 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Joint Learning of Localized Representations from Medical Images and Reports
Dec 06, 2021

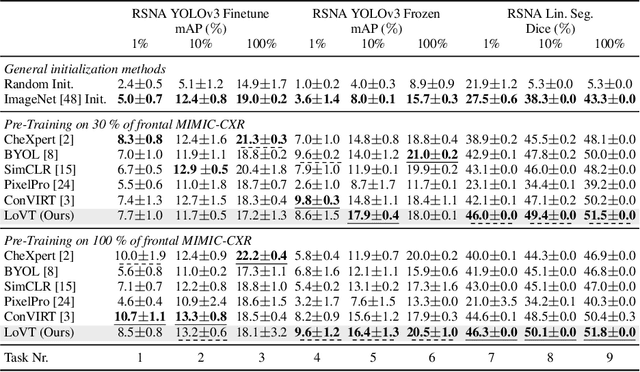

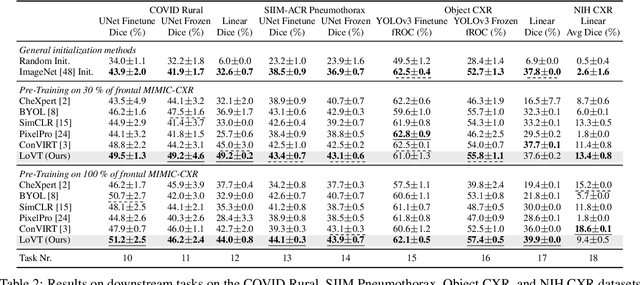
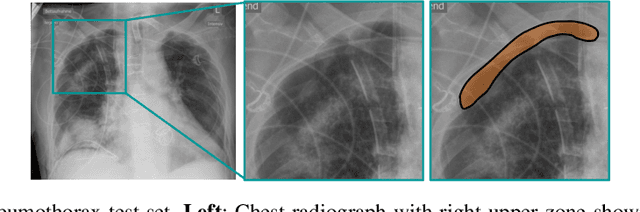
Contrastive learning has proven effective for pre-training image models on unlabeled data with promising results for tasks such as medical image classification. Using paired text and images (such as radiological reports and images) during pre-training improved the results even further. Still, most existing methods target image classification as downstream tasks and may not be optimal for localized tasks like semantic segmentation or object detection. We therefore propose Localized representation learning from Vision and Text (LoVT), to our best knowledge, the first text-supervised pre-training method that targets localized medical imaging tasks. Our method combines instance-level image-report contrastive learning with local contrastive learning on image region and report sentence representations. We evaluate LoVT and commonly used pre-training methods on a novel evaluation framework consisting of 18 localized tasks on chest X-rays from five public datasets. While there is no single best method, LoVT performs best on 11 out of the 18 studied tasks making it the preferred method of choice for localized tasks.
