 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Classification of Beer Bottles using Object Detection and Transfer Learning
Jan 11, 2022
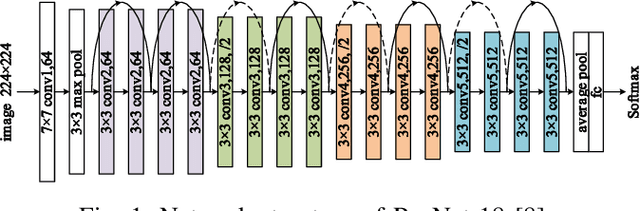

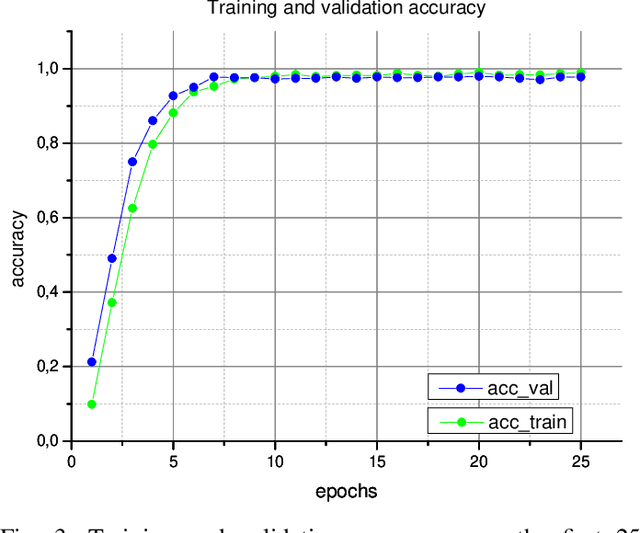
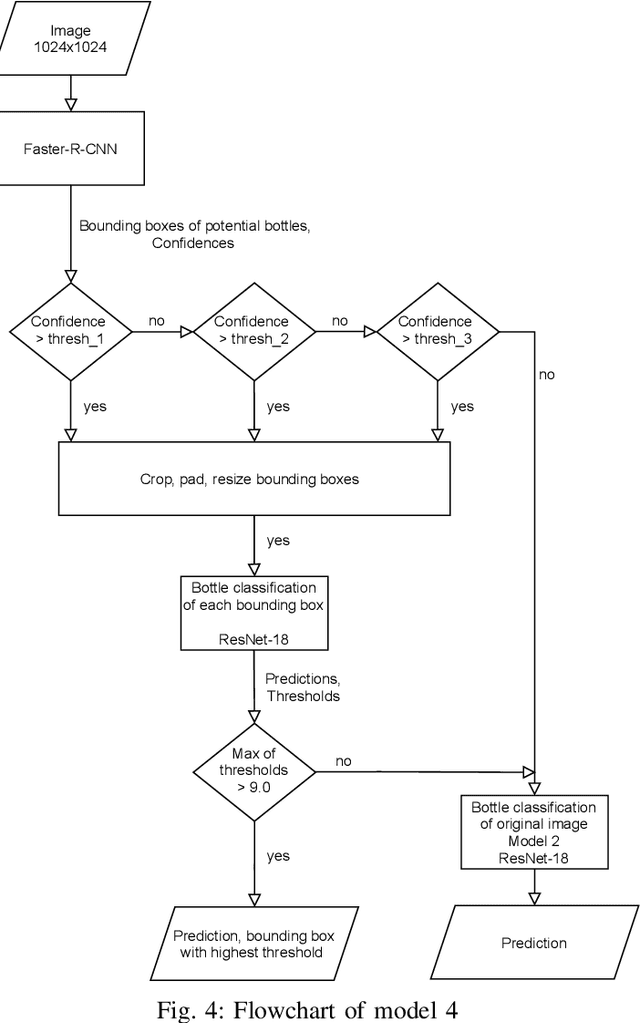
Classification problems are common in Computer Vision. Despite this, there is no dedicated work for the classification of beer bottles. As part of the challenge of the master course Deep Learning, a dataset of 5207 beer bottle images and brand labels was created. An image contains exactly one beer bottle. In this paper we present a deep learning model which classifies pictures of beer bottles in a two step approach. As the first step, a Faster-R-CNN detects image sections relevant for classification independently of the brand. In the second step, the relevant image sections are classified by a ResNet-18. The image section with the highest confidence is returned as class label. We propose a model, with which we surpass the classic one step transfer learning approach and reached an accuracy of 99.86% during the challenge on the final test dataset. We were able to achieve 100% accuracy after the challenge ended
M2FN: Multi-step Modality Fusion for Advertisement Image Assessment
