 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unifying Deep Local and Global Features for Efficient Image Search
Jan 14, 2020
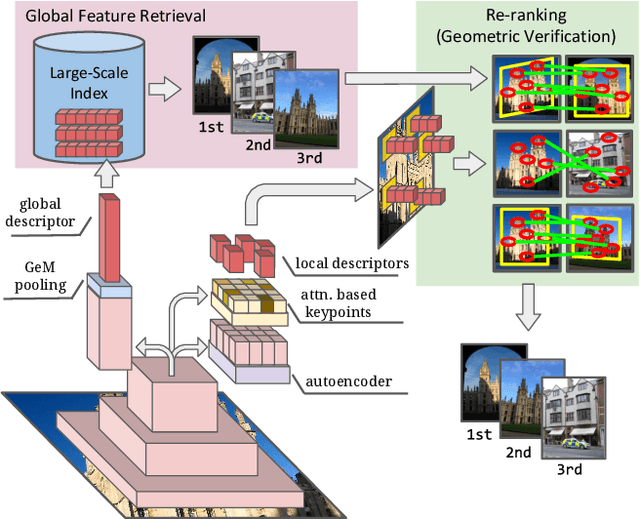

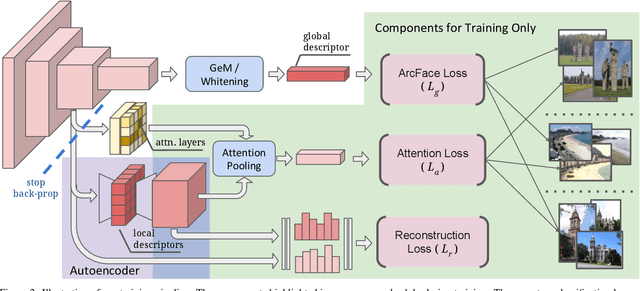
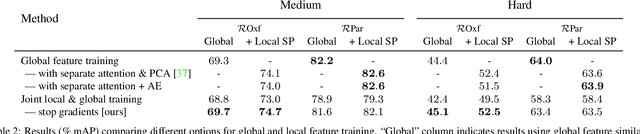
A key challenge in large-scale image retrieval problems is the trade-off between scalability and accuracy. Recent research has made great strides to improve scalability with compact global image features, and accuracy with local image features. In this work, our main contribution is to unify global and local image features into a single deep model, enabling scalable retrieval with high accuracy. We refer to the new model as DELG, standing for DEep Local and Global features. We leverage lessons from recent feature learning work and propose a model that combines generalized mean pooling for global features and attentive selection for local features. The entire network can be learned end-to-end by carefully balancing the gradient flow between two heads -- requiring only image-level labels. We also introduce an autoencoder-based dimensionality reduction technique for local features, which is integrated into the model, improving training efficiency and matching performance. Experiments on the Revisited Oxford and Paris datasets demonstrate that our jointly learned ResNet-50 based features outperform all previous results using deep global features (most with heavier backbones) and those that further re-rank with local features. Code and models will be released.
