 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHREAD: Trajectory Planning for Hybrid Rigid-Soft Manipulators with Environment-Aware Diffusion
Jun 19, 2026Manipulation in confined environments, such as threading a manipulator through narrow apertures, remains a fundamental challenge, especially for conventional rigid robots. Hybrid rigid-soft manipulators offer promise but face two compounding planning challenges: backbone shapes feasible in free space become infeasible under environmental contact, and planning rigid and soft segments independently ignores their kinematic coupling. We present THREAD, the first diffusion-based trajectory planner for hybrid manipulation, learning a generative prior over physically realizable backbone trajectories conditioned on local environment geometry, with physics-inspired losses encoding curvature, smoothness, and collision constraints jointly across both segments. Trained in simulation, THREAD achieves 92.4% task success with 5x fewer collisions than the strongest baseline. We show cross-embodiment real-world transfer with minimal online updates, successfully threading through apertures as small as 1.3x the soft segment diameter.
CATNAV: Cached Vision-Language Traversability for Efficient Zero-Shot Robot Navigation
Mar 24, 2026Navigating unstructured environments requires assessing traversal risk relative to a robot's physical capabilities, a challenge that varies across embodiments. We present CATNAV, a cost-aware traversability navigation framework that leverages multimodal LLMs for zero-shot, embodiment-aware costmap generation without task-specific training. We introduce a visuosemantic caching mechanism that detects scene novelty and reuses prior risk assessments for semantically similar frames, reducing online VLM queries by 85.7%. Furthermore, we introduce a VLM-based trajectory selection module that evaluates proposals through visual reasoning to choose the safest path given behavioral constraints. We evaluate CATNAV on a quadruped robot across indoor and outdoor unstructured environments, comparing against state-of-the-art vision-language-action baselines. Across five navigation tasks, CATNAV achieves 10 percentage point higher average goal-reaching rate and 33% fewer behavioral constraint violations.
HyReach: Vision-Guided Hybrid Manipulator Reaching in Unseen Cluttered Environments
Mar 22, 2026As robotic systems increasingly operate in unstructured, cluttered, and previously unseen environments, there is a growing need for manipulators that combine compliance, adaptability, and precise control. This work presents a real-time hybrid rigid-soft continuum manipulator system designed for robust open-world object reaching in such challenging environments. The system integrates vision-based perception and 3D scene reconstruction with shape-aware motion planning to generate safe trajectories. A learning-based controller drives the hybrid arm to arbitrary target poses, leveraging the flexibility of the soft segment while maintaining the precision of the rigid segment. The system operates without environment-specific retraining, enabling direct generalization to new scenes. Extensive real-world experiments demonstrate consistent reaching performance with errors below 2 cm across diverse cluttered setups, highlighting the potential of hybrid manipulators for adaptive and reliable operation in unstructured environments.
Visual-Language-Guided Task Planning for Horticultural Robots
Jan 17, 2026Crop monitoring is essential for precision agriculture, but current systems lack high-level reasoning. We introduce a novel, modular framework that uses a Visual Language Model (VLM) to guide robotic task planning, interleaving input queries with action primitives. We contribute a comprehensive benchmark for short- and long-horizon crop monitoring tasks in monoculture and polyculture environments. Our main results show that VLMs perform robustly for short-horizon tasks (comparable to human success), but exhibit significant performance degradation in challenging long-horizon tasks. Critically, the system fails when relying on noisy semantic maps, demonstrating a key limitation in current VLM context grounding for sustained robotic operations. This work offers a deployable framework and critical insights into VLM capabilities and shortcomings for complex agricultural robotics.
Precision Harvesting in Cluttered Environments: Integrating End Effector Design with Dual Camera Perception
Jan 31, 2025



Due to labor shortages in specialty crop industries, a need for robotic automation to increase agricultural efficiency and productivity has arisen. Previous manipulation systems perform well in harvesting in uncluttered and structured environments. High tunnel environments are more compact and cluttered in nature, requiring a rethinking of the large form factor systems and grippers. We propose a novel codesigned framework incorporating a global detection camera and a local eye-in-hand camera that demonstrates precise localization of small fruits via closed-loop visual feedback and reliable error handling. Field experiments in high tunnels show our system can reach an average of 85.0\% of cherry tomato fruit in 10.98s on average.