Feb 03, 2021
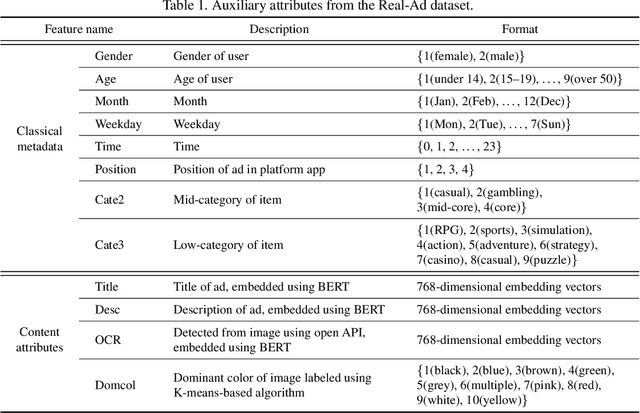
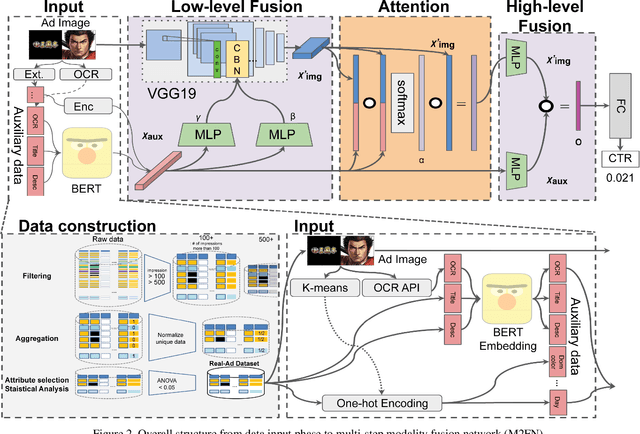
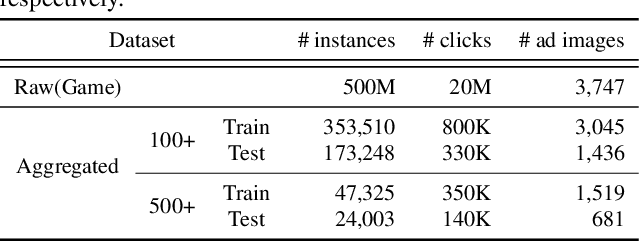
Assessing advertisements, specifically on the basis of user preferences and ad quality, is crucial to the marketing industry. Although recent studies have attempted to use deep neural networks for this purpose, these studies have not utilized image-related auxiliary attributes, which include embedded text frequently found in ad images. We, therefore, investigated the influence of these attributes on ad image preferences. First, we analyzed large-scale real-world ad log data and, based on our findings, proposed a novel multi-step modality fusion network (M2FN) that determines advertising images likely to appeal to user preferences. Our method utilizes auxiliary attributes through multiple steps in the network, which include conditional batch normalization-based low-level fusion and attention-based high-level fusion. We verified M2FN on the AVA dataset, which is widely used for aesthetic image assessment, and then demonstrated that M2FN can achieve state-of-the-art performance in preference prediction using a real-world ad dataset with rich auxiliary attributes.
