 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Performance or Trust? Why Not Both. Deep AUC Maximization with Self-Supervised Learning for COVID-19 Chest X-ray Classifications
Dec 14, 2021
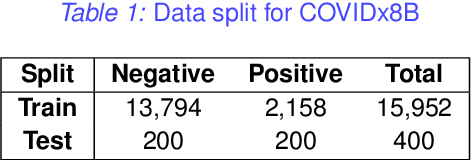
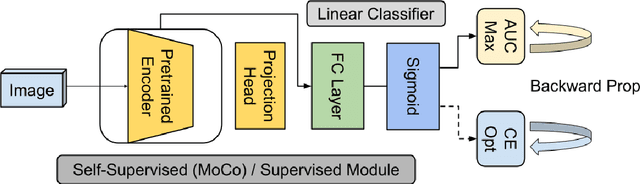
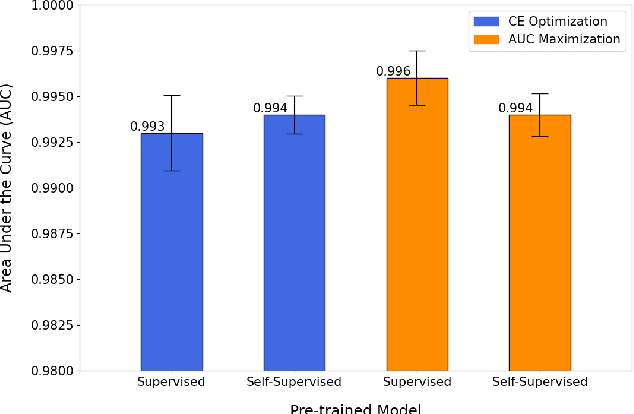
Effective representation learning is the key in improving model performance for medical image analysis. In training deep learning models, a compromise often must be made between performance and trust, both of which are essential for medical applications. Moreover, models optimized with cross-entropy loss tend to suffer from unwarranted overconfidence in the majority class and over-cautiousness in the minority class. In this work, we integrate a new surrogate loss with self-supervised learning for computer-aided screening of COVID-19 patients using radiography images. In addition, we adopt a new quantification score to measure a model's trustworthiness. Ablation study is conducted for both the performance and the trust on feature learning methods and loss functions. Comparisons show that leveraging the new surrogate loss on self-supervised models can produce label-efficient networks that are both high-performing and trustworthy.
* 3 pages
What's in a Loss Function for Image Classification?
Oct 30, 2020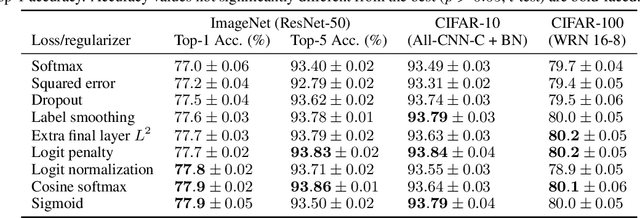
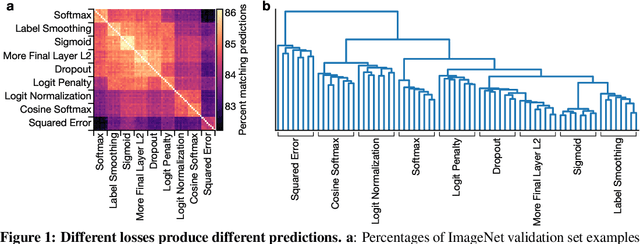
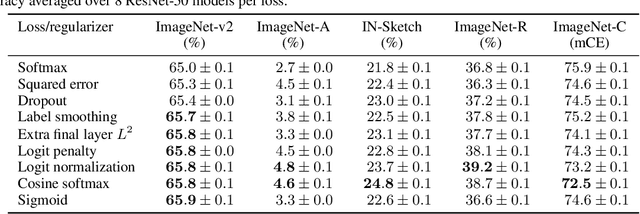
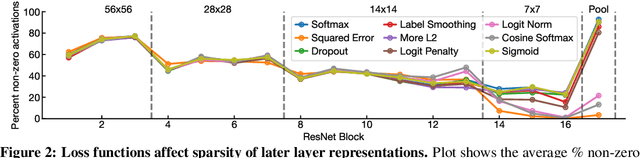
It is common to use the softmax cross-entropy loss to train neural networks on classification datasets where a single class label is assigned to each example. However, it has been shown that modifying softmax cross-entropy with label smoothing or regularizers such as dropout can lead to higher performance. This paper studies a variety of loss functions and output layer regularization strategies on image classification tasks. We observe meaningful differences in model predictions, accuracy, calibration, and out-of-distribution robustness for networks trained with different objectives. However, differences in hidden representations of networks trained with different objectives are restricted to the last few layers; representational similarity reveals no differences among network layers that are not close to the output. We show that all objectives that improve over vanilla softmax loss produce greater class separation in the penultimate layer of the network, which potentially accounts for improved performance on the original task, but results in features that transfer worse to other tasks.