A systematic review and meta-analysis of Digital Elevation Model (DEM) fusion: pre-processing, methods and applications
Apr 08, 2022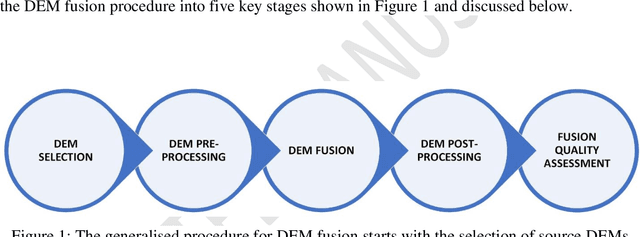

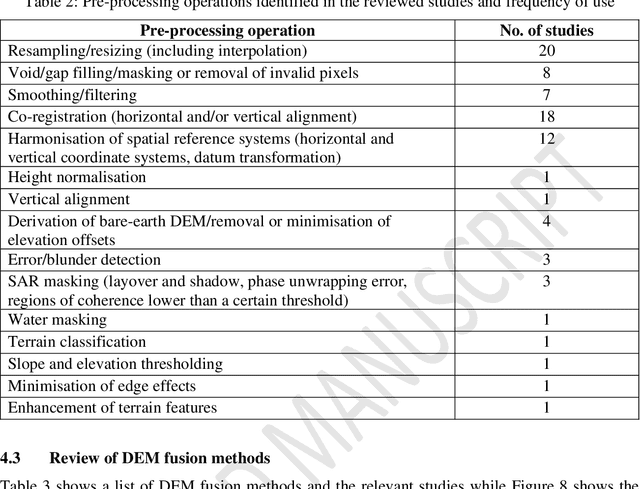
The remote sensing community has identified data fusion as one of the key challenging topics of the 21st century. The subject of image fusion in two-dimensional (2D) space has been covered in several published reviews. However, the special case of 2.5D/3D Digital Elevation Model (DEM) fusion has not been addressed till date. DEM fusion is a key application of data fusion in remote sensing. It takes advantage of the complementary characteristics of multi-source DEMs to deliver a more complete, accurate and reliable elevation dataset. Although several methods for fusing DEMs have been developed, the absence of a well-rounded review has limited their proliferation among researchers and end-users. It is often required to combine knowledge from multiple studies to inform a holistic perspective and guide further research. In response, this paper provides a systematic review of DEM fusion: the pre-processing workflow, methods and applications, enhanced with a meta-analysis. Through the discussion and comparative analysis, unresolved challenges and open issues were identified, and future directions for research were proposed. This review is a timely solution and an invaluable source of information for researchers within the fields of remote sensing and spatial information science, and the data fusion community at large.
On Maximum-a-Posteriori estimation with Plug & Play priors and stochastic gradient descent
Jan 16, 2022Bayesian methods to solve imaging inverse problems usually combine an explicit data likelihood function with a prior distribution that explicitly models expected properties of the solution. Many kinds of priors have been explored in the literature, from simple ones expressing local properties to more involved ones exploiting image redundancy at a non-local scale. In a departure from explicit modelling, several recent works have proposed and studied the use of implicit priors defined by an image denoising algorithm. This approach, commonly known as Plug & Play (PnP) regularisation, can deliver remarkably accurate results, particularly when combined with state-of-the-art denoisers based on convolutional neural networks. However, the theoretical analysis of PnP Bayesian models and algorithms is difficult and works on the topic often rely on unrealistic assumptions on the properties of the image denoiser. This papers studies maximum-a-posteriori (MAP) estimation for Bayesian models with PnP priors. We first consider questions related to existence, stability and well-posedness, and then present a convergence proof for MAP computation by PnP stochastic gradient descent (PnP-SGD) under realistic assumptions on the denoiser used. We report a range of imaging experiments demonstrating PnP-SGD as well as comparisons with other PnP schemes.
