 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SceneTrilogy: On Scene Sketches and its Relationship with Text and Photo
Apr 25, 2022
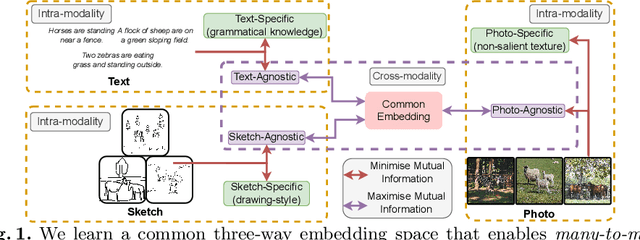
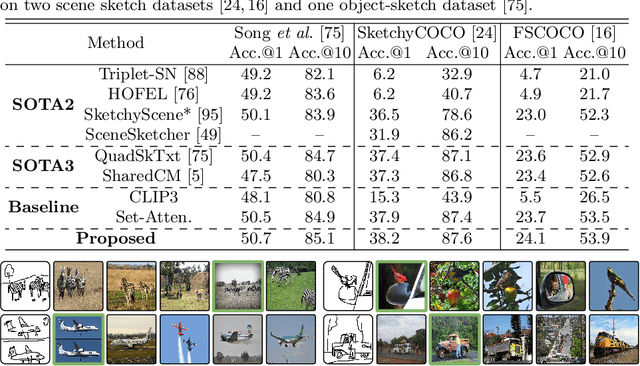
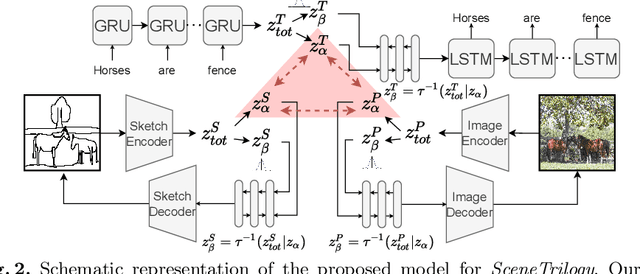

We for the first time extend multi-modal scene understanding to include that of free-hand scene sketches. This uniquely results in a trilogy of scene data modalities (sketch, text, and photo), where each offers unique perspectives for scene understanding, and together enable a series of novel scene-specific applications across discriminative (retrieval) and generative (captioning) tasks. Our key objective is to learn a common three-way embedding space that enables many-to-many modality interactions (e.g, sketch+text $\rightarrow$ photo retrieval). We importantly leverage the information bottleneck theory to achieve this goal, where we (i) decouple intra-modality information by minimising the mutual information between modality-specific and modality-agnostic components via a conditional invertible neural network, and (ii) align \textit{cross-modalities information} by maximising the mutual information between their modality-agnostic components using InfoNCE, with a specific multihead attention mechanism to allow many-to-many modality interactions. We spell out a few insights on the complementarity of each modality for scene understanding, and study for the first time a series of scene-specific applications like joint sketch- and text-based image retrieval, sketch captioning.
