 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Next-Best-View Prediction for Active Stereo Cameras and Highly Reflective Objects
Feb 27, 2022



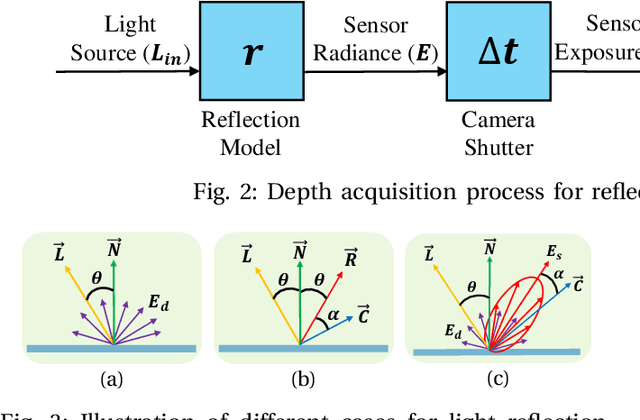
Depth acquisition with the active stereo camera is a challenging task for highly reflective objects. When setup permits, multi-view fusion can provide increased levels of depth completion. However, due to the slow acquisition speed of high-end active stereo cameras, collecting a large number of viewpoints for a single scene is generally not practical. In this work, we propose a next-best-view framework to strategically select camera viewpoints for completing depth data on reflective objects. In particular, we explicitly model the specular reflection of reflective surfaces based on the Phong reflection model and a photometric response function. Given the object CAD model and grayscale image, we employ an RGB-based pose estimator to obtain current pose predictions from the existing data, which is used to form predicted surface normal and depth hypotheses, and allows us to then assess the information gain from a subsequent frame for any candidate viewpoint. Using this formulation, we implement an active perception pipeline which is evaluated on a challenging real-world dataset. The evaluation results demonstrate that our active depth acquisition method outperforms two strong baselines for both depth completion and object pose estimation performance.
Salt and pepper noise removal method based on stationary Framelet transform with non-convex sparsity regularization
Oct 19, 2021
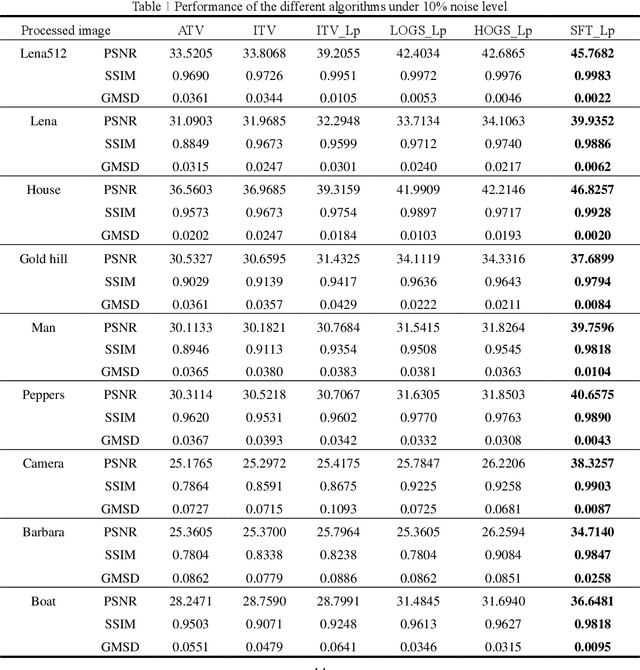
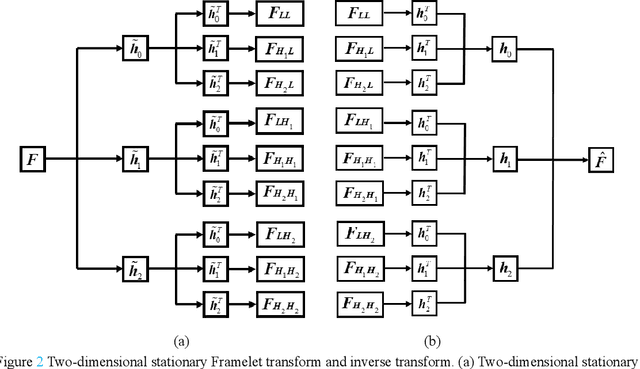
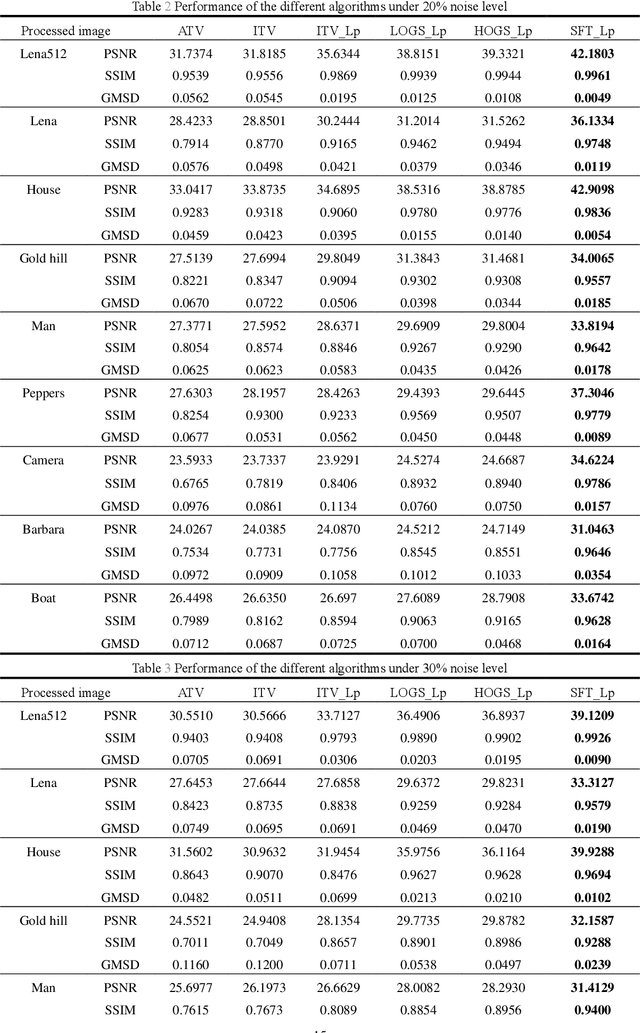
Salt and pepper noise removal is a common inverse problem in image processing, and it aims to restore image information with high quality. Traditional salt and pepper denoising methods have two limitations. First, noise characteristics are often not described accurately. For example, the noise location information is often ignored and the sparsity of the salt and pepper noise is often described by L1 norm, which cannot illustrate the sparse variables clearly. Second, conventional methods separate the contaminated image into a recovered image and a noise part, thus resulting in recovering an image with unsatisfied smooth parts and detail parts. In this study, we introduce a noise detection strategy to determine the position of the noise, and a non-convex sparsity regularization depicted by Lp quasi-norm is employed to describe the sparsity of the noise, thereby addressing the first limitation. The morphological component analysis framework with stationary Framelet transform is adopted to decompose the processed image into cartoon, texture, and noise parts to resolve the second limitation. In this framework, the stationary Framelet regularizations with different parameters control the restoration of the cartoon and texture parts. In this way, the two parts are recovered separately to avoid mutual interference. Then, the alternating direction method of multipliers (ADMM) is employed to solve the proposed model. Finally, experiments are conducted to verify the proposed method and compare it with some current state-of-the-art denoising methods. The experimental results show that the proposed method can remove salt and pepper noise while preserving the details of the processed image.
