 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZIM: Zero-Shot Image Matting for Anything
Nov 01, 2024



The recent segmentation foundation model, Segment Anything Model (SAM), exhibits strong zero-shot segmentation capabilities, but it falls short in generating fine-grained precise masks. To address this limitation, we propose a novel zero-shot image matting model, called ZIM, with two key contributions: First, we develop a label converter that transforms segmentation labels into detailed matte labels, constructing the new SA1B-Matte dataset without costly manual annotations. Training SAM with this dataset enables it to generate precise matte masks while maintaining its zero-shot capability. Second, we design the zero-shot matting model equipped with a hierarchical pixel decoder to enhance mask representation, along with a prompt-aware masked attention mechanism to improve performance by enabling the model to focus on regions specified by visual prompts. We evaluate ZIM using the newly introduced MicroMat-3K test set, which contains high-quality micro-level matte labels. Experimental results show that ZIM outperforms existing methods in fine-grained mask generation and zero-shot generalization. Furthermore, we demonstrate the versatility of ZIM in various downstream tasks requiring precise masks, such as image inpainting and 3D NeRF. Our contributions provide a robust foundation for advancing zero-shot matting and its downstream applications across a wide range of computer vision tasks. The code is available at \url{https://github.com/naver-ai/ZIM}.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Towards Label-Efficient Human Matting: A Simple Baseline for Weakly Semi-Supervised Trimap-Free Human Matting
Apr 01, 2024



This paper presents a new practical training method for human matting, which demands delicate pixel-level human region identification and significantly laborious annotations. To reduce the annotation cost, most existing matting approaches often rely on image synthesis to augment the dataset. However, the unnaturalness of synthesized training images brings in a new domain generalization challenge for natural images. To address this challenge, we introduce a new learning paradigm, weakly semi-supervised human matting (WSSHM), which leverages a small amount of expensive matte labels and a large amount of budget-friendly segmentation labels, to save the annotation cost and resolve the domain generalization problem. To achieve the goal of WSSHM, we propose a simple and effective training method, named Matte Label Blending (MLB), that selectively guides only the beneficial knowledge of the segmentation and matte data to the matting model. Extensive experiments with our detailed analysis demonstrate our method can substantially improve the robustness of the matting model using a few matte data and numerous segmentation data. Our training method is also easily applicable to real-time models, achieving competitive accuracy with breakneck inference speed (328 FPS on NVIDIA V100 GPU). The implementation code is available at \url{https://github.com/clovaai/WSSHM}.
ECLIPSE: Efficient Continual Learning in Panoptic Segmentation with Visual Prompt Tuning
Mar 29, 2024Panoptic segmentation, combining semantic and instance segmentation, stands as a cutting-edge computer vision task. Despite recent progress with deep learning models, the dynamic nature of real-world applications necessitates continual learning, where models adapt to new classes (plasticity) over time without forgetting old ones (catastrophic forgetting). Current continual segmentation methods often rely on distillation strategies like knowledge distillation and pseudo-labeling, which are effective but result in increased training complexity and computational overhead. In this paper, we introduce a novel and efficient method for continual panoptic segmentation based on Visual Prompt Tuning, dubbed ECLIPSE. Our approach involves freezing the base model parameters and fine-tuning only a small set of prompt embeddings, addressing both catastrophic forgetting and plasticity and significantly reducing the trainable parameters. To mitigate inherent challenges such as error propagation and semantic drift in continual segmentation, we propose logit manipulation to effectively leverage common knowledge across the classes. Experiments on ADE20K continual panoptic segmentation benchmark demonstrate the superiority of ECLIPSE, notably its robustness against catastrophic forgetting and its reasonable plasticity, achieving a new state-of-the-art. The code is available at https://github.com/clovaai/ECLIPSE.
Gaussian Mixture Proposals with Pull-Push Learning Scheme to Capture Diverse Events for Weakly Supervised Temporal Video Grounding
Dec 27, 2023



In the weakly supervised temporal video grounding study, previous methods use predetermined single Gaussian proposals which lack the ability to express diverse events described by the sentence query. To enhance the expression ability of a proposal, we propose a Gaussian mixture proposal (GMP) that can depict arbitrary shapes by learning importance, centroid, and range of every Gaussian in the mixture. In learning GMP, each Gaussian is not trained in a feature space but is implemented over a temporal location. Thus the conventional feature-based learning for Gaussian mixture model is not valid for our case. In our special setting, to learn moderately coupled Gaussian mixture capturing diverse events, we newly propose a pull-push learning scheme using pulling and pushing losses, each of which plays an opposite role to the other. The effects of components in our scheme are verified in-depth with extensive ablation studies and the overall scheme achieves state-of-the-art performance. Our code is available at https://github.com/sunoh-kim/pps.
