 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FisherMatch: Semi-Supervised Rotation Regression via Entropy-based Filtering
Mar 29, 2022
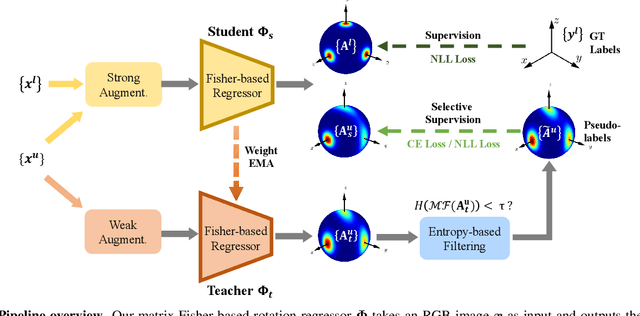
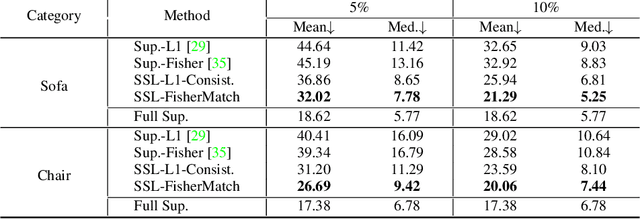
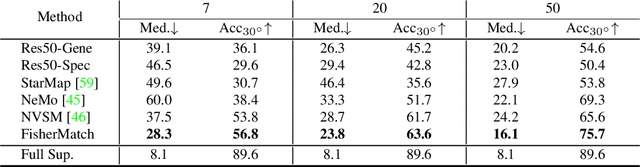
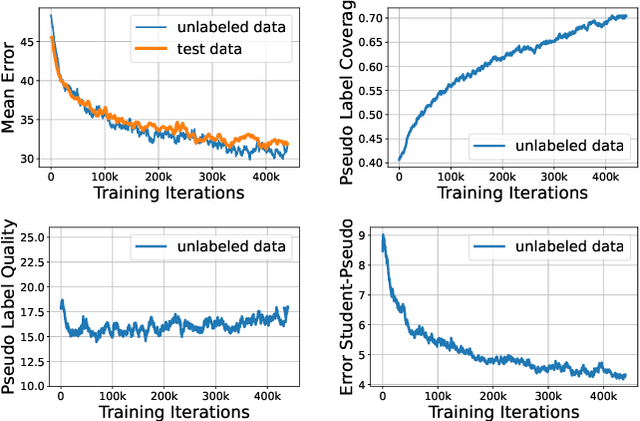
Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. Recent works achieve good performance relying on a large amount of expensive-to-obtain labeled data. To reduce the amount of supervision, we for the first time propose a general framework, FisherMatch, for semi-supervised rotation regression, without assuming any domain-specific knowledge or paired data. Inspired by the popular semi-supervised approach, FixMatch, we propose to leverage pseudo label filtering to facilitate the information flow from labeled data to unlabeled data in a teacher-student mutual learning framework. However, incorporating the pseudo label filtering mechanism into semi-supervised rotation regression is highly non-trivial, mainly due to the lack of a reliable confidence measure for rotation prediction. In this work, we propose to leverage matrix Fisher distribution to build a probabilistic model of rotation and devise a matrix Fisher-based regressor for jointly predicting rotation along with its prediction uncertainty. We then propose to use the entropy of the predicted distribution as a confidence measure, which enables us to perform pseudo label filtering for rotation regression. For supervising such distribution-like pseudo labels, we further investigate the problem of how to enforce loss between two matrix Fisher distributions. Our extensive experiments show that our method can work well even under very low labeled data ratios on different benchmarks, achieving significant and consistent performance improvement over supervised learning and other semi-supervised learning baselines. Our project page is at https://yd-yin.github.io/FisherMatch.
