 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Learning for Limited-Angle STEM-EDX Tomography -- Application to 3D Chemical Analysis of Phase-Change Memory Devices
Jun 09, 2026Energy Dispersive X-ray (EDX) tomography in Scanning Transmission Electron Microscopy (STEM) enables 3D compositional and elemental mapping at the nanoscale, but its use is limited by restricted tilt ranges and low-dose conditions required to avoid beam damage. Limited-angle acquisition introduces missing-wedge artefacts such as elongation and anisotropic resolution, while noisy low-dose data further degrade reconstruction quality and quantitative reliability. Here, we introduce an unsupervised deep learning framework based on Deep Image Prior with total variation regularization (DIP-TV) for limited-angle STEM-EDX tomography. We extend it to a multi-channel formulation (DIPm-TV) that jointly reconstructs multiple elemental maps by exploiting spatial correlations. Using a synthetic 3-channel phantom, we show that the method compensates for severe missing-wedge artefacts corresponding to approximately $100^\circ$ of missing angular range under moderate noise, outperforming simultaneous iterative reconstruction technique and compressed sensing approaches. We apply the method to 3D chemical analysis of Ge-Sb-Te (GST) memory devices in virgin (as-fabricated) and SET (crystalline) operational states. Samples were prepared as cross-sectional focused ion beam lamellae and acquired under a limited-angle tilt range from $-40^\circ$ to $+40^\circ$ with $5^\circ$ steps and a dose of $2.0\times10^5$ $e^-/Ang^2$. The multi-channel approach enables voxel-by-voxel elemental reconstruction using only EDX signals without external structural priors such as high-angle annular dark-field imaging. The reconstructed volumes show near-isotropic spatial resolution and reveal compositional heterogeneities associated with device operation. This approach enables 3D chemical characterization in experimentally accessible sample geometries where conventional methods fail due to severe angular limitations.
DD-INR: Dynamics-Driven Implicit Neural Representation for Accelerated Whole-Brain Functional MRI Reconstruction
Jun 09, 2026Accelerated acquisition of fMRI enables enhanced detection of neurovascular (BOLD) activity in the brain, but image reconstruction becomes challenging with high k-space undersampling: Task-evoked BOLD signals are small in magnitude, which traditional anatomical MRI reconstruction methods fail to recover, as they favor spatial accuracy over temporal fidelity. We present DD-INR, a Dynamics-Driven Implicit Neural Representation framework tailored for accelerated fMRI that benefits from incoherent time-varying sampling and a tailored spatiotemporal prior, outperforming traditional methods, demonstrated in simulation and in-vivo acquisition, both in terms of image quality and retrieval of activation patterns. DD-INR achieves this by splitting the fMRI data into a static background and a temporally varying dynamic component, representing only the dynamics with a dedicated INR, thereby focusing the model's capacity on activation-relevant changes while remaining compact. In general, DD-INR provides a promising framework for accelerated fMRI reconstruction, with the potential to improve the sensitivity and robustness of fMRI studies within practical scan time limits. The source code is available at https://github.com/JoosenLi/DD-INR.
Combining Cartesian and non-Cartesian acceleration techniques with SPARKLING for 1mm isotropic whole-brain MPRAGE in a minute
May 29, 2026Purpose: T1-weighted MPRAGE remains a cornerstone of clinical anatomical imaging, yet its long acquisition times constrain routine use. Established acceleration techniques, namely Parallel Imaging (PI) and Compressed Sensing (CS), tend to introduce substantial noise and blurring when pushed to high acceleration factors. Although they rely on fundamentally different redundancies, combining them synergistically remains an open challenge. Methods: The GoLF-SPARKLING framework was extended to jointly exploit two acceleration mechanisms: GRAPPA-based PI in the central k-space region and variable-density CS in the periphery, with independent acceleration factors in each zone. To preserve smooth signal evolution throughout the inversion-recovery period and avoid modulation artifacts, the acquisition trajectory was reordered accordingly. The resulting method was evaluated prospectively in vivo at 1mm isotropic resolution and benchmarked against Wave-CAIPI and Poisson-disk sampling. Results: The proposed hybrid approach produced sharper, less noisy, and more stable whole-brain images in approximately one minute than either acceleration strategy alone. Purely PI-based reconstructions were degraded by high g-factor noise, while purely CS-based reconstructions exhibited pronounced blurring. Furthermore, this method yielded lower average volumetric errors in downstream automated brain segmentation than state-of-the-art acceleration techniques, demonstrating its clinical utility. Conclusion: By jointly leveraging PI and CS, GoLF-SPARKLING achieves high acceleration factors that enable sub-minute, high-quality anatomical MRI. This translates into greater clinical throughput and more reliable imaging in patients who are challenging to scan.