GeNAS: Neural Architecture Search with Better Generalization
May 18, 2023Neural Architecture Search (NAS) aims to automatically excavate the optimal network architecture with superior test performance. Recent neural architecture search (NAS) approaches rely on validation loss or accuracy to find the superior network for the target data. In this paper, we investigate a new neural architecture search measure for excavating architectures with better generalization. We demonstrate that the flatness of the loss surface can be a promising proxy for predicting the generalization capability of neural network architectures. We evaluate our proposed method on various search spaces, showing similar or even better performance compared to the state-of-the-art NAS methods. Notably, the resultant architecture found by flatness measure generalizes robustly to various shifts in data distribution (e.g. ImageNet-V2,-A,-O), as well as various tasks such as object detection and semantic segmentation. Code is available at https://github.com/clovaai/GeNAS.
Pipe-BD: Pipelined Parallel Blockwise Distillation
Jan 29, 2023



Training large deep neural network models is highly challenging due to their tremendous computational and memory requirements. Blockwise distillation provides one promising method towards faster convergence by splitting a large model into multiple smaller models. In state-of-the-art blockwise distillation methods, training is performed block-by-block in a data-parallel manner using multiple GPUs. To produce inputs for the student blocks, the teacher model is executed from the beginning until the current block under training. However, this results in a high overhead of redundant teacher execution, low GPU utilization, and extra data loading. To address these problems, we propose Pipe-BD, a novel parallelization method for blockwise distillation. Pipe-BD aggressively utilizes pipeline parallelism for blockwise distillation, eliminating redundant teacher block execution and increasing per-device batch size for better resource utilization. We also extend to hybrid parallelism for efficient workload balancing. As a result, Pipe-BD achieves significant acceleration without modifying the mathematical formulation of blockwise distillation. We implement Pipe-BD on PyTorch, and experiments reveal that Pipe-BD is effective on multiple scenarios, models, and datasets.
Enabling Hard Constraints in Differentiable Neural Network and Accelerator Co-Exploration
Jan 23, 2023Co-exploration of an optimal neural architecture and its hardware accelerator is an approach of rising interest which addresses the computational cost problem, especially in low-profile systems. The large co-exploration space is often handled by adopting the idea of differentiable neural architecture search. However, despite the superior search efficiency of the differentiable co-exploration, it faces a critical challenge of not being able to systematically satisfy hard constraints such as frame rate. To handle the hard constraint problem of differentiable co-exploration, we propose HDX, which searches for hard-constrained solutions without compromising the global design objectives. By manipulating the gradients in the interest of the given hard constraint, high-quality solutions satisfying the constraint can be obtained.
Rediscovery of the Effectiveness of Standard Convolution for Lightweight Face Detection
Apr 04, 2022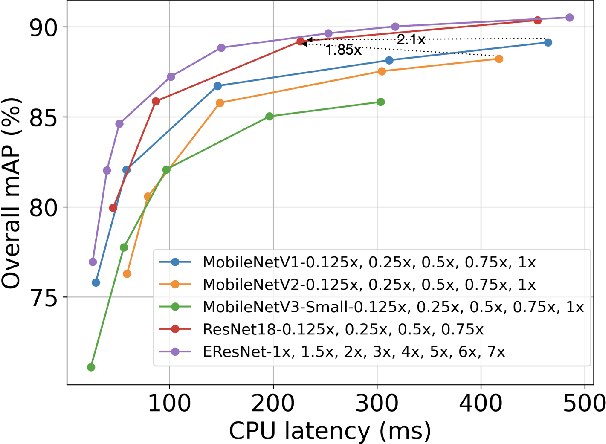
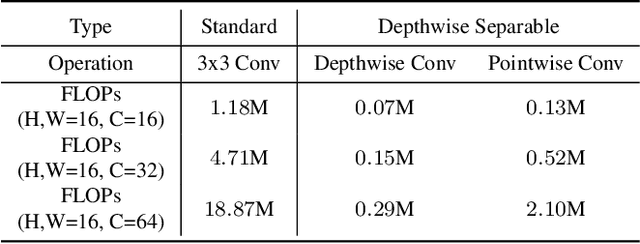
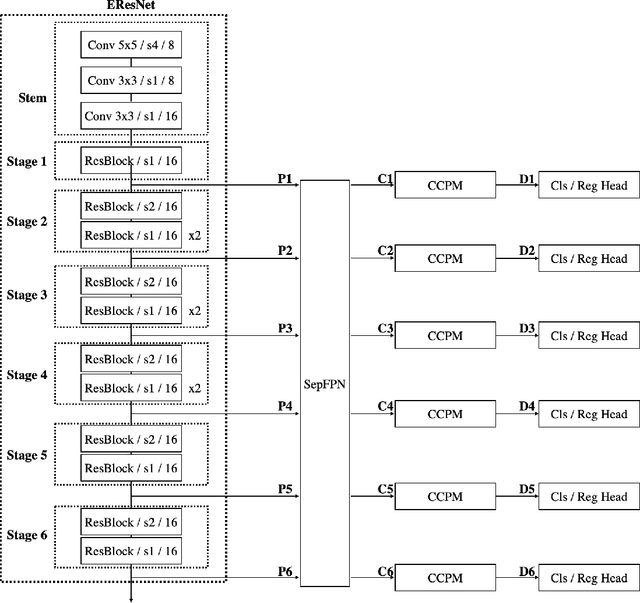
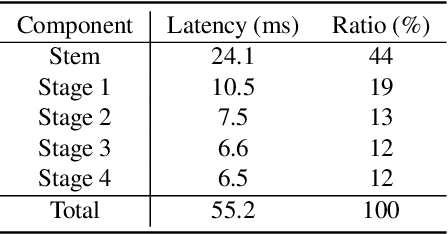
This paper analyses the design choices of face detection architecture that improve efficiency between computation cost and accuracy. Specifically, we re-examine the effectiveness of the standard convolutional block as a lightweight backbone architecture on face detection. Unlike the current tendency of lightweight architecture design, which heavily utilizes depthwise separable convolution layers, we show that heavily channel-pruned standard convolution layer can achieve better accuracy and inference speed when using a similar parameter size. This observation is supported by the analyses concerning the characteristics of the target data domain, face. Based on our observation, we propose to employ ResNet with a highly reduced channel, which surprisingly allows high efficiency compared to other mobile-friendly networks (e.g., MobileNet-V1,-V2,-V3). From the extensive experiments, we show that the proposed backbone can replace that of the state-of-the-art face detector with a faster inference speed. Also, we further propose a new feature aggregation method maximizing the detection performance. Our proposed detector EResFD obtained 80.4% mAP on WIDER FACE Hard subset which only takes 37.7 ms for VGA image inference in on CPU. Code will be available at https://github.com/clovaai/EResFD.