RestoreDet: Degradation Equivariant Representation for Object Detection in Low Resolution Images
Jan 07, 2022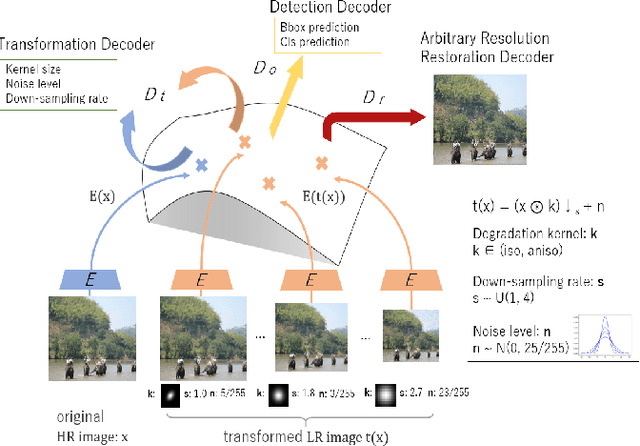
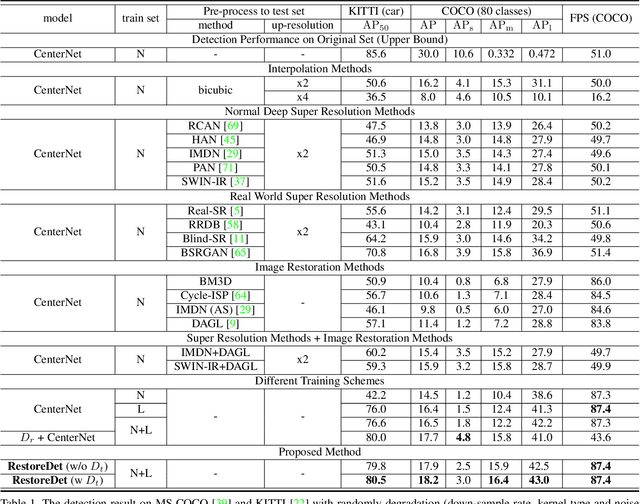
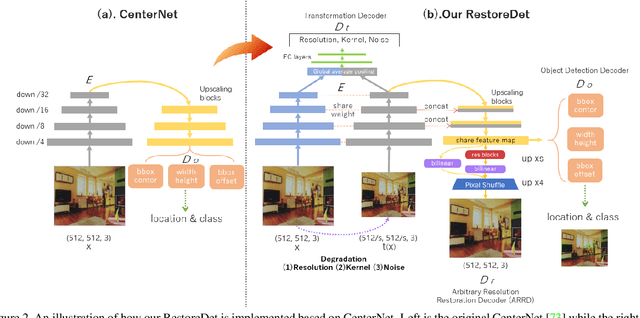
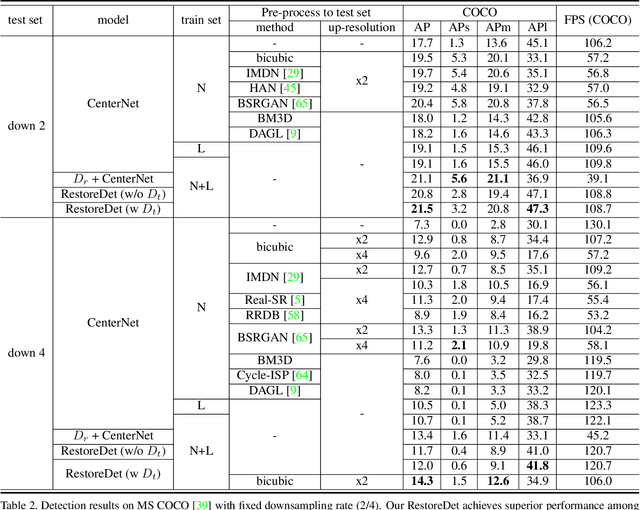
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in degraded images. However, most of these algorithms assume the degradation is fixed and known a priori. When the real degradation is unknown or differs from assumption, both the pre-processing module and the consequent high-level task such as object detection would fail. Here, we propose a novel framework, RestoreDet, to detect objects in degraded low resolution images. RestoreDet utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. Specifically, we learn this intrinsic visual structure by encoding and decoding the degradation transformation from a pair of original and randomly degraded images. The framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. RestoreDet is a generic framework that could be implemented on any mainstream object detection architectures. The extensive experiment shows that our framework based on CenterNet has achieved superior performance compared with existing methods when facing variant degradation situations. Our code would be released soon.