Unsupervised Deep Image Prior for Sparse-View and Limited-Angle Electron Tomography
May 26, 2026Electron tomography (ET) plays an important role in the three-dimensional (3D) characterization of nanomaterials. However, under limited-angle and sparse-view conditions, conventional algorithms produce degraded reconstructions, which compromise the quality and interpretability of resulting 3D data. In this paper, we present deep image prior (DIP), an unsupervised deep learning (DL) approach, for highly degraded tomography acquisitions and demonstrate, using simulated data, that its performance is comparable to that of supervised approaches requiring training datasets, even for tilt ranges as limited as 60° and tilt increments of 10°. We then apply it to experimental data and show that it enables reliable 3D quantification under both sparse-view and limited-angle conditions, highlighting its potential for a wide range of materials and acquisition modalities.
Benchmarking 3D multi-coil NC-PDNet MRI reconstruction
Nov 08, 2024



Deep learning has shown great promise for MRI reconstruction from undersampled data, yet there is a lack of research on validating its performance in 3D parallel imaging acquisitions with non-Cartesian undersampling. In addition, the artifacts and the resulting image quality depend on the under-sampling pattern. To address this uncharted territory, we extend the Non-Cartesian Primal-Dual Network (NC-PDNet), a state-of-the-art unrolled neural network, to a 3D multi-coil setting. We evaluated the impact of channel-specific versus channel-agnostic training configurations and examined the effect of coil compression. Finally, we benchmark four distinct non-Cartesian undersampling patterns, with an acceleration factor of six, using the publicly available Calgary-Campinas dataset. Our results show that NC-PDNet trained on compressed data with varying input channel numbers achieves an average PSNR of 42.98 dB for 1 mm isotropic 32 channel whole-brain 3D reconstruction. With an inference time of 4.95sec and a GPU memory usage of 5.49 GB, our approach demonstrates significant potential for clinical research application.
Robust plug-and-play methods for highly accelerated non-Cartesian MRI reconstruction
Nov 04, 2024



Achieving high-quality Magnetic Resonance Imaging (MRI) reconstruction at accelerated acquisition rates remains challenging due to the inherent ill-posed nature of the inverse problem. Traditional Compressed Sensing (CS) methods, while robust across varying acquisition settings, struggle to maintain good reconstruction quality at high acceleration factors ($\ge$ 8). Recent advances in deep learning have improved reconstruction quality, but purely data-driven methods are prone to overfitting and hallucination effects, notably when the acquisition setting is varying. Plug-and-Play (PnP) approaches have been proposed to mitigate the pitfalls of both frameworks. In a nutshell, PnP algorithms amount to replacing suboptimal handcrafted CS priors with powerful denoising deep neural network (DNNs). However, in MRI reconstruction, existing PnP methods often yield suboptimal results due to instabilities in the proximal gradient descent (PGD) schemes and the lack of curated, noiseless datasets for training robust denoisers. In this work, we propose a fully unsupervised preprocessing pipeline to generate clean, noiseless complex MRI signals from multicoil data, enabling training of a high-performance denoising DNN. Furthermore, we introduce an annealed Half-Quadratic Splitting (HQS) algorithm to address the instability issues, leading to significant improvements over existing PnP algorithms. When combined with preconditioning techniques, our approach achieves state-of-the-art results, providing a robust and efficient solution for high-quality MRI reconstruction.