Declipping of Speech Signals Using Frequency Selective Extrapolation
Apr 07, 2022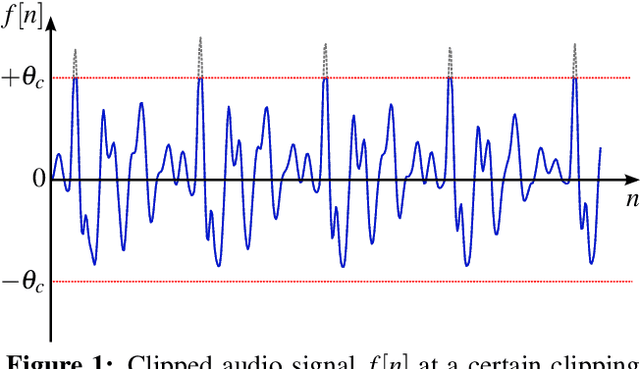

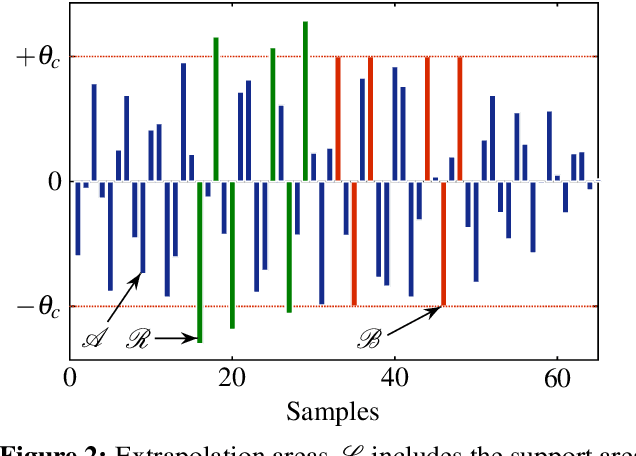
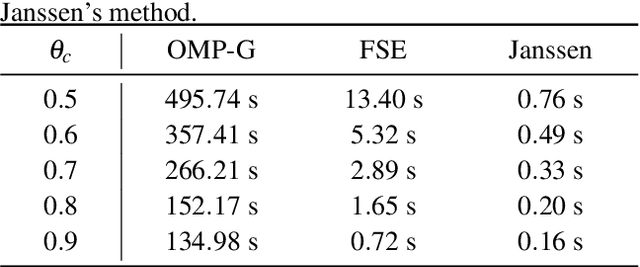
The reconstruction of clipped speech signals is an important task in audio signal processing to achieve an enhanced audio quality for further processing. In this paper, Frequency Selective Extrapolation (FSE), which is commonly used for error concealment or the reconstruction of incomplete image data, is adapted to be able to restore audio signals which are distorted from clipping. For this, FSE generates a model of the signal as an iterative superposition of Fourier basis functions. Clipped samples can then be replaced by estimated samples from the model. The performance of the proposed algorithm is evaluated by using different speech test data sets. Compared to other state-of-the-art declipping algorithms, this leads to a maximum gain in SNR of up to 3:5 dB and an average gain of 1 dB.
News Image Steganography: A Novel Architecture Facilitates the Fake News Identification
Jan 03, 2021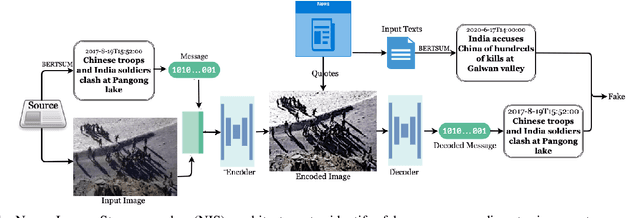

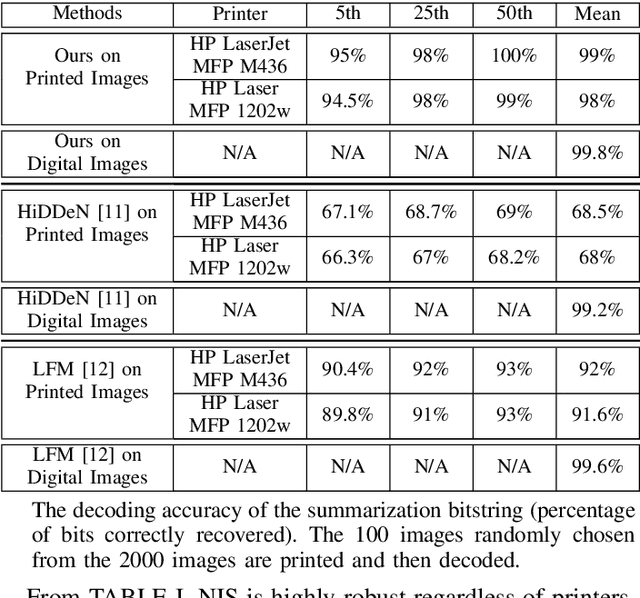
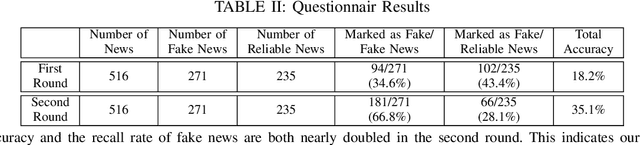
A larger portion of fake news quotes untampered images from other sources with ulterior motives rather than conducting image forgery. Such elaborate engraftments keep the inconsistency between images and text reports stealthy, thereby, palm off the spurious for the genuine. This paper proposes an architecture named News Image Steganography (NIS) to reveal the aforementioned inconsistency through image steganography based on GAN. Extractive summarization about a news image is generated based on its source texts, and a learned steganographic algorithm encodes and decodes the summarization of the image in a manner that approaches perceptual invisibility. Once an encoded image is quoted, its source summarization can be decoded and further presented as the ground truth to verify the quoting news. The pairwise encoder and decoder endow images of the capability to carry along their imperceptible summarization. Our NIS reveals the underlying inconsistency, thereby, according to our experiments and investigations, contributes to the identification accuracy of fake news that engrafts untampered images.
