 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressive Local Filter Pruning for Image Retrieval Acceleration
Jan 24, 2020
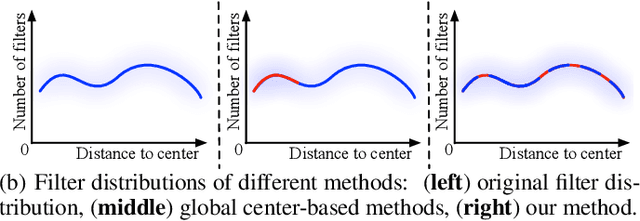
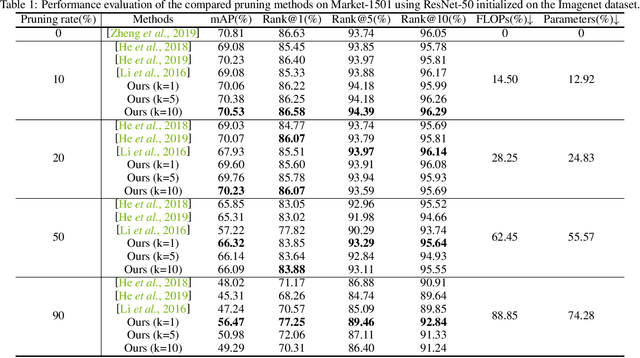
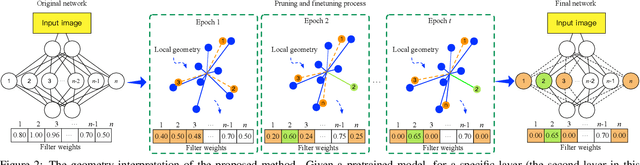
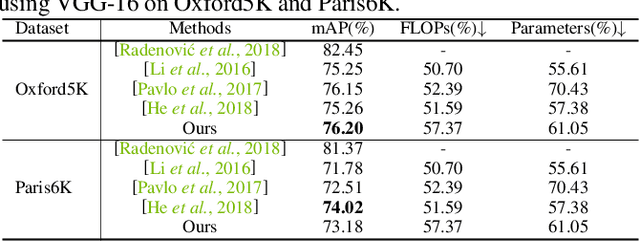
This paper focuses on network pruning for image retrieval acceleration. Prevailing image retrieval works target at the discriminative feature learning, while little attention is paid to how to accelerate the model inference, which should be taken into consideration in real-world practice. The challenge of pruning image retrieval models is that the middle-level feature should be preserved as much as possible. Such different requirements of the retrieval and classification model make the traditional pruning methods not that suitable for our task. To solve the problem, we propose a new Progressive Local Filter Pruning (PLFP) method for image retrieval acceleration. Specifically, layer by layer, we analyze the local geometric properties of each filter and select the one that can be replaced by the neighbors. Then we progressively prune the filter by gradually changing the filter weights. In this way, the representation ability of the model is preserved. To verify this, we evaluate our method on two widely-used image retrieval datasets,i.e., Oxford5k and Paris6K, and one person re-identification dataset,i.e., Market-1501. The proposed method arrives with superior performance to the conventional pruning methods, suggesting the effectiveness of the proposed method for image retrieval.
