 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Practical Certifiable Patch Defense with Vision Transformer
Mar 16, 2022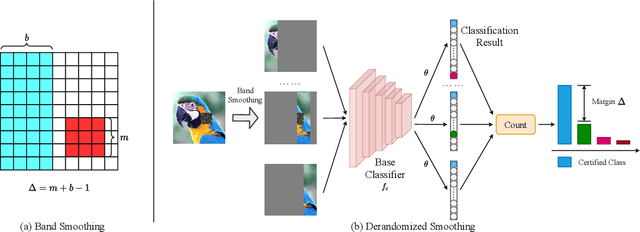

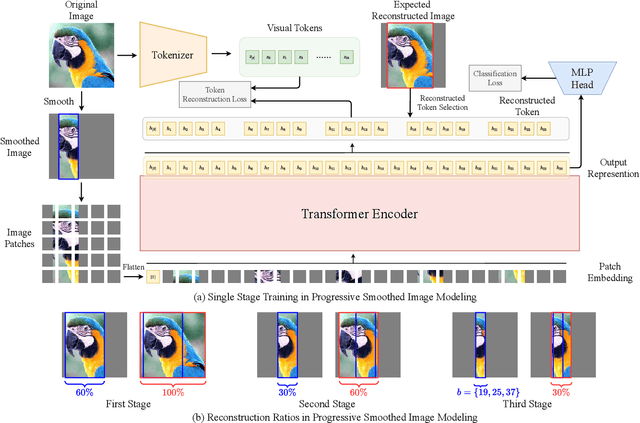
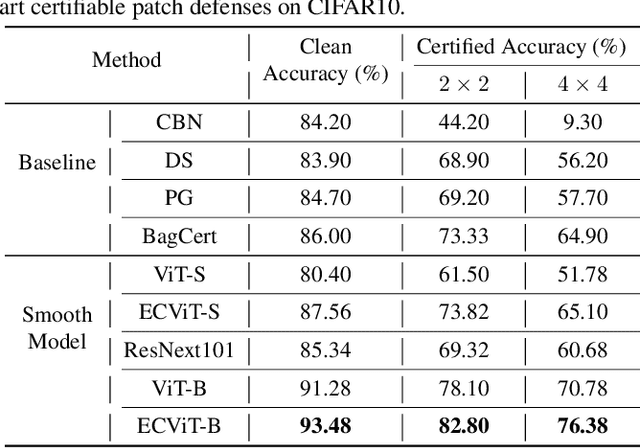
Patch attacks, one of the most threatening forms of physical attack in adversarial examples, can lead networks to induce misclassification by modifying pixels arbitrarily in a continuous region. Certifiable patch defense can guarantee robustness that the classifier is not affected by patch attacks. Existing certifiable patch defenses sacrifice the clean accuracy of classifiers and only obtain a low certified accuracy on toy datasets. Furthermore, the clean and certified accuracy of these methods is still significantly lower than the accuracy of normal classification networks, which limits their application in practice. To move towards a practical certifiable patch defense, we introduce Vision Transformer (ViT) into the framework of Derandomized Smoothing (DS). Specifically, we propose a progressive smoothed image modeling task to train Vision Transformer, which can capture the more discriminable local context of an image while preserving the global semantic information. For efficient inference and deployment in the real world, we innovatively reconstruct the global self-attention structure of the original ViT into isolated band unit self-attention. On ImageNet, under 2% area patch attacks our method achieves 41.70% certified accuracy, a nearly 1-fold increase over the previous best method (26.00%). Simultaneously, our method achieves 78.58% clean accuracy, which is quite close to the normal ResNet-101 accuracy. Extensive experiments show that our method obtains state-of-the-art clean and certified accuracy with inferring efficiently on CIFAR-10 and ImageNet.
A Practical Data-Free Approach to One-shot Federated Learning with Heterogeneity
Dec 23, 2021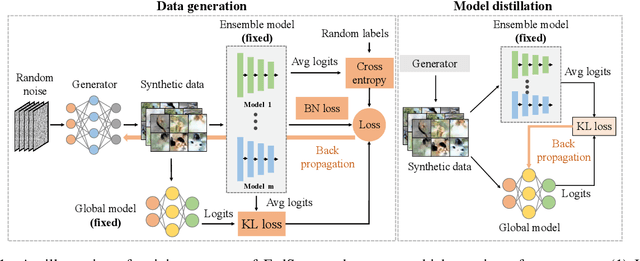

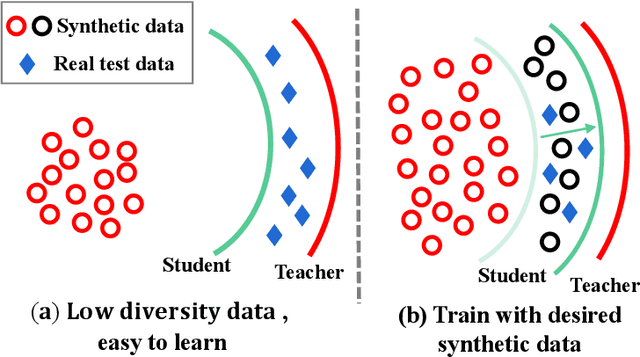

One-shot Federated Learning (FL) has recently emerged as a promising approach, which allows the central server to learn a model in a single communication round. Despite the low communication cost, existing one-shot FL methods are mostly impractical or face inherent limitations, e.g., a public dataset is required, clients' models are homogeneous, need to upload additional data/model information. To overcome these issues, we propose a more practical data-free approach named FedSyn for one-shot FL framework with heterogeneity. Our FedSyn trains the global model by a data generation stage and a model distillation stage. To the best of our knowledge, FedSyn is the first method that can be practically applied to various real-world applications due to the following advantages: (1) FedSyn requires no additional information (except the model parameters) to be transferred between clients and the server; (2) FedSyn does not require any auxiliary dataset for training; (3) FedSyn is the first to consider both model and statistical heterogeneities in FL, i.e., the clients' data are non-iid and different clients may have different model architectures. Experiments on a variety of real-world datasets demonstrate the superiority of our FedSyn. For example, FedSyn outperforms the best baseline method Fed-ADI by 5.08% on CIFAR10 dataset when data are non-iid.