Point Cloud Semantic Segmentation using Multi Scale Sparse Convolution Neural Network
May 04, 2022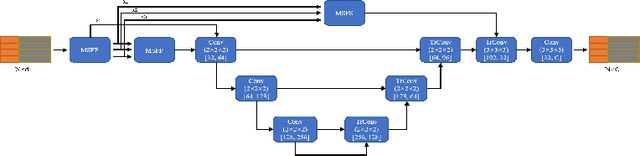
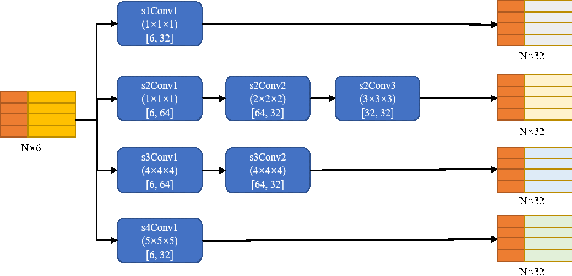
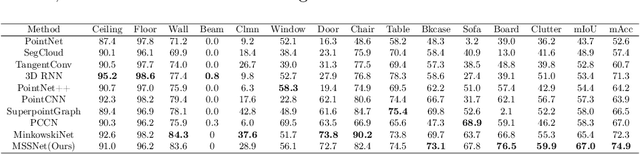
Point clouds have the characteristics of disorder, unstructured and sparseness.Aiming at the problem of the non-structural nature of point clouds, thanks to the excellent performance of convolutional neural networks in image processing, one of the solutions is to extract features from point clouds based on two-dimensional convolutional neural networks. The three-dimensional information carried in the point cloud can be converted to two-dimensional, and then processed by a two-dimensional convolutional neural network, and finally back-projected to three-dimensional.In the process of projecting 3D information to 2D and back-projection, certain information loss will inevitably be caused to the point cloud and category inconsistency will be introduced in the back-projection stage;Another solution is the voxel-based point cloud segmentation method, which divides the point cloud into small grids one by one.However, the point cloud is sparse, and the direct use of 3D convolutional neural network inevitably wastes computing resources. In this paper, we propose a feature extraction module based on multi-scale ultra-sparse convolution and a feature selection module based on channel attention, and build a point cloud segmentation network framework based on this.By introducing multi-scale sparse convolution, network could capture richer feature information based on convolution kernels of different sizes, improving the segmentation result of point cloud segmentation.