DeepRelativeFusion: Dense Monocular SLAM using Single-Image Relative Depth Prediction
Jun 07, 2020
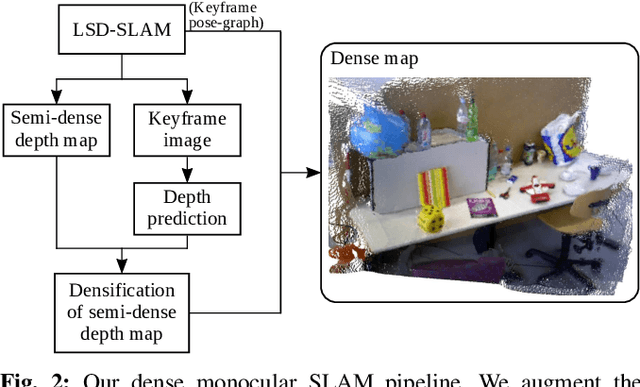
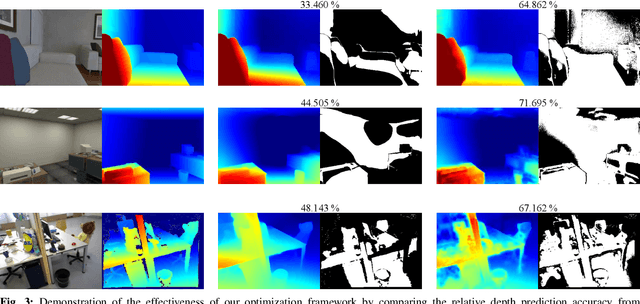
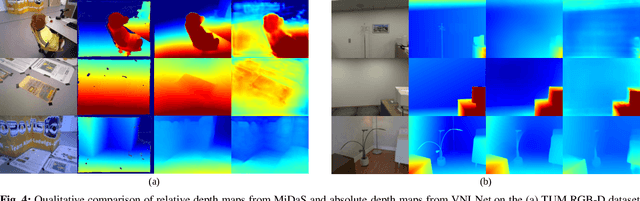
Traditional monocular visual simultaneous localization and mapping (SLAM) algorithms have been extensively studied and proven to reliably recover a sparse structure and camera motion. Nevertheless, the sparse structure is still insufficient for scene interaction, e.g., visual navigation and augmented reality applications. To densify the scene reconstruction, the use of single-image absolute depth prediction from convolutional neural networks (CNNs) for filling in the missing structure has been proposed. However, the prediction accuracy tends to not generalize well on scenes that are different from the training datasets. In this paper, we propose a dense monocular SLAM system, named DeepRelativeFusion, that is capable to recover a globally consistent 3D structure. To this end, we use a visual SLAM algorithm to reliably recover the camera poses and semi-dense depth maps of the keyframes, and then combine the keyframe pose-graph with the densified keyframe depth maps to reconstruct the scene. To perform the densification, we introduce two incremental improvements upon the energy minimization framework proposed by DeepFusion: (1) an additional image gradient term in the cost function, and (2) the use of single-image relative depth prediction. Despite the absence of absolute scale and depth range, the relative depth maps can be corrected using their respective semi-dense depth maps from the SLAM algorithm. We show that the corrected relative depth maps are sufficiently accurate to be used as priors for the densification. To demonstrate the generalizability of relative depth prediction, we illustrate qualitatively the dense reconstruction on two outdoor sequences. Our system also outperforms the state-of-the-art dense SLAM systems quantitatively in dense reconstruction accuracy by a large margin.
SMIT: Stochastic Multi-Label Image-to-Image Translation
Dec 10, 2018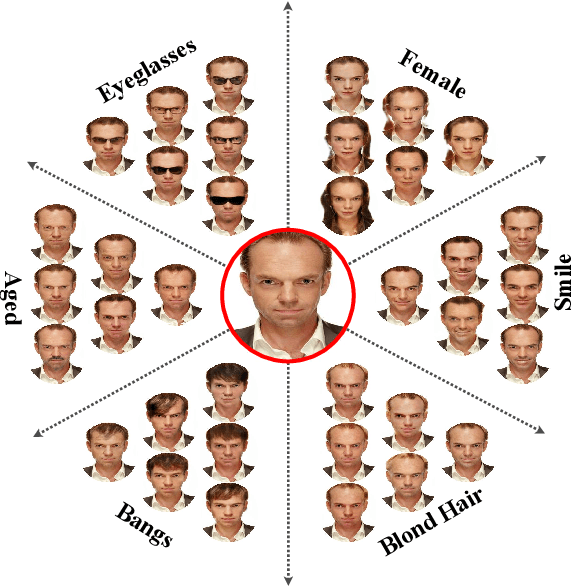

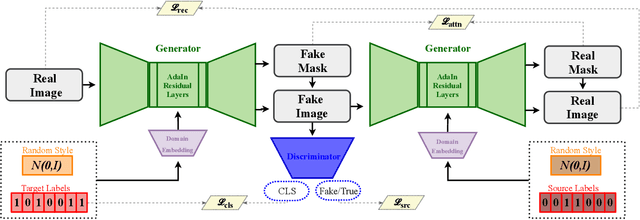
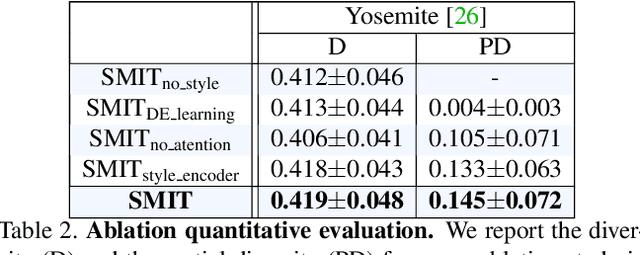
Cross-domain mapping has been a very active topic in recent years. Given one image, its main purpose is to translate it to the desired target domain, or multiple domains in the case of multiple labels. This problem is highly challenging due to three main reasons: (i) unpaired datasets, (ii) multiple attributes, and (iii) the multimodality associated with the translation. Most of the existing state-of-the-art has focused only on two reasons, i.e. producing disentangled representations from unpaired datasets in a one-to-one domain translation or producing multiple unimodal attributes from unpaired datasets. In this work, we propose a joint framework of diversity and multi-mapping image-to-image translations, using a single generator to conditionally produce countless and unique fake images that hold the underlying characteristics of the source image. Extensive experiments over different datasets demonstrate the effectiveness of our proposed approach with comparisons to the state-of-the-art in both multi-label and multimodal problems. Additionally, our method is able to generalize under different scenarios: continuous style interpolation, continuous label interpolation, and multi-label mapping.