FPIC: A Novel Semantic Dataset for Optical PCB Assurance
Feb 17, 2022
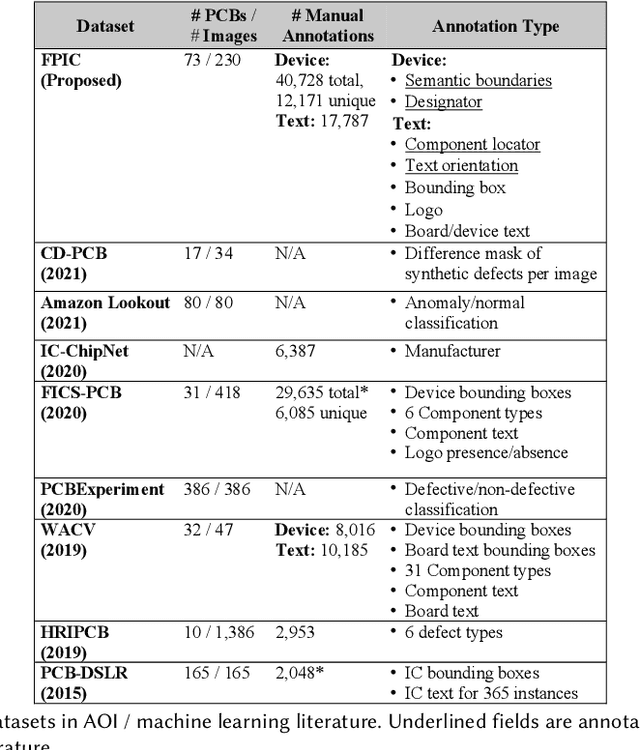
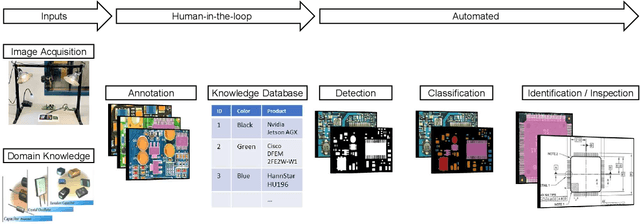
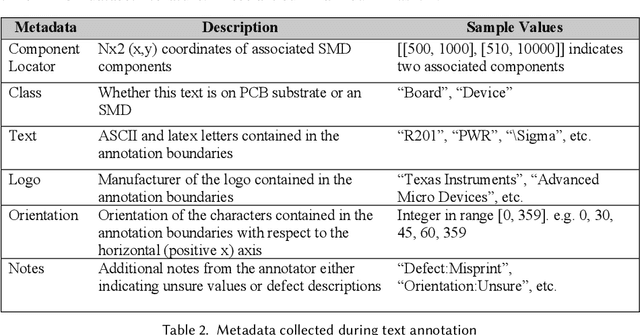
The continued outsourcing of printed circuit board (PCB) fabrication to overseas venues necessitates increased hardware assurance capabilities. Toward this end, several automated optical inspection (AOI) techniques have been proposed in the past exploring various aspects of PCB images acquired using digital cameras. In this work, we review state-of-the-art AOI techniques and observed the strong, rapid trend toward machine learning (ML) solutions. These require significant amounts of labeled ground truth data, which is lacking in the publicly available PCB data space. We propose the FICS PBC Image Collection (FPIC) dataset to address this bottleneck in available large-volume, diverse, semantic annotations. Additionally, this work covers the potential increase in hardware security capabilities and observed methodological distinctions highlighted during data collection.
