 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Satellite Image and Machine Learning based Knowledge Extraction in the Poverty and Welfare Domain
Mar 02, 2022

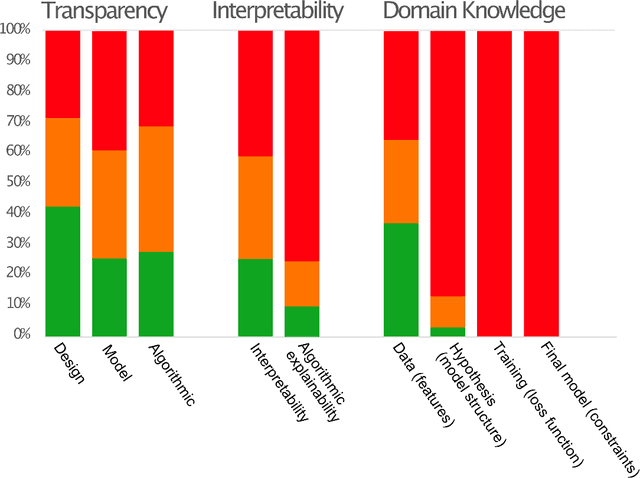

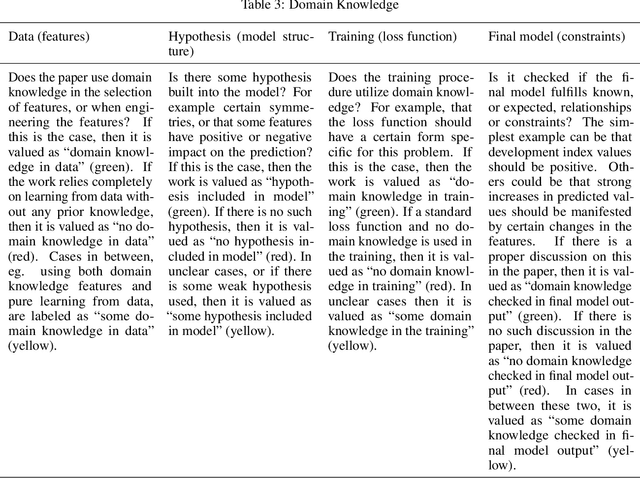
Recent advances in artificial intelligence and machine learning have created a step change in how to measure human development indicators, in particular asset based poverty. The combination of satellite imagery and machine learning has the capability to estimate poverty at a level similar to what is achieved with workhorse methods such as face-to-face interviews and household surveys. An increasingly important issue beyond static estimations is whether this technology can contribute to scientific discovery and consequently new knowledge in the poverty and welfare domain. A foundation for achieving scientific insights is domain knowledge, which in turn translates into explainability and scientific consistency. We review the literature focusing on three core elements relevant in this context: transparency, interpretability, and explainability and investigate how they relates to the poverty, machine learning and satellite imagery nexus. Our review of the field shows that the status of the three core elements of explainable machine learning (transparency, interpretability and domain knowledge) is varied and does not completely fulfill the requirements set up for scientific insights and discoveries. We argue that explainability is essential to support wider dissemination and acceptance of this research, and explainability means more than just interpretability.
Searching Intrinsic Dimensions of Vision Transformers
Apr 16, 2022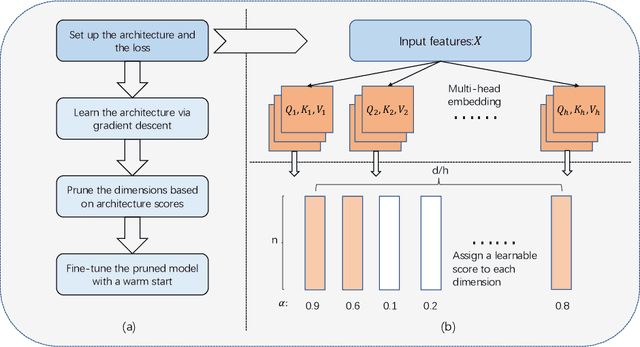
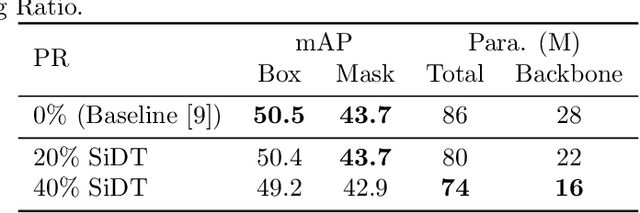
It has been shown by many researchers that transformers perform as well as convolutional neural networks in many computer vision tasks. Meanwhile, the large computational costs of its attention module hinder further studies and applications on edge devices. Some pruning methods have been developed to construct efficient vision transformers, but most of them have considered image classification tasks only. Inspired by these results, we propose SiDT, a method for pruning vision transformer backbones on more complicated vision tasks like object detection, based on the search of transformer dimensions. Experiments on CIFAR-100 and COCO datasets show that the backbones with 20\% or 40\% dimensions/parameters pruned can have similar or even better performance than the unpruned models. Moreover, we have also provided the complexity analysis and comparisons with the previous pruning methods.