Compositional Generalization in Image Captioning
Sep 16, 2019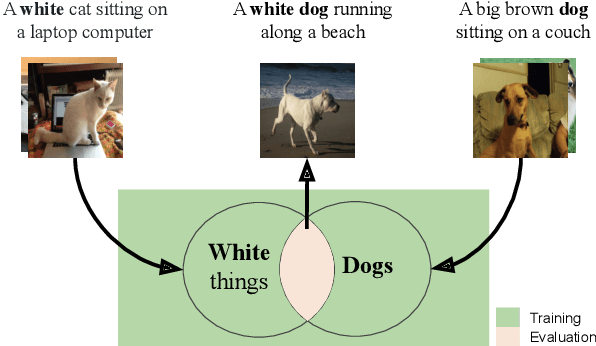

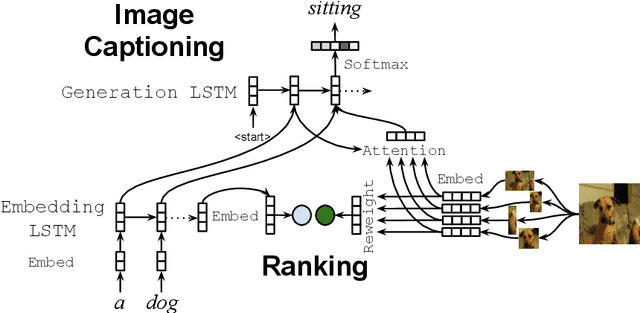
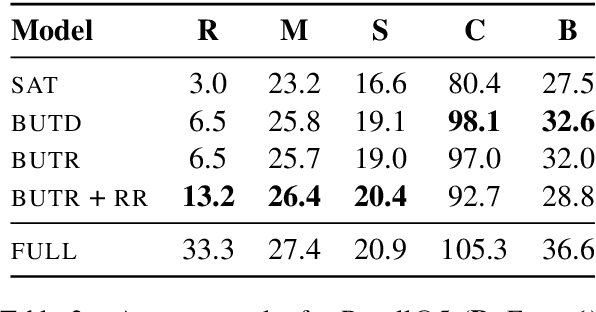
Image captioning models are usually evaluated on their ability to describe a held-out set of images, not on their ability to generalize to unseen concepts. We study the problem of compositional generalization, which measures how well a model composes unseen combinations of concepts when describing images. State-of-the-art image captioning models show poor generalization performance on this task. We propose a multi-task model to address the poor performance, that combines caption generation and image--sentence ranking, and uses a decoding mechanism that re-ranks the captions according their similarity to the image. This model is substantially better at generalizing to unseen combinations of concepts compared to state-of-the-art captioning models.
Generative Patch Priors for Practical Compressive Image Recovery
Jun 18, 2020
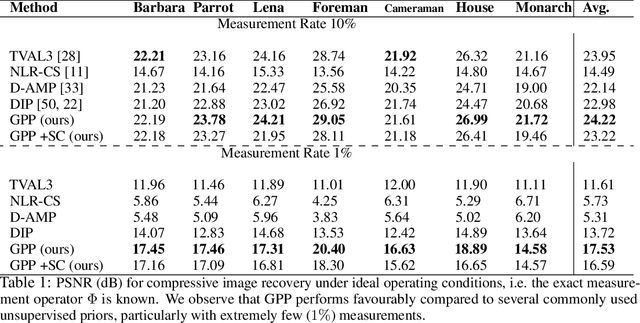
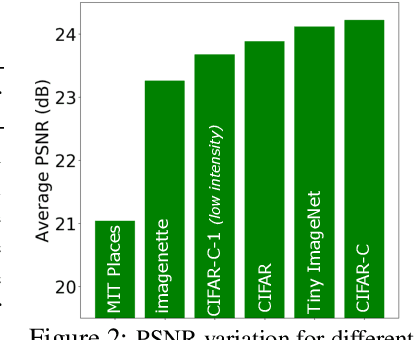
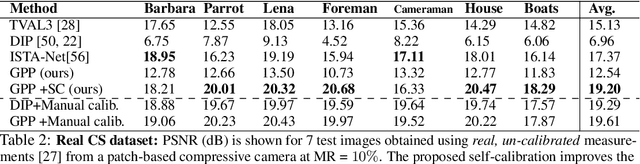
In this paper, we propose the generative patch prior (GPP) that defines a generative prior for compressive image recovery, based on patch-manifold models. Unlike learned, image-level priors that are restricted to the range space of a pre-trained generator, GPP can recover a wide variety of natural images using a pre-trained patch generator. Additionally, GPP retains the benefits of generative priors like high reconstruction quality at extremely low sensing rates, while also being much more generally applicable. We show that GPP outperforms several unsupervised and supervised techniques on three different sensing models -- linear compressive sensing with known, and unknown calibration settings, and the non-linear phase retrieval problem. Finally, we propose an alternating optimization strategy using GPP for joint calibration-and-reconstruction which performs favorably against several baselines on a real world, un-calibrated compressive sensing dataset.
