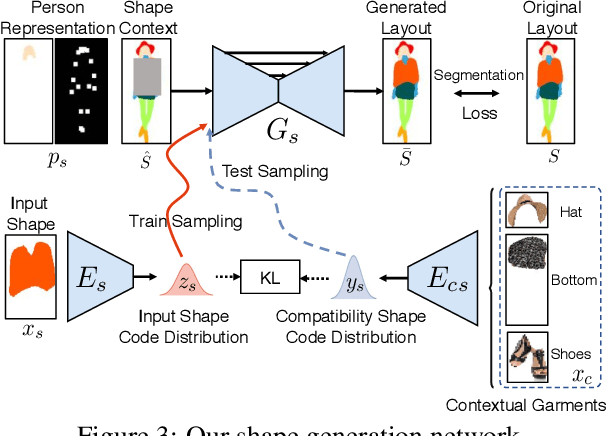
Visual compatibility is critical for fashion analysis, yet is missing in existing fashion image synthesis systems. In this paper, we propose to explicitly model visual compatibility through fashion image inpainting. To this end, we present Fashion Inpainting Networks (FiNet), a two-stage image-to-image generation framework that is able to perform compatible and diverse inpainting. Disentangling the generation of shape and appearance to ensure photorealistic results, our framework consists of a shape generation network and an appearance generation network. More importantly, for each generation network, we introduce two encoders interacting with one another to learn latent code in a shared compatibility space. The latent representations are jointly optimized with the corresponding generation network to condition the synthesis process, encouraging a diverse set of generated results that are visually compatible with existing fashion garments. In addition, our framework is readily extended to clothing reconstruction and fashion transfer, with impressive results. Extensive experiments with comparisons with state-of-the-art approaches on fashion synthesis task quantitatively and qualitatively demonstrate the effectiveness of our method.
Learning Image-Specific Attributes by Hyperbolic Neighborhood Graph Propagation
May 25, 2019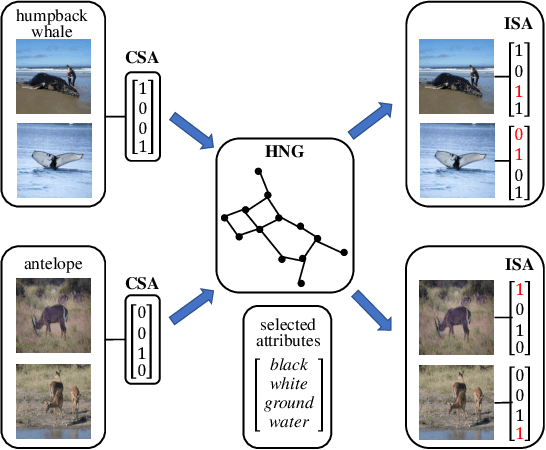
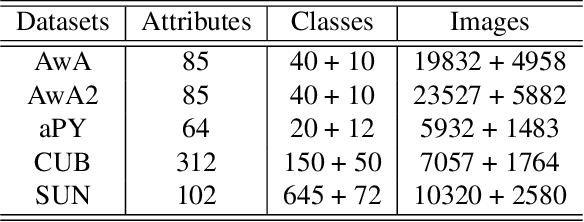
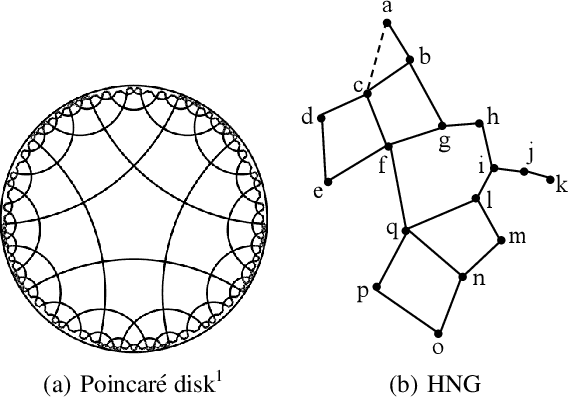
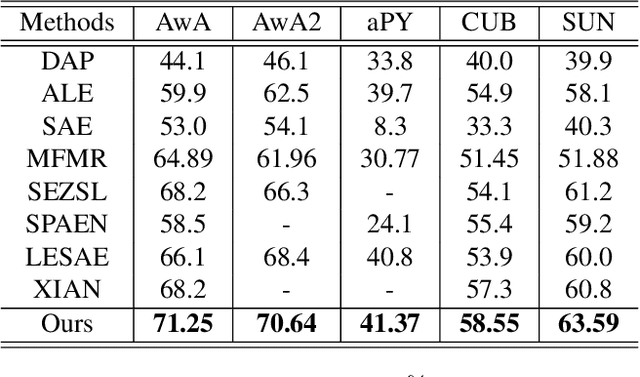
As a kind of semantic representation of visual object descriptions, attributes are widely used in various computer vision tasks. In most of existing attribute-based research, class-specific attributes (CSA), which are class-level annotations, are usually adopted due to its low annotation cost for each class instead of each individual image. However, class-specific attributes are usually noisy because of annotation errors and diversity of individual images. Therefore, it is desirable to obtain image-specific attributes (ISA), which are image-level annotations, from the original class-specific attributes. In this paper, we propose to learn image-specific attributes by graph-based attribute propagation. Considering the intrinsic property of hyperbolic geometry that its distance expands exponentially, hyperbolic neighborhood graph (HNG) is constructed to characterize the relationship between samples. Based on HNG, we define neighborhood consistency for each sample to identify inconsistent samples. Subsequently, inconsistent samples are refined based on their neighbors in HNG. Extensive experiments on five benchmark datasets demonstrate the significant superiority of the learned image-specific attributes over the original class-specific attributes in the zero-shot object classification task.