Dewarping Document Image By Displacement Flow Estimation with Fully Convolutional Network
Apr 14, 2021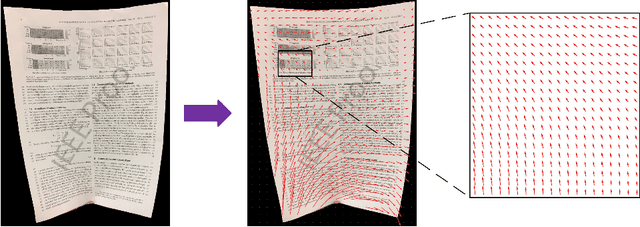

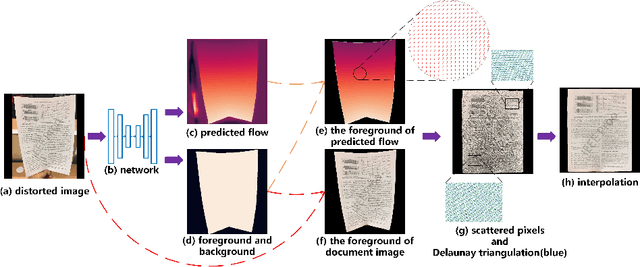
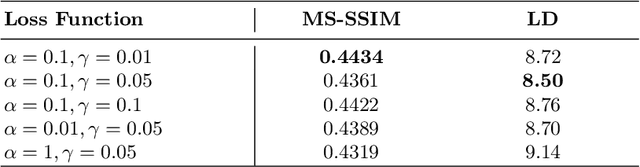
As camera-based documents are increasingly used, the rectification of distorted document images becomes a need to improve the recognition performance. In this paper, we propose a novel framework for both rectifying distorted document image and removing background finely, by estimating pixel-wise displacements using a fully convolutional network (FCN). The document image is rectified by transformation according to the displacements of pixels. The FCN is trained by regressing displacements of synthesized distorted documents, and to control the smoothness of displacements, we propose a Local Smooth Constraint (LSC) in regularization. Our approach is easy to implement and consumes moderate computing resource. Experiments proved that our approach can dewarp document images effectively under various geometric distortions, and has achieved the state-of-the-art performance in terms of local details and overall effect.
Convolutional Neural Network Modelling for MODIS Land Surface Temperature Super-Resolution
Feb 22, 2022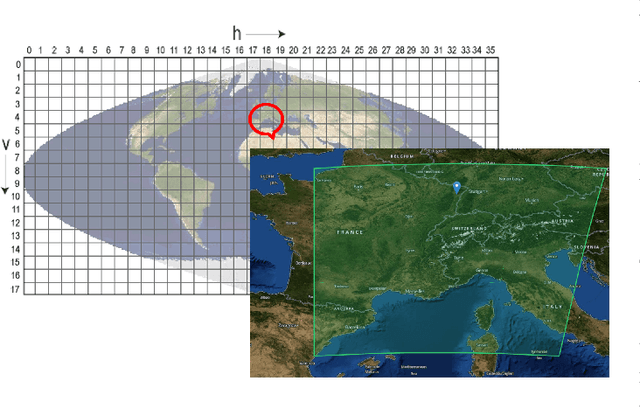
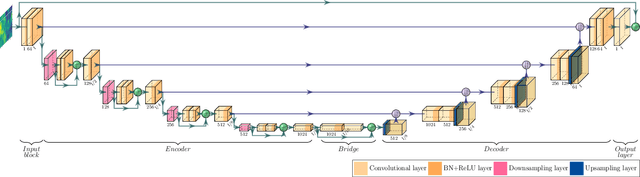
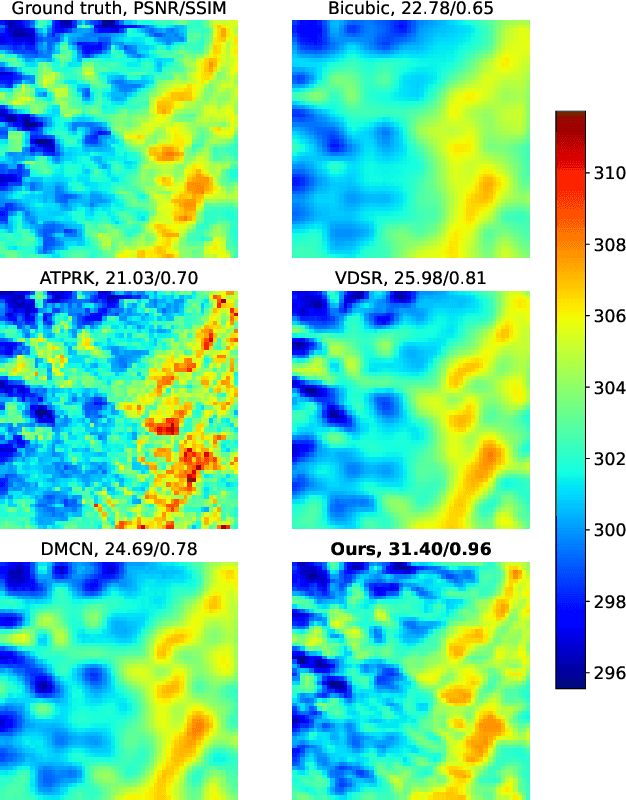
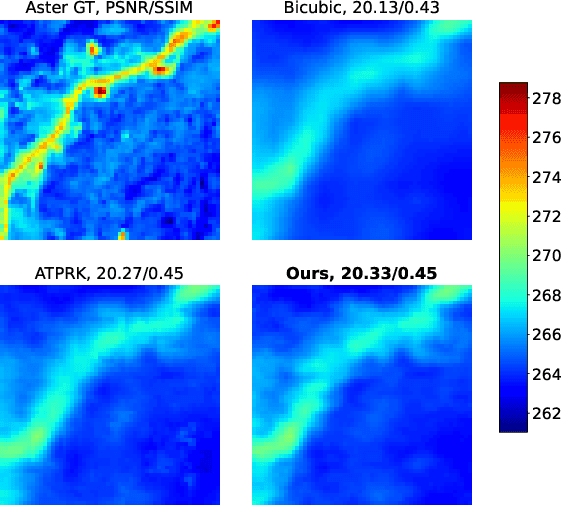
Nowadays, thermal infrared satellite remote sensors enable to extract very interesting information at large scale, in particular Land Surface Temperature (LST). However such data are limited in spatial and/or temporal resolutions which prevents from an analysis at fine scales. For example, MODIS satellite provides daily acquisitions with 1Km spatial resolutions which is not sufficient to deal with highly heterogeneous environments as agricultural parcels. Therefore, image super-resolution is a crucial task to better exploit MODIS LSTs. This issue is tackled in this paper. We introduce a deep learning-based algorithm, named Multi-residual U-Net, for super-resolution of MODIS LST single-images. Our proposed network is a modified version of U-Net architecture, which aims at super-resolving the input LST image from 1Km to 250m per pixel. The results show that our Multi-residual U-Net outperforms other state-of-the-art methods.