Learning Spatially Structured Image Transformations Using Planar Neural Networks
Dec 03, 2019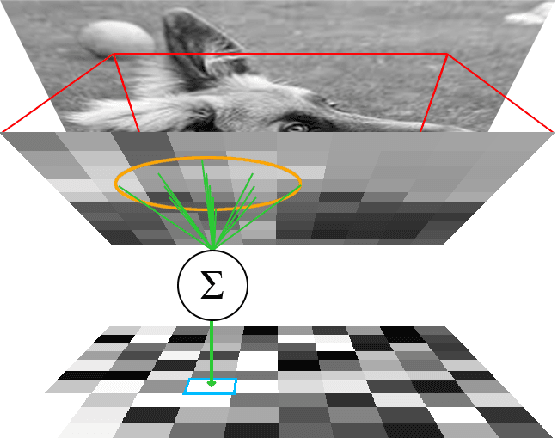

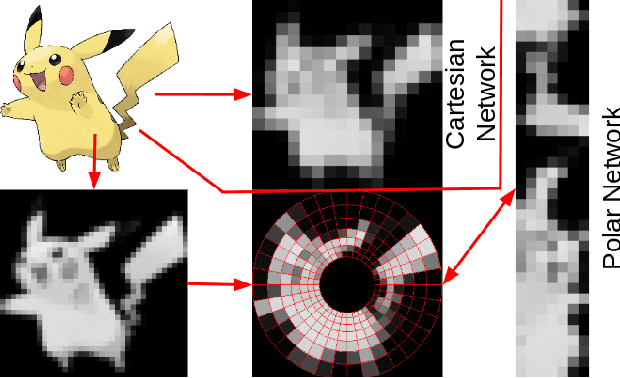
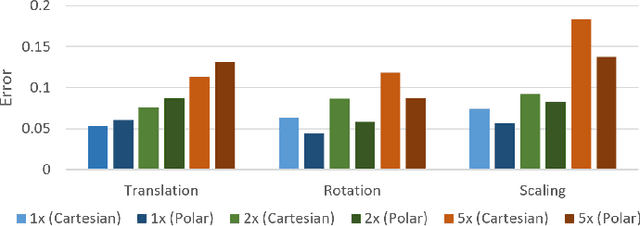
Learning image transformations is essential to the idea of mental simulation as a method of cognitive inference. We take a connectionist modeling approach, using planar neural networks to learn fundamental imagery transformations, like translation, rotation, and scaling, from perceptual experiences in the form of image sequences. We investigate how variations in network topology, training data, and image shape, among other factors, affect the efficiency and effectiveness of learning visual imagery transformations, including effectiveness of transfer to operating on new types of data.