It's All In the Teacher: Zero-Shot Quantization Brought Closer to the Teacher
Apr 01, 2022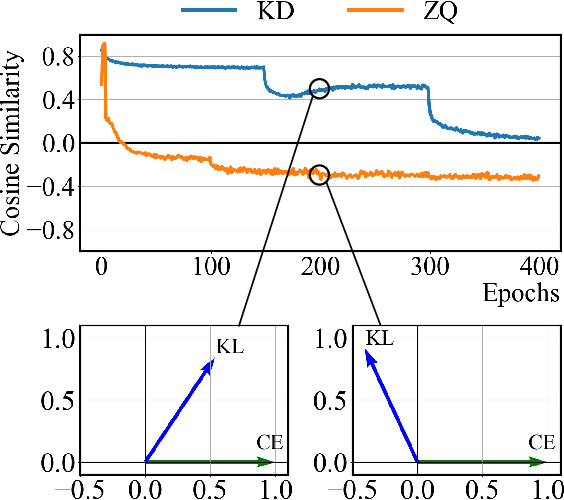
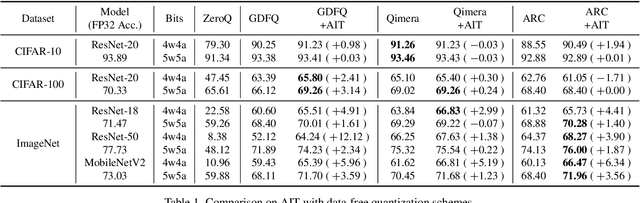
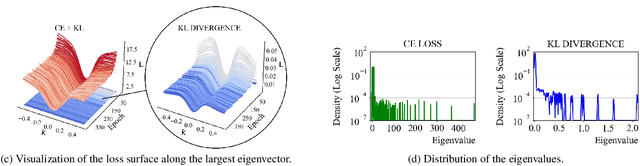
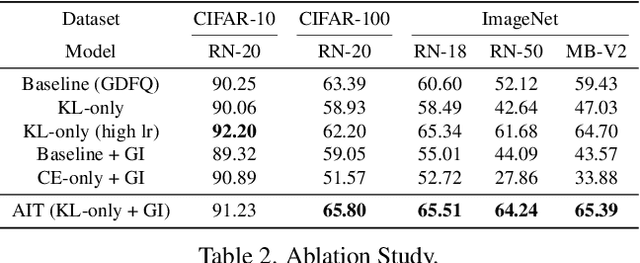
Model quantization is considered as a promising method to greatly reduce the resource requirements of deep neural networks. To deal with the performance drop induced by quantization errors, a popular method is to use training data to fine-tune quantized networks. In real-world environments, however, such a method is frequently infeasible because training data is unavailable due to security, privacy, or confidentiality concerns. Zero-shot quantization addresses such problems, usually by taking information from the weights of a full-precision teacher network to compensate the performance drop of the quantized networks. In this paper, we first analyze the loss surface of state-of-the-art zero-shot quantization techniques and provide several findings. In contrast to usual knowledge distillation problems, zero-shot quantization often suffers from 1) the difficulty of optimizing multiple loss terms together, and 2) the poor generalization capability due to the use of synthetic samples. Furthermore, we observe that many weights fail to cross the rounding threshold during training the quantized networks even when it is necessary to do so for better performance. Based on the observations, we propose AIT, a simple yet powerful technique for zero-shot quantization, which addresses the aforementioned two problems in the following way: AIT i) uses a KL distance loss only without a cross-entropy loss, and ii) manipulates gradients to guarantee that a certain portion of weights are properly updated after crossing the rounding thresholds. Experiments show that AIT outperforms the performance of many existing methods by a great margin, taking over the overall state-of-the-art position in the field.