WRICNet:A Weighted Rich-scale Inception Coder Network for Multi-Resolution Remote Sensing Image Change Detection
Aug 18, 2021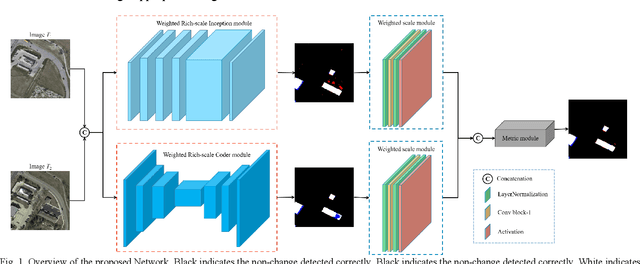
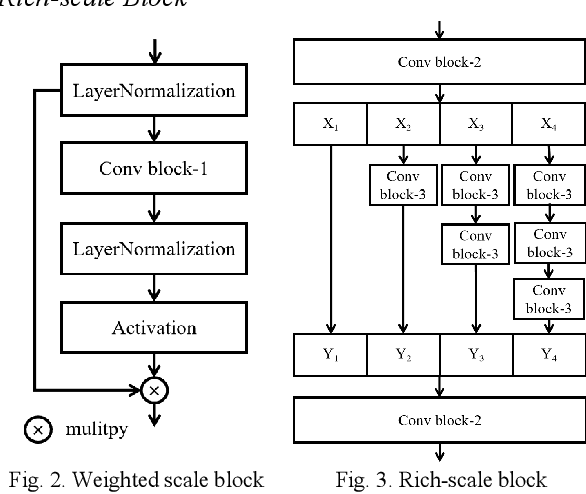
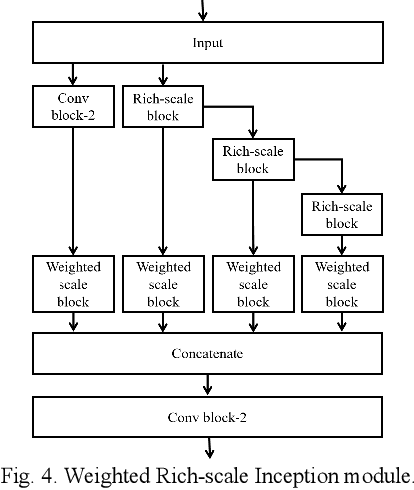
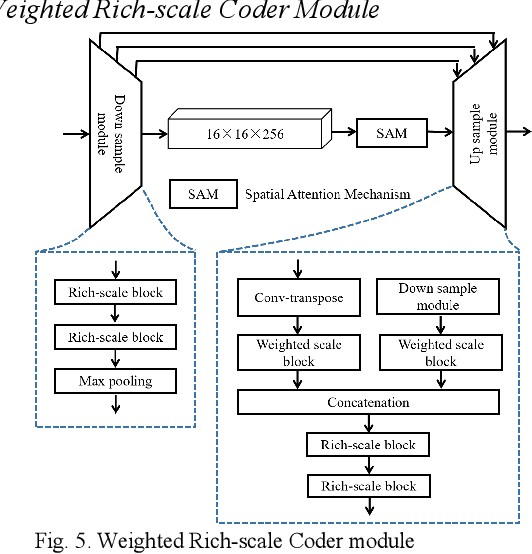
Majority models of remote sensing image changing detection can only get great effect in a specific resolution data set. With the purpose of improving change detection effectiveness of the model in the multi-resolution data set, a weighted rich-scale inception coder network (WRICNet) is proposed in this article, which can make a great fusion of shallow multi-scale features, and deep multi-scale features. The weighted rich-scale inception module of the proposed can obtain shallow multi-scale features, the weighted rich-scale coder module can obtain deep multi-scale features. The weighted scale block assigns appropriate weights to features of different scales, which can strengthen expressive ability of the edge of the changing area. The performance experiments on the multi-resolution data set demonstrate that, compared to the comparative methods, the proposed can further reduce the false alarm outside the change area, and the missed alarm in the change area, besides, the edge of the change area is more accurate. The ablation study of the proposed shows that the training strategy, and improvements of this article can improve the effectiveness of change detection.