Self-Validation: Early Stopping for Single-Instance Deep Generative Priors
Oct 23, 2021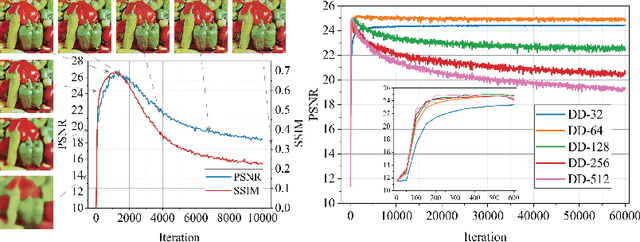
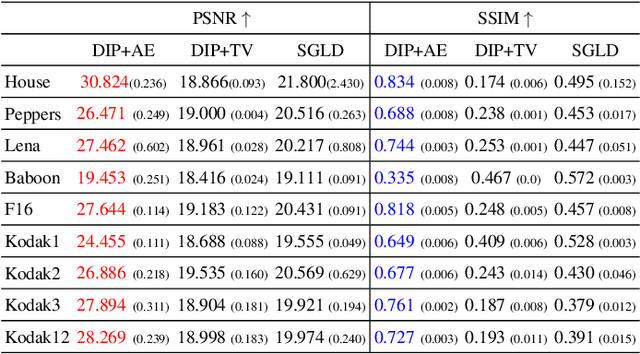
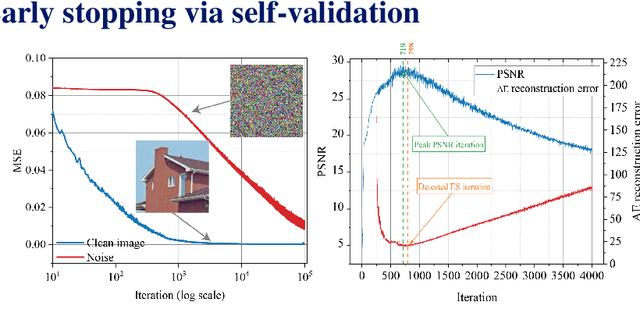
Recent works have shown the surprising effectiveness of deep generative models in solving numerous image reconstruction (IR) tasks, even without training data. We call these models, such as deep image prior and deep decoder, collectively as single-instance deep generative priors (SIDGPs). The successes, however, often hinge on appropriate early stopping (ES), which by far has largely been handled in an ad-hoc manner. In this paper, we propose the first principled method for ES when applying SIDGPs to IR, taking advantage of the typical bell trend of the reconstruction quality. In particular, our method is based on collaborative training and self-validation: the primal reconstruction process is monitored by a deep autoencoder, which is trained online with the historic reconstructed images and used to validate the reconstruction quality constantly. Experimentally, on several IR problems and different SIDGPs, our self-validation method is able to reliably detect near-peak performance and signal good ES points. Our code is available at https://sun-umn.github.io/Self-Validation/.
