 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fine-Tuning and Training of DenseNet for Histopathology Image Representation Using TCGA Diagnostic Slides
Jan 20, 2021
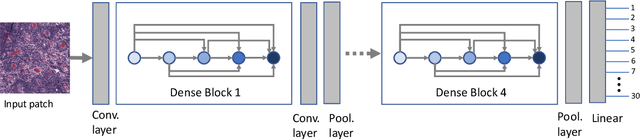
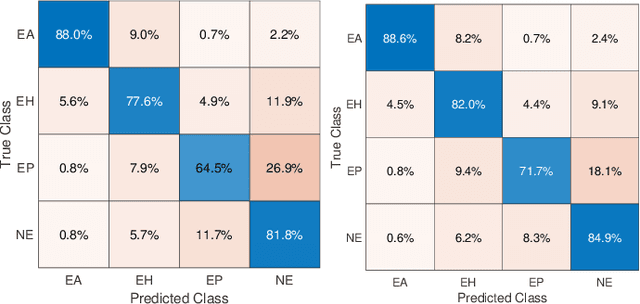
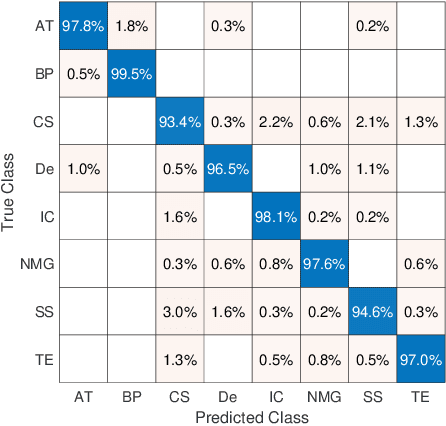
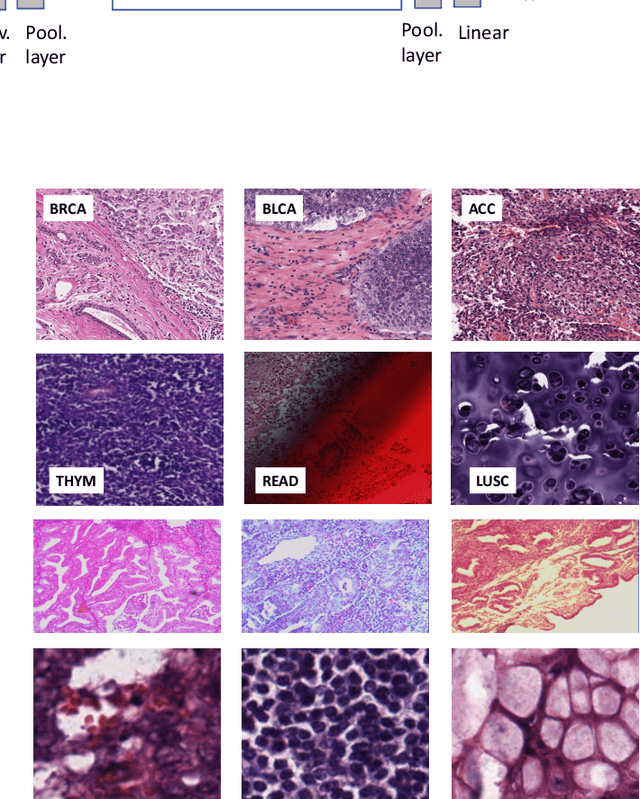
Feature vectors provided by pre-trained deep artificial neural networks have become a dominant source for image representation in recent literature. Their contribution to the performance of image analysis can be improved through finetuning. As an ultimate solution, one might even train a deep network from scratch with the domain-relevant images, a highly desirable option which is generally impeded in pathology by lack of labeled images and the computational expense. In this study, we propose a new network, namely KimiaNet, that employs the topology of the DenseNet with four dense blocks, fine-tuned and trained with histopathology images in different configurations. We used more than 240,000 image patches with 1000x1000 pixels acquired at 20x magnification through our proposed "highcellularity mosaic" approach to enable the usage of weak labels of 7,126 whole slide images of formalin-fixed paraffin-embedded human pathology samples publicly available through the The Cancer Genome Atlas (TCGA) repository. We tested KimiaNet using three public datasets, namely TCGA, endometrial cancer images, and colorectal cancer images by evaluating the performance of search and classification when corresponding features of different networks are used for image representation. As well, we designed and trained multiple convolutional batch-normalized ReLU (CBR) networks. The results show that KimiaNet provides superior results compared to the original DenseNet and smaller CBR networks when used as feature extractor to represent histopathology images.