U-Net Transformer: Self and Cross Attention for Medical Image Segmentation
Mar 12, 2021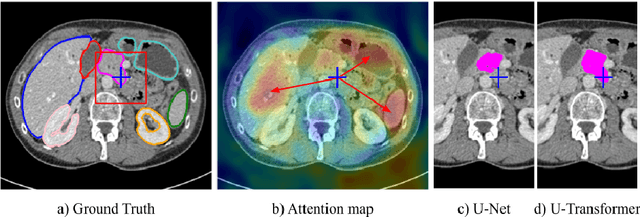

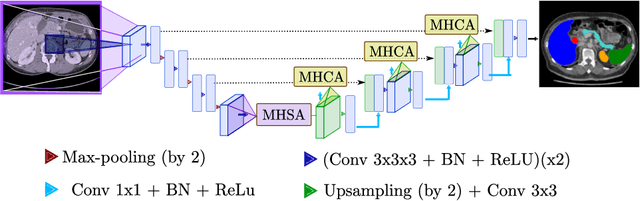
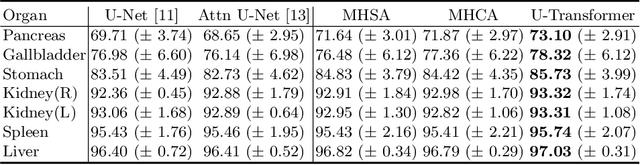
Medical image segmentation remains particularly challenging for complex and low-contrast anatomical structures. In this paper, we introduce the U-Transformer network, which combines a U-shaped architecture for image segmentation with self- and cross-attention from Transformers. U-Transformer overcomes the inability of U-Nets to model long-range contextual interactions and spatial dependencies, which are arguably crucial for accurate segmentation in challenging contexts. To this end, attention mechanisms are incorporated at two main levels: a self-attention module leverages global interactions between encoder features, while cross-attention in the skip connections allows a fine spatial recovery in the U-Net decoder by filtering out non-semantic features. Experiments on two abdominal CT-image datasets show the large performance gain brought out by U-Transformer compared to U-Net and local Attention U-Nets. We also highlight the importance of using both self- and cross-attention, and the nice interpretability features brought out by U-Transformer.
Unsupervised Multimodal Image Registration with Adaptative Gradient Guidance
Nov 12, 2020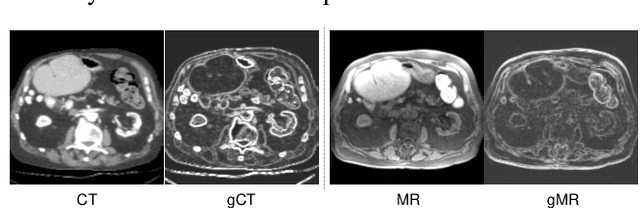
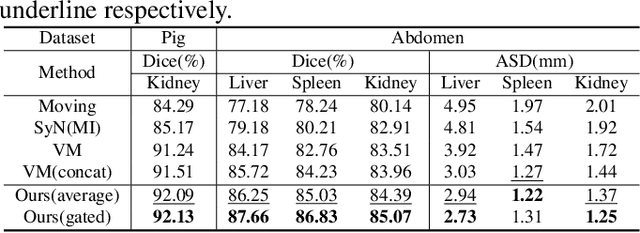
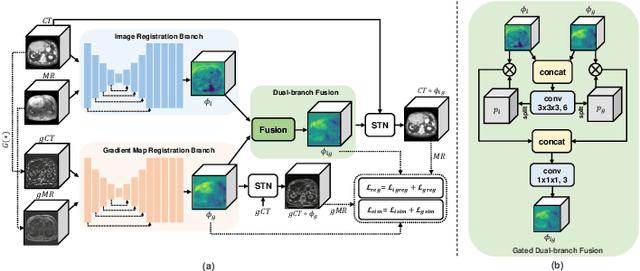

Multimodal image registration (MIR) is a fundamental procedure in many image-guided therapies. Recently, unsupervised learning-based methods have demonstrated promising performance over accuracy and efficiency in deformable image registration. However, the estimated deformation fields of the existing methods fully rely on the to-be-registered image pair. It is difficult for the networks to be aware of the mismatched boundaries, resulting in unsatisfactory organ boundary alignment. In this paper, we propose a novel multimodal registration framework, which leverages the deformation fields estimated from both: (i) the original to-be-registered image pair, (ii) their corresponding gradient intensity maps, and adaptively fuses them with the proposed gated fusion module. With the help of auxiliary gradient-space guidance, the network can concentrate more on the spatial relationship of the organ boundary. Experimental results on two clinically acquired CT-MRI datasets demonstrate the effectiveness of our proposed approach.