Pollen Grain Microscopic Image Classification Using an Ensemble of Fine-Tuned Deep Convolutional Neural Networks
Nov 15, 2020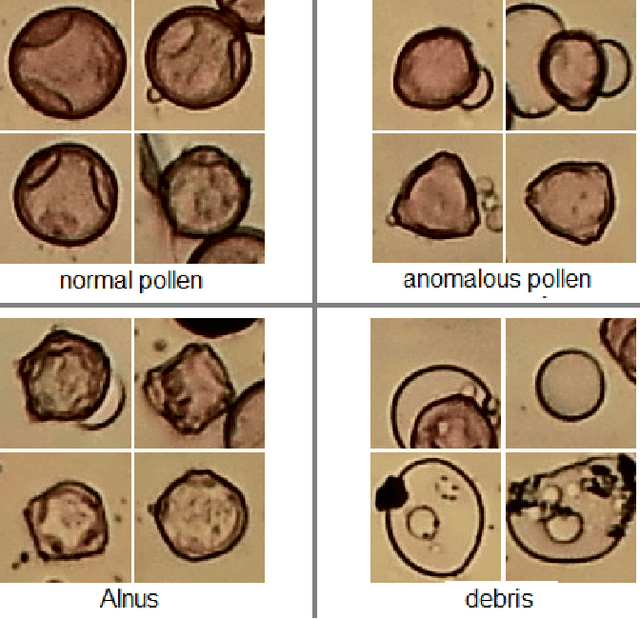
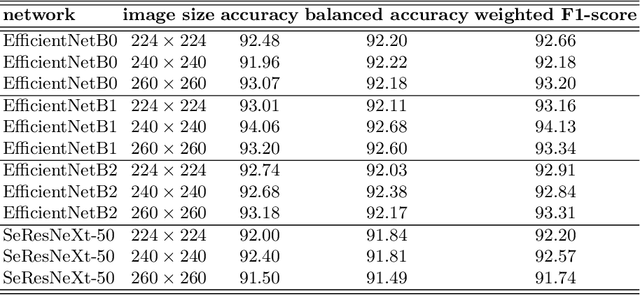
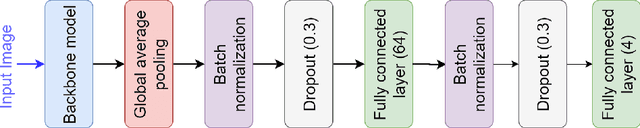
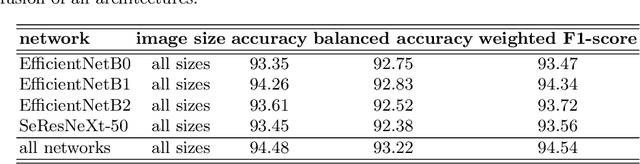
Pollen grain micrograph classification has multiple applications in medicine and biology. Automatic pollen grain image classification can alleviate the problems of manual categorisation such as subjectivity and time constraints. While a number of computer-based methods have been introduced in the literature to perform this task, classification performance needs to be improved for these methods to be useful in practice. In this paper, we present an ensemble approach for pollen grain microscopic image classification into four categories: Corylus Avellana well-developed pollen grain, Corylus Avellana anomalous pollen grain, Alnus well-developed pollen grain, and non-pollen (debris) instances. In our approach, we develop a classification strategy that is based on fusion of four state-of-the-art fine-tuned convolutional neural networks, namely EfficientNetB0, EfficientNetB1, EfficientNetB2 and SeResNeXt-50 deep models. These models are trained with images of three fixed sizes (224x224, 240x240, and 260x260 pixels) and their prediction probability vectors are then fused in an ensemble method to form a final classification vector for a given pollen grain image. Our proposed method is shown to yield excellent classification performance, obtaining an accuracy of of 94.48% and a weighted F1-score of 94.54% on the ICPR 2020 Pollen Grain Classification Challenge training dataset based on five-fold cross-validation. Evaluated on the test set of the challenge, our approach achieved a very competitive performance in comparison to the top ranked approaches with an accuracy and a weighted F1-score of 96.28% and 96.30%, respectively.
