 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Label-Free Model Evaluation with Semi-Structured Dataset Representations
Dec 01, 2021
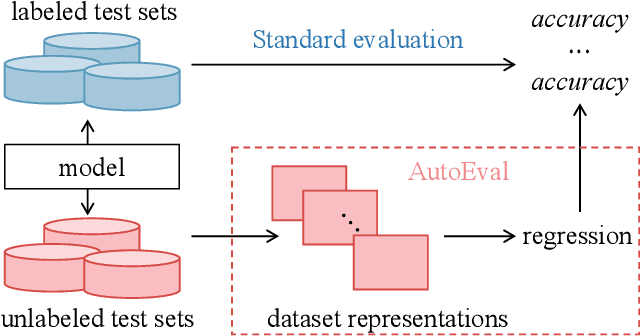
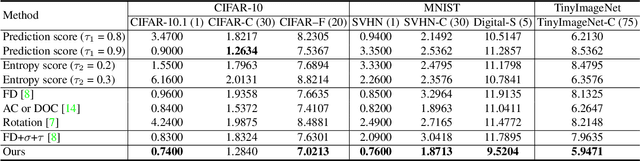


Label-free model evaluation, or AutoEval, estimates model accuracy on unlabeled test sets, and is critical for understanding model behaviors in various unseen environments. In the absence of image labels, based on dataset representations, we estimate model performance for AutoEval with regression. On the one hand, image feature is a straightforward choice for such representations, but it hampers regression learning due to being unstructured (\ie no specific meanings for component at certain location) and of large-scale. On the other hand, previous methods adopt simple structured representations (like average confidence or average feature), but insufficient to capture the data characteristics given their limited dimensions. In this work, we take the best of both worlds and propose a new semi-structured dataset representation that is manageable for regression learning while containing rich information for AutoEval. Based on image features, we integrate distribution shapes, clusters, and representative samples for a semi-structured dataset representation. Besides the structured overall description with distribution shapes, the unstructured description with clusters and representative samples include additional fine-grained information facilitating the AutoEval task. On three existing datasets and 25 newly introduced ones, we experimentally show that the proposed representation achieves competitive results. Code and dataset are available at https://github.com/sxzrt/Semi-Structured-Dataset-Representations.
P2M: A Processing-in-Pixel-in-Memory Paradigm for Resource-Constrained TinyML Applications
Mar 17, 2022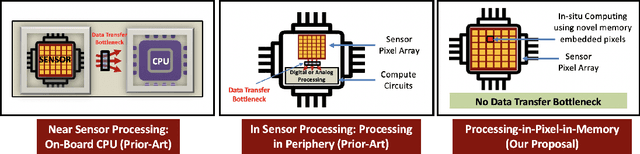

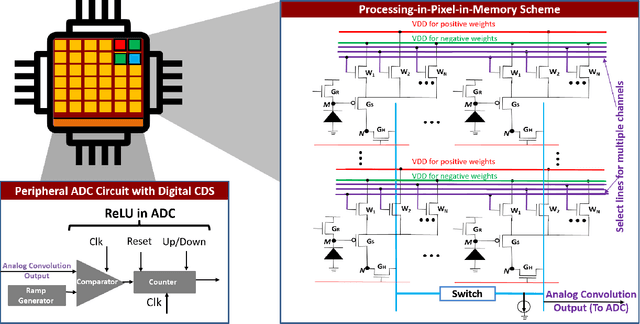

The demand to process vast amounts of data generated from state-of-the-art high resolution cameras has motivated novel energy-efficient on-device AI solutions. Visual data in such cameras are usually captured in the form of analog voltages by a sensor pixel array, and then converted to the digital domain for subsequent AI processing using analog-to-digital converters (ADC). Recent research has tried to take advantage of massively parallel low-power analog/digital computing in the form of near- and in-sensor processing, in which the AI computation is performed partly in the periphery of the pixel array and partly in a separate on-board CPU/accelerator. Unfortunately, high-resolution input images still need to be streamed between the camera and the AI processing unit, frame by frame, causing energy, bandwidth, and security bottlenecks. To mitigate this problem, we propose a novel Processing-in-Pixel-in-memory (P2M) paradigm, that customizes the pixel array by adding support for analog multi-channel, multi-bit convolution, batch normalization, and ReLU (Rectified Linear Units). Our solution includes a holistic algorithm-circuit co-design approach and the resulting P2M paradigm can be used as a drop-in replacement for embedding memory-intensive first few layers of convolutional neural network (CNN) models within foundry-manufacturable CMOS image sensor platforms. Our experimental results indicate that P2M reduces data transfer bandwidth from sensors and analog to digital conversions by ~21x, and the energy-delay product (EDP) incurred in processing a MobileNetV2 model on a TinyML use case for visual wake words dataset (VWW) by up to ~11x compared to standard near-processing or in-sensor implementations, without any significant drop in test accuracy.