Image Segmentation of Zona-Ablated Human Blastocysts
Aug 19, 2020

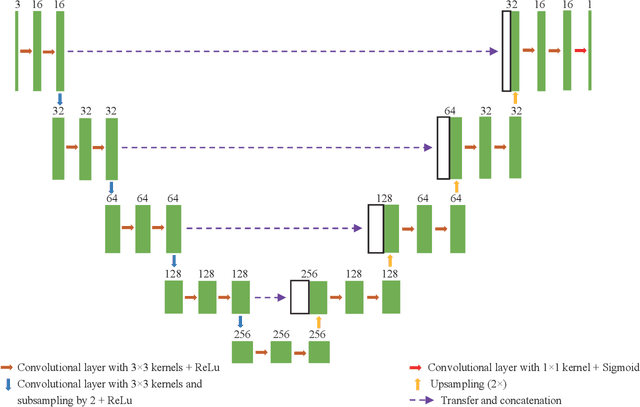
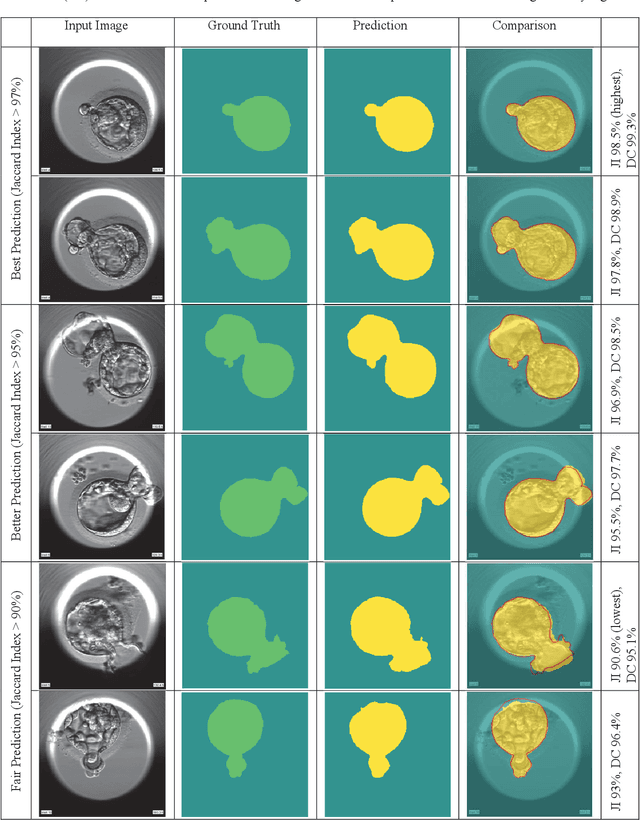
Automating human preimplantation embryo grading offers the potential for higher success rates with in vitro fertilization (IVF) by providing new quantitative and objective measures of embryo quality. Current IVF procedures typically use only qualitative manual grading, which is limited in the identification of genetically abnormal embryos. The automatic quantitative assessment of blastocyst expansion can potentially improve sustained pregnancy rates and reduce health risks from abnormal pregnancies through a more accurate identification of genetic abnormality. The expansion rate of a blastocyst is an important morphological feature to determine the quality of a developing embryo. In this work, a deep learning based human blastocyst image segmentation method is presented, with the goal of facilitating the challenging task of segmenting irregularly shaped blastocysts. The type of blastocysts evaluated here has undergone laser ablation of the zona pellucida, which is required prior to trophectoderm biopsy. This complicates the manual measurements of the expanded blastocyst's size, which shows a correlation with genetic abnormalities. The experimental results on the test set demonstrate segmentation greatly improves the accuracy of expansion measurements, resulting in up to 99.4% accuracy, 98.1% precision, 98.8% recall, a 98.4% Dice Coefficient, and a 96.9% Jaccard Index.