An Efficient End-to-End Deep Neural Network for Interstitial Lung Disease Recognition and Classification
Apr 21, 2022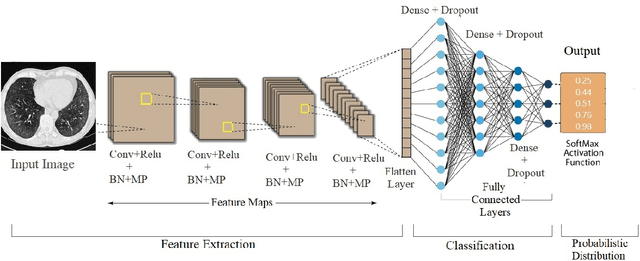
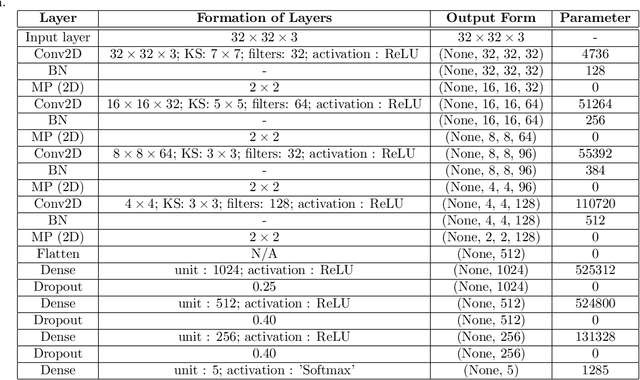
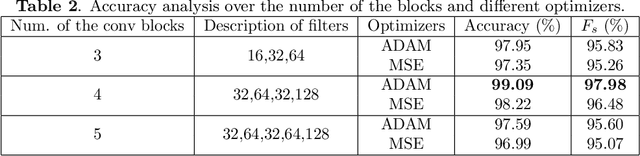
The automated Interstitial Lung Diseases (ILDs) classification technique is essential for assisting clinicians during the diagnosis process. Detecting and classifying ILDs patterns is a challenging problem. This paper introduces an end-to-end deep convolution neural network (CNN) for classifying ILDs patterns. The proposed model comprises four convolutional layers with different kernel sizes and Rectified Linear Unit (ReLU) activation function, followed by batch normalization and max-pooling with a size equal to the final feature map size well as four dense layers. We used the ADAM optimizer to minimize categorical cross-entropy. A dataset consisting of 21328 image patches of 128 CT scans with five classes is taken to train and assess the proposed model. A comparison study showed that the presented model outperformed pre-trained CNNs and five-fold cross-validation on the same dataset. For ILDs pattern classification, the proposed approach achieved the accuracy scores of 99.09% and the average F score of 97.9%, outperforming three pre-trained CNNs. These outcomes show that the proposed model is relatively state-of-the-art in precision, recall, f score, and accuracy.
Towards Practical Certifiable Patch Defense with Vision Transformer
Mar 16, 2022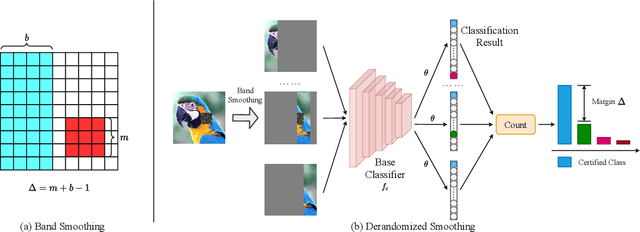

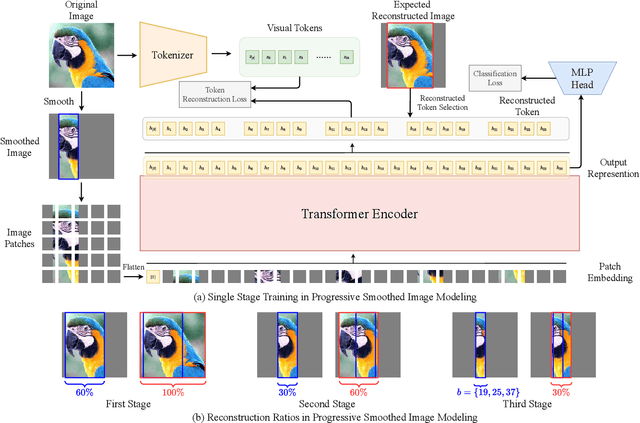
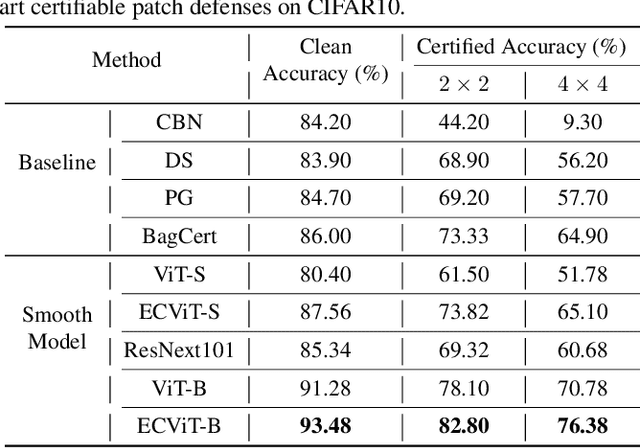
Patch attacks, one of the most threatening forms of physical attack in adversarial examples, can lead networks to induce misclassification by modifying pixels arbitrarily in a continuous region. Certifiable patch defense can guarantee robustness that the classifier is not affected by patch attacks. Existing certifiable patch defenses sacrifice the clean accuracy of classifiers and only obtain a low certified accuracy on toy datasets. Furthermore, the clean and certified accuracy of these methods is still significantly lower than the accuracy of normal classification networks, which limits their application