Big Self-Supervised Models Advance Medical Image Classification
Jan 13, 2021
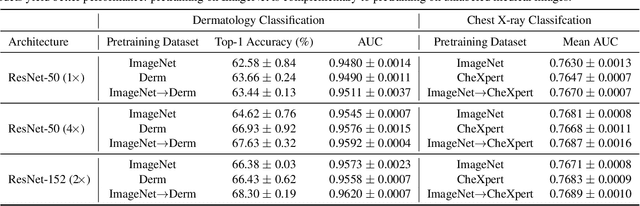
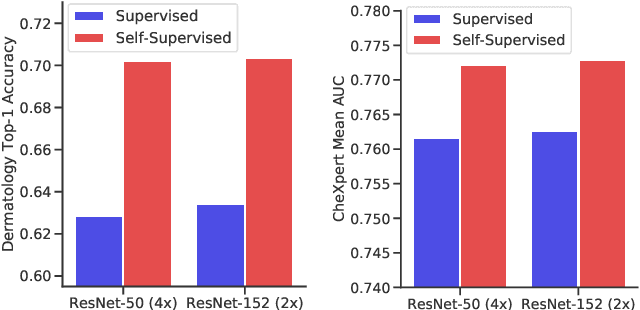
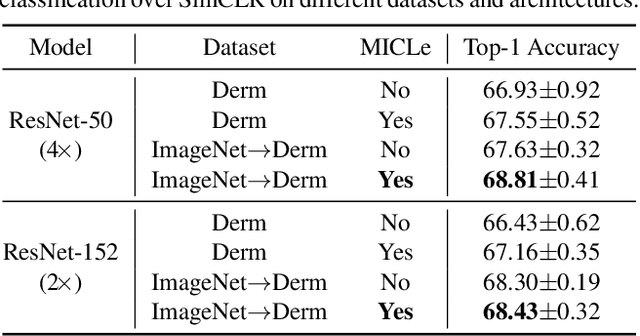
Self-supervised pretraining followed by supervised fine-tuning has seen success in image recognition, especially when labeled examples are scarce, but has received limited attention in medical image analysis. This paper studies the effectiveness of self-supervised learning as a pretraining strategy for medical image classification. We conduct experiments on two distinct tasks: dermatology skin condition classification from digital camera images and multi-label chest X-ray classification, and demonstrate that self-supervised learning on ImageNet, followed by additional self-supervised learning on unlabeled domain-specific medical images significantly improves the accuracy of medical image classifiers. We introduce a novel Multi-Instance Contrastive Learning (MICLe) method that uses multiple images of the underlying pathology per patient case, when available, to construct more informative positive pairs for self-supervised learning. Combining our contributions, we achieve an improvement of 6.7% in top-1 accuracy and an improvement of 1.1% in mean AUC on dermatology and chest X-ray classification respectively, outperforming strong supervised baselines pretrained on ImageNet. In addition, we show that big self-supervised models are robust to distribution shift and can learn efficiently with a small number of labeled medical images.
Deep Aesthetic Assessment and Retrieval of Breast Cancer Treatment Outcomes
May 25, 2022Treatments for breast cancer have continued to evolve and improve in recent years, resulting in a substantial increase in survival rates, with approximately 80\% of patients having a 10-year survival period. Given the serious impact that breast cancer treatments can have on a patient's body image, consequently affecting her self-confidence and sexual and intimate relationships, it is paramount to ensure that women receive the treatment that optimizes both survival and aesthetic outcomes. Currently, there is no gold standard for evaluating the aesthetic outcome of breast cancer treatment. In addition, there is no standard way to show patients the potential outcome of surgery. The presentation of similar cases from the past would be extremely important to manage women's expectations of the possible outcome. In this work, we propose a deep neural network to perform the aesthetic evaluation. As a proof-of-concept, we focus on a binary aesthetic evaluation. Besides its use for classification, this deep neural network can also be used to find the most similar past cases by searching for nearest neighbours in the highly semantic space before classification. We performed the experiments on a dataset consisting of 143 photos of women after conservative treatment for breast cancer. The results for accuracy and balanced accuracy showed the superior performance of our proposed model compared to the state of the art in aesthetic evaluation of breast cancer treatments. In addition, the model showed a good ability to retrieve similar previous cases, with the retrieved cases having the same or adjacent class (in the 4-class setting) and having similar types of asymmetry. Finally, a qualitative interpretability assessment was also performed to analyse the robustness and trustworthiness of the model.