Facial Emotion Characterization and Detection using Fourier Transform and Machine Learning
Dec 06, 2021
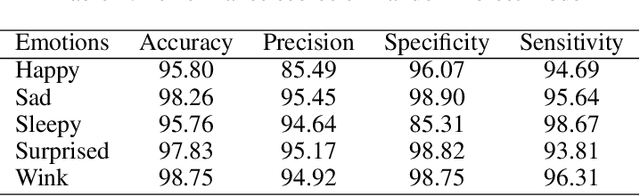

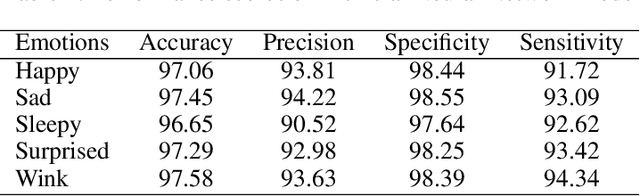
We present a Fourier-based machine learning technique that characterizes and detects facial emotions. The main challenging task in the development of machine learning (ML) models for classifying facial emotions is the detection of accurate emotional features from a set of training samples, and the generation of feature vectors for constructing a meaningful feature space and building ML models. In this paper, we hypothesis that the emotional features are hidden in the frequency domain; hence, they can be captured by leveraging the frequency domain and masking techniques. We also make use of the conjecture that a facial emotions are convoluted with the normal facial features and the other emotional features; however, they carry linearly separable spatial frequencies (we call computational emotional frequencies). Hence, we propose a technique by leveraging fast Fourier transform (FFT) and rectangular narrow-band frequency kernels, and the widely used Yale-Faces image dataset. We test the hypothesis using the performance scores of the random forest (RF) and the artificial neural network (ANN) classifiers as the measures to validate the effectiveness of the captured emotional frequencies. Our finding is that the computational emotional frequencies discovered by the proposed approach provides meaningful emotional features that help RF and ANN achieve a high precision scores above 93%, on average.
Towards Evaluating Gaussian Blurring in Perceptual Hashing as a Facial Image Filter
Feb 01, 2020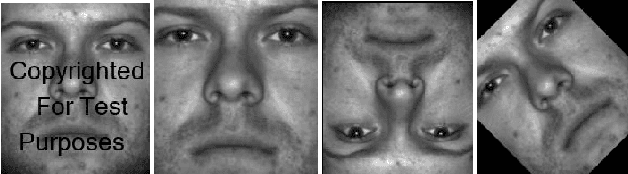
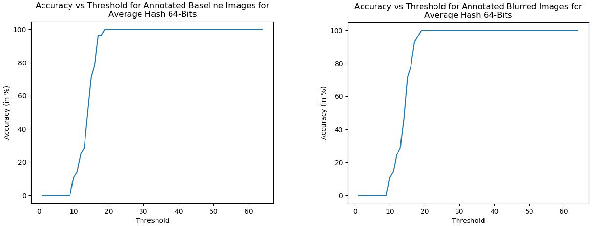
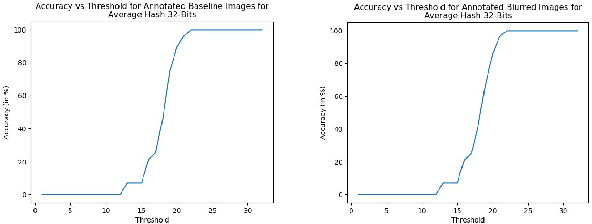
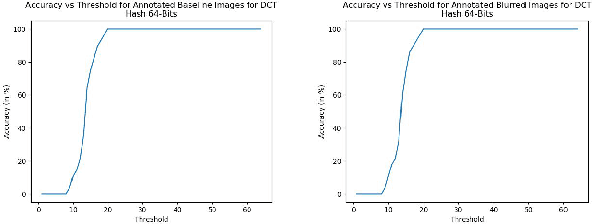
With the growth in social media, there is a huge amount of images of faces available on the internet. Often, people use other people's pictures on their own profile. Perceptual hashing is often used to detect whether two images are identical. Therefore, it can be used to detect whether people are misusing others' pictures. In perceptual hashing, a hash is calculated for a given image, and a new test image is mapped to one of the existing hashes if duplicate features are present. Therefore, it can be used as an image filter to flag banned image content or adversarial attacks --which are modifications that are made on purpose to deceive the filter-- even though the content might be changed to deceive the filters. For this reason, it is critical for perceptual hashing to be robust enough to take transformations such as resizing, cropping, and slight pixel modifications into account. In this paper, we would like to propose to experiment with effect of gaussian blurring in perceptual hashing for detecting misuse of personal images specifically for face images. We hypothesize that use of gaussian blurring on the image before calculating its hash will increase the accuracy of our filter that detects adversarial attacks which consist of image cropping, adding text annotation, and image rotation.