in practice. To move towards a practical certifiable patch defense, we introduce Vision Transformer (ViT) into the framework of Derandomized Smoothing (DS). Specifically, we propose a progressive smoothed image modeling task to train Vision Transformer, which can capture the more discriminable local context of an image while preserving the global semantic information. For efficient inference and deployment in the real world, we innovatively reconstruct the global self-attention structure of the original ViT into isolated band unit self-attention. On ImageNet, under 2% area patch attacks our method achieves 41.70% certified accuracy, a nearly 1-fold increase over the previous best method (26.00%). Simultaneously, our method achieves 78.58% clean accuracy, which is quite close to the normal ResNet-101 accuracy. Extensive experiments show that our method obtains state-of-the-art clean and certified accuracy with inferring efficiently on CIFAR-10 and ImageNet.
Dual-MTGAN: Stochastic and Deterministic Motion Transfer for Image-to-Video Synthesis
Feb 26, 2021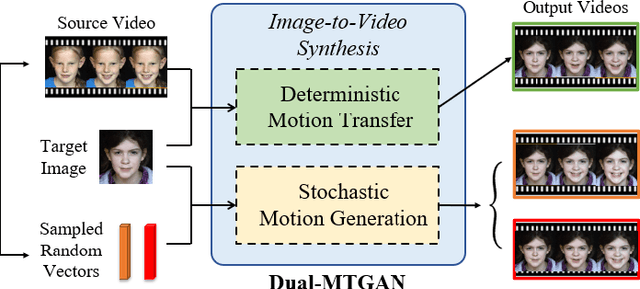
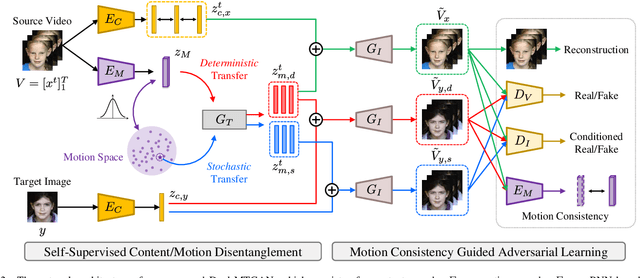


Generating videos with content and motion variations is a challenging task in computer vision. While the recent development of GAN allows video generation from latent representations, it is not easy to produce videos with particular content of motion patterns of interest. In this paper, we propose Dual Motion Transfer GAN (Dual-MTGAN), which takes image and video data as inputs while learning disentangled content and motion representations. Our Dual-MTGAN is able to perform deterministic motion transfer and stochastic motion generation. Based on a given image, the former preserves the input content and transfers motion patterns observed from another video sequence, and the latter directly produces videos with plausible yet diverse motion patterns based on the input image. The proposed model is trained in an end-to-end manner, without the need to utilize pre-defined motion features like pose or facial landmarks. Our quantitative and qualitative results would confirm the effectiveness and robustness of our model in addressing such conditioned image-to-video tasks.