Improved FRQI on superconducting processors and its restrictions in the NISQ era
Oct 29, 2021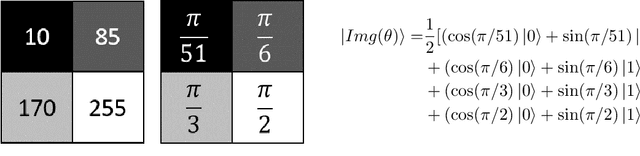
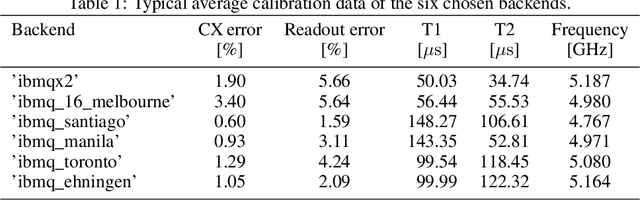

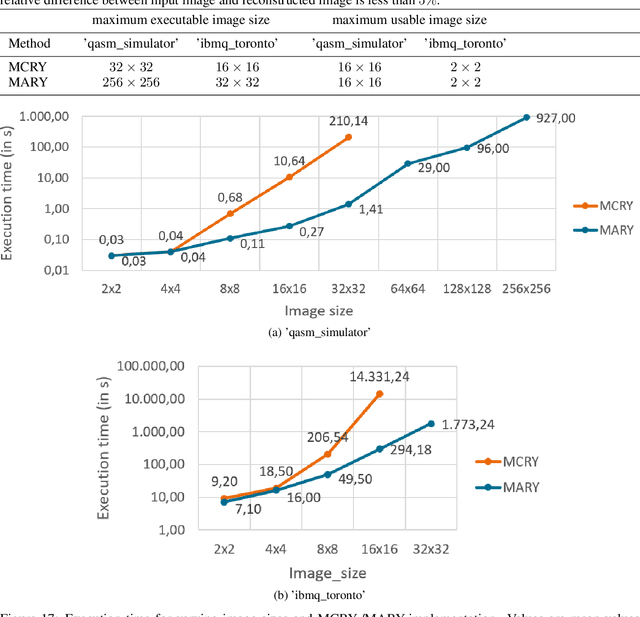
In image processing, the amount of data to be processed grows rapidly, in particular when imaging methods yield images of more than two dimensions or time series of images. Thus, efficient processing is a challenge, as data sizes may push even supercomputers to their limits. Quantum image processing promises to encode images with logarithmically less qubits than classical pixels in the image. In theory, this is a huge progress, but so far not many experiments have been conducted in practice, in particular on real backends. Often, the precise conversion of classical data to quantum states, the exact implementation, and the interpretation of the measurements in the classical context are challenging. We investigate these practical questions in this paper. In particular, we study the feasibility of the Flexible Representation of Quantum Images (FRQI). Furthermore, we check experimentally what is the limit in the current noisy intermediate-scale quantum era, i.e. up to which image size an image can be encoded, both on simulators and on real backends. Finally, we propose a method for simplifying the circuits needed for the FRQI. With our alteration, the number of gates needed, especially of the error-prone controlled-NOT gates, can be reduced. As a consequence, the size of manageable images increases.
Semantic Example Guided Image-to-Image Translation
Sep 28, 2019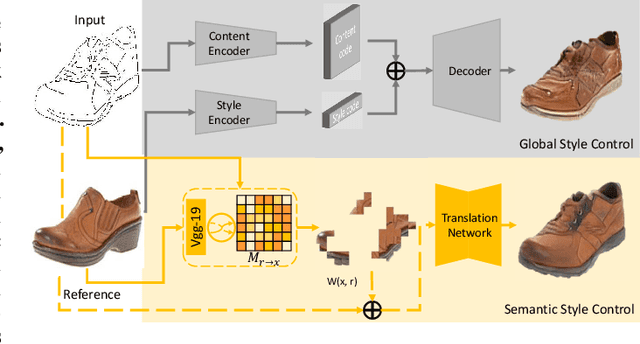


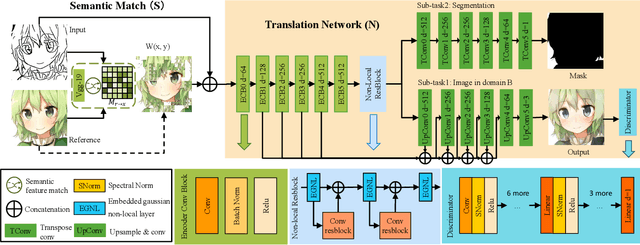
Many image-to-image (I2I) translation problems are in nature of high diversity that a single input may have various counterparts. Prior works proposed the multi-modal network that can build a many-to-many mapping between two visual domains. However, most of them are guided by sampled noises. Some others encode the reference images into a latent vector, by which the semantic information of the reference image will be washed away. In this work, we aim to provide a solution to control the output based on references semantically. Given a reference image and an input in another domain, a semantic matching is first performed between the two visual contents and generates the auxiliary image, which is explicitly encouraged to preserve semantic characteristics of the reference. A deep network then is used for I2I translation and the final outputs are expected to be semantically similar to both the input and the reference; however, no such paired data can satisfy that dual-similarity in a supervised fashion, so we build up a self-supervised framework to serve the training purpose. We improve the quality and diversity of the outputs by employing non-local blocks and a multi-task architecture. We assess the proposed method through extensive qualitative and quantitative evaluations and also presented comparisons with several state-of-art models.