Towards Empirical Sandwich Bounds on the Rate-Distortion Function
Nov 23, 2021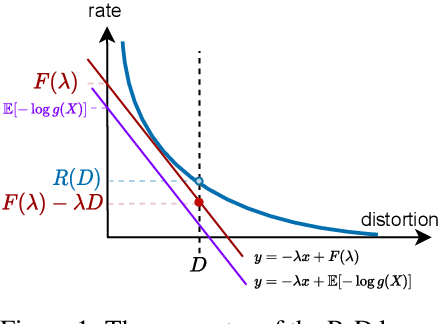
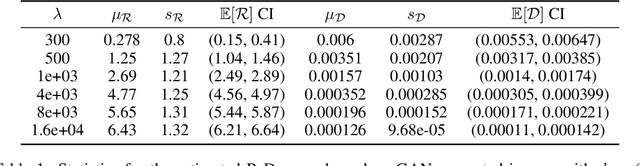
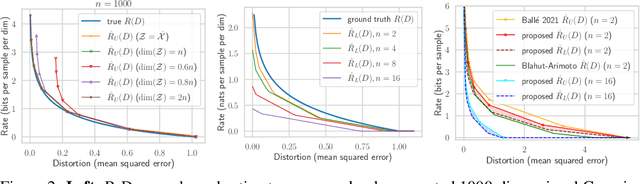
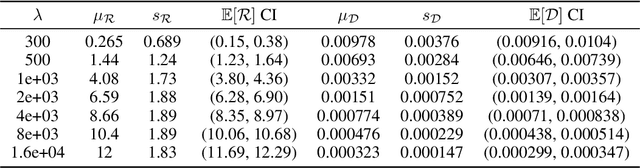
Rate-distortion (R-D) function, a key quantity in information theory, characterizes the fundamental limit of how much a data source can be compressed subject to a fidelity criterion, by any compression algorithm. As researchers push for ever-improving compression performance, establishing the R-D function of a given data source is not only of scientific interest, but also sheds light on the possible room for improving compression algorithms. Previous work on this problem relied on distributional assumptions on the data source (Gibson, 2017) or only applied to discrete data. By contrast, this paper makes the first attempt at an algorithm for sandwiching the R-D function of a general (not necessarily discrete) source requiring only i.i.d. data samples. We estimate R-D sandwich bounds on Gaussian and high-dimension banana-shaped sources, as well as GAN-generated images. Our R-D upper bound on natural images indicates room for improving the performance of state-of-the-art image compression methods by 1 dB in PSNR at various bitrates.
Self-Supervision with Superpixels: Training Few-shot Medical Image Segmentation without Annotation
Jul 20, 2020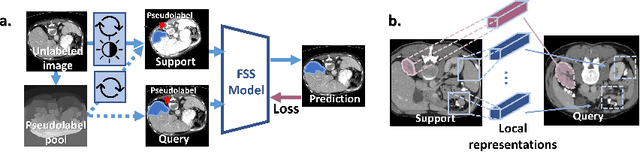
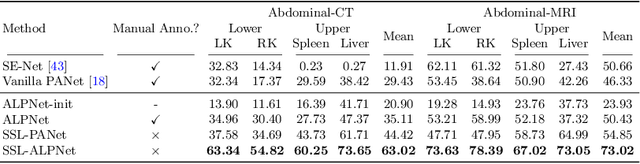
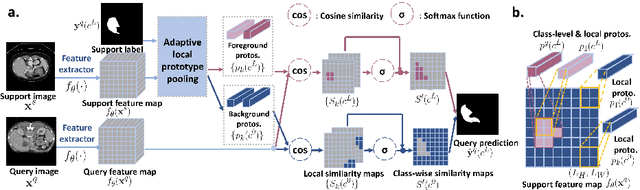
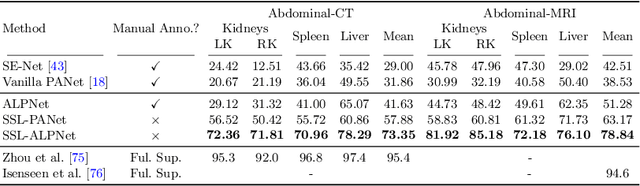
Few-shot semantic segmentation (FSS) has great potential for medical imaging applications. Most of the existing FSS techniques require abundant annotated semantic classes for training. However, these methods may not be applicable for medical images due to the lack of annotations. To address this problem we make several contributions: (1) A novel self-supervised FSS framework for medical images in order to eliminate the requirement for annotations during training. Additionally, superpixel-based pseudo-labels are generated to provide supervision; (2) An adaptive local prototype pooling module plugged into prototypical networks, to solve the common challenging foreground-background imbalance problem in medical image segmentation; (3) We demonstrate the general applicability of the proposed approach for medical images using three different tasks: abdominal organ segmentation for CT and MRI, as well as cardiac segmentation for MRI. Our results show that, for medical image segmentation, the proposed method outperforms conventional FSS methods which require manual annotations for training.