O-ViT: Orthogonal Vision Transformer
Jan 28, 2022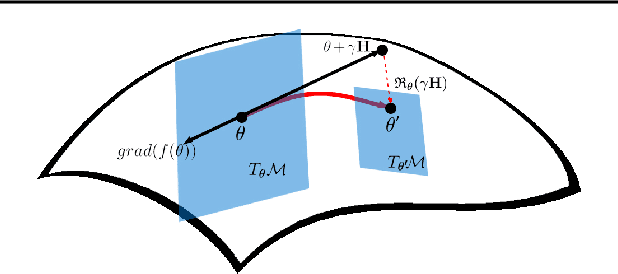
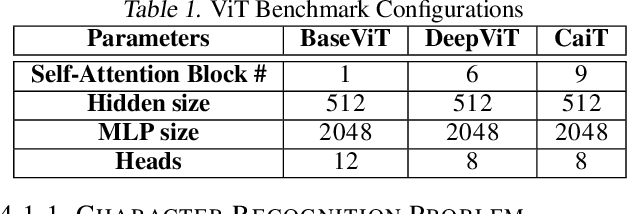
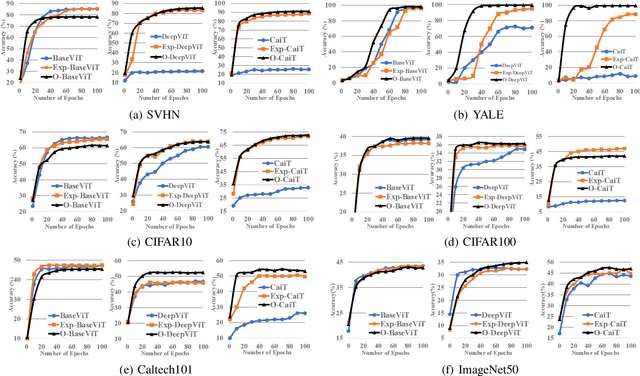
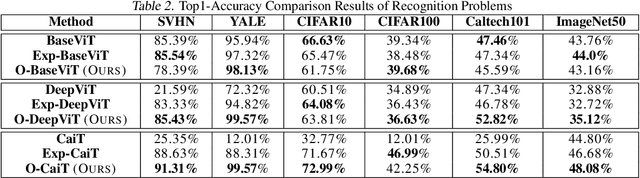
Inspired by the tremendous success of the self-attention mechanism in natural language processing, the Vision Transformer (ViT) creatively applies it to image patch sequences and achieves incredible performance. However, the scaled dot-product self-attention of ViT brings about scale ambiguity to the structure of the original feature space. To address this problem, we propose a novel method named Orthogonal Vision Transformer (O-ViT), to optimize ViT from the geometric perspective. O-ViT limits parameters of self-attention blocks to be on the norm-keeping orthogonal manifold, which can keep the geometry of the feature space. Moreover, O-ViT achieves both orthogonal constraints and cheap optimization overhead by adopting a surjective mapping between the orthogonal group and its Lie algebra.We have conducted comparative experiments on image recognition tasks to demonstrate O-ViT's validity and experiments show that O-ViT can boost the performance of ViT by up to 3.6%.
Self-supervised Learning from 100 Million Medical Images
Jan 04, 2022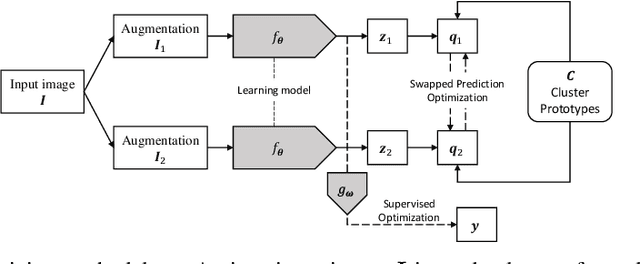
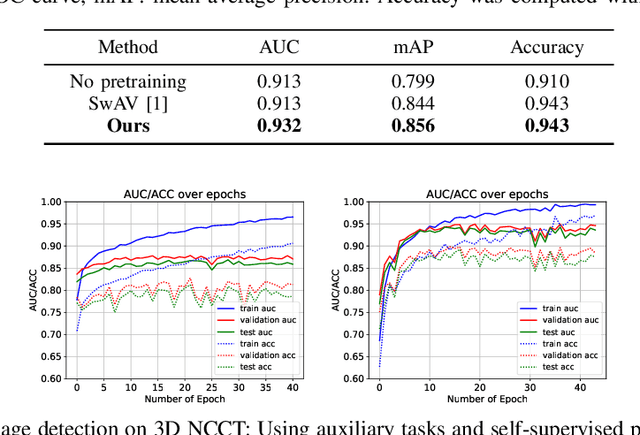
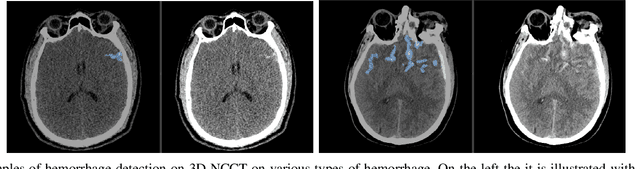
Building accurate and robust artificial intelligence systems for medical image assessment requires not only the research and design of advanced deep learning models but also the creation of large and curated sets of annotated training examples. Constructing such datasets, however, is often very costly -- due to the complex nature of annotation tasks and the high level of expertise required for the interpretation of medical images (e.g., expert radiologists). To counter this