 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheX-GPT: Harnessing Large Language Models for Enhanced Chest X-ray Report Labeling
Jan 21, 2024



Free-text radiology reports present a rich data source for various medical tasks, but effectively labeling these texts remains challenging. Traditional rule-based labeling methods fall short of capturing the nuances of diverse free-text patterns. Moreover, models using expert-annotated data are limited by data scarcity and pre-defined classes, impacting their performance, flexibility and scalability. To address these issues, our study offers three main contributions: 1) We demonstrate the potential of GPT as an adept labeler using carefully designed prompts. 2) Utilizing only the data labeled by GPT, we trained a BERT-based labeler, CheX-GPT, which operates faster and more efficiently than its GPT counterpart. 3) To benchmark labeler performance, we introduced a publicly available expert-annotated test set, MIMIC-500, comprising 500 cases from the MIMIC validation set. Our findings demonstrate that CheX-GPT not only excels in labeling accuracy over existing models, but also showcases superior efficiency, flexibility, and scalability, supported by our introduction of the MIMIC-500 dataset for robust benchmarking. Code and models are available at https://github.com/kakaobrain/CheXGPT.
Open-Vocabulary Object Detection using Pseudo Caption Labels
Mar 23, 2023



Recent open-vocabulary detection methods aim to detect novel objects by distilling knowledge from vision-language models (VLMs) trained on a vast amount of image-text pairs. To improve the effectiveness of these methods, researchers have utilized datasets with a large vocabulary that contains a large number of object classes, under the assumption that such data will enable models to extract comprehensive knowledge on the relationships between various objects and better generalize to unseen object classes. In this study, we argue that more fine-grained labels are necessary to extract richer knowledge about novel objects, including object attributes and relationships, in addition to their names. To address this challenge, we propose a simple and effective method named Pseudo Caption Labeling (PCL), which utilizes an image captioning model to generate captions that describe object instances from diverse perspectives. The resulting pseudo caption labels offer dense samples for knowledge distillation. On the LVIS benchmark, our best model trained on the de-duplicated VisualGenome dataset achieves an AP of 34.5 and an APr of 30.6, comparable to the state-of-the-art performance. PCL's simplicity and flexibility are other notable features, as it is a straightforward pre-processing technique that can be used with any image captioning model without imposing any restrictions on model architecture or training process.
DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting
Mar 10, 2022
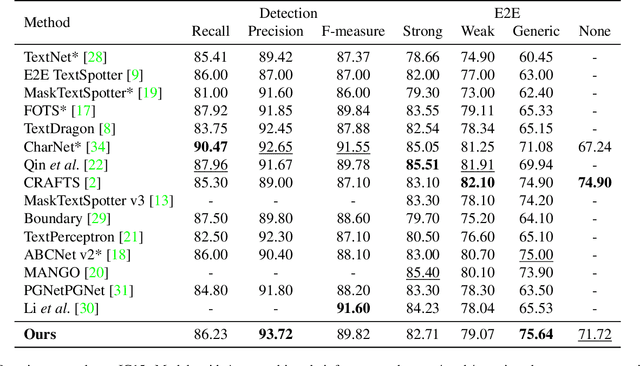
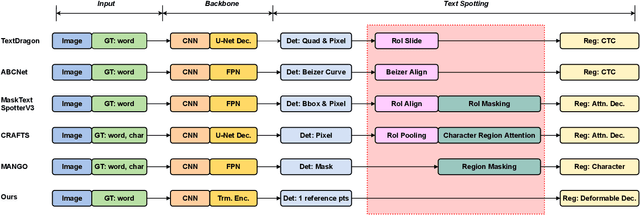
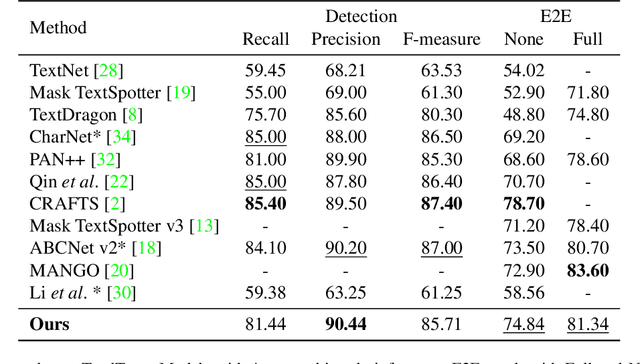
Recent end-to-end scene text spotters have achieved great improvement in recognizing arbitrary-shaped text instances. Common approaches for text spotting use region of interest pooling or segmentation masks to restrict features to single text instances. However, this makes it hard for the recognizer to decode correct sequences when the detection is not accurate i.e. one or more characters are cropped out. Considering that it is hard to accurately decide word boundaries with only the detector, we propose a novel Detection-agnostic End-to-End Recognizer, DEER, framework. The proposed method reduces the tight dependency between detection and recognition modules by bridging them with a single reference point for each text instance, instead of using detected regions. The proposed method allows the decoder to recognize the texts that are indicated by the reference point, with features from the whole image. Since only a single point is required to recognize the text, the proposed method enables text spotting without an arbitrarily-shaped detector or bounding polygon annotations. Experimental results present that the proposed method achieves competitive results on regular and arbitrarily-shaped text spotting benchmarks. Further analysis shows that DEER is robust to the detection errors. The code and dataset will be publicly available.