Compression-Resistant Backdoor Attack against Deep Neural Networks
Jan 03, 2022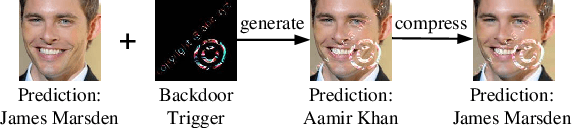
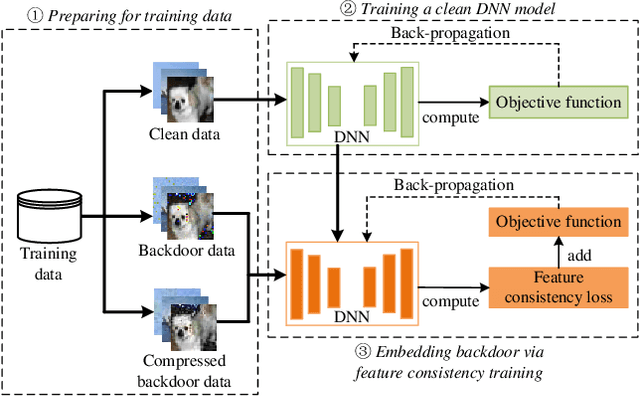

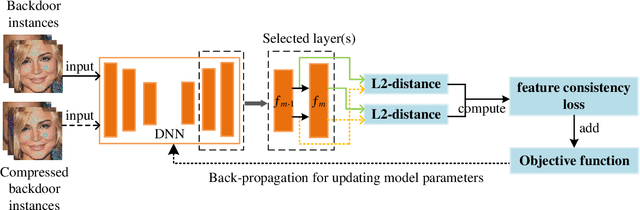
In recent years, many backdoor attacks based on training data poisoning have been proposed. However, in practice, those backdoor attacks are vulnerable to image compressions. When backdoor instances are compressed, the feature of specific backdoor trigger will be destroyed, which could result in the backdoor attack performance deteriorating. In this paper, we propose a compression-resistant backdoor attack based on feature consistency training. To the best of our knowledge, this is the first backdoor attack that is robust to image compressions. First, both backdoor images and their compressed versions are input into the deep neural network (DNN) for training. Then, the feature of each image is extracted by internal layers of the DNN. Next, the feature difference between backdoor images and their compressed versions are minimized. As a result, the DNN treats the feature of compressed images as the feature of backdoor images in feature space. After training, the backdoor attack against DNN is robust to image compression. Furthermore, we consider three different image compressions (i.e., JPEG, JPEG2000, WEBP) in feature consistency training, so that the backdoor attack is robust to multiple image compression algorithms. Experimental results demonstrate the effectiveness and robustness of the proposed backdoor attack. When the backdoor instances are compressed, the attack success rate of common backdoor attack is lower than 10%, while the attack success rate of our compression-resistant backdoor is greater than 97%. The compression-resistant attack is still robust even when the backdoor images are compressed with low compression quality. In addition, extensive experiments have demonstrated that, our compression-resistant backdoor attack has the generalization ability to resist image compression which is not used in the training process.