Polarity Sampling: Quality and Diversity Control of Pre-Trained Generative Networks via Singular Values
Mar 03, 2022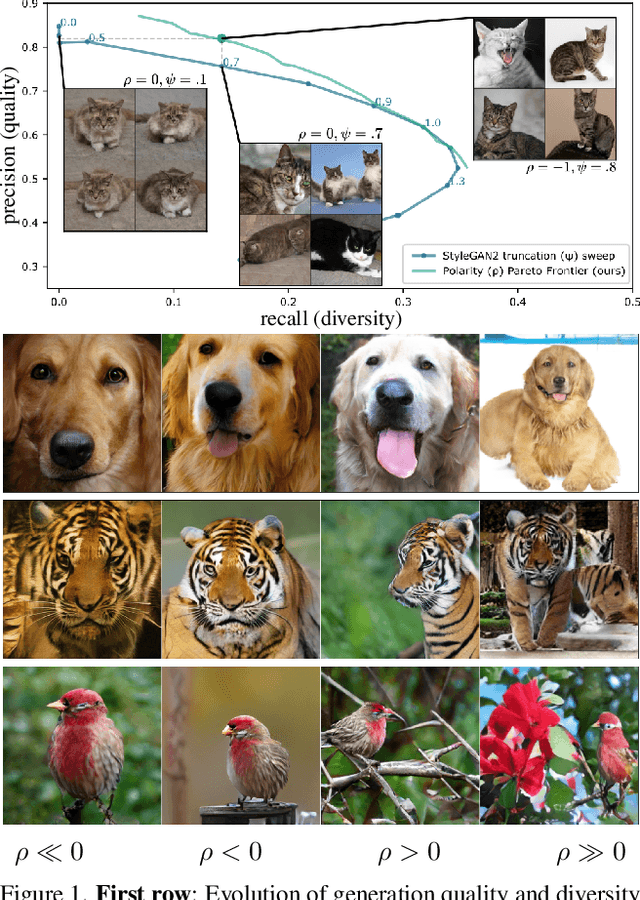
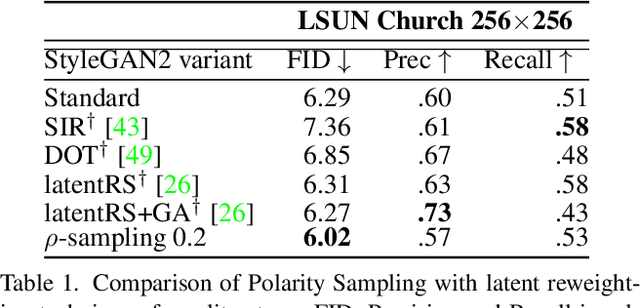
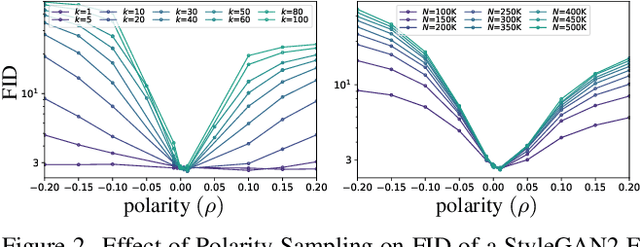
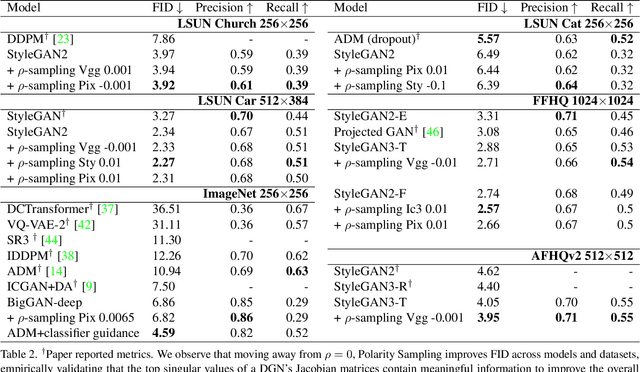
We present Polarity Sampling, a theoretically justified plug-and-play method for controlling the generation quality and diversity of pre-trained deep generative networks DGNs). Leveraging the fact that DGNs are, or can be approximated by, continuous piecewise affine splines, we derive the analytical DGN output space distribution as a function of the product of the DGN's Jacobian singular values raised to a power $\rho$. We dub $\rho$ the $\textbf{polarity}$ parameter and prove that $\rho$ focuses the DGN sampling on the modes ($\rho < 0$) or anti-modes ($\rho > 0$) of the DGN output-space distribution. We demonstrate that nonzero polarity values achieve a better precision-recall (quality-diversity) Pareto frontier than standard methods, such as truncation, for a number of state-of-the-art DGNs. We also present quantitative and qualitative results on the improvement of overall generation quality (e.g., in terms of the Frechet Inception Distance) for a number of state-of-the-art DGNs, including StyleGAN3, BigGAN-deep, NVAE, for different conditional and unconditional image generation tasks. In particular, Polarity Sampling redefines the state-of-the-art for StyleGAN2 on the FFHQ Dataset to FID 2.57, StyleGAN2 on the LSUN Car Dataset to FID 2.27 and StyleGAN3 on the AFHQv2 Dataset to FID 3.95. Demo: bit.ly/polarity-demo-colab