limitation, we propose a method for self-supervised learning of rich image features based on contrastive learning and online feature clustering. For this purpose we leverage large training datasets of over 100,000,000 medical images of various modalities, including radiography, computed tomography (CT), magnetic resonance (MR) imaging and ultrasonography. We propose to use these features to guide model training in supervised and hybrid self-supervised/supervised regime on various downstream tasks. We highlight a number of advantages of this strategy on challenging image assessment problems in radiography, CT and MR: 1) Significant increase in accuracy compared to the state-of-the-art (e.g., AUC boost of 3-7% for detection of abnormalities from chest radiography scans and hemorrhage detection on brain CT); 2) Acceleration of model convergence during training by up to 85% compared to using no pretraining (e.g., 83% when training a model for detection of brain metastases in MR scans); 3) Increase in robustness to various image augmentations, such as intensity variations, rotations or scaling reflective of data variation seen in the field.
Learning Program Representations for Food Images and Cooking Recipes
Mar 30, 2022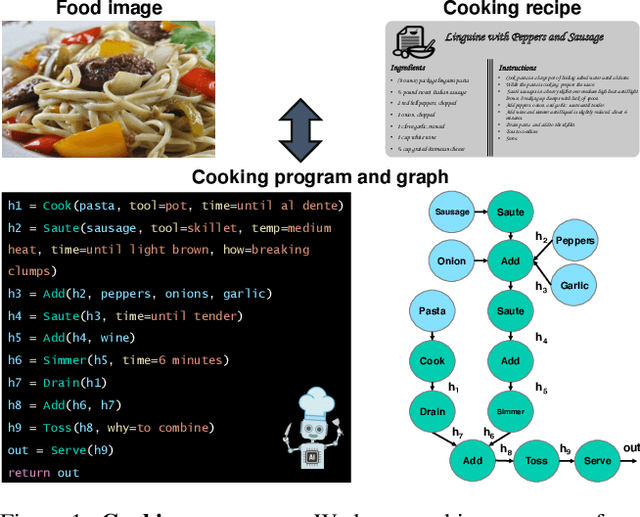
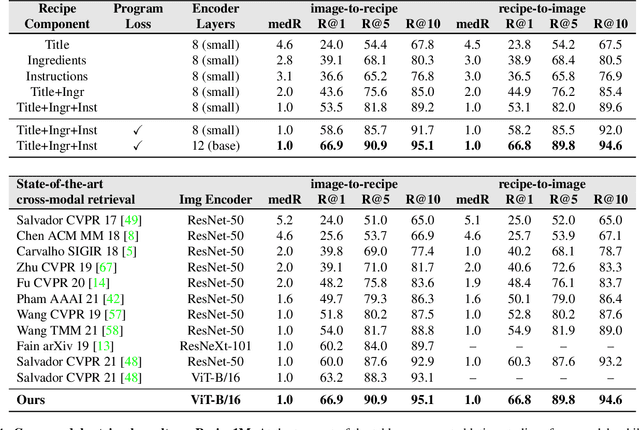
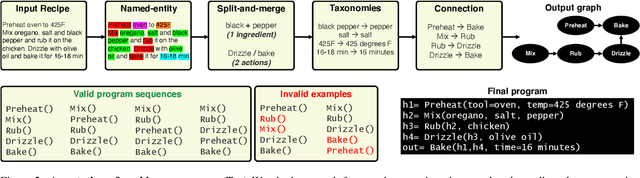
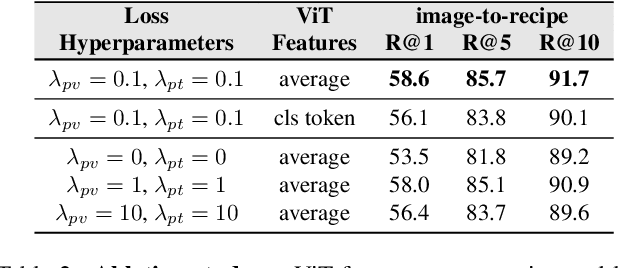
In this paper, we are interested in modeling a how-to instructional procedure, such as a cooking recipe, with a meaningful and rich high-level representation. Specifically, we propose to represent cooking recipes and food images as cooking programs. Programs provide a structured representation of the task, capturing cooking semantics and sequential relationships of actions in the form of a graph. This allows them to be easily manipulated by users and executed by