Human Imperceptible Attacks and Applications to Improve Fairness
Nov 30, 2021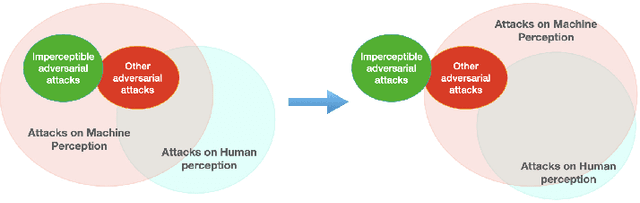

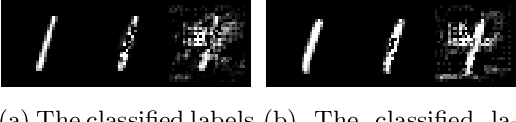
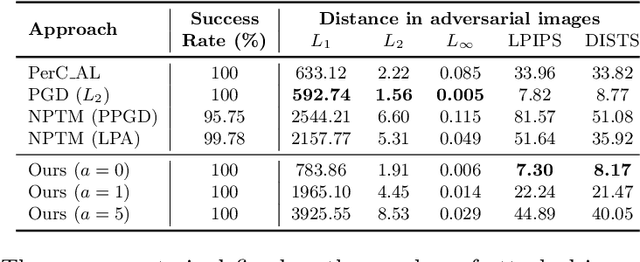
Modern neural networks are able to perform at least as well as humans in numerous tasks involving object classification and image generation. However, small perturbations which are imperceptible to humans may significantly degrade the performance of well-trained deep neural networks. We provide a Distributionally Robust Optimization (DRO) framework which integrates human-based image quality assessment methods to design optimal attacks that are imperceptible to humans but significantly damaging to deep neural networks. Through extensive experiments, we show that our attack algorithm generates better-quality (less perceptible to humans) attacks than other state-of-the-art human imperceptible attack methods. Moreover, we demonstrate that DRO training using our optimally designed human imperceptible attacks can improve group fairness in image classification. Towards the end, we provide an algorithmic implementation to speed up DRO training significantly, which could be of independent interest.
Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
Feb 17, 2021
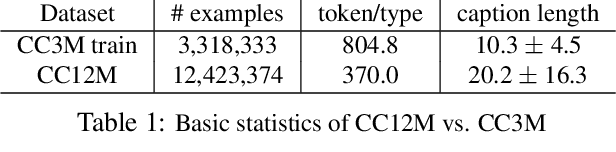

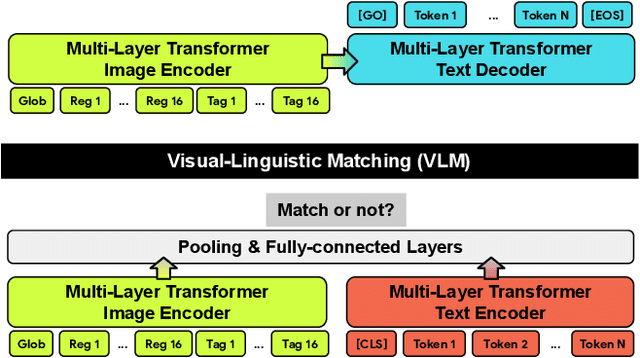
The availability of large-scale image captioning and visual question answering datasets has contributed significantly to recent successes in vision-and-language pre-training. However, these datasets are often collected with overrestrictive requirements, inherited from their original target tasks (e.g., image caption generation), which limit the resulting dataset scale and diversity. We take a step further in pushing the limits of vision-and-language pre-training data by relaxing the data collection pipeline used in Conceptual Captions 3M (CC3M) [Sharma et al. 2018] and introduce the Conceptual 12M (CC12M), a dataset with 12 million image-text pairs specifically meant to be used for vision-and-language pre-training. We perform an analysis of this dataset, as well as benchmark its effectiveness against CC3M on multiple downstream tasks with an emphasis on long-tail visual recognition. The quantitative and qualitative results clearly illustrate the benefit of scaling up pre-training data for vision-and-language tasks, as indicated by the new state-of-the-art results on both the nocaps and Conceptual Captions benchmarks.