Don't Lie to Me! Robust and Efficient Explainability with Verified Perturbation Analysis
Feb 15, 2022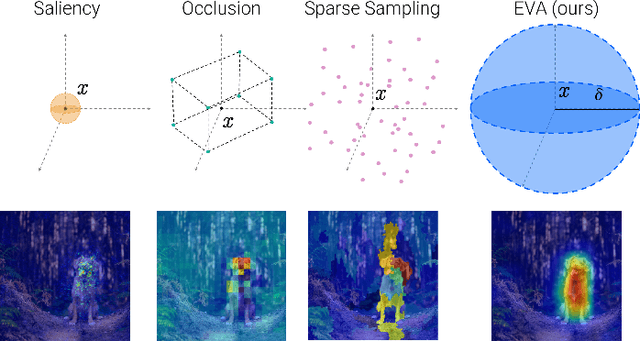
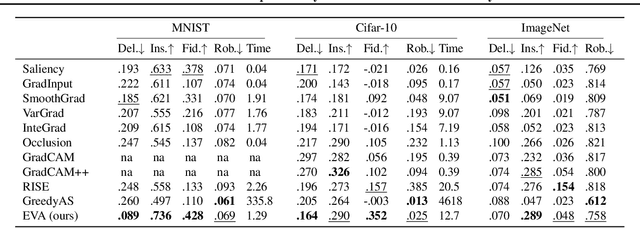
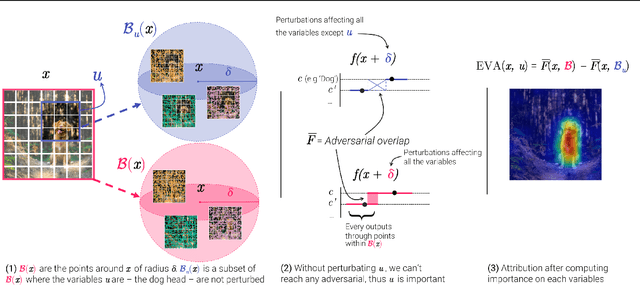
A variety of methods have been proposed to try to explain how deep neural networks make their decisions. Key to those approaches is the need to sample the pixel space efficiently in order to derive importance maps. However, it has been shown that the sampling methods used to date introduce biases and other artifacts, leading to inaccurate estimates of the importance of individual pixels and severely limit the reliability of current explainability methods. Unfortunately, the alternative -- to exhaustively sample the image space is computationally prohibitive. In this paper, we introduce EVA (Explaining using Verified perturbation Analysis) -- the first explainability method guarantee to have an exhaustive exploration of a perturbation space. Specifically, we leverage the beneficial properties of verified perturbation analysis -- time efficiency, tractability and guaranteed complete coverage of a manifold -- to efficiently characterize the input variables that are most likely to drive the model decision. We evaluate the approach systematically and demonstrate state-of-the-art results on multiple benchmarks.