Single Plane-Wave Imaging using Physics-Based Deep Learning
Sep 08, 2021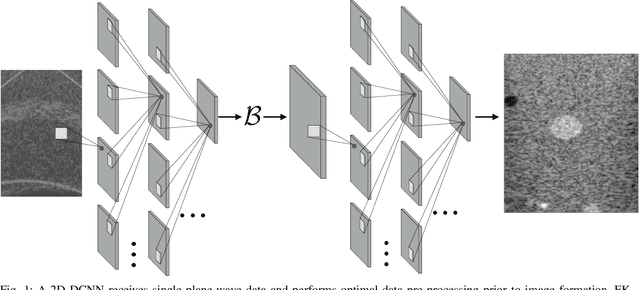
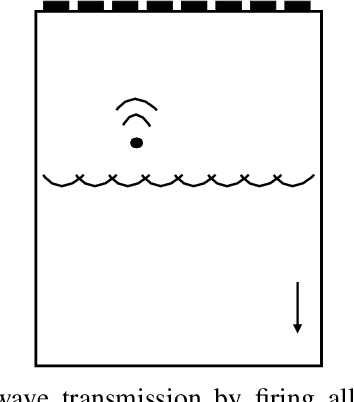
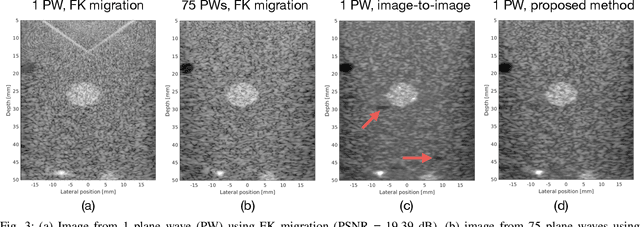
In plane-wave imaging, multiple unfocused ultrasound waves are transmitted into a medium of interest from different angles and an image is formed from the recorded reflections. The number of plane waves used leads to a trade-off between frame-rate and image quality, with single-plane-wave (SPW) imaging being the fastest possible modality with the worst image quality. Recently, deep learning methods have been proposed to improve ultrasound imaging. One approach is to use image-to-image networks that work on the formed image and another is to directly learn a mapping from data to an image. Both approaches utilize purely data-driven models and require deep, expressive network architectures, combined with large numbers of training samples to obtain good results. Here, we propose a data-to-image architecture that incorporates a wave-physics-based image formation algorithm in-between deep convolutional neural networks. To achieve this, we implement the Fourier (FK) migration method as network layers and train the whole network end-to-end. We compare our proposed data-to-image network with an image-to-image network in simulated data experiments, mimicking a medical ultrasound application. Experiments show that it is possible to obtain high-quality SPW images, almost similar to an image formed using 75 plane waves over an angular range of $\pm$16$^\circ$. This illustrates the great potential of combining deep neural networks with physics-based image formation algorithms for SPW imaging.
