 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter Spotting Using Machine Learning Techniques
Jul 28, 2021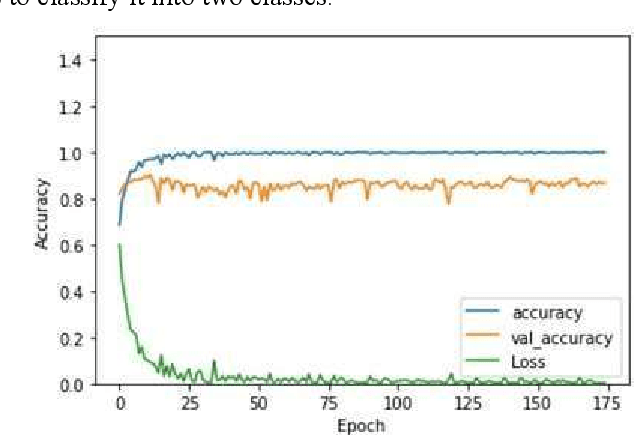
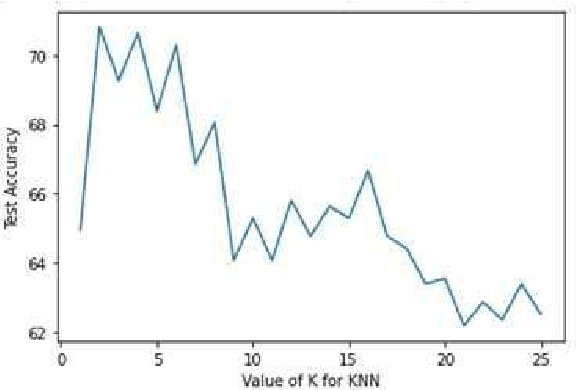
This work presents a comparison of machine learning algorithms that are implemented to segment the characters of text presented as an image. The algorithms are designed to work on degraded documents with text that is not aligned in an organized fashion. The paper investigates the use of Support Vector Machines, K-Nearest Neighbor algorithm and an Encoder Network to perform the operation of character spotting. Character Spotting involves extracting potential characters from a stream of text by selecting regions bound by white space.
Denoising and Segmentation of Epigraphical Scripts
Jul 25, 2021

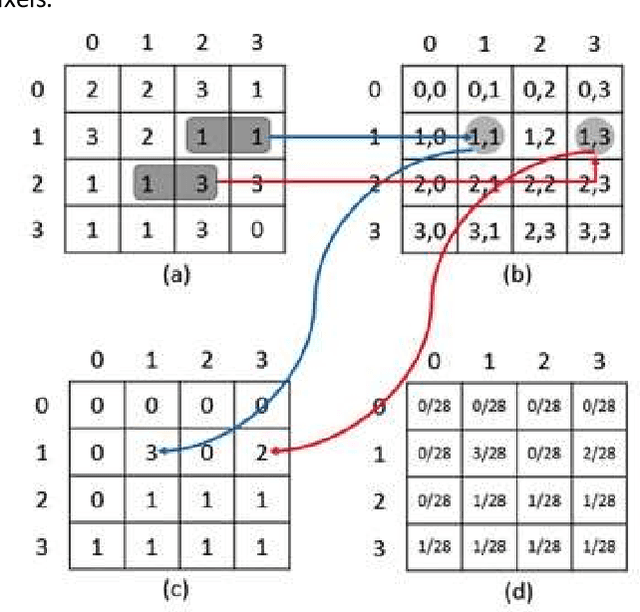
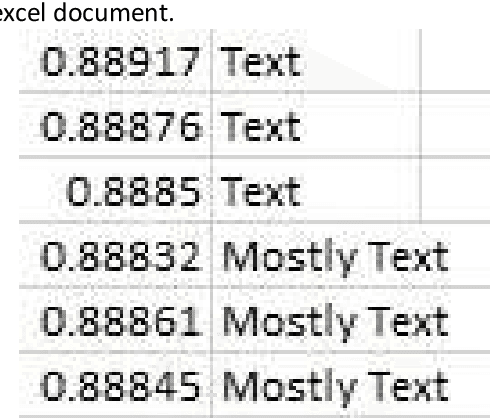
This paper is a presentation of a new method for denoising images using Haralick features and further segmenting the characters using artificial neural networks. The image is divided into kernels, each of which is converted to a GLCM (Gray Level Co-Occurrence Matrix) on which a Haralick Feature generation function is called, the result of which is an array with fourteen elements corresponding to fourteen features The Haralick values and the corresponding noise/text classification form a dictionary, which is then used to de-noise the image through kernel comparison. Segmentation is the process of extracting characters from a document and can be used when letters are separated by white space, which is an explicit boundary marker. Segmentation is the first step in many Natural Language Processing problems. This paper explores the process of segmentation using Neural Networks. While there have been numerous methods to segment characters of a document, this paper is only concerned with the accuracy of doing so using neural networks. It is imperative that the characters be segmented correctly, for failing to do so will lead to incorrect recognition by Natural language processing tools. Artificial Neural Networks was used to attain accuracy of upto 89%. This method is suitable for languages where the characters are delimited by white space. However, this method will fail to provide acceptable results when the language heavily uses connected letters. An example would be the Devanagari script, which is predominantly used in northern India.