Validation of Simulation-Based Testing: Bypassing Domain Shift with Label-to-Image Synthesis
Jun 10, 2021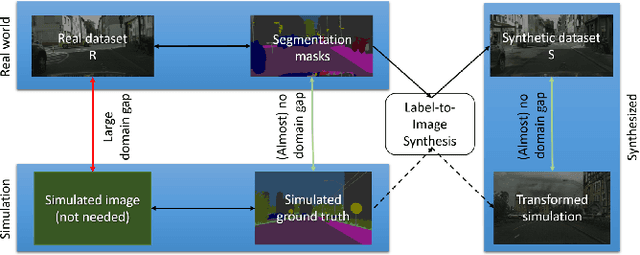
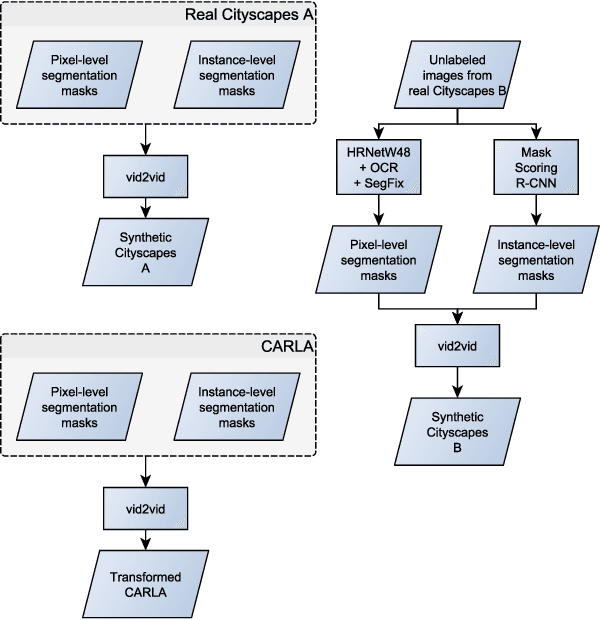


Many machine learning applications can benefit from simulated data for systematic validation - in particular if real-life data is difficult to obtain or annotate. However, since simulations are prone to domain shift w.r.t. real-life data, it is crucial to verify the transferability of the obtained results. We propose a novel framework consisting of a generative label-to-image synthesis model together with different transferability measures to inspect to what extent we can transfer testing results of semantic segmentation models from synthetic data to equivalent real-life data. With slight modifications, our approach is extendable to, e.g., general multi-class classification tasks. Grounded on the transferability analysis, our approach additionally allows for extensive testing by incorporating controlled simulations. We validate our approach empirically on a semantic segmentation task on driving scenes. Transferability is tested using correlation analysis of IoU and a learned discriminator. Although the latter can distinguish between real-life and synthetic tests, in the former we observe surprisingly strong correlations of 0.7 for both cars and pedestrians.