Vision Transformer with Deformable Attention
Jan 03, 2022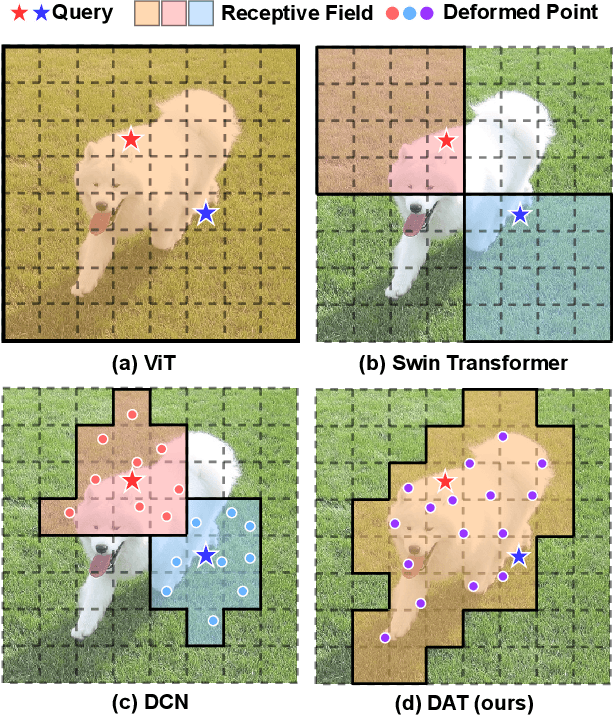
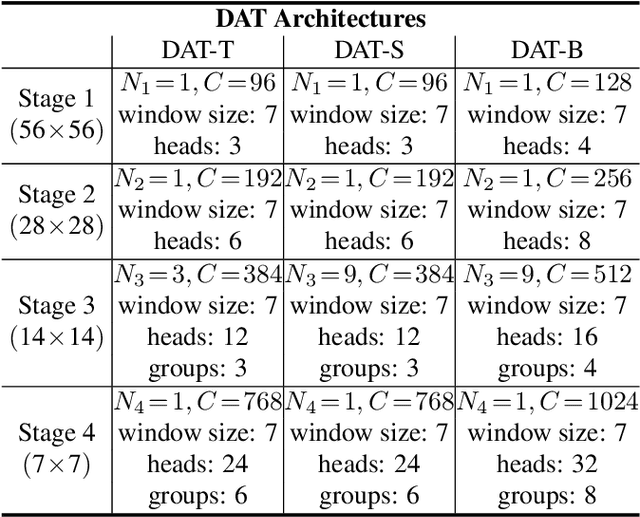
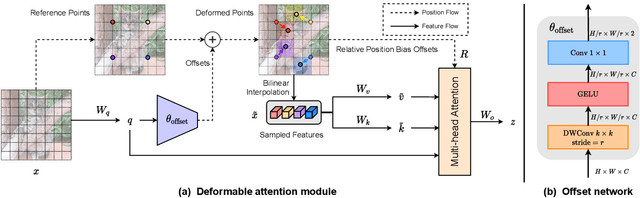
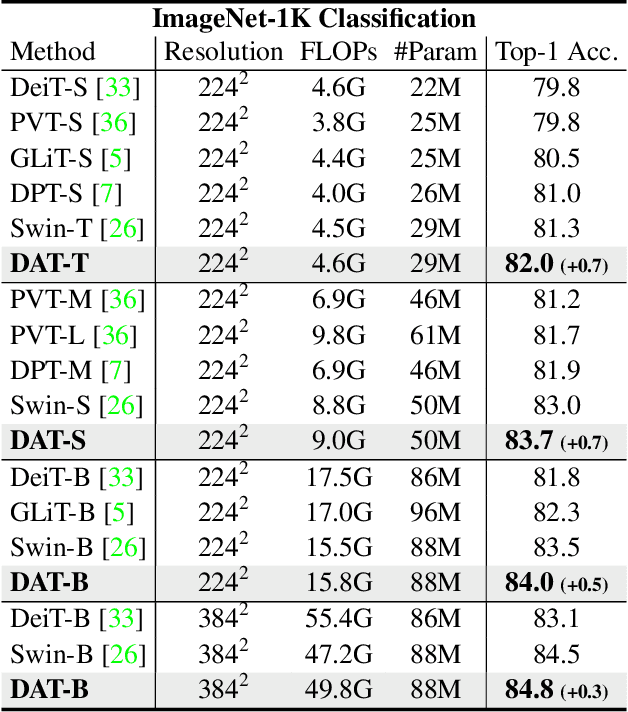
Transformers have recently shown superior performances on various vision tasks. The large, sometimes even global, receptive field endows Transformer models with higher representation power over their CNN counterparts. Nevertheless, simply enlarging receptive field also gives rise to several concerns. On the one hand, using dense attention e.g., in ViT, leads to excessive memory and computational cost, and features can be influenced by irrelevant parts which are beyond the region of interests. On the other hand, the sparse attention adopted in PVT or Swin Transformer is data agnostic and may limit the ability to model long range relations. To mitigate these issues, we propose a novel deformable self-attention module, where the positions of key and value pairs in self-attention are selected in a data-dependent way. This flexible scheme enables the self-attention module to focus on relevant regions and capture more informative features. On this basis, we present Deformable Attention Transformer, a general backbone model with deformable attention for both image classification and dense prediction tasks. Extensive experiments show that our models achieve consistently improved results on comprehensive benchmarks. Code is available at https://github.com/LeapLabTHU/DAT.
Trilevel Neural Architecture Search for Efficient Single Image Super-Resolution