Ray-transfer functions for camera simulation of 3D scenes with hidden lens design
Feb 23, 2022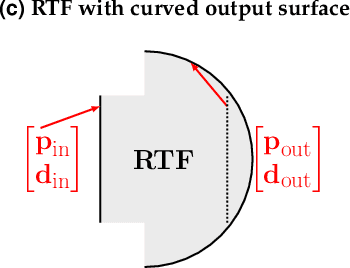

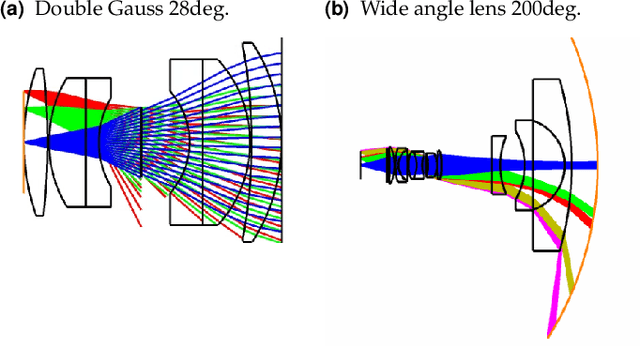
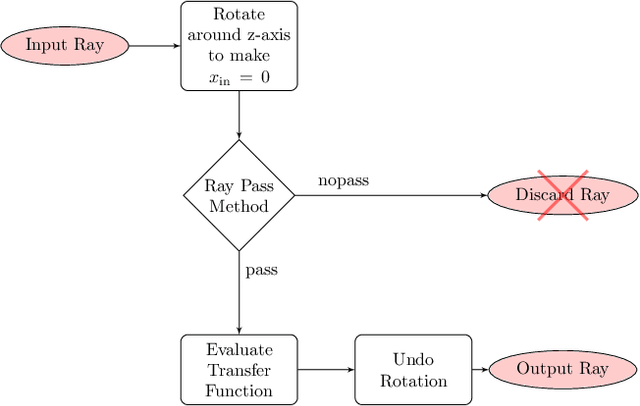
Combining image sensor simulation tools (e.g., ISETCam) with physically based ray tracing (e.g., PBRT) offers possibilities for designing and evaluating novel imaging systems as well as for synthesizing physically accurate, labeled images for machine learning. One practical limitation has been simulating the optics precisely: Lens manufacturers generally prefer to keep lens design confidential. We present a pragmatic solution to this problem using a black box lens model in Zemax; such models provide necessary optical information while preserving the lens designer's intellectual property. First, we describe and provide software to construct a polynomial ray transfer function that characterizes how rays entering the lens at any position and angle subsequently exit the lens. We implement the ray-transfer calculation as a camera model in PBRT and confirm that the PBRT ray-transfer calculations match the Zemax lens calculations for edge spread functions and relative illumination.