Towards Boosting the Channel Attention in Real Image Denoising : Sub-band Pyramid Attention
Dec 23, 2020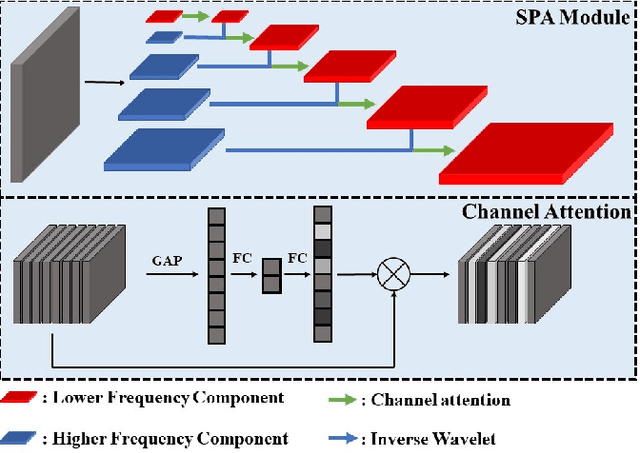
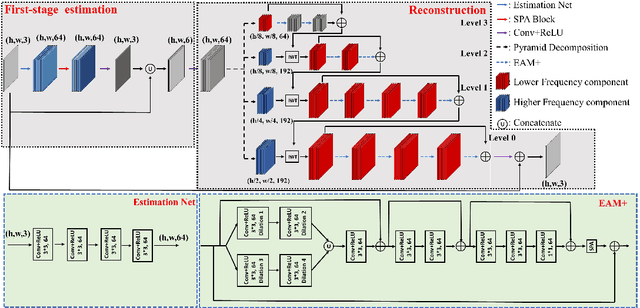


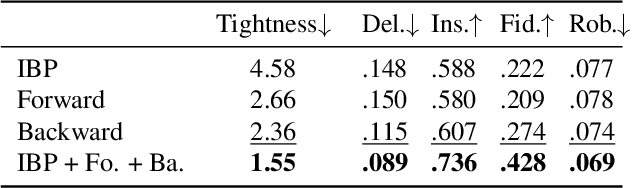
Convolutional layers in Artificial Neural Networks (ANN) treat the channel features equally without feature selection flexibility. While using ANNs for image denoising in real-world applications with unknown noise distributions, particularly structured noise with learnable patterns, modeling informative features can substantially boost the performance. Channel attention methods in real image denoising tasks exploit dependencies between the feature channels, hence being a frequency component filtering mechanism. Existing channel attention modules typically use global statics as descriptors to learn the inter-channel correlations. This method deems inefficient at learning representative coefficients for re-scaling the channels in frequency level. This paper proposes a novel Sub-band Pyramid Attention (SPA) based on wavelet sub-band pyramid to recalibrate the frequency components of the extracted features in a more fine-grained fashion. We equip the SPA blocks on a network designed for real image denoising. Experimental results show that the proposed method achieves a remarkable improvement than the benchmark naive channel attention block. Furthermore, our results show how the pyramid level affects the performance of the SPA blocks and exhibits favorable generalization capability for the SPA blocks.