Jan 17, 2021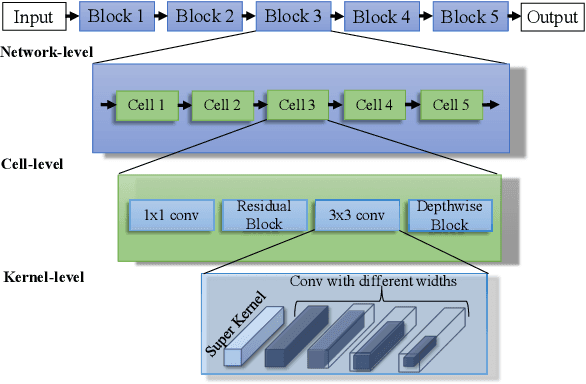
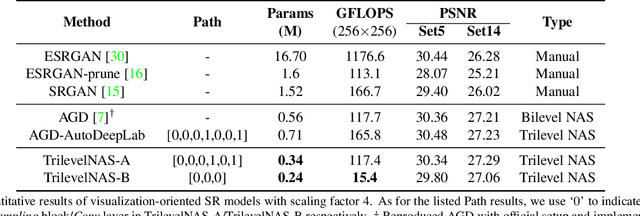
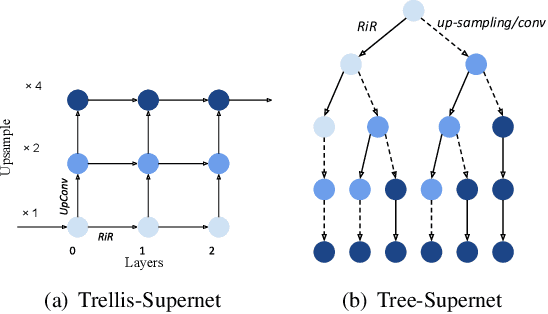
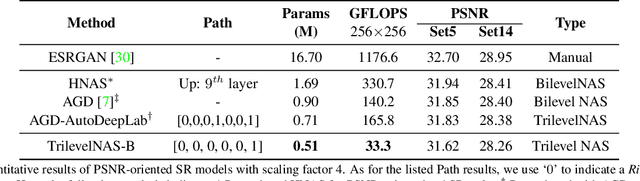
This paper proposes a trilevel neural architecture search (NAS) method for efficient single image super-resolution (SR). For that, we first define the discrete search space at three-level, i.e., at network-level, cell-level, and kernel-level (convolution-kernel). For modeling the discrete search space, we apply a new continuous relaxation on the discrete search spaces to build a hierarchical mixture of network-path, cell-operations, and kernel-width. Later an efficient search algorithm is proposed to perform optimization in a hierarchical supernet manner that provides a globally optimized and compressed network via joint convolution kernel width pruning, cell structure search, and network path optimization. Unlike current NAS methods, we exploit a sorted sparsestmax activation to let the three-level neural structures contribute sparsely. Consequently, our NAS optimization progressively converges to those neural structures with dominant contributions to the supernet. Additionally, our proposed optimization construction enables a simultaneous search and training in a single phase, which dramatically reduces search and train time compared to the traditional NAS algorithms. Experiments on the standard benchmark datasets demonstrate that our NAS algorithm provides SR models that are significantly lighter in terms of the number of parameters and FLOPS with PSNR value comparable to the current state-of-the-art.