Deep Symmetric Adaptation Network for Cross-modality Medical Image Segmentation
Jan 18, 2021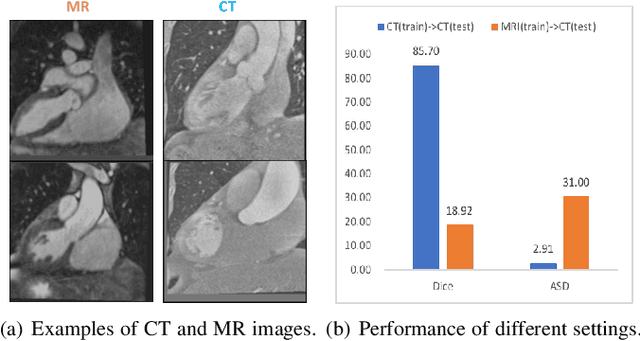
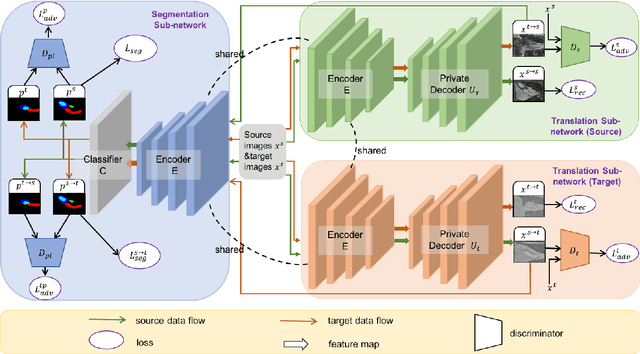
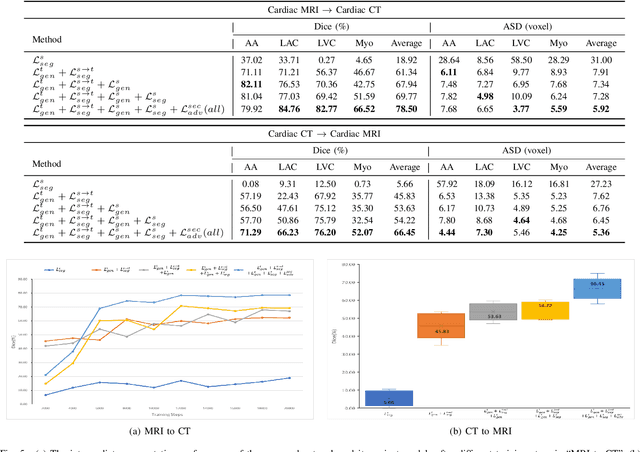
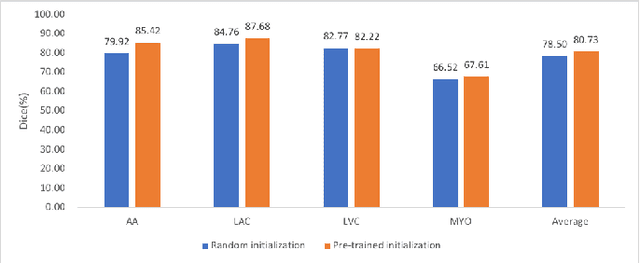
Unsupervised domain adaptation (UDA) methods have shown their promising performance in the cross-modality medical image segmentation tasks. These typical methods usually utilize a translation network to transform images from the source domain to target domain or train the pixel-level classifier merely using translated source images and original target images. However, when there exists a large domain shift between source and target domains, we argue that this asymmetric structure could not fully eliminate the domain gap. In this paper, we present a novel deep symmetric architecture of UDA for medical image segmentation, which consists of a segmentation sub-network, and two symmetric source and target domain translation sub-networks. To be specific, based on two translation sub-networks, we introduce a bidirectional alignment scheme via a shared encoder and private decoders to simultaneously align features 1) from source to target domain and 2) from target to source domain, which helps effectively mitigate the discrepancy between domains. Furthermore, for the segmentation sub-network, we train a pixel-level classifier using not only original target images and translated source images, but also original source images and translated target images, which helps sufficiently leverage the semantic information from the images with different styles. Extensive experiments demonstrate that our method has remarkable advantages compared to the state-of-the-art methods in both cross-modality Cardiac and BraTS segmentation tasks.