agents. To this end, we build a model that is trained to learn a joint embedding between recipes and food images via self-supervision and jointly generate a program from this embedding as a sequence. To validate our idea, we crowdsource programs for cooking recipes and show that: (a) projecting the image-recipe embeddings into programs leads to better cross-modal retrieval results; (b) generating programs from images leads to better recognition results compared to predicting raw cooking instructions; and (c) we can generate food images by manipulating programs via optimizing the latent code of a GAN. Code, data, and models are available online.
You Only Cut Once: Boosting Data Augmentation with a Single Cut
Jan 28, 2022
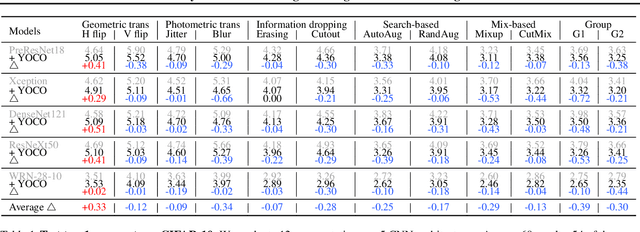

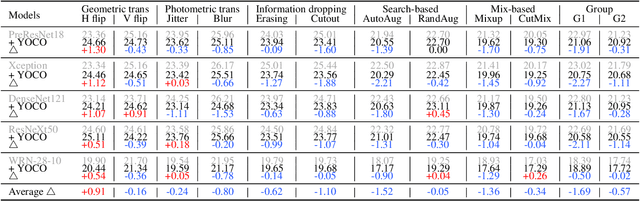
We present You Only Cut Once (YOCO) for performing data augmentations. YOCO cuts one image into two pieces and performs data augmentations individually within each piece. Applying YOCO improves the diversity of the augmentation per sample and encourages neural networks to recognize objects from partial information. YOCO enjoys the properties of parameter-free, easy usage, and boosting almost all augmentations for free. Thorough experiments are conducted to evaluate its effectiveness. We first demonstrate that YOCO can be seamlessly applied to varying data augmentations, neural network architectures, and brings performance gains on CIFAR and ImageNet classification tasks, sometimes surpassing conventional image-level augmentation by large margins. Moreover, we show YOCO benefits contrastive pre-training toward a more powerful representation that can be better transferred to multiple downstream tasks. Finally, we study a number of variants of YOCO and empirically analyze the performance for respective settings. Code is available at GitHub.