MatchFormer: Interleaving Attention in Transformers for Feature Matching
Mar 21, 2022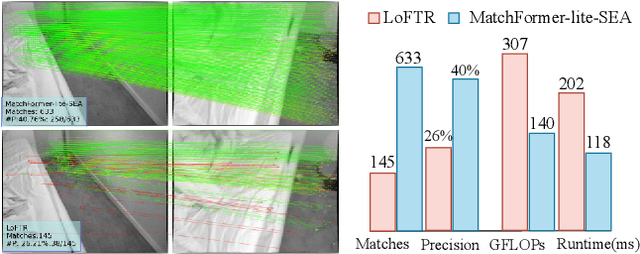
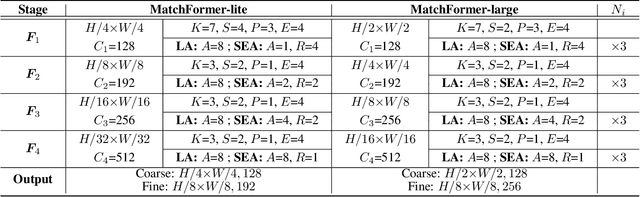
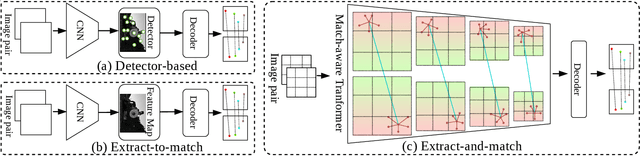
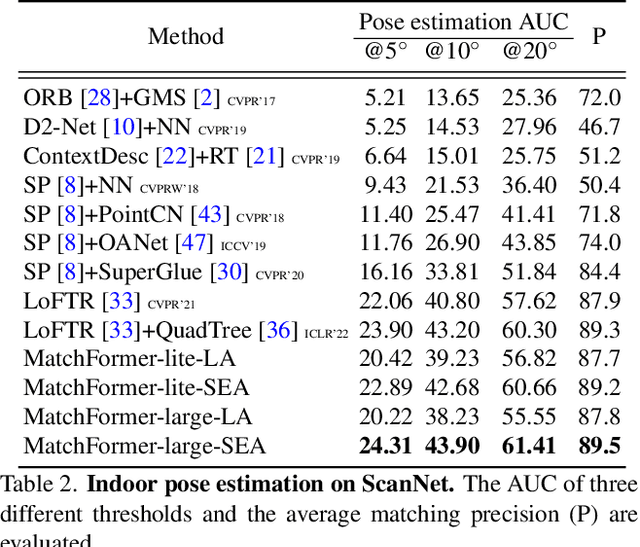
Local feature matching is a computationally intensive task at the subpixel level. While detector-based methods coupled with feature descriptors struggle in low-texture scenes, CNN-based methods with a sequential extract-to-match pipeline, fail to make use of the matching capacity of the encoder and tend to overburden the decoder for matching. In contrast, we propose a novel hierarchical extract-and-match transformer, termed as MatchFormer. Inside each stage of the hierarchical encoder, we interleave self-attention for feature extraction and cross-attention for feature matching, enabling a human-intuitive extract-and-match scheme. Such a match-aware encoder releases the overloaded decoder and makes the model highly efficient. Further, combining self- and cross-attention on multi-scale features in a hierarchical architecture improves matching robustness, particularly in low-texture indoor scenes or with less outdoor training data. Thanks to such a strategy, MatchFormer is a multi-win solution in efficiency, robustness, and precision. Compared to the previous best method in indoor pose estimation, our lite MatchFormer has only 45% GFLOPs, yet achieves a +1.3% precision gain and a 41% running speed boost. The large MatchFormer reaches state-of-the-art on four different benchmarks, including indoor pose estimation (ScanNet), outdoor pose estimation (MegaDepth), homography estimation and image matching (HPatch), and visual localization (InLoc). Code will be made publicly available at https://github.com/jamycheung/MatchFormer.