Robust Autoencoder GAN for Cryo-EM Image Denoising
Aug 17, 2020
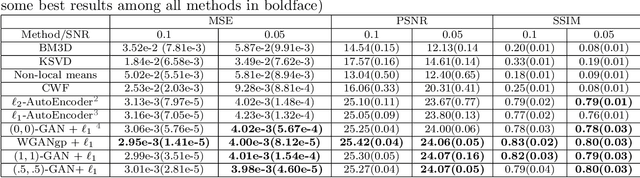
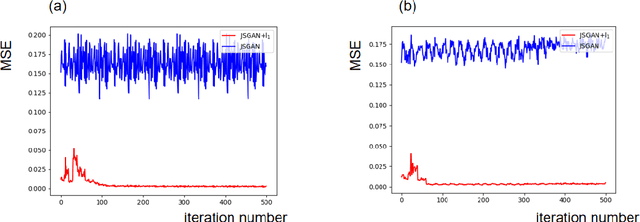
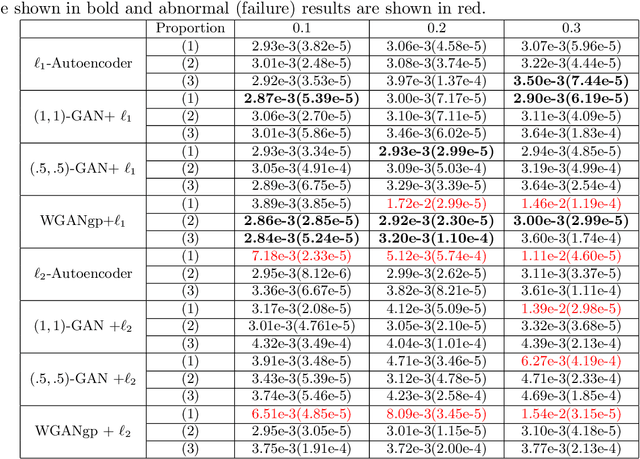
The cryo-electron microscopy (Cryo-EM) becomes popular for macromolecular structure determination. However, the 2D images which Cryo-EM detects are of high noise and often mixed with multiple heterogeneous conformations or contamination, imposing a challenge for denoising. Traditional image denoising methods can not remove Cryo-EM image noise well when the signal-noise-ratio (SNR) of images is meager. Thus it is desired to develop new effective denoising techniques to facilitate further research such as 3D reconstruction, 2D conformation classification, and so on. In this paper, we approach the robust image denoising problem in Cryo-EM by a joint Autoencoder and Generative Adversarial Networks (GAN) method. Equipped with robust $\ell_1$ Autoencoder and some designs of robust $\beta$-GANs, one can stabilize the training of GANs and achieve the state-of-the-art performance of robust denoising with low SNR data and against possible information contamination. The method is evaluated by both a heterogeneous conformational dataset on the Thermus aquaticus RNA Polymerase (RNAP) and a homogenous dataset on the Plasmodium falciparum 80S ribosome dataset (EMPIRE-10028), in terms of Mean Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), as well as heterogeneous conformation clustering. These results suggest that our proposed methodology provides an effective tool for Cryo-EM 2D image denoising.