Semi-supervised Cardiac Image Segmentation via Label Propagation and Style Transfer
Dec 29, 2020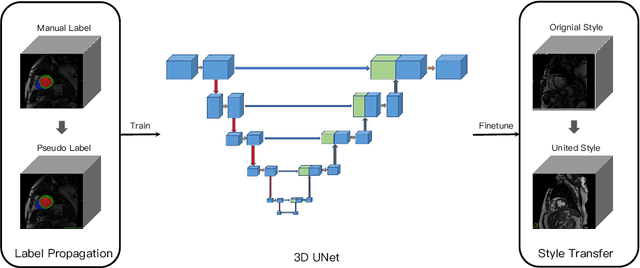
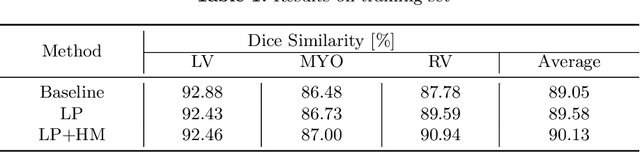
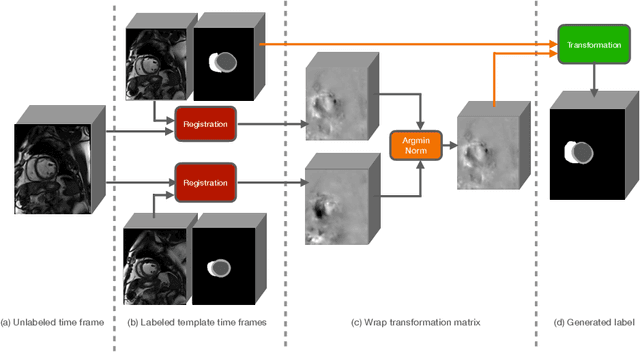

Accurate segmentation of cardiac structures can assist doctors to diagnose diseases, and to improve treatment planning, which is highly demanded in the clinical practice. However, the shortage of annotation and the variance of the data among different vendors and medical centers restrict the performance of advanced deep learning methods. In this work, we present a fully automatic method to segment cardiac structures including the left (LV) and right ventricle (RV) blood pools, as well as for the left ventricular myocardium (MYO) in MRI volumes. Specifically, we design a semi-supervised learning method to leverage unlabelled MRI sequence timeframes by label propagation. Then we exploit style transfer to reduce the variance among different centers and vendors for more robust cardiac image segmentation. We evaluate our method in the M&Ms challenge 7 , ranking 2nd place among 14 competitive teams.
Using Uncertainty in Deep Learning Reconstruction for Cone-Beam CT of the Brain
Aug 20, 2021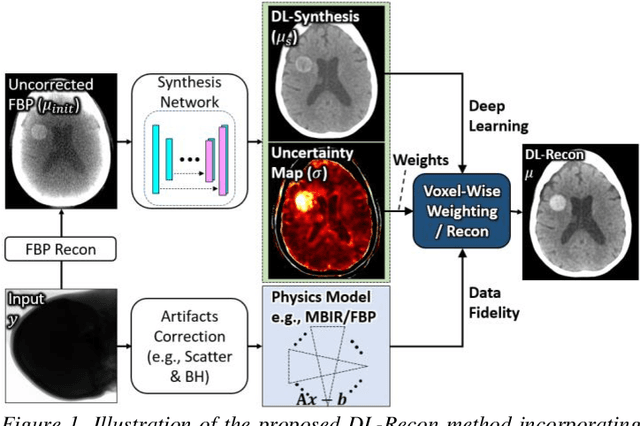
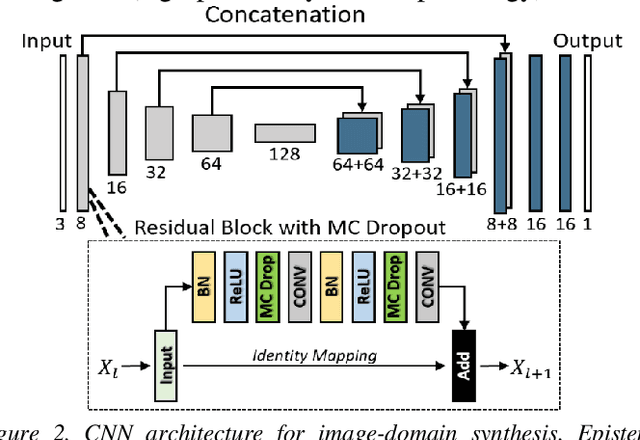
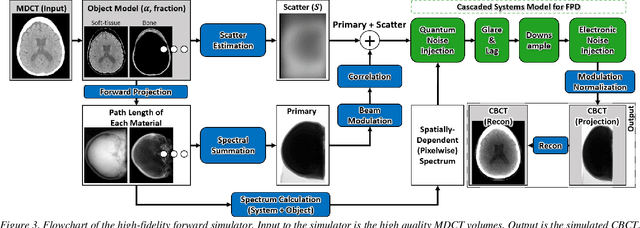
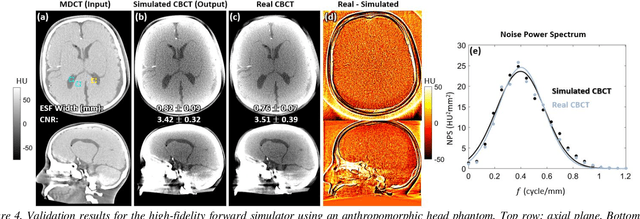
Contrast resolution beyond the limits of conventional cone-beam CT (CBCT) systems is essential to high-quality imaging of the brain. We present a deep learning reconstruction method (dubbed DL-Recon) that integrates physically principled reconstruction models