STRIVE: Scene Text Replacement In Videos
Sep 06, 2021
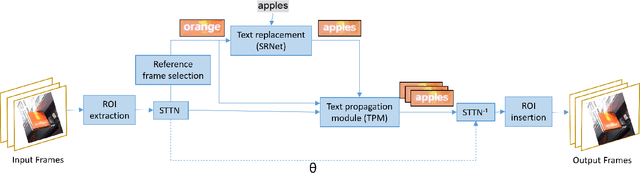
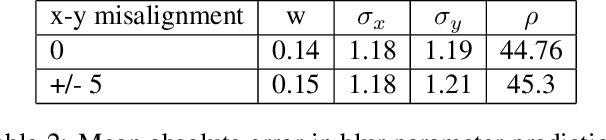
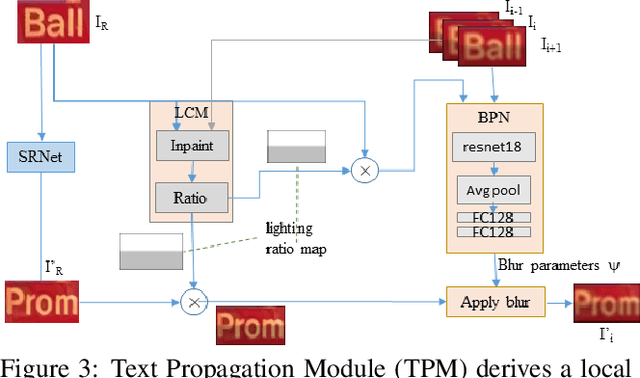
We propose replacing scene text in videos using deep style transfer and learned photometric transformations.Building on recent progress on still image text replacement,we present extensions that alter text while preserving the appearance and motion characteristics of the original video.Compared to the problem of still image text replacement,our method addresses additional challenges introduced by video, namely effects induced by changing lighting, motion blur, diverse variations in camera-object pose over time,and preservation of temporal consistency. We parse the problem into three steps. First, the text in all frames is normalized to a frontal pose using a spatio-temporal trans-former network. Second, the text is replaced in a single reference frame using a state-of-art still-image text replacement method. Finally, the new text is transferred from the reference to remaining frames using a novel learned image transformation network that captures lighting and blur effects in a temporally consistent manner. Results on synthetic and challenging real videos show realistic text trans-fer, competitive quantitative and qualitative performance,and superior inference speed relative to alternatives. We introduce new synthetic and real-world datasets with paired text objects. To the best of our knowledge this is the first attempt at deep video text replacement.