HoughCL: Finding Better Positive Pairs in Dense Self-supervised Learning
Nov 21, 2021
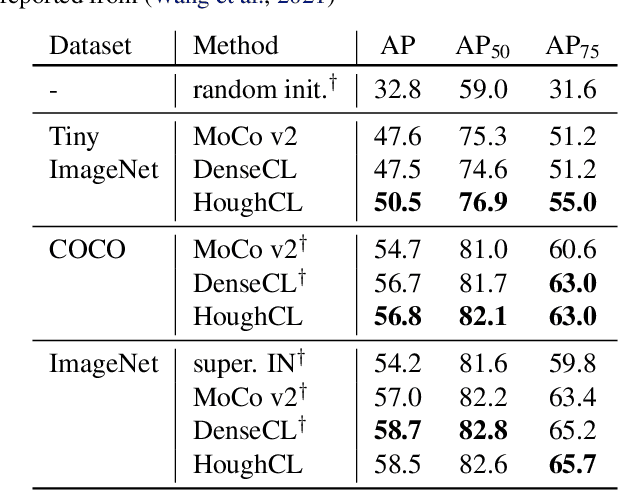
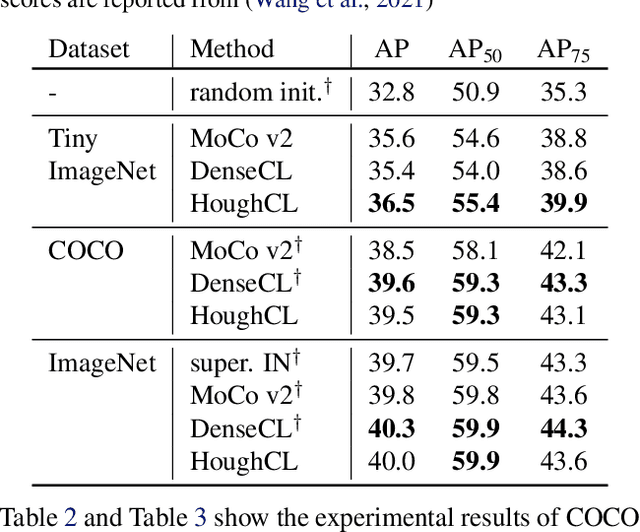
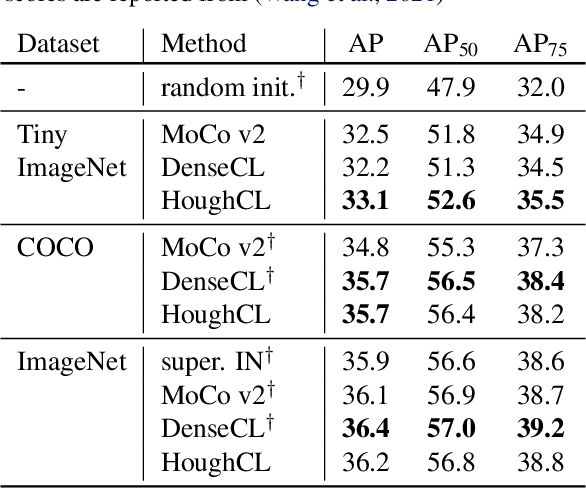
Recently, self-supervised methods show remarkable achievements in image-level representation learning. Nevertheless, their image-level self-supervisions lead the learned representation to sub-optimal for dense prediction tasks, such as object detection, instance segmentation, etc. To tackle this issue, several recent self-supervised learning methods have extended image-level single embedding to pixel-level dense embeddings. Unlike image-level representation learning, due to the spatial deformation of augmentation, it is difficult to sample pixel-level positive pairs. Previous studies have sampled pixel-level positive pairs using the winner-takes-all among similarity or thresholding warped distance between dense embeddings. However, these naive methods can be struggled by background clutter and outliers problems. In this paper, we introduce Hough Contrastive Learning (HoughCL), a Hough space based method that enforces geometric consistency between two dense features. HoughCL achieves robustness against background clutter and outliers. Furthermore, compared to baseline, our dense positive pairing method has no additional learnable parameters and has a small extra computation cost. Compared to previous works, our method shows better or comparable performance on dense prediction fine-tuning tasks.