Visual Servoing for Pose Control of Soft Continuum Arm in a Structured Environment
Feb 11, 2022
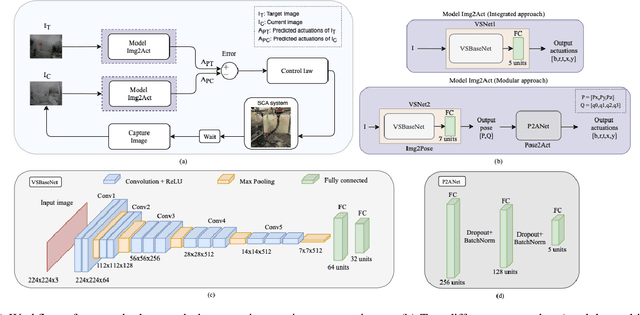

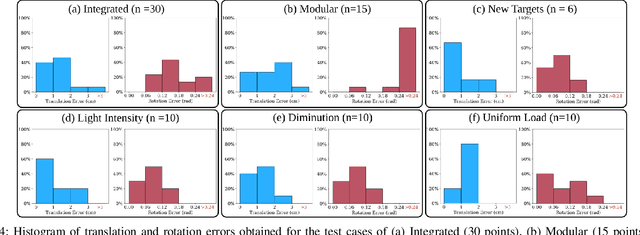
For soft continuum arms, visual servoing is a popular control strategy that relies on visual feedback to close the control loop. However, robust visual servoing is challenging as it requires reliable feature extraction from the image, accurate control models and sensors to perceive the shape of the arm, both of which can be hard to implement in a soft robot. This letter circumvents these challenges by presenting a deep neural network-based method to perform smooth and robust 3D positioning tasks on a soft arm by visual servoing using a camera mounted at the distal end of the arm. A convolutional neural network is trained to predict the actuations required to achieve the desired pose in a structured environment. Integrated and modular approaches for estimating the actuations from the image are proposed and are experimentally compared. A proportional control law is implemented to reduce the error between the desired and current image as seen by the camera. The model together with the proportional feedback control makes the described approach robust to several variations such as new targets, lighting, loads, and diminution of the soft arm. Furthermore, the model lends itself to be transferred to a new environment with minimal effort.