MESSFN : a Multi-level and Enhanced Spectral-Spatial Fusion Network for Pan-sharpening
Sep 21, 2021


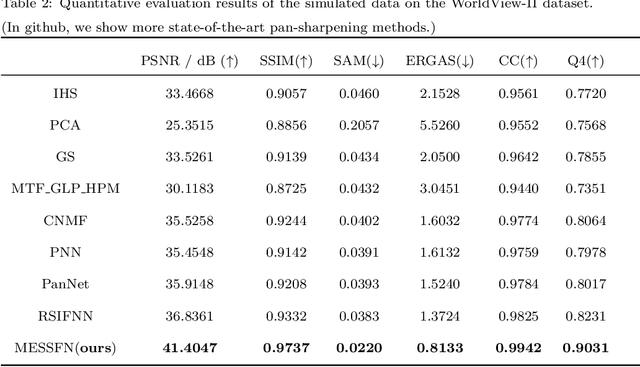
Dominant pan-sharpening frameworks simply concatenate the MS stream and the PAN stream once at a specific level. This way of fusion neglects the multi-level spectral-spatial correlation between the two streams, which is vital to improving the fusion performance. In consideration of this, we propose a Multi-level and Enhanced Spectral-Spatial Fusion Network (MESSFN) with the following innovations: First, to fully exploit and strengthen the above correlation, a Hierarchical Multi-level Fusion Architecture (HMFA) is carefully designed. A novel Spectral-Spatial (SS) stream is established to hierarchically derive and fuse the multi-level prior spectral and spatial expertise from the MS stream and the PAN stream. This helps the SS stream master a joint spectral-spatial representation in the hierarchical network for better modeling the fusion relationship. Second, to provide superior expertise, consequently, based on the intrinsic characteristics of the MS image and the PAN image, two feature extraction blocks are specially developed. In the MS stream, a Residual Spectral Attention Block (RSAB) is proposed to mine the potential spectral correlations between different spectra of the MS image through adjacent cross-spectrum interaction. While in the PAN stream, a Residual Multi-scale Spatial Attention Block (RMSAB) is proposed to capture multi-scale information and reconstruct precise high-frequency details from the PAN image through an improved spatial attention-based inception structure. The spectral and spatial feature representations are enhanced. Extensive experiments on two datasets demonstrate that the proposed network is competitive with or better than state-of-the-art methods. Our code can be found in github.
Decomposing Normal and Abnormal Features of Medical Images for Content-based Image Retrieval
Nov 12, 2020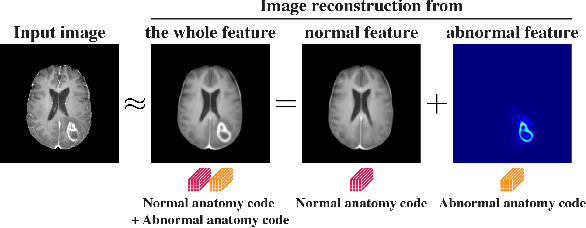
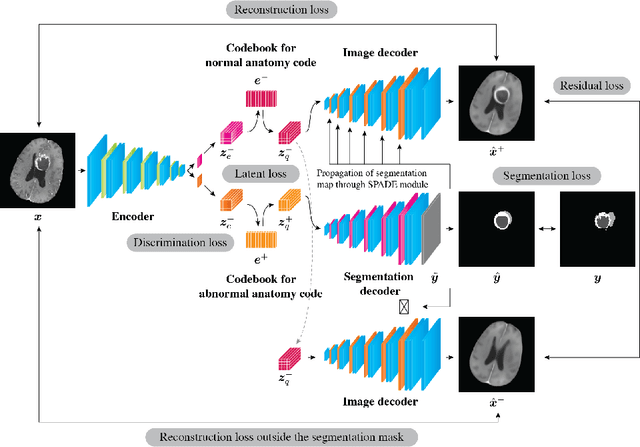
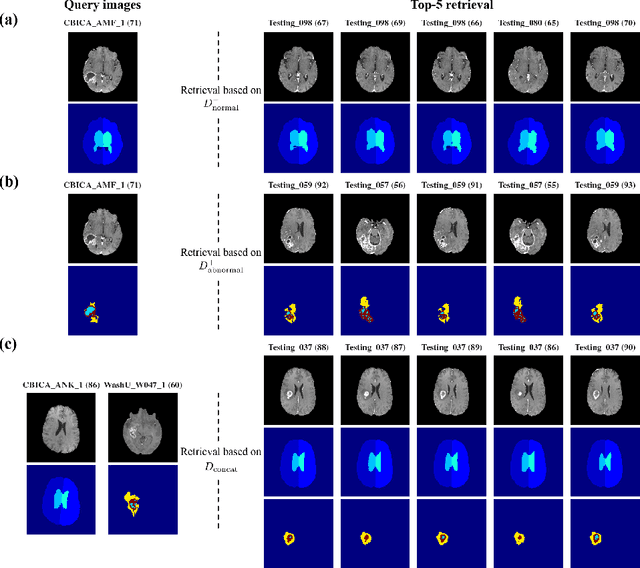
Medical images can be decomposed into normal and abnormal features, which is considered as the compositionality. Based on this idea, we propose an encoder-decoder network to decompose a medical image into two discrete latent codes: a normal anatomy code and an abnormal anatomy code. Using these latent codes, we demonstrate a similarity retrieval by focusing on either normal or abnormal features of medical images.