Crossing the Format Boundary of Text and Boxes: Towards Unified Vision-Language Modeling
Nov 23, 2021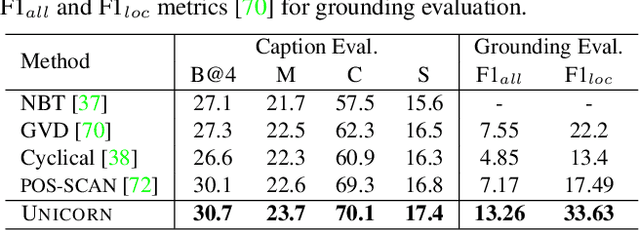
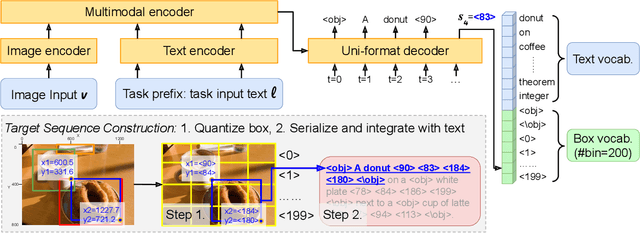
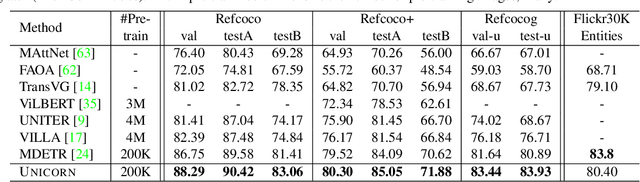
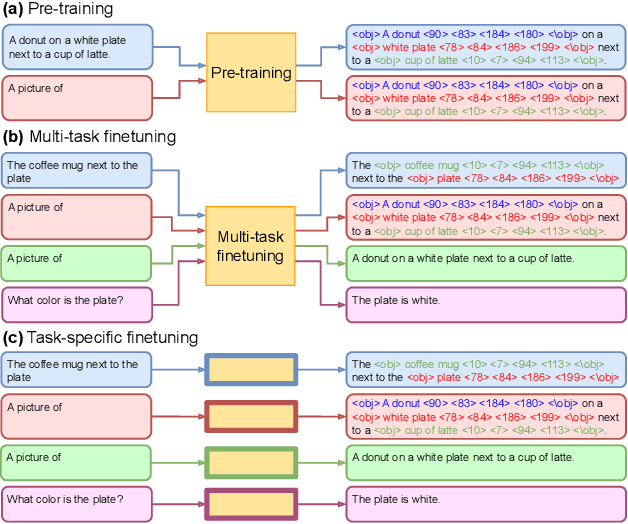
In this paper, we propose UNICORN, a vision-language (VL) model that unifies text generation and bounding box prediction into a single architecture. Specifically, we quantize each box into four discrete box tokens and serialize them as a sequence, which can be integrated with text tokens. We formulate all VL problems as a generation task, where the target sequence consists of the integrated text and box tokens. We then train a transformer encoder-decoder to predict the target in an auto-regressive manner. With such a unified framework and input-output format, UNICORN achieves comparable performance to task-specific state of the art on 7 VL benchmarks, covering the visual grounding, grounded captioning, visual question answering, and image captioning tasks. When trained with multi-task finetuning, UNICORN can approach different VL tasks with a single set of parameters, thus crossing downstream task boundary. We show that having a single model not only saves parameters, but also further boosts the model performance on certain tasks. Finally, UNICORN shows the capability of generalizing to new tasks such as ImageNet object localization.