Active Semantic Mapping with Mobile Manipulator in Horticultural Environments
Dec 13, 2024



Semantic maps are fundamental for robotics tasks such as navigation and manipulation. They also enable yield prediction and phenotyping in agricultural settings. In this paper, we introduce an efficient and scalable approach for active semantic mapping in horticultural environments, employing a mobile robot manipulator equipped with an RGB-D camera. Our method leverages probabilistic semantic maps to detect semantic targets, generate candidate viewpoints, and compute corresponding information gain. We present an efficient ray-casting strategy and a novel information utility function that accounts for both semantics and occlusions. The proposed approach reduces total runtime by 8% compared to previous baselines. Furthermore, our information metric surpasses other metrics in reducing multi-class entropy and improving surface coverage, particularly in the presence of segmentation noise. Real-world experiments validate our method's effectiveness but also reveal challenges such as depth sensor noise and varying environmental conditions, requiring further research.
Visual Servoing for Pose Control of Soft Continuum Arm in a Structured Environment
Feb 11, 2022
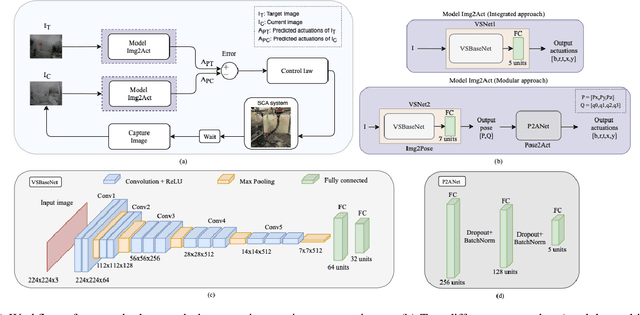

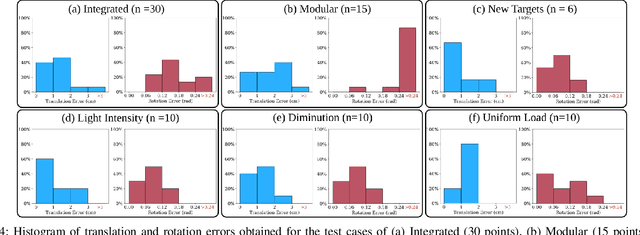
For soft continuum arms, visual servoing is a popular control strategy that relies on visual feedback to close the control loop. However, robust visual servoing is challenging as it requires reliable feature extraction from the image, accurate control models and sensors to perceive the shape of the arm, both of which can be hard to implement in a soft robot. This letter circumvents these challenges by presenting a deep neural network-based method to perform smooth and robust 3D positioning tasks on a soft arm by visual servoing using a camera mounted at the distal end of the arm. A convolutional neural network is trained to predict the actuations required to achieve the desired pose in a structured environment. Integrated and modular approaches for estimating the actuations from the image are proposed and are experimentally compared. A proportional control law is implemented to reduce the error between the desired and current image as seen by the camera. The model together with the proportional feedback control makes the described approach robust to several variations such as new targets, lighting, loads, and diminution of the soft arm. Furthermore, the model lends itself to be transferred to a new environment with minimal effort.