Can Giraffes Become Birds? An Evaluation of Image-to-image Translation for Data Generation
Jan 10, 2020
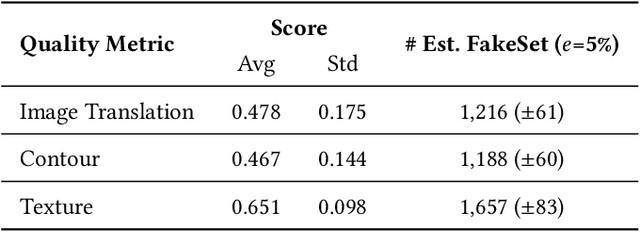
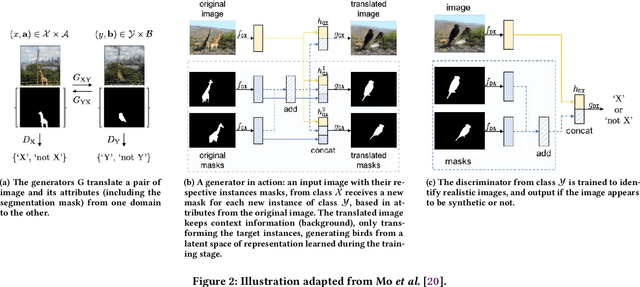
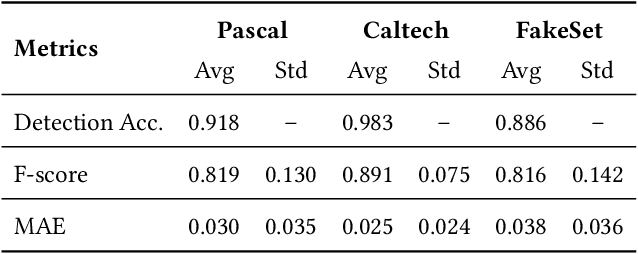
There is an increasing interest in image-to-image translation with applications ranging from generating maps from satellite images to creating entire clothes' images from only contours. In the present work, we investigate image-to-image translation using Generative Adversarial Networks (GANs) for generating new data, taking as a case study the morphing of giraffes images into bird images. Morphing a giraffe into a bird is a challenging task, as they have different scales, textures, and morphology. An unsupervised cross-domain translator entitled InstaGAN was trained on giraffes and birds, along with their respective masks, to learn translation between both domains. A dataset of synthetic bird images was generated using translation from originally giraffe images while preserving the original spatial arrangement and background. It is important to stress that the generated birds do not exist, being only the result of a latent representation learned by InstaGAN. Two subsets of common literature datasets were used for training the GAN and generating the translated images: COCO and Caltech-UCSD Birds 200-2011. To evaluate the realness and quality of the generated images and masks, qualitative and quantitative analyses were made. For the quantitative analysis, a pre-trained Mask R-CNN was used for the detection and segmentation of birds on Pascal VOC, Caltech-UCSD Birds 200-2011, and our new dataset entitled FakeSet. The generated dataset achieved detection and segmentation results close to the real datasets, suggesting that the generated images are realistic enough to be detected and segmented by a state-of-the-art deep neural network.