Single-stage Keypoint-based Category-level Object Pose Estimation from an RGB Image
Sep 13, 2021
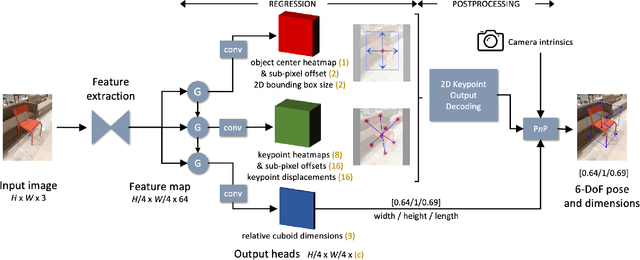

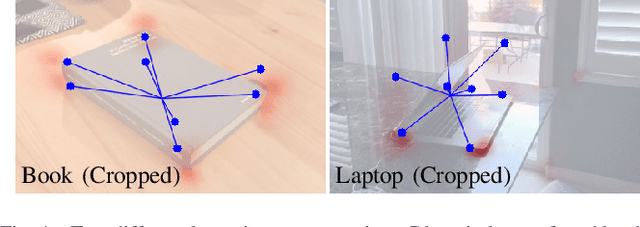
Prior work on 6-DoF object pose estimation has largely focused on instance-level processing, in which a textured CAD model is available for each object being detected. Category-level 6-DoF pose estimation represents an important step toward developing robotic vision systems that operate in unstructured, real-world scenarios. In this work, we propose a single-stage, keypoint-based approach for category-level object pose estimation that operates on unknown object instances within a known category using a single RGB image as input. The proposed network performs 2D object detection, detects 2D keypoints, estimates 6-DoF pose, and regresses relative bounding cuboid dimensions. These quantities are estimated in a sequential fashion, leveraging the recent idea of convGRU for propagating information from easier tasks to those that are more difficult. We favor simplicity in our design choices: generic cuboid vertex coordinates, single-stage network, and monocular RGB input. We conduct extensive experiments on the challenging Objectron benchmark, outperforming state-of-the-art methods on the 3D IoU metric (27.6% higher than the MobilePose single-stage approach and 7.1% higher than the related two-stage approach).
CtlGAN: Few-shot Artistic Portraits Generation with Contrastive Transfer Learning
Mar 16, 2022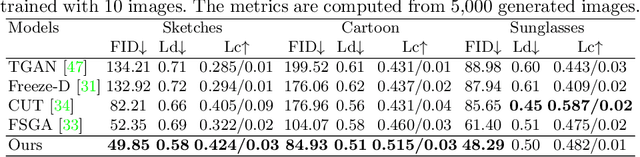

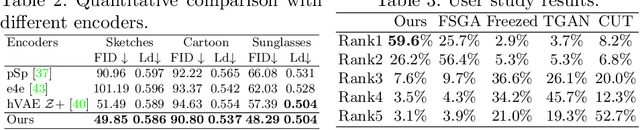
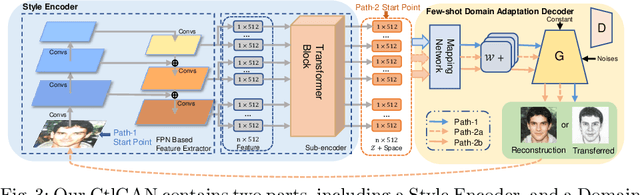
Generating artistic portraits is a challenging problem in computer vision. Existing portrait stylization models that generate good quality results are based on Image-to-Image Translation and require abundant data from both source and target domains. However, without enough data, these methods would result in overfitting. In this work, we propose CtlGAN, a new few-shot artistic portraits generation model with a novel contrastive transfer learning strategy. We adapt a pretrained StyleGAN in the source domain to a target artistic domain with no more than 10 artistic faces. To reduce overfitting to the few training examples, we introduce a novel Cross-Domain Triplet loss which explicitly encourages the target instances generated from different latent codes to be distinguishable. We propose a new encoder which embeds real faces into Z+ space and proposes a dual-path training strategy to better cope with the adapted decoder and eliminate the artifacts. Extensive qualitative, quantitative comparisons and a user study show our method significantly outperforms state-of-the-arts under 10-shot and 1-shot settings and generates high quality artistic portraits. The code will be made publicly available.