Domain Adaptation based Technique for Image Emotion Recognition using Pre-trained Facial Expression Recognition Models
Nov 17, 2020

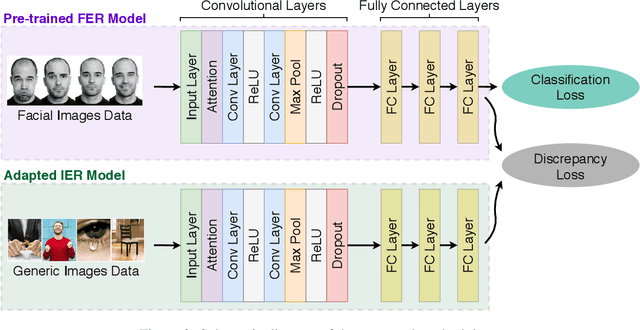
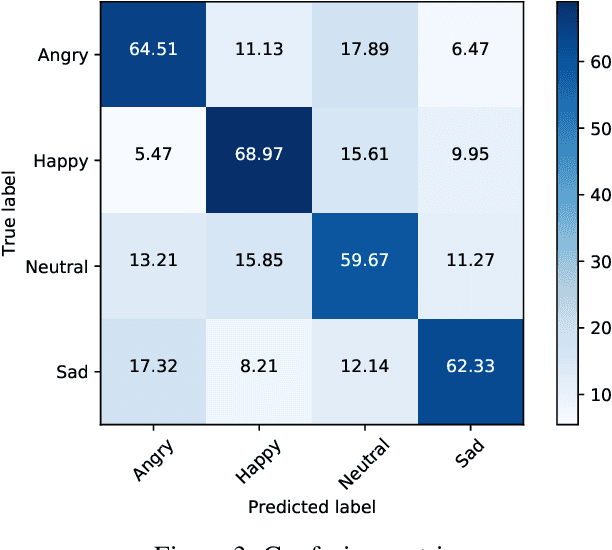
In this paper, a domain adaptation based technique for recognizing the emotions in images containing facial, non-facial, and non-human components has been proposed. We have also proposed a novel technique to explain the proposed system's predictions in terms of Intersection Score. Image emotion recognition is useful for graphics, gaming, animation, entertainment, and cinematography. However, well-labeled large scale datasets and pre-trained models are not available for image emotion recognition. To overcome this challenge, we have proposed a deep learning approach based on an attentional convolutional network that adapts pre-trained facial expression recognition models. It detects the visual features of an image and performs emotion classification based on them. The experiments have been performed on the Flickr image dataset, and the images have been classified in 'angry,' 'happy,' 'sad,' and 'neutral' emotion classes. The proposed system has demonstrated better performance than the benchmark results with an accuracy of 63.87% for image emotion recognition. We have also analyzed the embedding plots for various emotion classes to explain the proposed system's predictions.
Parallel Neural Local Lossless Compression
Jan 13, 2022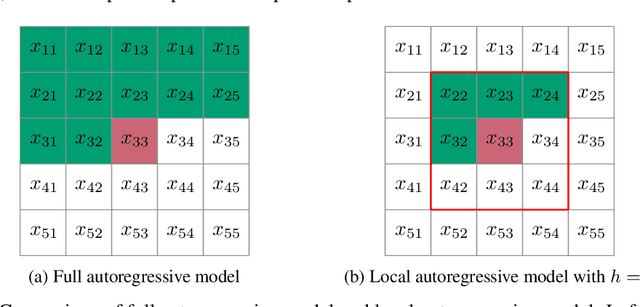
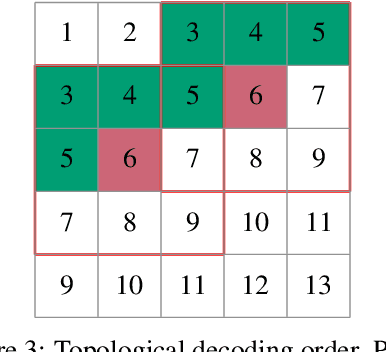

The recently proposed Neural Local Lossless Compression (NeLLoC), which is based on a local autoregressive model, has achieved state-of-the-art (SOTA) out-of-distribution (OOD) generalization performance in the image compression task. In addition to the encouragement of OOD generalization, the local model also allows parallel inference in the decoding stage. In this paper, we propose a parallelization scheme for local autoregressive models. We discuss the practicalities of implementing this scheme, and provide experimental evidence of significant gains in compression runtime compared to the previous, non-parallel implementation.