SNAKE-fMRI: A modular fMRI data simulator from the space-time domain to k-space and back
Apr 12, 2024We propose a new, modular, open-source, Python-based 3D+time fMRI data simulation software, \emph{SNAKE-fMRI}, which stands for \emph{S}imulator from \emph{N}eurovascular coupling to \emph{A}cquisition of \emph{K}-space data for \emph{E}xploration of fMRI acquisition techniques.Unlike existing tools, the goal here is to simulate the complete chain of fMRI data acquisition, from the spatio-temporal design of evoked brain responses to various multi-coil k-space data 3D sampling strategies, with the possibility of extending the forward acquisition model to various noise and artifact sources while remaining memory-efficient.By using this \emph{in silico} setup, we are thus able to provide realistic and reproducible ground truth for fMRI reconstruction methods in 3D accelerated acquisition settings and explore the influence of critical parameters, such as the acceleration factor and signal-to-noise ratio~(SNR), on downstream tasks of image reconstruction and statistical analysis of evoked brain activity.We present three scenarios of increasing complexity to showcase the flexibility, versatility, and fidelity of \emph{SNAKE-fMRI}: From a temporally-fixed full 3D Cartesian to various 3D non-Cartesian sampling patterns, we can compare -- with reproducibility guarantees -- how experimental paradigms, acquisition strategies and reconstruction methods contribute and interact together, affecting the downstream statistical analysis.
Benchmarking learned non-Cartesian k-space trajectories and reconstruction networks
Jan 27, 2022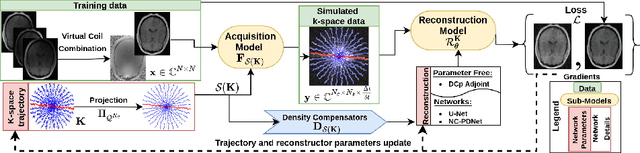
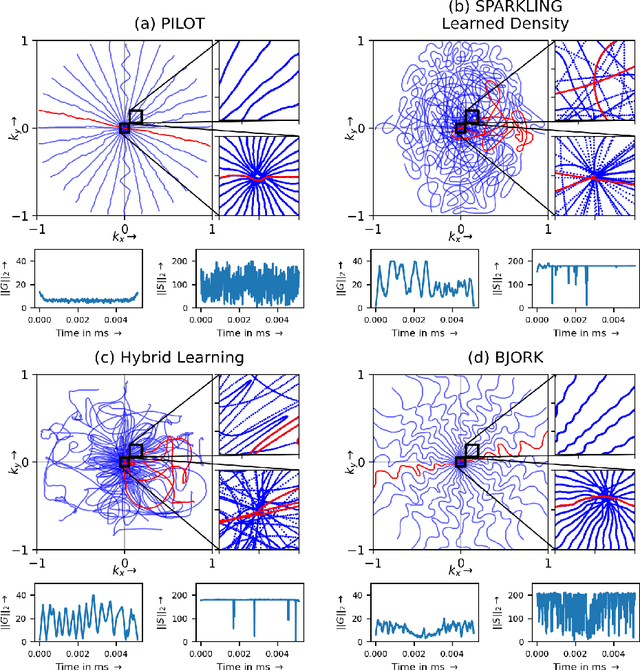
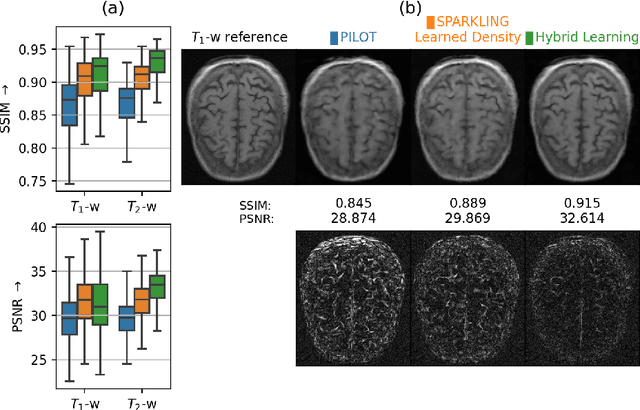
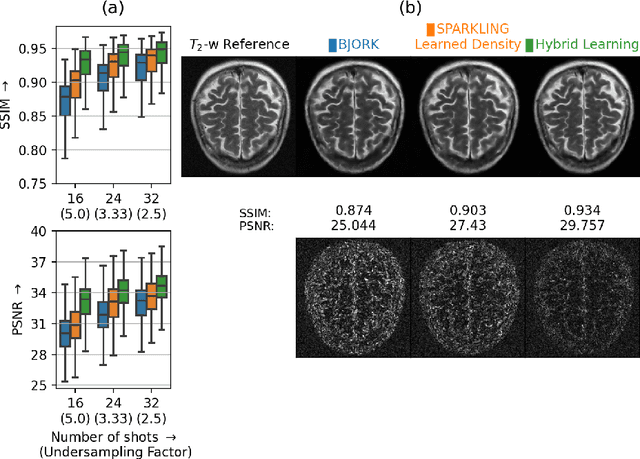
We benchmark the current existing methods to jointly learn non-Cartesian k-space trajectory and reconstruction: PILOT, BJORK, and compare them with those obtained from the recently developed generalized hybrid learning (HybLearn) framework. We present the advantages of using projected gradient descent to enforce MR scanner hardware constraints as compared to using added penalties in the cost function. Further, we use the novel HybLearn scheme to jointly learn and compare our results through a retrospective study on fastMRI validation dataset.