Learning the sampling density in 2D SPARKLING MRI acquisition for optimized image reconstruction
Mar 05, 2021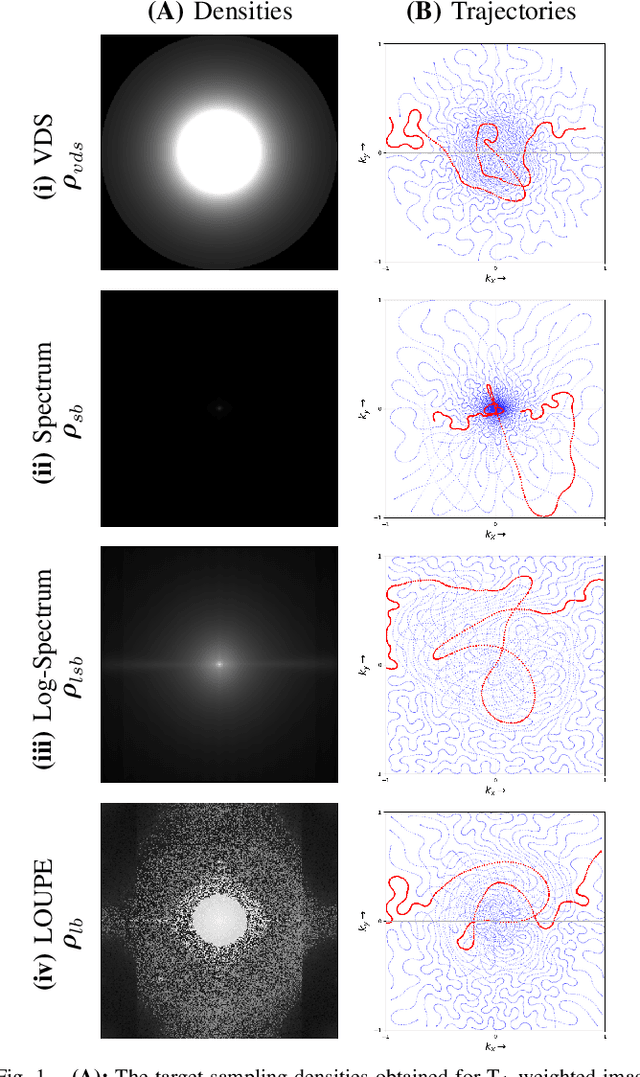
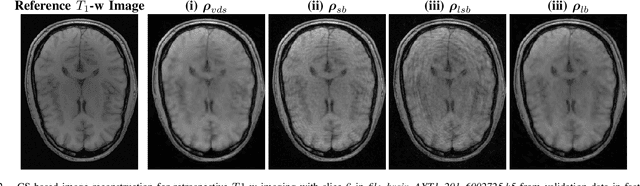
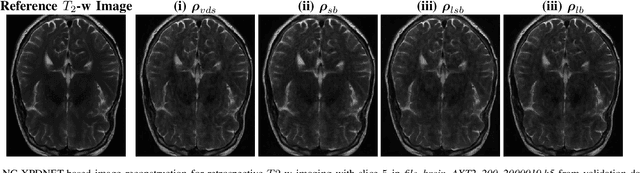
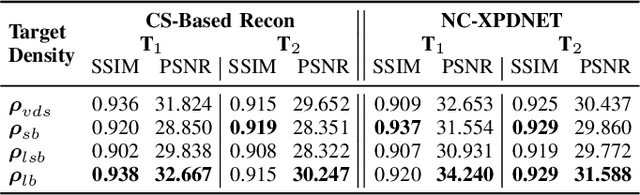
The SPARKLING algorithm was originally developed for accelerated 2D magnetic resonance imaging (MRI) in the compressed sensing (CS) context. It yields non-Cartesian sampling trajectories that jointly fulfill a target sampling density while each individual trajectory complies with MR hardware constraints. However, the two main limitations of SPARKLING are first that the optimal target sampling density is unknown and thus a user-defined parameter and second that this sampling pattern generation remains disconnected from MR image reconstruction thus from the optimization of image quality. Recently, datadriven learning schemes such as LOUPE have been proposed to learn a discrete sampling pattern, by jointly optimizing the whole pipeline from data acquisition to image reconstruction. In this work, we merge these methods with a state-of-the-art deep neural network for image reconstruction, called XPDNET, to learn the optimal target sampling density. Next, this density is used as input parameter to SPARKLING to obtain 20x accelerated non-Cartesian trajectories. These trajectories are tested on retrospective compressed sensing (CS) studies and show superior performance in terms of image quality with both deep learning (DL) and conventional CS reconstruction schemes.