Learning Weakly-Supervised Contrastive Representations
Feb 18, 2022



We argue that a form of the valuable information provided by the auxiliary information is its implied data clustering information. For instance, considering hashtags as auxiliary information, we can hypothesize that an Instagram image will be semantically more similar with the same hashtags. With this intuition, we present a two-stage weakly-supervised contrastive learning approach. The first stage is to cluster data according to its auxiliary information. The second stage is to learn similar representations within the same cluster and dissimilar representations for data from different clusters. Our empirical experiments suggest the following three contributions. First, compared to conventional self-supervised representations, the auxiliary-information-infused representations bring the performance closer to the supervised representations, which use direct downstream labels as supervision signals. Second, our approach performs the best in most cases, when comparing our approach with other baseline representation learning methods that also leverage auxiliary data information. Third, we show that our approach also works well with unsupervised constructed clusters (e.g., no auxiliary information), resulting in a strong unsupervised representation learning approach.
Vehicle trajectory prediction in top-view image sequences based on deep learning method
Feb 02, 2021
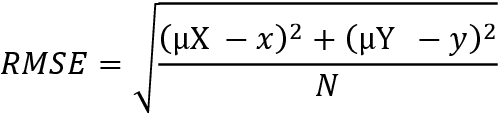
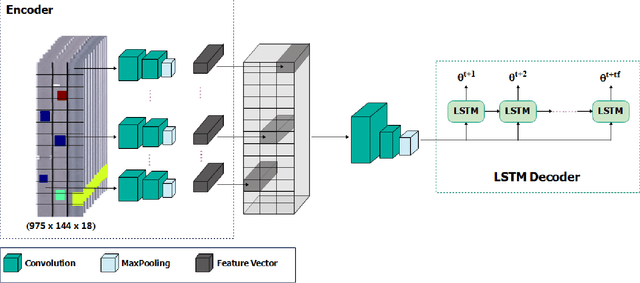
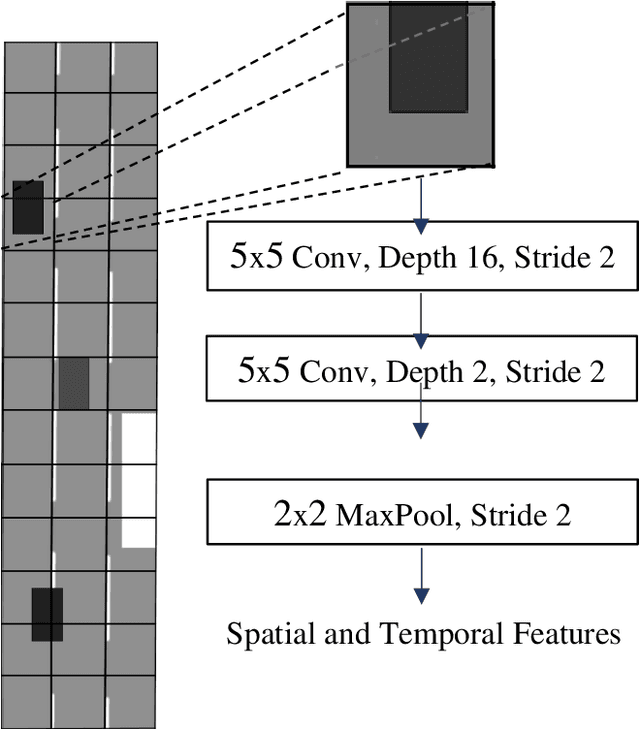
Annually, a large number of injuries and deaths around the world are related to motor vehicle accidents. This value has recently been reduced to some extent, via the use of driver-assistance systems. Developing driver-assistance systems (i.e., automated driving systems) can play a crucial role in reducing this number. Estimating and predicting surrounding vehicles' movement is essential for an automated vehicle and advanced safety systems. Moreover, predicting the trajectory is influenced by numerous factors, such as drivers' behavior during accidents, history of the vehicle's movement and the surrounding vehicles, and their position on the traffic scene. The vehicle must move over a safe path in traffic and react to other drivers' unpredictable behaviors in the shortest time. Herein, to predict automated vehicles' path, a model with low computational complexity is proposed, which is trained by images taken from the road's aerial image. Our method is based on an encoder-decoder model that utilizes a social tensor to model the effect of the surrounding vehicles' movement on the target vehicle. The proposed model can predict the vehicle's future path in any freeway only by viewing the images related to the history of the target vehicle's movement and its neighbors. Deep learning was used as a tool for extracting the features of these images. Using the HighD database, an image dataset of the road's aerial image was created, and the model's performance was evaluated on this new database. We achieved the RMSE of 1.91 for the next 5 seconds and found that the proposed method had less error than the best path-prediction methods in previous studies.
