 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHALA-LLM: Smartly Handling Ambiguous Labels in Aligning LLMs
Jun 03, 2026Many human-centered tasks, including natural language inference (NLI) and emotion recognition (ER), have multiple plausible interpretations, leading to label ambiguity and challenging disagreements across human annotators. As LLMs are increasingly deployed in real-world settings, faithfully modeling such ambiguity is essential to identify contested inputs, preserve variability in ambiguous cases, and capture the full distribution of human judgments. Yet, existing LLM alignment approaches have predominantly assumed a single correct label, excluding annotator disagreement during optimization. Instead of treating this ambiguity as noise, we show how to treat it as information that improves model behavior through a new algorithm called SMARTLY HANDLING AMBIGUOUS LABELS IN ALIGNING LLMS (SHALA-LLM). This reinforcement learning framework provides a new way for LLMs to learn directly from annotator distributions while dynamically prioritizing highly ambiguous samples during optimization. Experiments on ambiguity-sensitive NLI and ER benchmarks, including ChaosNLI, GoEmotions, and MSP-Podcast, demonstrate that SHALA-LLM improves agreement with annotator label distributions, e.g. on ChaosNLI, it reduces Jensen-Shannon Distance by up to 62.1%. At the same time, SHALA-LLM improves F1 by up to 16.7%, showing that modeling annotator disagreement can also strengthen classification performance.
AmbER$^2$: Dual Ambiguity-Aware Emotion Recognition Applied to Speech and Text
Jan 25, 2026Emotion recognition is inherently ambiguous, with uncertainty arising both from rater disagreement and from discrepancies across modalities such as speech and text. There is growing interest in modeling rater ambiguity using label distributions. However, modality ambiguity remains underexplored, and multimodal approaches often rely on simple feature fusion without explicitly addressing conflicts between modalities. In this work, we propose AmbER$^2$, a dual ambiguity-aware framework that simultaneously models rater-level and modality-level ambiguity through a teacher-student architecture with a distribution-wise training objective. Evaluations on IEMOCAP and MSP-Podcast show that AmbER$^2$ consistently improves distributional fidelity over conventional cross-entropy baselines and achieves performance competitive with, or superior to, recent state-of-the-art systems. For example, on IEMOCAP, AmbER$^2$ achieves relative improvements of 20.3% on Bhattacharyya coefficient (0.83 vs. 0.69), 13.6% on R$^2$ (0.67 vs. 0.59), 3.8% on accuracy (0.683 vs. 0.658), and 4.5% on F1 (0.675 vs. 0.646). Further analysis across ambiguity levels shows that explicitly modeling ambiguity is particularly beneficial for highly uncertain samples. These findings highlight the importance of jointly addressing rater and modality ambiguity when building robust emotion recognition systems.
Classifying Phonotrauma Severity from Vocal Fold Images with Soft Ordinal Regression
Nov 12, 2025



Phonotrauma refers to vocal fold tissue damage resulting from exposure to forces during voicing. It occurs on a continuum from mild to severe, and treatment options can vary based on severity. Assessment of severity involves a clinician's expert judgment, which is costly and can vary widely in reliability. In this work, we present the first method for automatically classifying phonotrauma severity from vocal fold images. To account for the ordinal nature of the labels, we adopt a widely used ordinal regression framework. To account for label uncertainty, we propose a novel modification to ordinal regression loss functions that enables them to operate on soft labels reflecting annotator rating distributions. Our proposed soft ordinal regression method achieves predictive performance approaching that of clinical experts, while producing well-calibrated uncertainty estimates. By providing an automated tool for phonotrauma severity assessment, our work can enable large-scale studies of phonotrauma, ultimately leading to improved clinical understanding and patient care.
Resonance: Drawing from Memories to Imagine Positive Futures through AI-Augmented Journaling
Mar 31, 2025



People inherently use experiences of their past while imagining their future, a capability that plays a crucial role in mental health. Resonance is an AI-powered journaling tool designed to augment this ability by offering AI-generated, action-oriented suggestions for future activities based on the user's own past memories. Suggestions are offered when a new memory is logged and are followed by a prompt for the user to imagine carrying out the suggestion. In a two-week randomized controlled study (N=55), we found that using Resonance significantly improved mental health outcomes, reducing the users' PHQ8 scores, a measure of current depression, and increasing their daily positive affect, particularly when they would likely act on the suggestion. Notably, the effectiveness of the suggestions was higher when they were personal, novel, and referenced the user's logged memories. Finally, through open-ended feedback, we discuss the factors that encouraged or hindered the use of the tool.
* 17 pages, 13 figures
A HeARTfelt Robot: Social Robot-Driven Deep Emotional Art Reflection with Children
Sep 16, 2024