An Empirical Investigation of 3D Anomaly Detection and Segmentation
Mar 10, 2022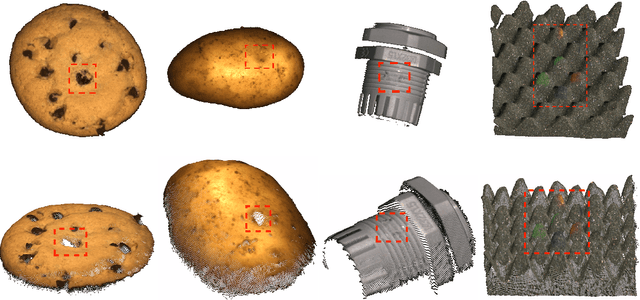

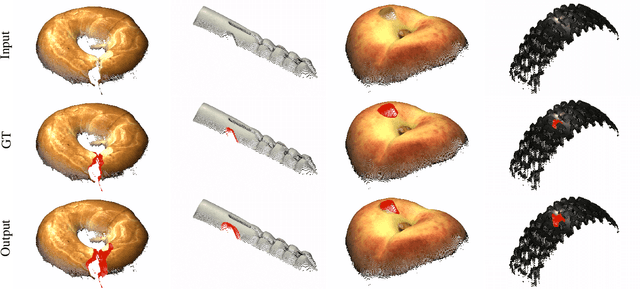
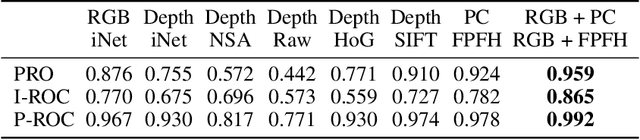
Anomaly detection and segmentation in images has made tremendous progress in recent years while 3D information has often been ignored. The objective of this paper is to further understand the benefit and role of 3D as opposed to color in image anomaly detection. Our study begins by presenting a surprising finding: standard color-only anomaly segmentation methods, when applied to 3D datasets, significantly outperform all current methods. On the other hand, we observe that color-only methods are insufficient for images containing geometric anomalies where shape cannot be unambiguously inferred from 2D. This suggests that better 3D methods are needed. We investigate different representations for 3D anomaly detection and discover that handcrafted orientation-invariant representations are unreasonably effective on this task. We uncover a simple 3D-only method that outperforms all recent approaches while not using deep learning, external pretraining datasets, or color information. As the 3D-only method cannot detect color and texture anomalies, we combine it with 2D color features, granting us the best current results by a large margin (Pixel-wise ROCAUC: 99.2%, PRO: 95.9% on MVTec 3D-AD). We conclude by discussing future challenges for 3D anomaly detection and segmentation.
Uncertainty-Aware Deep Co-training for Semi-supervised Medical Image Segmentation
Dec 02, 2021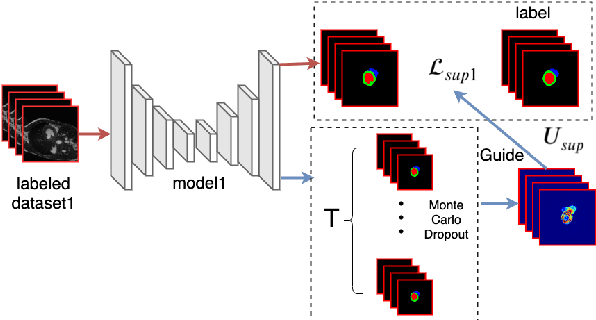
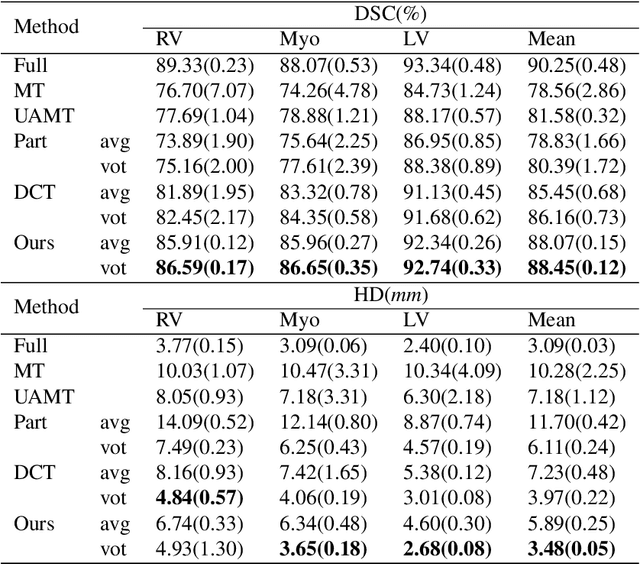
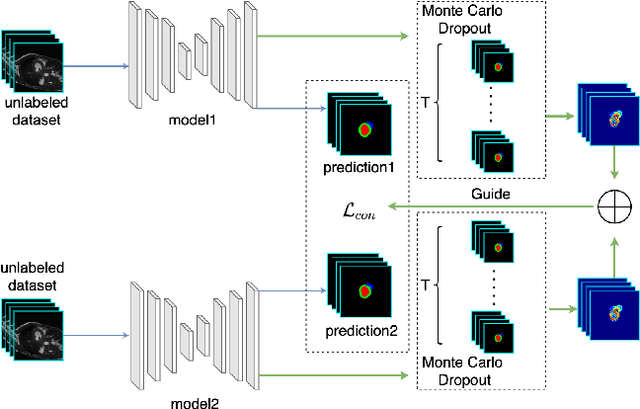
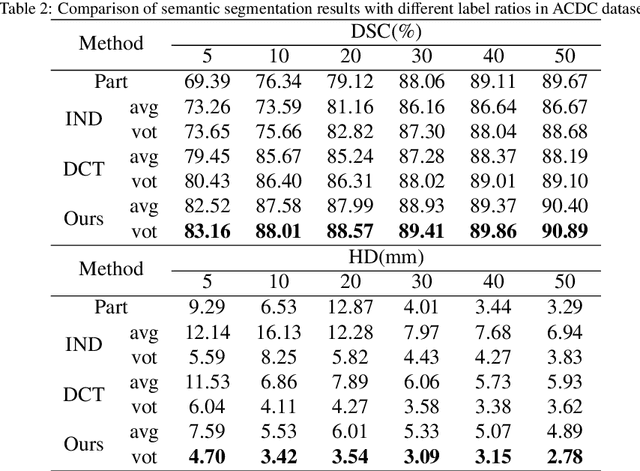
Semi-supervised learning has made significant strides in the medical domain since it alleviates the heavy burden of collecting abundant pixel-wise annotated data for semantic segmentation tasks. Existing semi-supervised approaches enhance the ability to extract features from unlabeled data with prior knowledge obtained from limited labeled data. However, due to the scarcity of labeled data, the features extracted by the models are limited in supervised learning, and the quality of predictions for unlabeled data also cannot be guaranteed. Both