Self-Normalized Density Map (SNDM) for Counting Microbiological Objects
Mar 15, 2022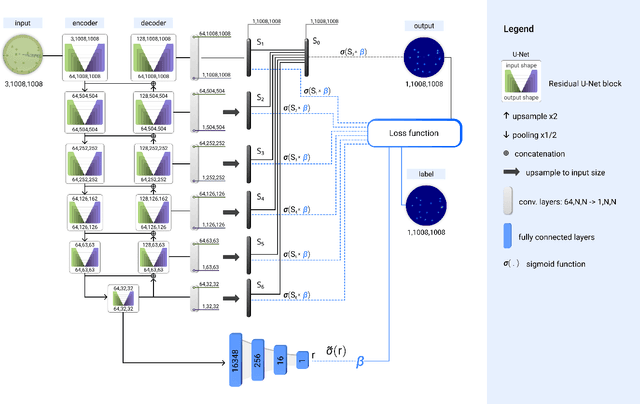
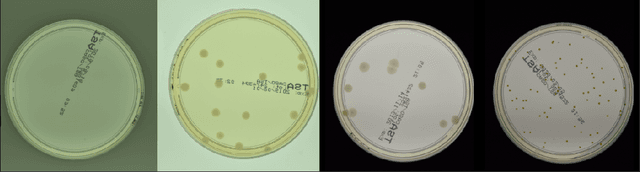
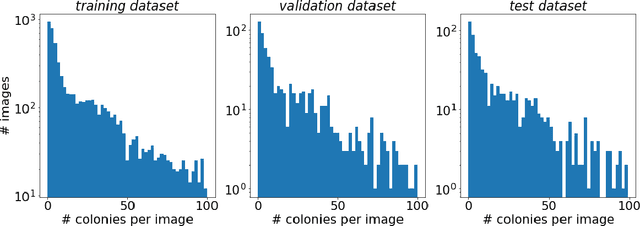
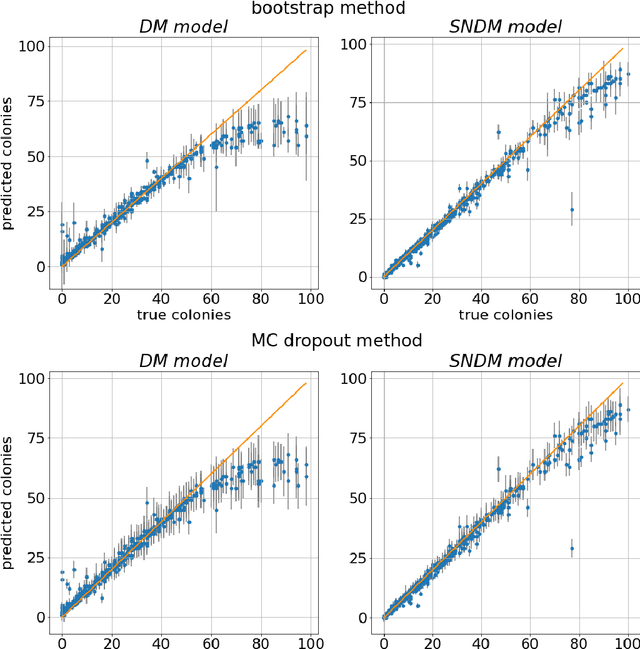
The statistical properties of the density map (DM) approach to counting microbiological objects on images are studied in detail. The DM is given by U$^2$-Net. Two statistical methods for deep neural networks are utilized: the bootstrap and the Monte Carlo (MC) dropout. The detailed analysis of the uncertainties for the DM predictions leads to a deeper understanding of the DM model's deficiencies. Based on our investigation, we propose a self-normalization module in the network. The improved network model, called Self-Normalized Density Map (SNDM), can correct its output density map by itself to accurately predict the total number of objects in the image. The SNDM architecture outperforms the original model. Moreover, both statistical frameworks -- bootstrap and MC dropout -- have consistent statistical results for SNDM, which were not observed in the original model.