SIGMA: Semantic-complete Graph Matching for Domain Adaptive Object Detection
Mar 12, 2022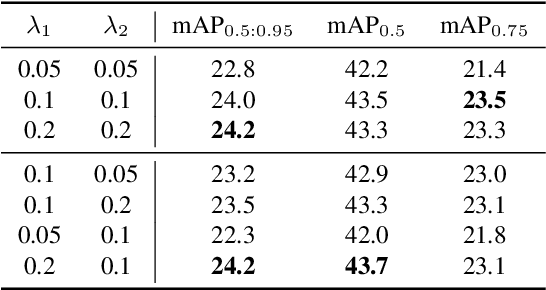

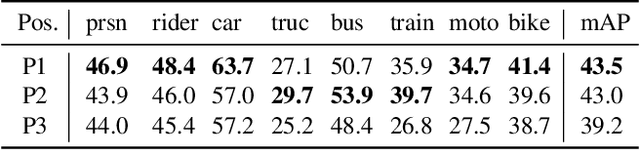
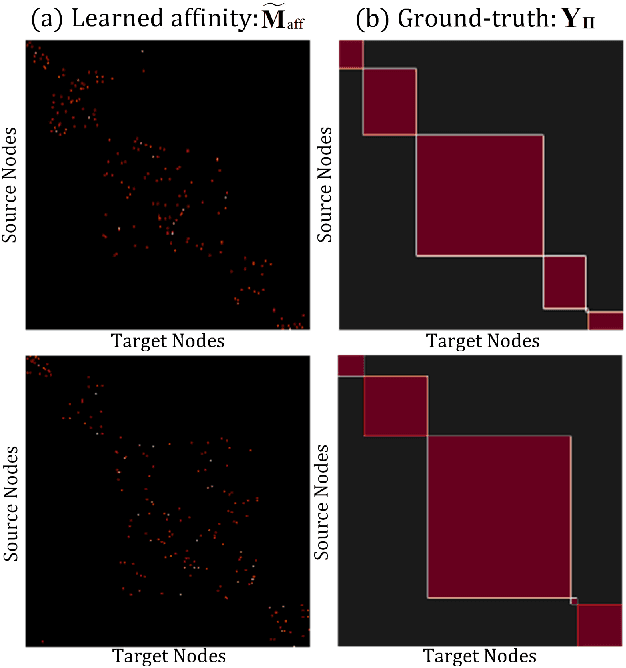
Domain Adaptive Object Detection (DAOD) leverages a labeled domain to learn an object detector generalizing to a novel domain free of annotations. Recent advances align class-conditional distributions by narrowing down cross-domain prototypes (class centers). Though great success,they ignore the significant within-class variance and the domain-mismatched semantics within the training batch, leading to a sub-optimal adaptation. To overcome these challenges, we propose a novel SemantIc-complete Graph MAtching (SIGMA) framework for DAOD, which completes mismatched semantics and reformulates the adaptation with graph matching. Specifically, we design a Graph-embedded Semantic Completion module (GSC) that completes mismatched semantics through generating hallucination graph nodes in missing categories. Then, we establish cross-image graphs to model class-conditional distributions and learn a graph-guided memory bank for better semantic completion in turn. After representing the source and target data as graphs, we reformulate the adaptation as a graph matching problem, i.e., finding well-matched node pairs across graphs to reduce the domain gap, which is solved with a novel Bipartite Graph Matching adaptor (BGM). In a nutshell, we utilize graph nodes to establish semantic-aware node affinity and leverage graph edges as quadratic constraints in a structure-aware matching loss, achieving fine-grained adaptation with a node-to-node graph matching. Extensive experiments verify that SIGMA outperforms existing works significantly. Our codes are available at https://github.com/CityU-AIM-Group/SIGMA.
Open-Edit: Open-Domain Image Manipulation with Open-Vocabulary Instructions
Aug 04, 2020
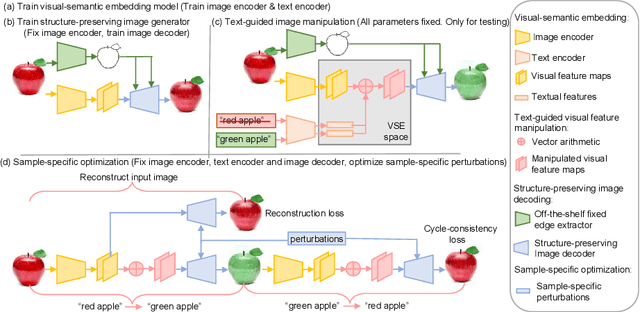


We propose a novel algorithm, named Open-Edit, which is the first attempt on open-domain image manipulation with open-vocabulary instructions. It is a challenging task considering the large variation of image domains and the lack of training supervision. Our approach takes advantage of the unified visual-semantic embedding space pretrained on a general image-caption dataset, and manipulates the embedded visual features by applying text-guided vector arithmetic on the image feature maps. A structure-preserving image decoder then generates the manipulated images from the manipulated feature maps. We further propose an on-the-fly sample-specific optimization approach with cycle-consistency constraints to regularize the manipulated images and force them to preserve details of the source images. Our approach shows promising results in manipulating open-vocabulary color, texture, and high-level attributes for various scenarios of open-domain images.