will impede consistency training. To this end, we proposed a novel uncertainty-aware scheme to make models learn regions purposefully. Specifically, we employ Monte Carlo Sampling as an estimation method to attain an uncertainty map, which can serve as a weight for losses to force the models to focus on the valuable region according to the characteristics of supervised learning and unsupervised learning. Simultaneously, in the backward process, we joint unsupervised and supervised losses to accelerate the convergence of the network via enhancing the gradient flow between different tasks. Quantitatively, we conduct extensive experiments on three challenging medical datasets. Experimental results show desirable improvements to state-of-the-art counterparts.
Hyperspectral Mixed Noise Removal via Subspace Representation and Weighted Low-rank Tensor Regularization
Nov 13, 2021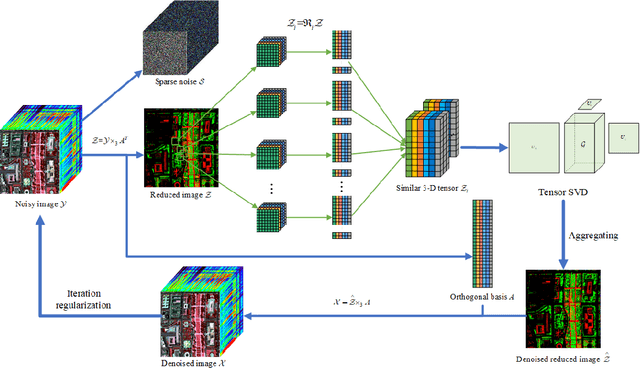


Recently, the low-rank property of different components extracted from the image has been considered in man hyperspectral image denoising methods. However, these methods usually unfold the 3D tensor to 2D matrix or 1D vector to exploit the prior information, such as nonlocal spatial self-similarity (NSS) and global spectral correlation (GSC), which break the intrinsic structure correlation of hyperspectral image (HSI) and thus lead to poor restoration quality. In addition, most of them suffer from heavy computational burden issues due to the involvement of singular value decomposition operation on matrix and tensor in the original high-dimensionality space of HSI. We employ subspace representation and the weighted low-rank tensor regularization (SWLRTR) into the model to remove the mixed noise in the hyperspectral image. Specifically, to employ the GSC among spectral bands, the noisy HSI is projected into a low-dimensional subspace which simplified calculation. After that, a weighted low-rank tensor regularization term is introduced to characterize the priors in the reduced image subspace. Moreover, we design an algorithm based on alternating minimization to solve the nonconvex problem. Experiments on simulated and real datasets demonstrate that the SWLRTR method performs better than other hyperspectral denoising methods quantitatively and visually.