Hybrid learning of Non-Cartesian k-space trajectory and MR image reconstruction networks
Oct 25, 2021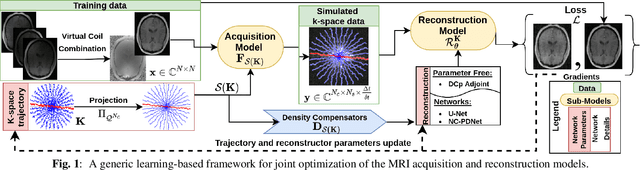

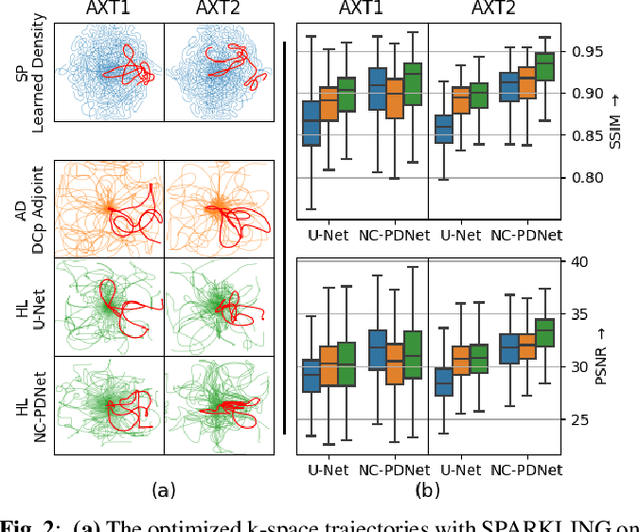
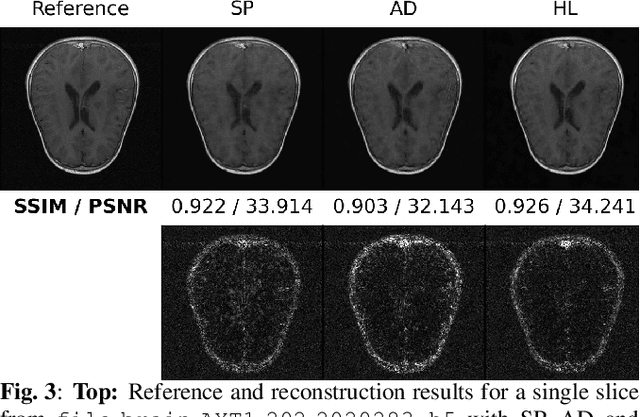
Compressed sensing (CS) in Magnetic resonance Imaging (MRI) essentially involves the optimization of 1) the sampling pattern in k-space under MR hardware constraints and 2) image reconstruction from the undersampled k-space data. Recently, deep learning methods have allowed the community to address both problems simultaneously, especially in the non-Cartesian acquisition setting. This paper aims to contribute to this field by tackling some major concerns in existing approaches.Regarding the learning of the sampling pattern, we perform ablation studies using parameter-free reconstructions like the density compensated (DCp) adjoint operator of the nonuniform fast Fourier transform (NUFFT) to ensure that the learned k-space trajectories actually sample the center of k-space densely. Additionally we optimize these trajectories by embedding a projected gradient descent algorithm over the hardware MR constraints. Later, we introduce a novel hybrid learning approach that operates across multiple resolutions to jointly optimize the reconstruction network and the k-space trajectory and present improved image reconstruction quality at 20-fold acceleration factor on T1 and T2-weighted images on the fastMRI dataset with SSIM scores of nearly 0.92-0.95 in our retrospective studies.