WideCaps: A Wide Attention based Capsule Network for Image Classification
Aug 14, 2021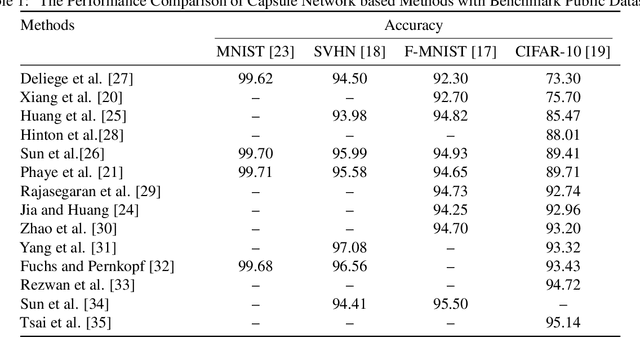
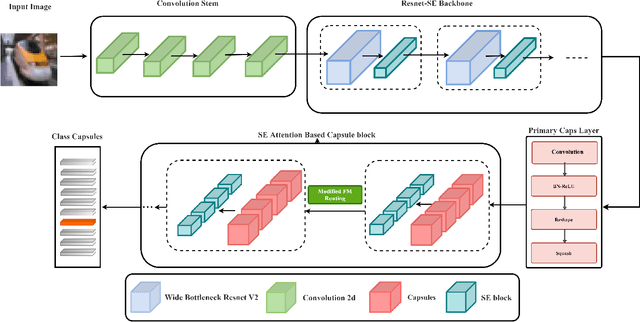
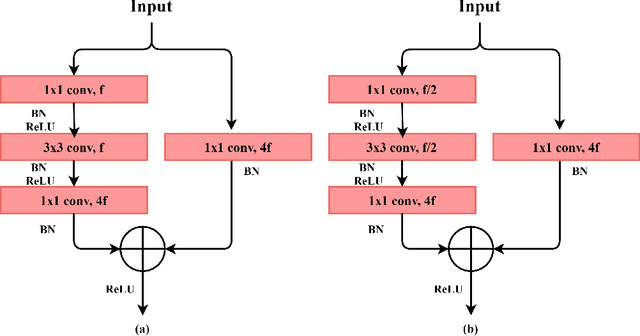

The capsule network is a distinct and promising segment of the neural network family that drew attention due to its unique ability to maintain the equivariance property by preserving the spatial relationship amongst the features. The capsule network has attained unprecedented success over image classification tasks with datasets such as MNIST and affNIST by encoding the characteristic features into the capsules and building the parse-tree structure. However, on the datasets involving complex foreground and background regions such as CIFAR-10, the performance of the capsule network is sub-optimal due to its naive data routing policy and incompetence towards extracting complex features. This paper proposes a new design strategy for capsule network architecture for efficiently dealing with complex images. The proposed method incorporates wide bottleneck residual modules and the Squeeze and Excitation attention blocks upheld by the modified FM routing algorithm to address the defined problem. A wide bottleneck residual module facilitates extracting complex features followed by the squeeze and excitation attention block to enable channel-wise attention by suppressing the trivial features. This setup allows channel inter-dependencies at almost no computational cost, thereby enhancing the representation ability of capsules on complex images. We extensively evaluate the performance of the proposed model on three publicly available datasets, namely CIFAR-10, Fashion MNIST, and SVHN, to outperform the top-5 performance on CIFAR-10 and Fashion MNIST with highly competitive performance on the SVHN dataset.