Salt and pepper noise removal method based on stationary Framelet transform with non-convex sparsity regularization
Nov 02, 2021
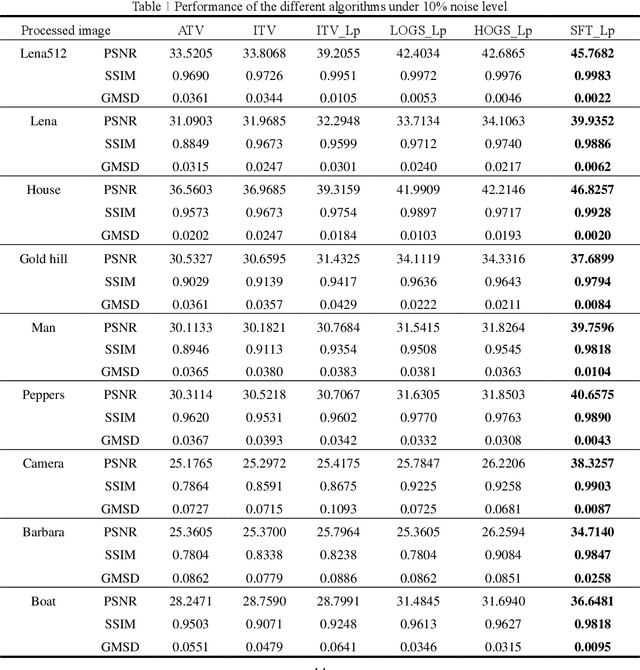
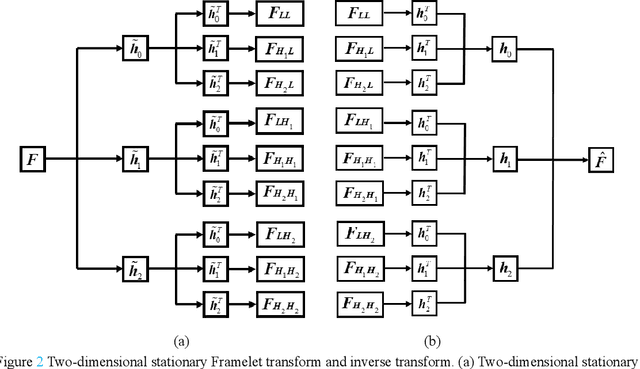
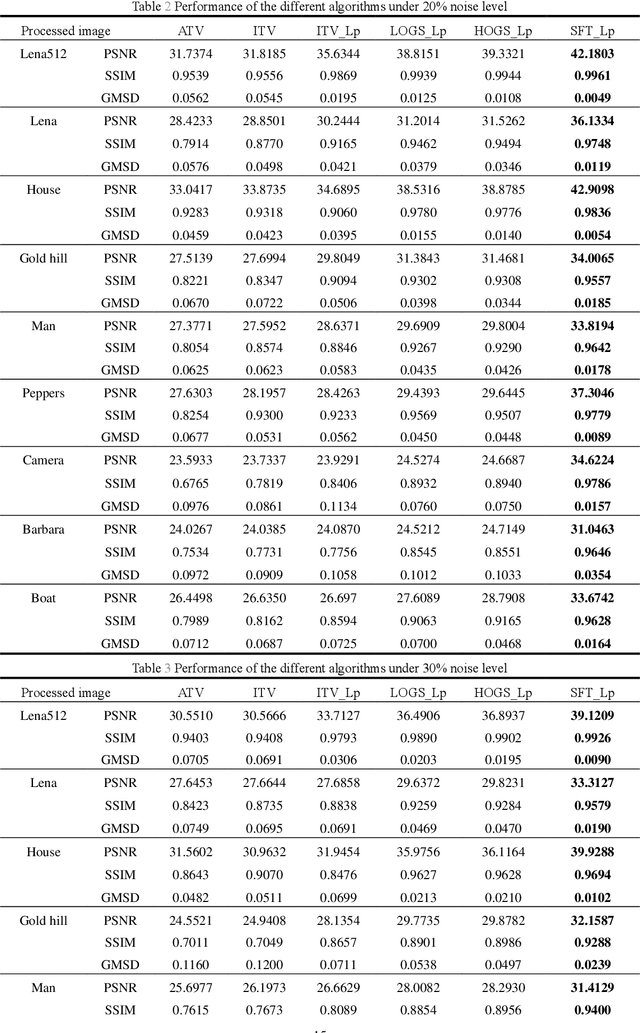
Salt and pepper noise removal is a common inverse problem in image processing. Traditional denoising methods have two limitations. First, noise characteristics are often not described accurately. For example, the noise location information is often ignored and the sparsity of the salt and pepper noise is often described by L1 norm, which cannot illustrate the sparse variables clearly. Second, conventional methods separate the contaminated image into a recovered image and a noise part, thus resulting in recovering an image with unsatisfied smooth parts and detail parts. In this study, we introduce a noise detection strategy to determine the position of the noise, and a non-convex sparsity regularization depicted by Lp quasi-norm is employed to describe the sparsity of the noise, thereby addressing the first limitation. The morphological component analysis framework with stationary Framelet transform is adopted to decompose the processed image into cartoon, texture, and noise parts to resolve the second limitation. Then, the alternating direction method of multipliers (ADMM) is employed to solve the proposed model. Finally, experiments are conducted to verify the proposed method and compare it with some current state-of-the-art denoising methods. The experimental results show that the proposed method can remove salt and pepper noise while preserving the details of the processed image.