with DL-based image synthesis based on the statistical uncertainty in the synthesis image. A synthesis network was developed to generate a synthesized CBCT image (DL-Synthesis) from an uncorrected filtered back-projection (FBP) image. To improve generalizability (including accurate representation of lesions not seen in training), voxel-wise epistemic uncertainty of DL-Synthesis was computed using a Bayesian inference technique (Monte-Carlo dropout). In regions of high uncertainty, the DL-Recon method incorporates information from a physics-based reconstruction model and artifact-corrected projection data. Two forms of the DL-Recon method are proposed: (i) image-domain fusion of DL-Synthesis and FBP (DL-FBP) weighted by DL uncertainty; and (ii) a model-based iterative image reconstruction (MBIR) optimization using DL-Synthesis to compute a spatially varying regularization term based on DL uncertainty (DL-MBIR). The error in DL-Synthesis images was correlated with the uncertainty in the synthesis estimate. Compared to FBP and PWLS, the DL-Recon methods (both DL-FBP and DL-MBIR) showed ~50% reduction in noise (at matched spatial resolution) and ~40-70% improvement in image uniformity. Conventional DL-Synthesis alone exhibited ~10-60% under-estimation of lesion contrast and ~5-40% reduction in lesion segmentation accuracy (Dice coefficient) in simulated and real brain lesions, suggesting a lack of reliability / generalizability for structures unseen in the training data. DL-FBP and DL-MBIR improved the accuracy of reconstruction by directly incorporating information from the measurements in regions of high uncertainty.