Mugs: A Multi-Granular Self-Supervised Learning Framework
Mar 27, 2022
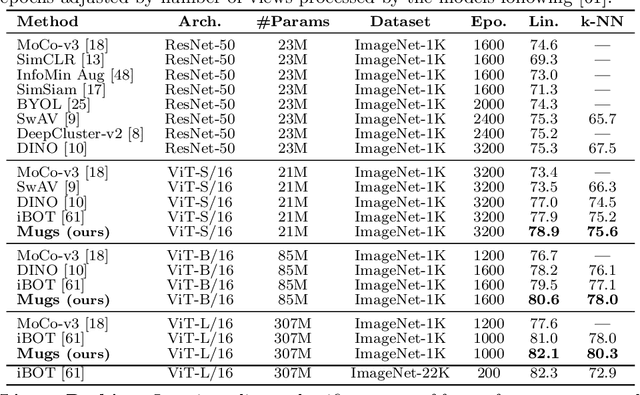
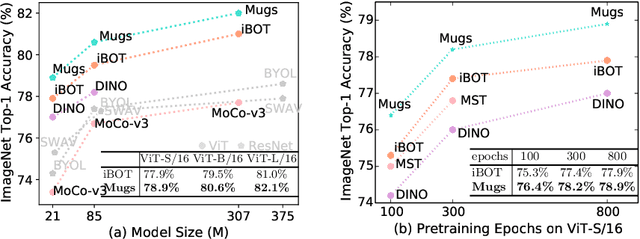
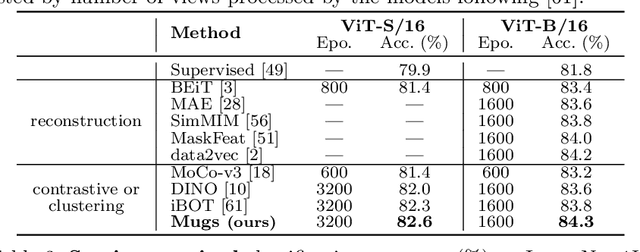
In self-supervised learning, multi-granular features are heavily desired though rarely investigated, as different downstream tasks (e.g., general and fine-grained classification) often require different or multi-granular features, e.g.~fine- or coarse-grained one or their mixture. In this work, for the first time, we propose an effective MUlti-Granular Self-supervised learning (Mugs) framework to explicitly learn multi-granular visual features. Mugs has three complementary granular supervisions: 1) an instance discrimination supervision (IDS), 2) a novel local-group discrimination supervision (LGDS), and 3) a group discrimination supervision (GDS). IDS distinguishes different instances to learn instance-level fine-grained features. LGDS aggregates features of an image and its neighbors into a local-group feature, and pulls local-group features from different crops of the same image together and push them away for others. It provides complementary instance supervision to IDS via an extra alignment on local neighbors, and scatters different local-groups separately to increase discriminability. Accordingly, it helps learn high-level fine-grained features at a local-group level. Finally, to prevent similar local-groups from being scattered randomly or far away, GDS brings similar samples close and thus pulls similar local-groups together, capturing coarse-grained features at a (semantic) group level. Consequently, Mugs can capture three granular features that often enjoy higher generality on diverse downstream tasks over single-granular features, e.g.~instance-level fine-grained features in contrastive learning. By only pretraining on ImageNet-1K, Mugs sets new SoTA linear probing accuracy 82.1$\%$ on ImageNet-1K and improves previous SoTA by $1.1\%$. It also surpasses SoTAs on other tasks, e.g. transfer learning, detection and segmentation.
HL-Net: Heterophily Learning Network for Scene Graph Generation
May 04, 2022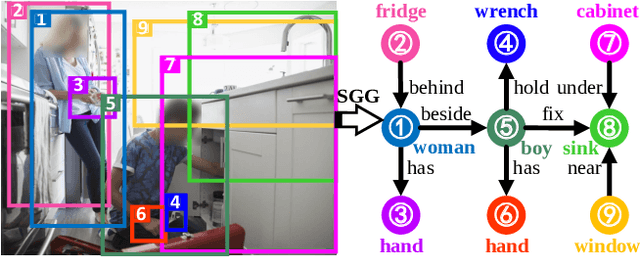
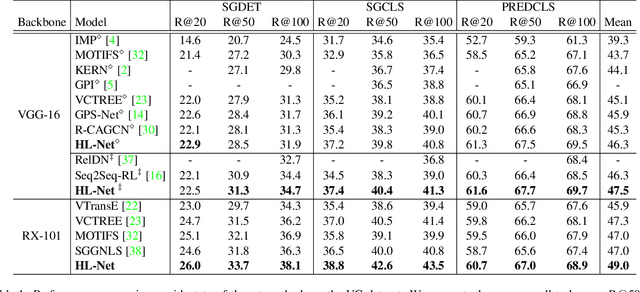
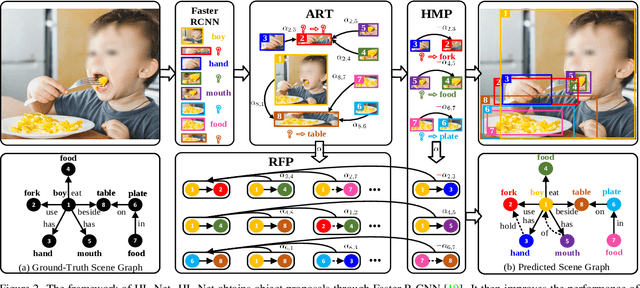
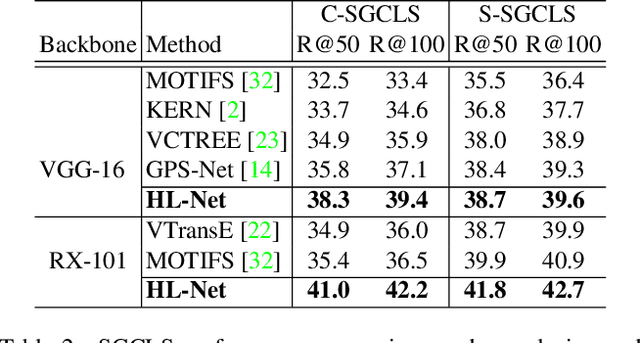