Visual Learning-based Planning for Continuous High-Dimensional POMDPs
Dec 17, 2021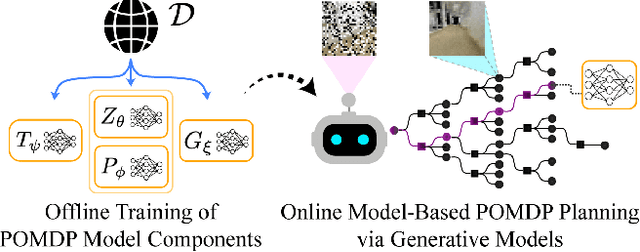
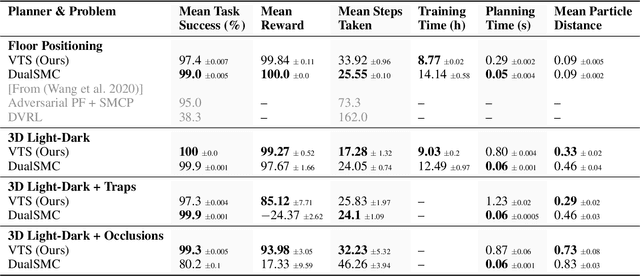
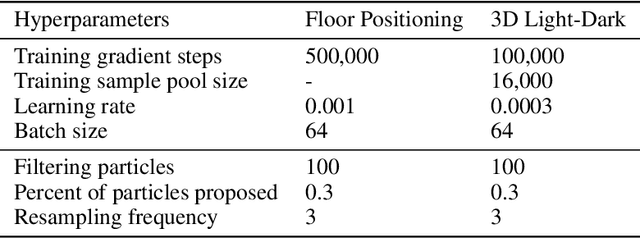
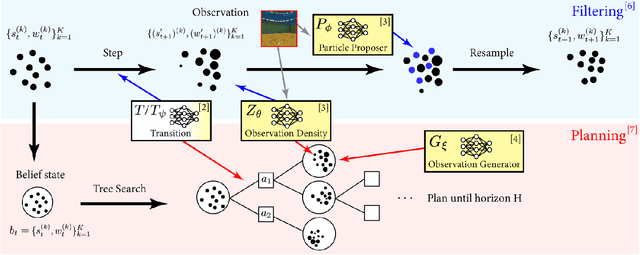
The Partially Observable Markov Decision Process (POMDP) is a powerful framework for capturing decision-making problems that involve state and transition uncertainty. However, most current POMDP planners cannot effectively handle very high-dimensional observations they often encounter in the real world (e.g. image observations in robotic domains). In this work, we propose Visual Tree Search (VTS), a learning and planning procedure that combines generative models learned offline with online model-based POMDP planning. VTS bridges offline model training and online planning by utilizing a set of deep generative observation models to predict and evaluate the likelihood of image observations in a Monte Carlo tree search planner. We show that VTS is robust to different observation noises and, since it utilizes online, model-based planning, can adapt to different reward structures without the need to re-train. This new approach outperforms a baseline state-of-the-art on-policy planning algorithm while using significantly less offline training time.