Social-emotional learning (SEL) skills are essential for children to develop to provide a foundation for future relational and academic success. Using art as a medium for creation or as a topic to provoke conversation is a well-known method of SEL learning. Similarly, social robots have been used to teach SEL competencies like empathy, but the combination of art and social robotics has been minimally explored. In this paper, we present a novel child-robot interaction designed to foster empathy and promote SEL competencies via a conversation about art scaffolded by a social robot. Participants (N=11, age range: 7-11) conversed with a social robot about emotional and neutral art. Analysis of video and speech data demonstrated that this interaction design successfully engaged children in the practice of SEL skills, like emotion recognition and self-awareness, and greater rates of empathetic reasoning were observed when children engaged with the robot about emotional art. This study demonstrated that art-based reflection with a social robot, particularly on emotional art, can foster empathy in children, and interactions with a social robot help alleviate discomfort when sharing deep or vulnerable emotions.
Multipar-T: Multiparty-Transformer for Capturing Contingent Behaviors in Group Conversations
Apr 19, 2023



As we move closer to real-world AI systems, AI agents must be able to deal with multiparty (group) conversations. Recognizing and interpreting multiparty behaviors is challenging, as the system must recognize individual behavioral cues, deal with the complexity of multiple streams of data from multiple people, and recognize the subtle contingent social exchanges that take place amongst group members. To tackle this challenge, we propose the Multiparty-Transformer (Multipar-T), a transformer model for multiparty behavior modeling. The core component of our proposed approach is the Crossperson Attention, which is specifically designed to detect contingent behavior between pairs of people. We verify the effectiveness of Multipar-T on a publicly available video-based group engagement detection benchmark, where it outperforms state-of-the-art approaches in average F-1 scores by 5.2% and individual class F-1 scores by up to 10.0%. Through qualitative analysis, we show that our Crossperson Attention module is able to discover contingent behavior.
Mixed Effects Random Forests for Personalised Predictions of Clinical Depression Severity
Jan 24, 2023



This work demonstrates how mixed effects random forests enable accurate predictions of depression severity using multimodal physiological and digital activity data collected from an 8-week study involving 31 patients with major depressive disorder. We show that mixed effects random forests outperform standard random forests and personal average baselines when predicting clinical Hamilton Depression Rating Scale scores (HDRS_17). Compared to the latter baseline, accuracy is significantly improved for each patient by an average of 0.199-0.276 in terms of mean absolute error (p<0.05). This is noteworthy as these simple baselines frequently outperform machine learning methods in mental health prediction tasks. We suggest that this improved performance results from the ability of the mixed effects random forest to personalise model parameters to individuals in the dataset. However, we find that these improvements pertain exclusively to scenarios where labelled patient data are available to the model at training time. Investigating methods that improve accuracy when generalising to new patients is left as important future work.
Computational Empathy Counteracts the Negative Effects of Anger on Creative Problem Solving
Aug 15, 2022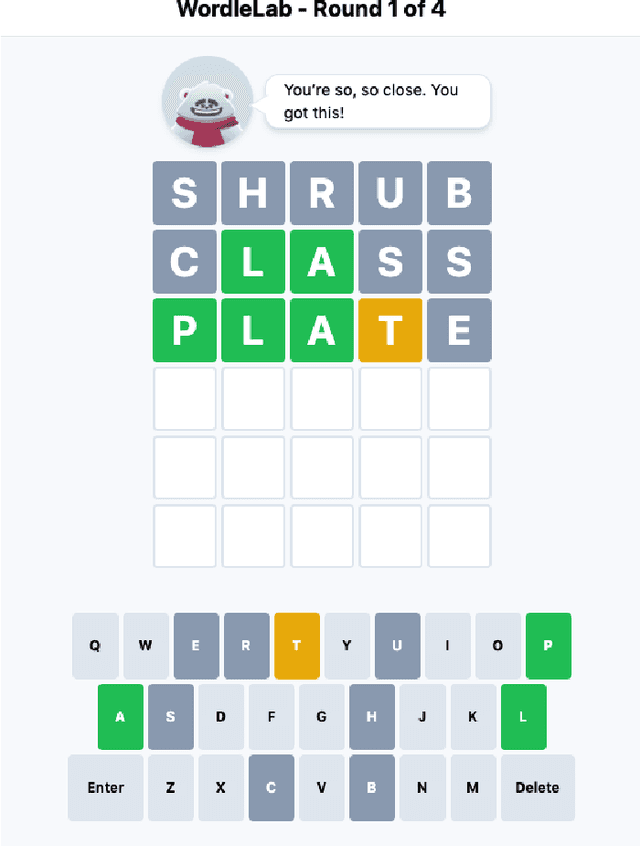