MODNet-V: Improving Portrait Video Matting via Background Restoration
Sep 24, 2021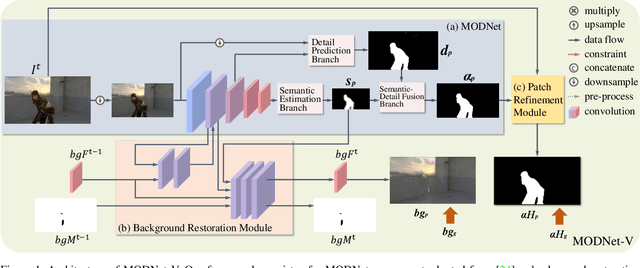

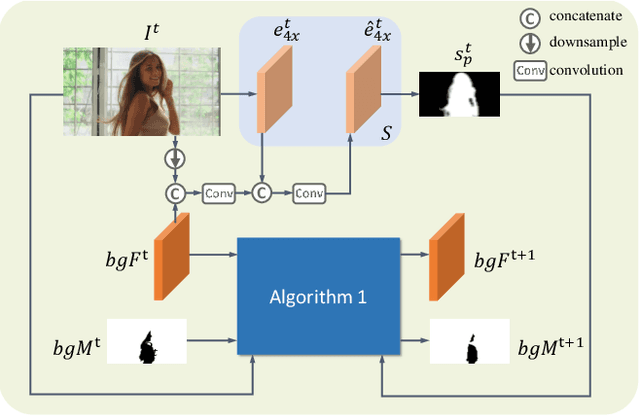
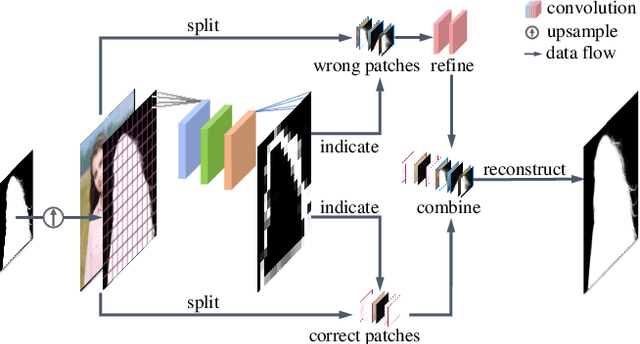
To address the challenging portrait video matting problem more precisely, existing works typically apply some matting priors that require additional user efforts to obtain, such as annotated trimaps or background images. In this work, we observe that instead of asking the user to explicitly provide a background image, we may recover it from the input video itself. To this end, we first propose a novel background restoration module (BRM) to recover the background image dynamically from the input video. BRM is extremely lightweight and can be easily integrated into existing matting models. By combining BRM with a recent image matting model, MODNet, we then present MODNet-V for portrait video matting. Benefited from the strong background prior provided by BRM, MODNet-V has only 1/3 of the parameters of MODNet but achieves comparable or even better performances. Our design allows MODNet-V to be trained in an end-to-end manner on a single NVIDIA 3090 GPU. Finally, we introduce a new patch refinement module (PRM) to adapt MODNet-V for high-resolution videos while keeping MODNet-V lightweight and fast.
Spectral analysis of re-parameterized light fields
Oct 12, 2021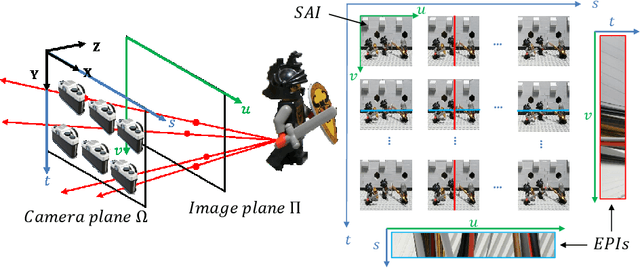
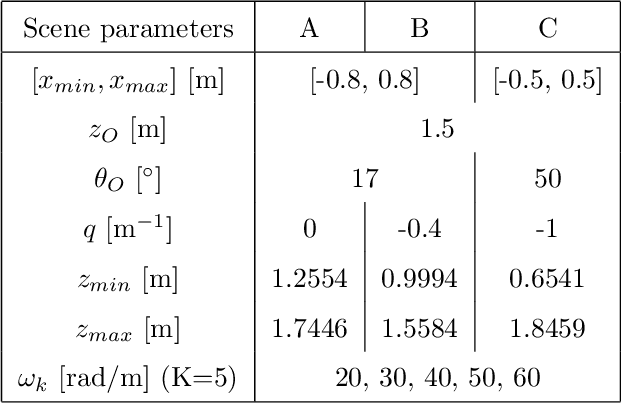
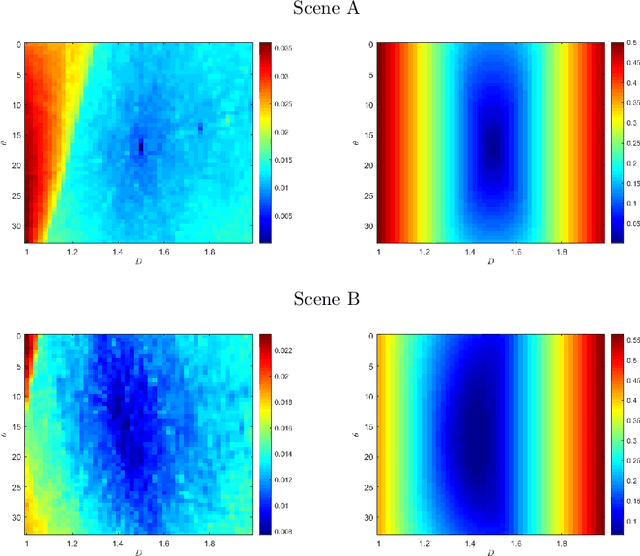
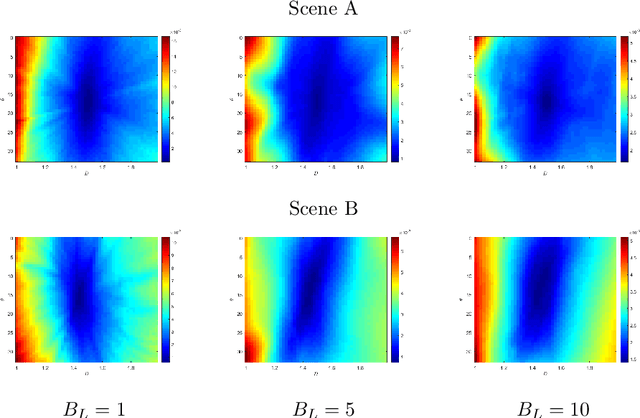
In this paper, we study the spectral properties of re-parameterized light field. Following previous studies of the light field spectrum, which notably provided sampling guidelines, we focus on the two plane parameterization of the light field. However, we introduce additional flexibility by allowing the image plane to be tilted and not only parallel. A formal theoretical analysis is first presented, which shows that more flexible sampling guidelines (i.e. wider