Application of DatasetGAN in medical imaging: preliminary studies
Feb 27, 2022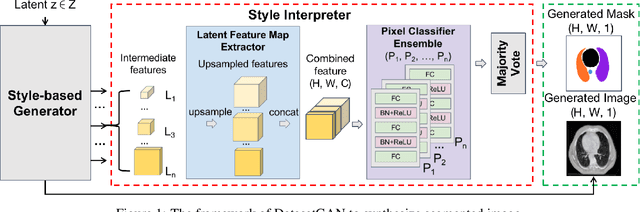

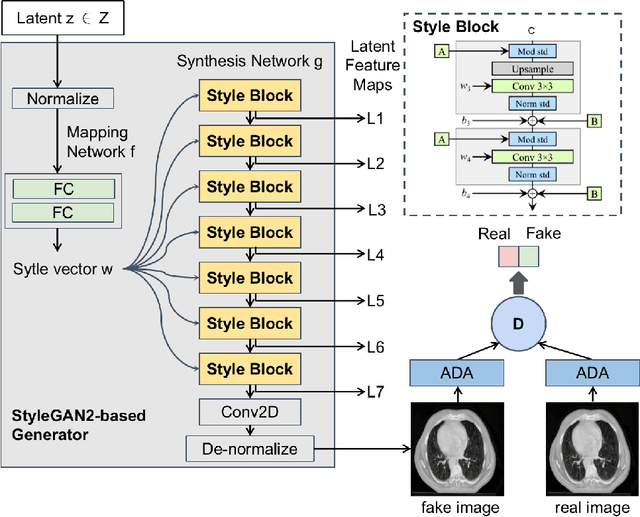

Generative adversarial networks (GANs) have been widely investigated for many potential applications in medical imaging. DatasetGAN is a recently proposed framework based on modern GANs that can synthesize high-quality segmented images while requiring only a small set of annotated training images. The synthesized annotated images could be potentially employed for many medical imaging applications, where images with segmentation information are required. However, to the best of our knowledge, there are no published studies focusing on its applications to medical imaging. In this work, preliminary studies were conducted to investigate the utility of DatasetGAN in medical imaging. Three improvements were proposed to the original DatasetGAN framework, considering the unique characteristics of medical images. The synthesized segmented images by DatasetGAN were visually evaluated. The trained DatasetGAN was further analyzed by evaluating the performance of a pre-defined image segmentation technique, which was trained by the use of the synthesized datasets. The effectiveness, concerns, and potential usage of DatasetGAN were discussed.