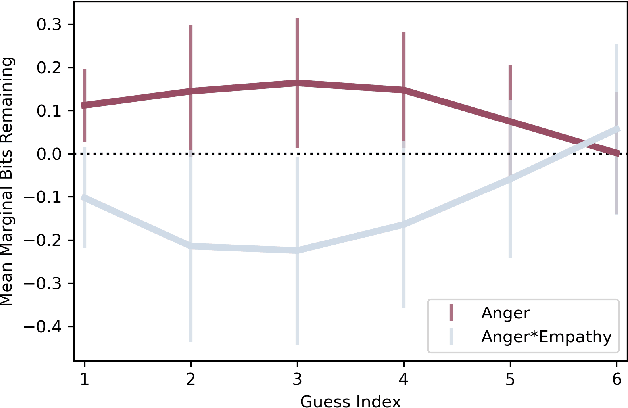
How does empathy influence creative problem solving? We introduce a computational empathy intervention based on context-specific affective mimicry and perspective taking by a virtual agent appearing in the form of a well-dressed polar bear. In an online experiment with 1,006 participants randomly assigned to an emotion elicitation intervention (with a control elicitation condition and anger elicitation condition) and a computational empathy intervention (with a control virtual agent and an empathic virtual agent), we examine how anger and empathy influence participants' performance in solving a word game based on Wordle. We find participants who are assigned to the anger elicitation condition perform significantly worse on multiple performance metrics than participants assigned to the control condition. However, we find the empathic virtual agent counteracts the drop in performance induced by the anger condition such that participants assigned to both the empathic virtual agent and the anger condition perform no differently than participants in the control elicitation condition and significantly better than participants assigned to the control virtual agent and the anger elicitation condition. While empathy reduces the negative effects of anger, we do not find evidence that the empathic virtual agent influences performance of participants who are assigned to the control elicitation condition. By introducing a framework for computational empathy interventions and conducting a two-by-two factorial design randomized experiment, we provide rigorous, empirical evidence that computational empathy can counteract the negative effects of anger on creative problem solving.
Human Detection of Political Deepfakes across Transcripts, Audio, and Video
Feb 25, 2022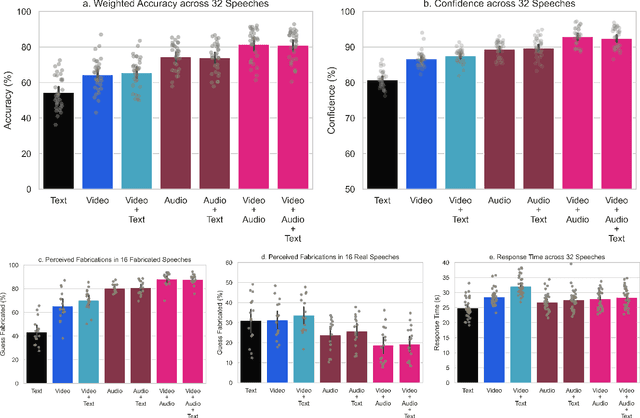