Scene graph generation (SGG) aims to detect objects and predict their pairwise relationships within an image. Current SGG methods typically utilize graph neural networks (GNNs) to acquire context information between objects/relationships. Despite their effectiveness, however, current SGG methods only assume scene graph homophily while ignoring heterophily. Accordingly, in this paper, we propose a novel Heterophily Learning Network (HL-Net) to comprehensively explore the homophily and heterophily between objects/relationships in scene graphs. More specifically, HL-Net comprises the following 1) an adaptive reweighting transformer module, which adaptively integrates the information from different layers to exploit both the heterophily and homophily in objects; 2) a relationship feature propagation module that efficiently explores the connections between relationships by considering heterophily in order to refine the relationship representation; 3) a heterophily-aware message-passing scheme to further distinguish the heterophily and homophily between objects/relationships, thereby facilitating improved message passing in graphs. We conducted extensive experiments on two public datasets: Visual Genome (VG) and Open Images (OI). The experimental results demonstrate the superiority of our proposed HL-Net over existing state-of-the-art approaches. In more detail, HL-Net outperforms the second-best competitors by 2.1$\%$ on the VG dataset for scene graph classification and 1.2$\%$ on the IO dataset for the final score. Code is available at https://github.com/siml3/HL-Net.
Self-Similarity Priors: Neural Collages as Differentiable Fractal Representations
Apr 15, 2022
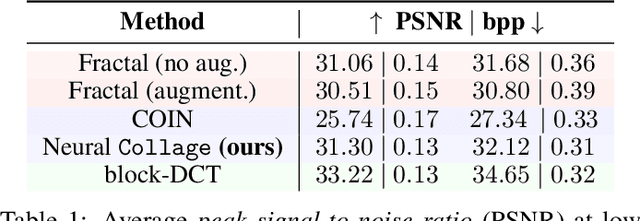


Many patterns in nature exhibit self-similarity: they can be compactly described via self-referential transformations. Said patterns commonly appear in natural and artificial objects, such as molecules, shorelines, galaxies and even images. In this work, we investigate the role of learning in the automated discovery of self-similarity and in its utilization for downstream tasks. To this end, we design a novel class of implicit operators, Neural Collages, which (1) represent data as the parameters of a self-referential, structured transformation, and (2) employ hypernetworks to amortize the cost of finding these parameters to a single forward pass. We investigate how to leverage the representations produced by Neural Collages in various tasks, including data compression and generation. Neural Collages image compressors are orders of magnitude faster than other self-similarity-based algorithms during encoding and offer compression rates competitive with implicit methods. Finally, we showcase applications of Neural Collages for fractal art and as deep generative models.