Deep-ASPECTS: A Segmentation-Assisted Model for Stroke Severity Measurement
Mar 17, 2022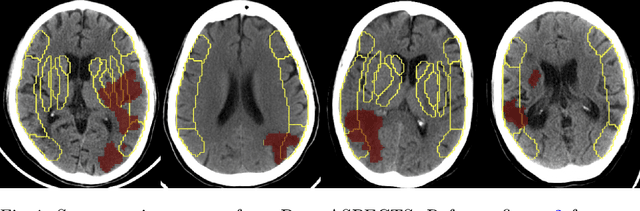
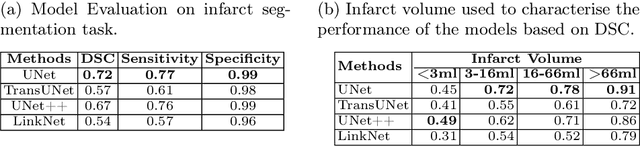
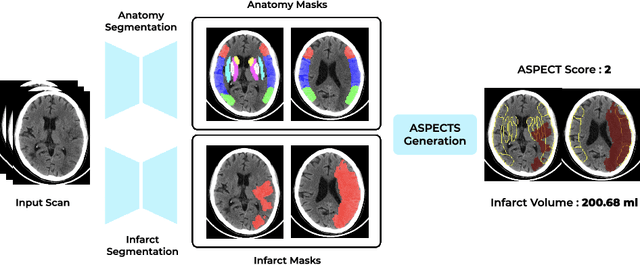

A stroke occurs when an artery in the brain ruptures and bleeds or when the blood supply to the brain is cut off. Blood and oxygen cannot reach the brain's tissues due to the rupture or obstruction resulting in tissue death. The Middle cerebral artery (MCA) is the largest cerebral artery and the most commonly damaged vessel in stroke. The quick onset of a focused neurological deficit caused by interruption of blood flow in the territory supplied by the MCA is known as an MCA stroke. Alberta stroke programme early CT score (ASPECTS) is used to estimate the extent of early ischemic changes in patients with MCA stroke. This study proposes a deep learning-based method to score the CT scan for ASPECTS. Our work has three highlights. First, we propose a novel method for medical image segmentation for stroke detection. Second, we show the effectiveness of AI solution for fully-automated ASPECT scoring with reduced diagnosis time for a given non-contrast CT (NCCT) Scan. Our algorithms show a dice similarity coefficient of 0.64 for the MCA anatomy segmentation and 0.72 for the infarcts segmentation. Lastly, we show that our model's performance is inline with inter-reader variability between radiologists.
Effect of Prior-based Losses on Segmentation Performance: A Benchmark
Jan 07, 2022
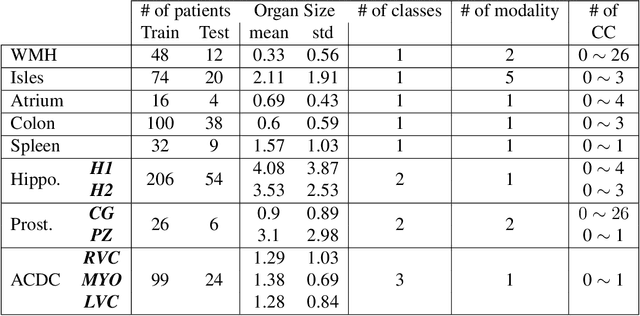

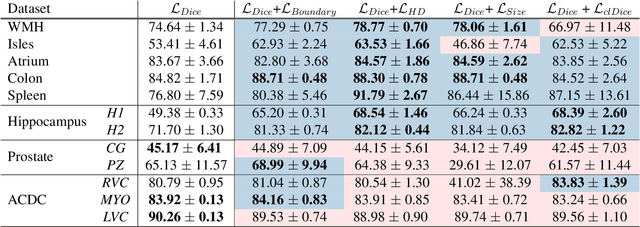
Today, deep convolutional neural networks (CNNs) have demonstrated state-of-the-art performance for medical image segmentation, on various imaging modalities and tasks. Despite early success, segmentation networks may still generate anatomically aberrant segmentations, with holes or inaccuracies near the object boundaries. To enforce anatomical plausibility, recent research studies have focused on incorporating prior knowledge such as object shape or boundary, as constraints in the loss function. Prior integrated could be low-level referring to reformulated representations extracted from the ground-truth segmentations, or high-level representing external medical information such as the organ's shape or size. Over the past few years, prior-based losses exhibited a rising interest in the research field since they allow integration of expert knowledge while still being architecture-agnostic. However, given the diversity of prior-based losses on different medical imaging challenges and tasks, it has become hard to identify what loss works best for which dataset. In this paper, we establish a benchmark of recent prior-based losses for medical image segmentation. The main objective is to provide intuition onto which losses to choose given a particular task or dataset. To this end, four low-level and high-level prior-based losses are selected. The considered losses are validated on 8 different datasets from a variety of medical image segmentation challenges including the Decathlon, the ISLES and the WMH challenge. Results show that whereas low-level prior-based losses can guarantee an increase in performance over the Dice loss baseline regardless of the dataset characteristics, high-level prior-based losses can increase anatomical plausibility as per data characteristics.