HoughCL: Finding Better Positive Pairs in Dense Self-supervised Learning
Nov 21, 2021
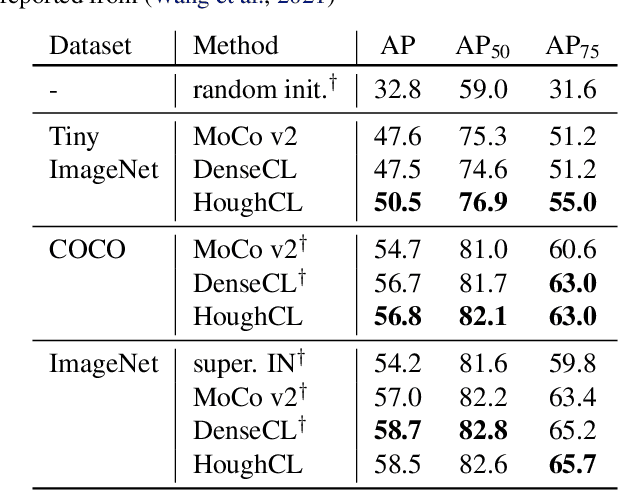
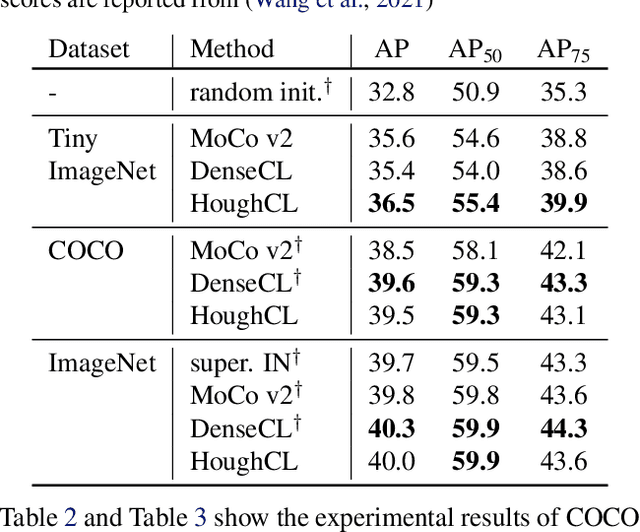
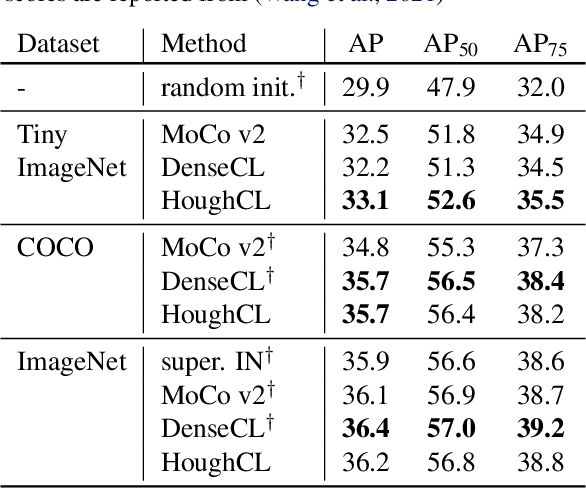
Recently, self-supervised methods show remarkable achievements in image-level representation learning. Nevertheless, their image-level self-supervisions lead the learned representation to sub-optimal for dense prediction tasks, such as object detection, instance segmentation, etc. To tackle this issue, several recent self-supervised learning methods have extended image-level single embedding to pixel-level dense embeddings. Unlike image-level representation learning, due to the spatial deformation of augmentation, it is difficult to sample pixel-level positive pairs. Previous studies have sampled pixel-level positive pairs using the winner-takes-all among similarity or thresholding warped distance between dense embeddings. However, these naive methods can be struggled by background clutter and outliers problems. In this paper, we introduce Hough Contrastive Learning (HoughCL), a Hough space based method that enforces geometric consistency between two dense features. HoughCL achieves robustness against background clutter and outliers. Furthermore, compared to baseline, our dense positive pairing method has no additional learnable parameters and has a small extra computation cost. Compared to previous works, our method shows better or comparable performance on dense prediction fine-tuning tasks.
SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models
Jul 20, 2021

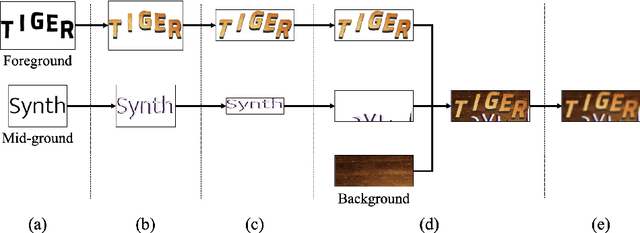
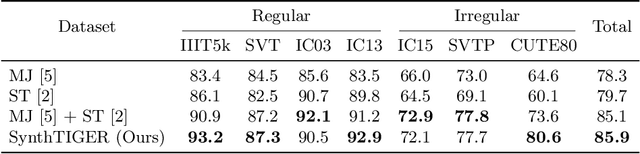
For successful scene text recognition (STR) models, synthetic text image generators have alleviated the lack of annotated text images from the real world. Specifically, they generate multiple text images with diverse backgrounds, font styles, and text shapes and enable STR models to learn visual patterns that might not be accessible from manually annotated data. In this paper, we introduce a new synthetic text image generator, SynthTIGER, by analyzing techniques used for text image synthesis and integrating effective ones under a single algorithm. Moreover, we propose two techniques that alleviate the long-tail problem in length and character distributions of training data. In our experiments, SynthTIGER achieves better STR performance than the combination of synthetic datasets, MJSynth (MJ) and SynthText (ST). Our ablation study demonstrates the benefits of using sub-components of SynthTIGER and the guideline on generating synthetic text images for STR models. Our implementation is publicly available at https://github.com/clovaai/synthtiger.
Accelerating Object Detection by Erasing Background Activations
Feb 05, 2020
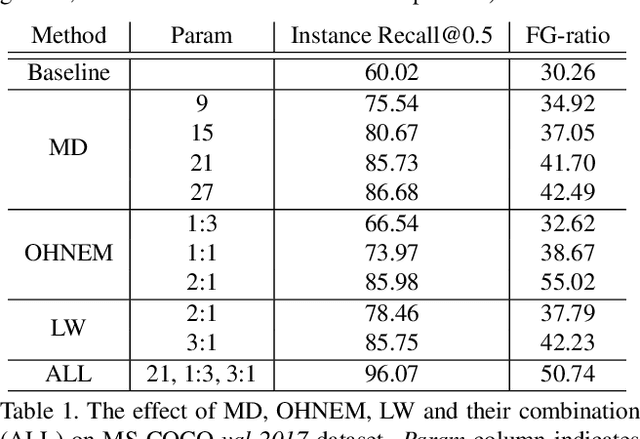
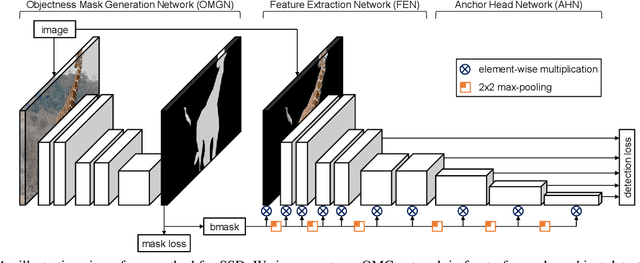
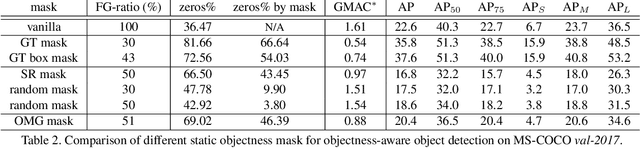
Recent advances in deep learning have enabled complex real-world use cases comprised of multiple vision tasks and detection tasks are being shifted to the edge side as a pre-processing step of the entire workload. However, since running a deep model on resource-constraint devices is challenging, the design of an efficient network is demanded. In this paper, we present an objectness-aware object detection method to accelerate detection speed by circumventing feature map computation on background regions where target objects don't exist. To accomplish this goal, we incorporate a light-weight objectness mask generation (OMG) network in front of an object detection (OD) network so that it can zero out background areas of an input image before being fed into the OD network. The inference speed, therefore, can be expedited with sparse convolution. By switching background areas to zeros for entire activations, the average number of zero values on MobileNetV2-SSDLite with ReLU activation is increased further, from 36% to 68% during inference step, which reduces 37.89\% MAC with negligible accuracy drop on MS-COCO. Moreover, experimental results also show similar trends in heavy networks such as VGG and RetinaNet with ResNet101, and an additional dataset, PASCAL VOC. The code will be released.