camera baselines) can be used to sample the light field when adapting the image plane orientation to the scene geometry. We then present our simulations and results to support these theoretical findings. While the work introduced in this paper is mostly theoretical, we believe these new findings open exciting avenues for more practical application of light fields, such as view synthesis or compact representation.
Enabling Deep Learning on Edge Devices through Filter Pruning and Knowledge Transfer
Jan 22, 2022Deep learning models have introduced various intelligent applications to edge devices, such as image classification, speech recognition, and augmented reality. There is an increasing need of training such models on the devices in order to deliver personalized, responsive, and private learning. To address this need, this paper presents a new solution for deploying and training state-of-the-art models on the resource-constrained devices. First, the paper proposes a novel filter-pruning-based model compression method to create lightweight trainable models from large models trained in the cloud, without much loss of accuracy. Second, it proposes a novel knowledge transfer method to enable the on-device model to update incrementally in real time or near real time using incremental learning on new data and enable the on-device model to learn the unseen categories with the help of the in-cloud model in an unsupervised fashion. The results show that 1) our model compression method can remove up to 99.36% parameters of WRN-28-10, while preserving a Top-1 accuracy of over 90% on CIFAR-10; 2) our knowledge transfer method enables the compressed models to achieve more than 90% accuracy on CIFAR-10 and retain good accuracy on old categories; 3) it allows the compressed models to converge within real time (three to six minutes) on the edge for incremental learning tasks; 4) it enables the model to classify unseen categories of data (78.92% Top-1 accuracy) that it is never trained with.