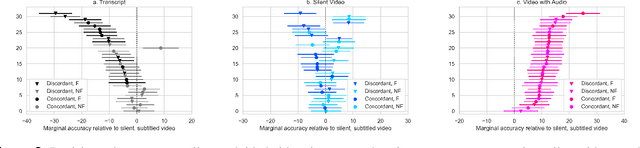
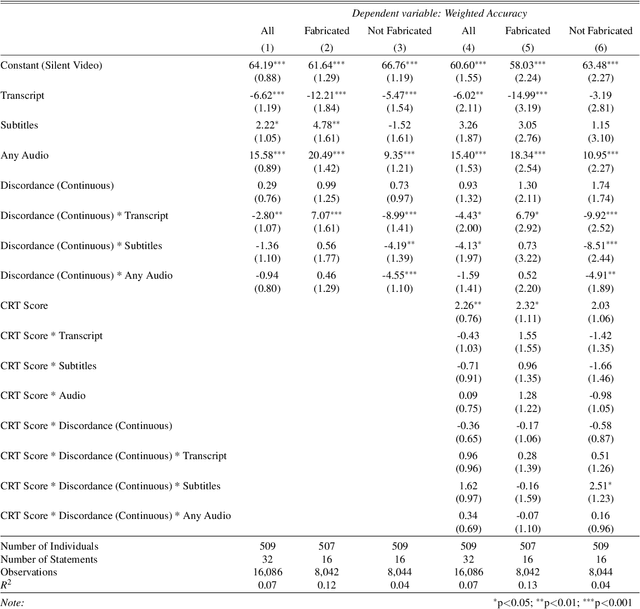
Recent advances in technology for hyper-realistic visual effects provoke the concern that deepfake videos of political speeches will soon be visually indistinguishable from authentic video recordings. Yet there exists little empirical research on how audio-visual information influences people's susceptibility to fall for political misinformation. The conventional wisdom in the field of communication research predicts that people will fall for fake news more often when the same version of a story is presented as a video as opposed to text. However, audio-visual manipulations often leave distortions that some but not all people may pick up on. Here, we evaluate how communication modalities influence people's ability to discern real political speeches from fabrications based on a randomized experiment with 5,727 participants who provide 61,792 truth discernment judgments. We show participants soundbites from political speeches that are randomly assigned to appear using permutations of text, audio, and video modalities. We find that communication modalities mediate discernment accuracy: participants are more accurate on video with audio than silent video, and more accurate on silent video than text transcripts. Likewise, we find participants rely more on how something is said (the audio-visual cues) rather than what is said (the speech content itself). However, political speeches that do not match public perceptions of politicians' beliefs reduce participants' reliance on visual cues. In particular, we find that reflective reasoning moderates the degree to which participants consider visual information: low performance on the Cognitive Reflection Test is associated with an underreliance on visual cues and an overreliance on what is said.
Predicting Driver Self-Reported Stress by Analyzing the Road Scene
Sep 27, 2021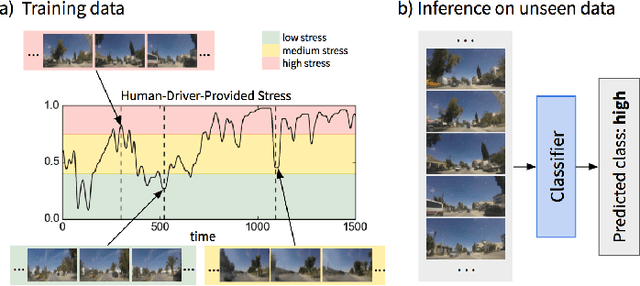
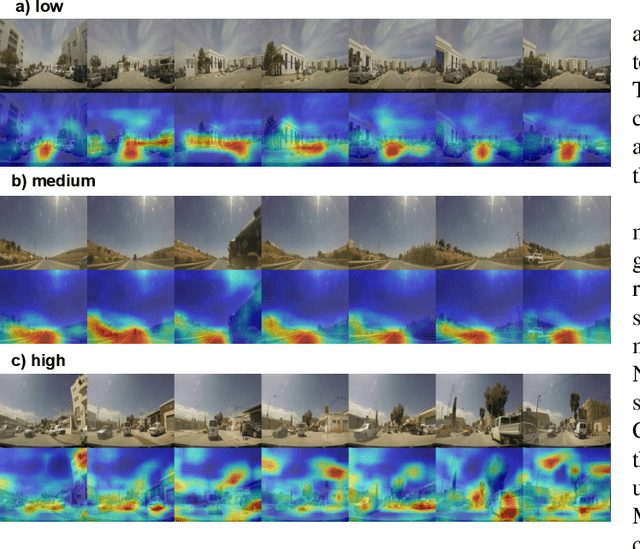
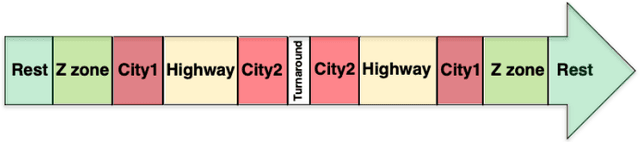
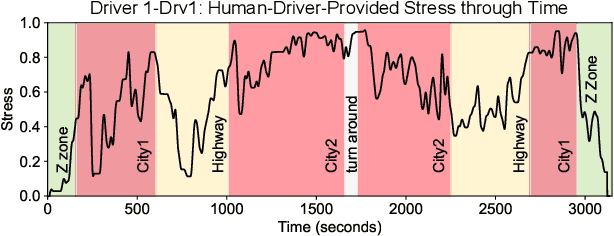
Several studies have shown the relevance of biosignals in driver stress recognition. In this work, we examine something important that has been less frequently explored: We develop methods to test if the visual driving scene can be used to estimate a drivers' subjective stress levels. For this purpose, we use the AffectiveROAD video recordings and their corresponding stress labels, a continuous human-driver-provided stress metric. We use the common class discretization for stress, dividing its continuous values into three classes: low, medium, and high. We design and evaluate three computer vision modeling approaches to classify the driver's stress levels: (1) object presence features, where features are computed using automatic scene segmentation; (2) end-to-end image classification; and (3) end-to-end video classification. All three approaches show promising results, suggesting that it is possible to approximate the drivers' subjective stress from the information found in the visual scene. We observe that the video classification, which processes the temporal information integrated with the visual information, obtains the highest accuracy of $0.72$, compared to a random baseline accuracy of $0.33$ when tested on a set of nine drivers.