SHINE: SHaring the INverse Estimate from the forward pass for bi-level optimization and implicit models
Jun 24, 2021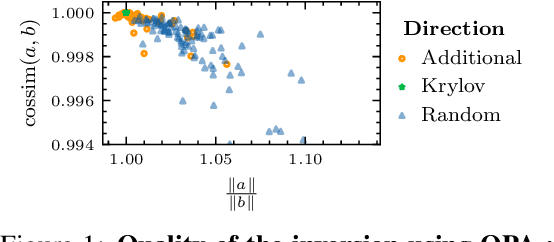
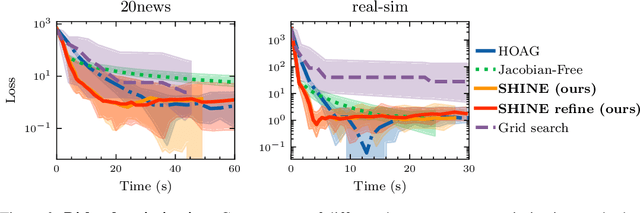
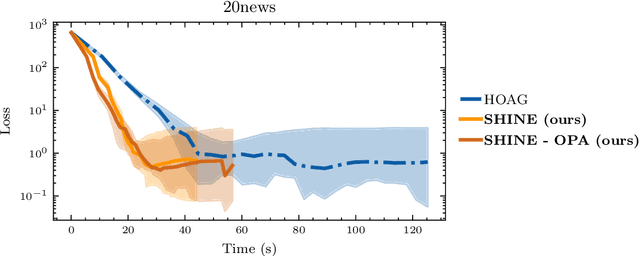
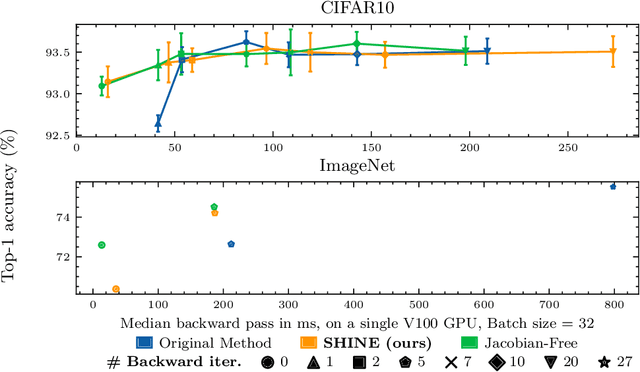
In recent years, implicit deep learning has emerged as a method to increase the depth of deep neural networks. While their training is memory-efficient, they are still significantly slower to train than their explicit counterparts. In Deep Equilibrium Models (DEQs), the training is performed as a bi-level problem, and its computational complexity is partially driven by the iterative inversion of a huge Jacobian matrix. In this paper, we propose a novel strategy to tackle this computational bottleneck from which many bi-level problems suffer. The main idea is to use the quasi-Newton matrices from the forward pass to efficiently approximate the inverse Jacobian matrix in the direction needed for the gradient computation. We provide a theorem that motivates using our method with the original forward algorithms. In addition, by modifying these forward algorithms, we further provide theoretical guarantees that our method asymptotically estimates the true implicit gradient. We empirically study this approach in many settings, ranging from hyperparameter optimization to large Multiscale DEQs applied to CIFAR and ImageNet. We show that it reduces the computational cost of the backward pass by up to two orders of magnitude. All this is achieved while retaining the excellent performance of the original models in hyperparameter optimization and on CIFAR, and giving encouraging and competitive results on ImageNet.