 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Edit: Open-Domain Image Manipulation with Open-Vocabulary Instructions
Paper and Code

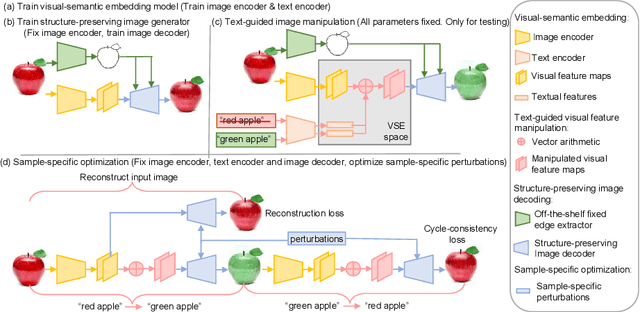


We propose a novel algorithm, named Open-Edit, which is the first attempt on open-domain image manipulation with open-vocabulary instructions. It is a challenging task considering the large variation of image domains and the lack of training supervision. Our approach takes advantage of the unified visual-semantic embedding space pretrained on a general image-caption dataset, and manipulates the embedded visual features by applying text-guided vector arithmetic on the image feature maps. A structure-preserving image decoder then generates the manipulated images from the manipulated feature maps. We further propose an on-the-fly sample-specific optimization approach with cycle-consistency constraints to regularize the manipulated images and force them to preserve details of the source images. Our approach shows promising results in manipulating open-vocabulary color, texture, and high-level attributes for various scenarios of open-domain images.