Dimensions of Motion: Learning to Predict a Subspace of Optical Flow from a Single Image
Jan 06, 2022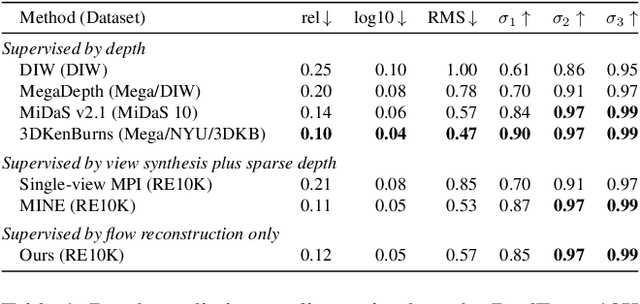
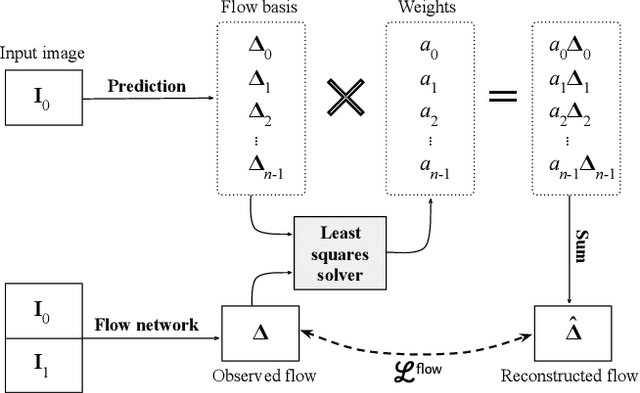
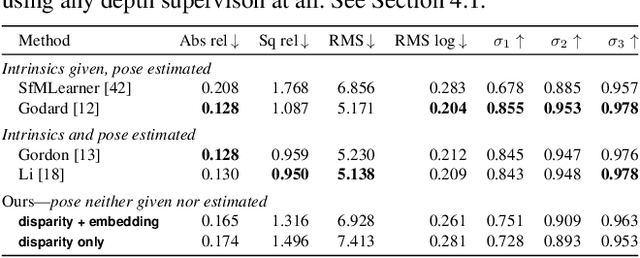
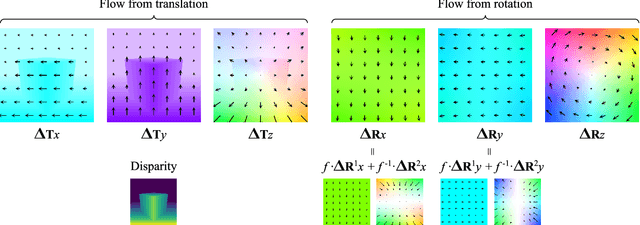
We introduce the problem of predicting, from a single video frame, a low-dimensional subspace of optical flow which includes the actual instantaneous optical flow. We show how several natural scene assumptions allow us to identify an appropriate flow subspace via a set of basis flow fields parameterized by disparity and a representation of object instances. The flow subspace, together with a novel loss function, can be used for the tasks of predicting monocular depth or predicting depth plus an object instance embedding. This provides a new approach to learning these tasks in an unsupervised fashion using monocular input video without requiring camera intrinsics or poses.