TransformNet: Self-supervised representation learning through predicting geometric transformations
Feb 08, 2022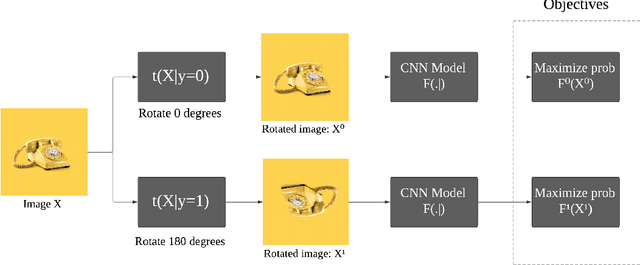
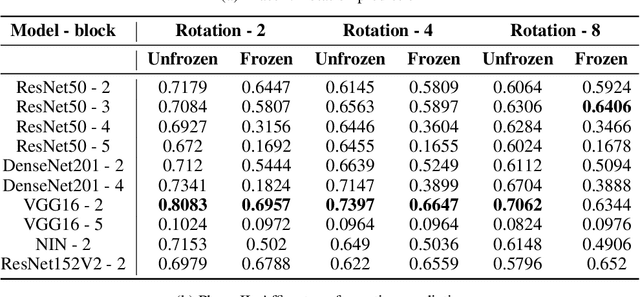
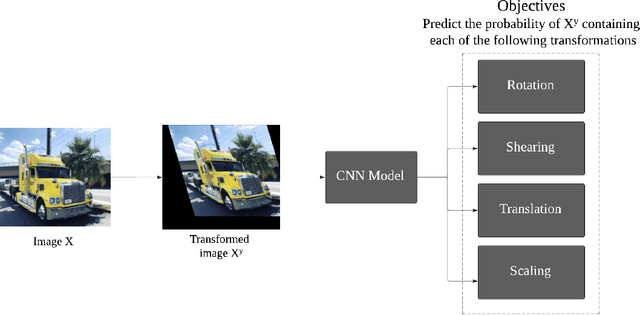

Deep neural networks need a big amount of training data, while in the real world there is a scarcity of data available for training purposes. To resolve this issue unsupervised methods are used for training with limited data. In this report, we describe the unsupervised semantic feature learning approach for recognition of the geometric transformation applied to the input data. The basic concept of our approach is that if someone is unaware of the objects in the images, he/she would not be able to quantitatively predict the geometric transformation that was applied to them. This self supervised scheme is based on pretext task and the downstream task. The pretext classification task to quantify the geometric transformations should force the CNN to learn high-level salient features of objects useful for image classification. In our baseline model, we define image rotations by multiples of 90 degrees. The CNN trained on this pretext task will be used for the classification of images in the CIFAR-10 dataset as a downstream task. we run the baseline method using various models, including ResNet, DenseNet, VGG-16, and NIN with a varied number of rotations in feature extracting and fine-tuning settings. In extension of this baseline model we experiment with transformations other than rotation in pretext task. We compare performance of selected models in various settings with different transformations applied to images,various data augmentation techniques as well as using different optimizers. This series of different type of experiments will help us demonstrate the recognition accuracy of our self-supervised model when applied to a downstream task of classification.