VisImages: A Large-scale, High-quality Image Corpus in Visualization Publications
Jul 10, 2020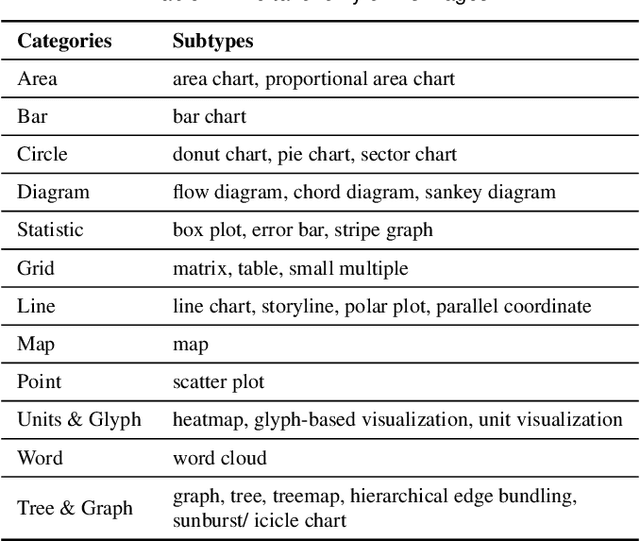
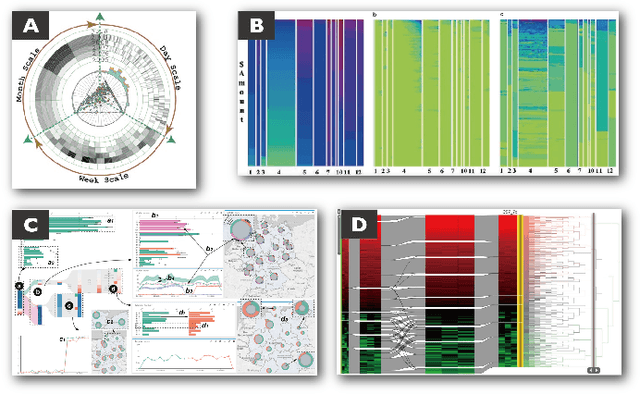

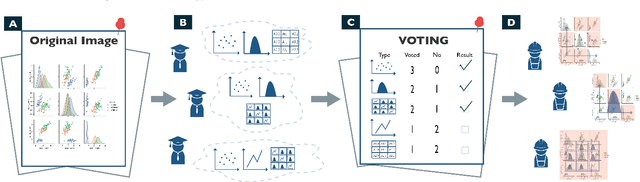
Images in visualization publications contain rich information, such as novel visual designs, model details, and experiment results. Constructing such an image corpus can contribute to the community in many aspects, including literature analysis from the perspective of visual representations, empirical studies on visual memorability, and machine learning research for chart detection. This study presents VisImages, a high-quality and large-scale image corpus collected from visualization publications. VisImages contain fruitful and diverse annotations for each image, including captions, types of visual representations, and bounding boxes. First, we algorithmically extract the images associated with captions and manually correct the errors. Second, to categorize visualizations in publications, we extend and iteratively refine the existing taxonomy through a multi-round pilot study. Third, guided by this taxonomy, we invite senior visualization practitioners to annotate visual representations that appear in each image. In this process, we borrow techniques such as "gold standards" and majority voting for quality control. Finally, we recruit the crowd to draw bounding boxes for visual representations in the images. The resulting corpus contains 35,096 annotated visualizations from 12,267 images with 12,057 captions in 1397 papers from VAST and InfoVis. We demonstrate the usefulness of VisImages through the following four use cases: 1) analysis of color usage in VAST and InfoVis papers across years, 2) discussion of the researcher preference on visualization types, 3) spatial distribution analysis of visualizations in visual analytic systems, and 4) training visualization detection models.
Producing augmentation-invariant embeddings from real-life imagery
Dec 10, 2021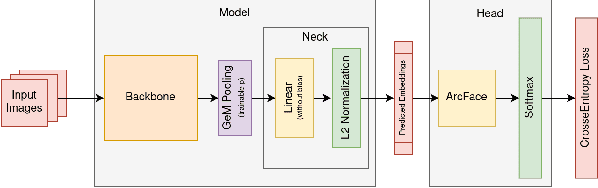
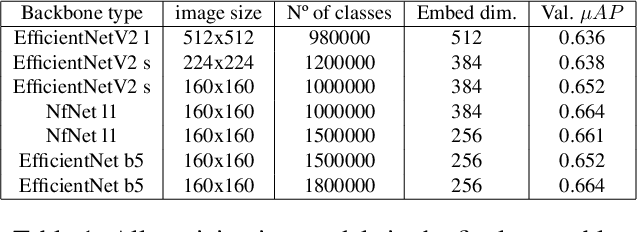


This article presents an efficient way to produce feature-rich, high-dimensionality embedding spaces from real-life images. The features produced are designed to be independent from augmentations used in real-life cases which appear on social media. Our approach uses convolutional neural networks (CNN) to produce an embedding space. An ArcFace head was used to train the model by employing automatically produced augmentations. Additionally, we present a way to make an ensemble out of different embeddings containing the same semantic information, a way to normalize the resulting embedding using an external dataset, and a novel way to perform quick training of these models with a high number of classes in the ArcFace head. Using this approach we achieved the 2nd place in the 2021 Facebook AI Image Similarity Challenge: Descriptor Track.