Weighted Histogram Equalization Using Entropy of Probability Density Function
Nov 22, 2021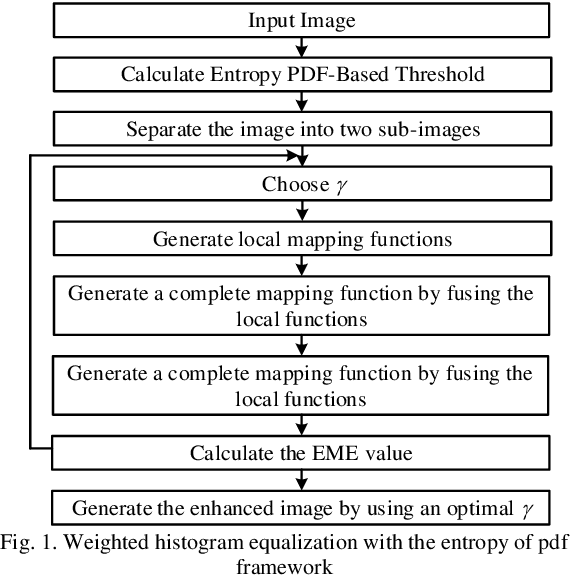
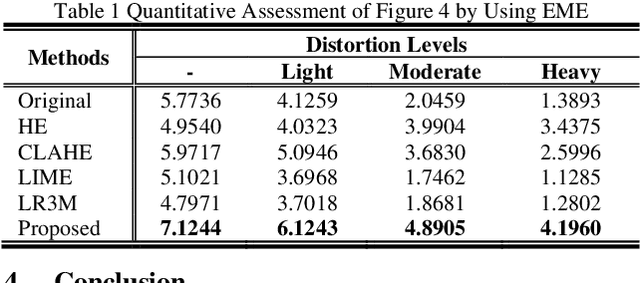
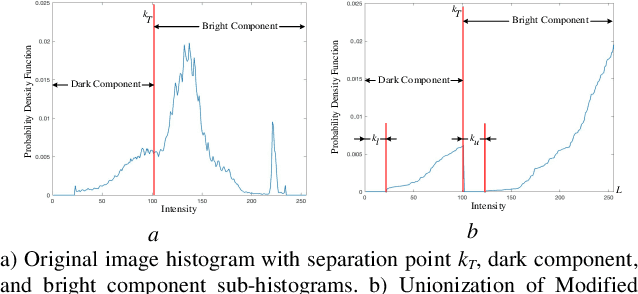

Low-contrast image enhancement is essential for high-quality image display and other visual applications. However, it is a challenging task as the enhancement is expected to increase the visibility of an image while maintaining its naturalness. In this paper, the weighted histogram equalization using the entropy of the probability density function is proposed. The computation of the local mapping functions utilizes the relationship between non-height bin and height bin distributions. Finally, the complete tone mapping function is produced by concatenating local mapping functions. Computer simulation results on the CSIQ dataset demonstrate that the proposed method produces images with higher visibility and visual quality, which outperforms traditional and recently proposed contrast enhancement algorithms methods in qualitative and quantitative metrics.
Cloud Removal from Satellite Images
Dec 23, 2021

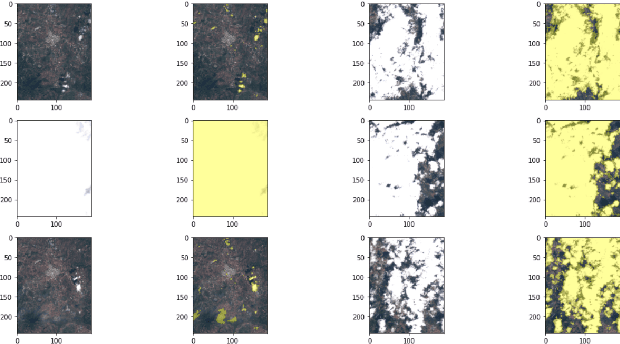
In this report, we have analyzed available cloud detection technique using sentinel hub. We have also implemented spatial attention generative adversarial network and improved quality of generated image compared to previous solution [7].