Rediscovery of the Effectiveness of Standard Convolution for Lightweight Face Detection
Apr 04, 2022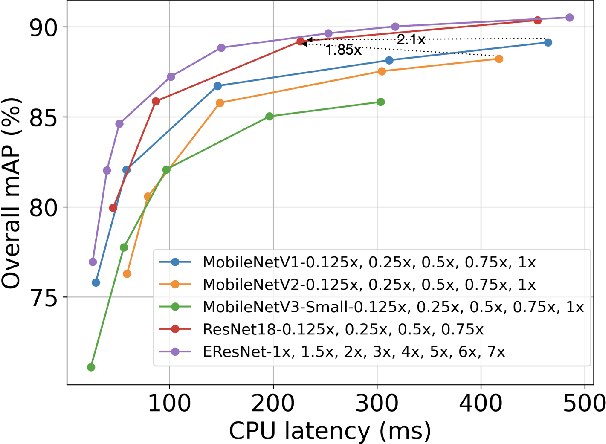
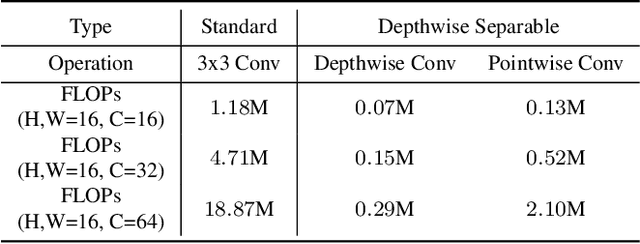
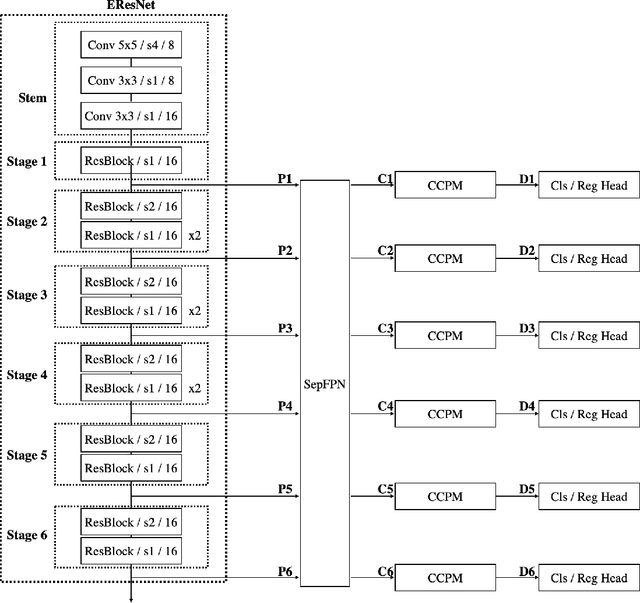
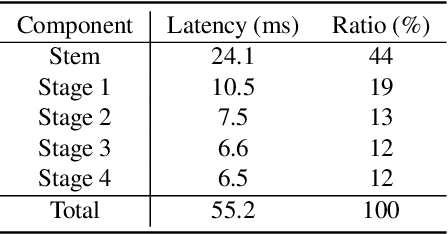
This paper analyses the design choices of face detection architecture that improve efficiency between computation cost and accuracy. Specifically, we re-examine the effectiveness of the standard convolutional block as a lightweight backbone architecture on face detection. Unlike the current tendency of lightweight architecture design, which heavily utilizes depthwise separable convolution layers, we show that heavily channel-pruned standard convolution layer can achieve better accuracy and inference speed when using a similar parameter size. This observation is supported by the analyses concerning the characteristics of the target data domain, face. Based on our observation, we propose to employ ResNet with a highly reduced channel, which surprisingly allows high efficiency compared to other mobile-friendly networks (e.g., MobileNet-V1,-V2,-V3). From the extensive experiments, we show that the proposed backbone can replace that of the state-of-the-art face detector with a faster inference speed. Also, we further propose a new feature aggregation method maximizing the detection performance. Our proposed detector EResFD obtained 80.4% mAP on WIDER FACE Hard subset which only takes 37.7 ms for VGA image inference in on CPU. Code will be available at https://github.com/clovaai/EResFD.