A physics-informed, vision-based method to reconstruct all deformation modes in slender bodies
Sep 17, 2021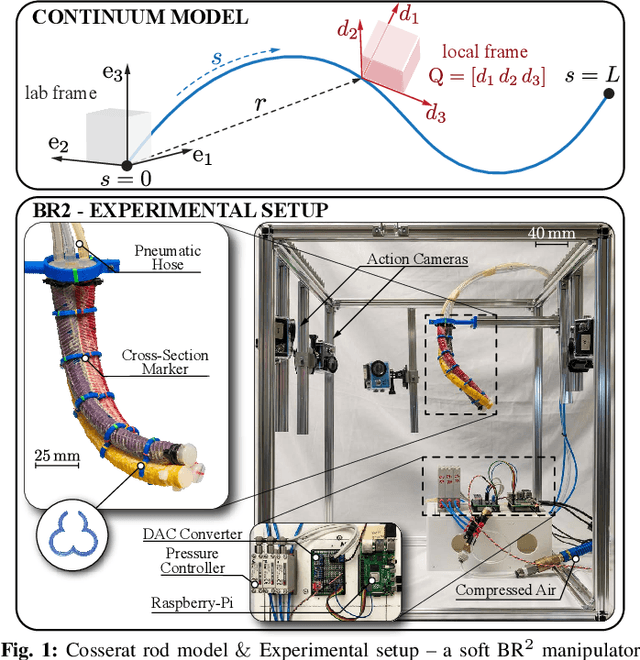
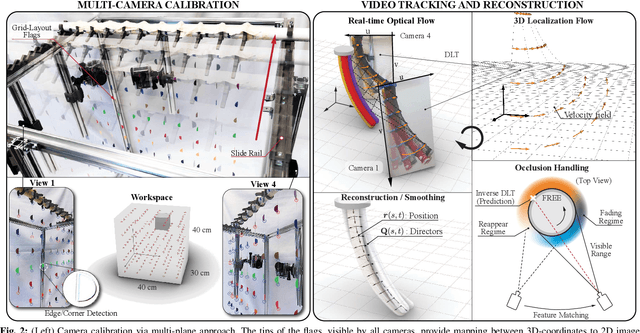
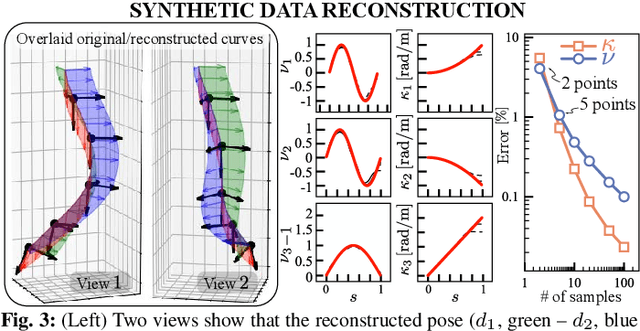
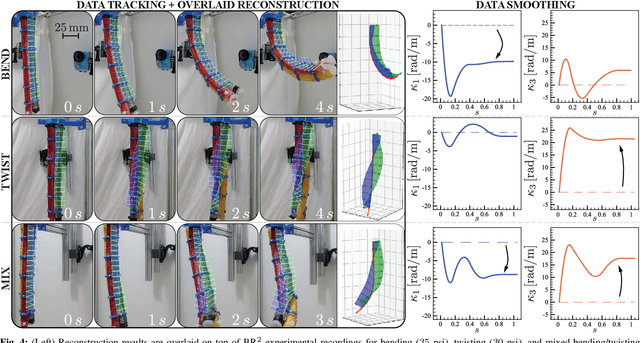
This paper is concerned with the problem of estimating (interpolating and smoothing) the shape (pose and the six modes of deformation) of a slender flexible body from multiple camera measurements. This problem is important in both biology, where slender, soft, and elastic structures are ubiquitously encountered across species, and in engineering, particularly in the area of soft robotics. The proposed mathematical formulation for shape estimation is physics-informed, based on the use of the special Cosserat rod theory whose equations encode slender body mechanics in the presence of bending, shearing, twisting and stretching. The approach is used to derive numerical algorithms which are experimentally demonstrated for fiber reinforced and cable-driven soft robot arms. These experimental demonstrations show that the methodology is accurate (<5 mm error, three times less than the arm diameter) and robust to noise and uncertainties.