EDTER: Edge Detection with Transformer
Mar 16, 2022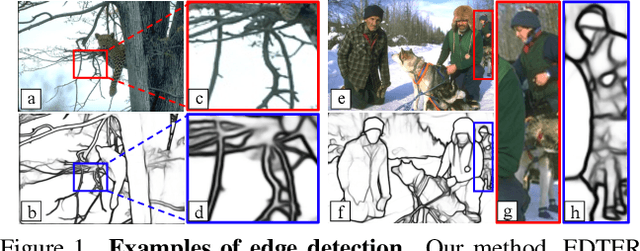

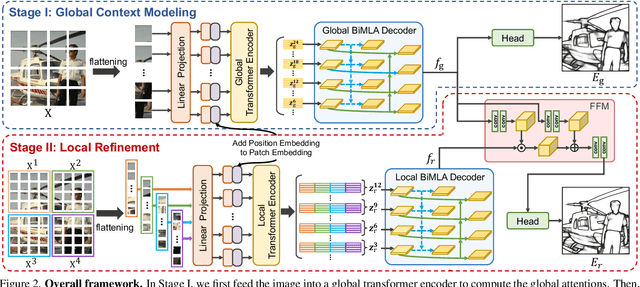
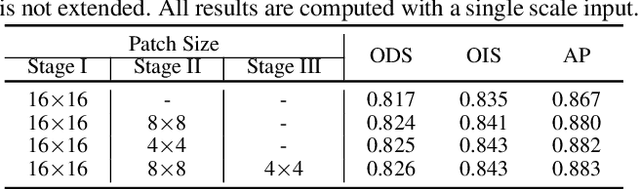
Convolutional neural networks have made significant progresses in edge detection by progressively exploring the context and semantic features. However, local details are gradually suppressed with the enlarging of receptive fields. Recently, vision transformer has shown excellent capability in capturing long-range dependencies. Inspired by this, we propose a novel transformer-based edge detector, \emph{Edge Detection TransformER (EDTER)}, to extract clear and crisp object boundaries and meaningful edges by exploiting the full image context information and detailed local cues simultaneously. EDTER works in two stages. In Stage I, a global transformer encoder is used to capture long-range global context on coarse-grained image patches. Then in Stage II, a local transformer encoder works on fine-grained patches to excavate the short-range local cues. Each transformer encoder is followed by an elaborately designed Bi-directional Multi-Level Aggregation decoder to achieve high-resolution features. Finally, the global context and local cues are combined by a Feature Fusion Module and fed into a decision head for edge prediction. Extensive experiments on BSDS500, NYUDv2, and Multicue demonstrate the superiority of EDTER in comparison with state-of-the-arts.
StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Translation
Feb 24, 2022


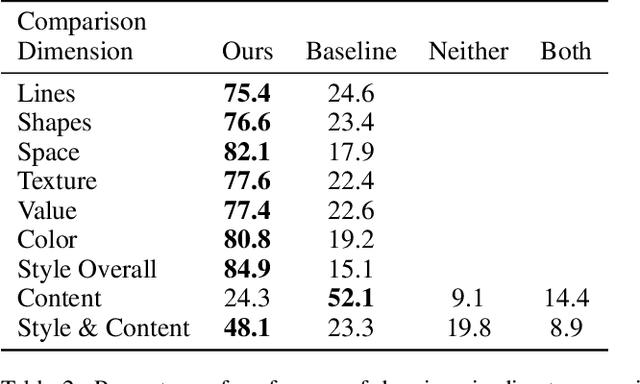
Generating images that fit a given text description using machine learning has improved greatly with the release of technologies such as the CLIP image-text encoder model; however, current methods lack artistic control of the style of image to be generated. We present an approach for generating styled drawings for a given text description where a user can specify a desired drawing style using a sample image. Inspired by a theory in art that style and content are generally inseparable during the creative process, we propose a coupled approach, known here as StyleCLIPDraw, whereby the drawing is generated by optimizing for style and content simultaneously throughout the process as opposed to applying style transfer after creating content in a sequence. Based on human evaluation, the styles of images generated by StyleCLIPDraw are strongly preferred to those by the sequential approach. Although the quality of content generation degrades for certain styles, overall considering both content \textit{and} style, StyleCLIPDraw is found far more preferred, indicating the importance of style, look, and feel of machine generated images to people as well as indicating that style is coupled in the drawing process itself. Our code (https://github.com/pschaldenbrand/StyleCLIPDraw), a demonstration (https://replicate.com/pschaldenbrand/style-clip-draw), and style evaluation data (https://www.kaggle.com/pittsburghskeet/drawings-with-style-evaluation-styleclipdraw) are publicly available.
Improving Adversarial Transferability with Spatial Momentum
Mar 25, 2022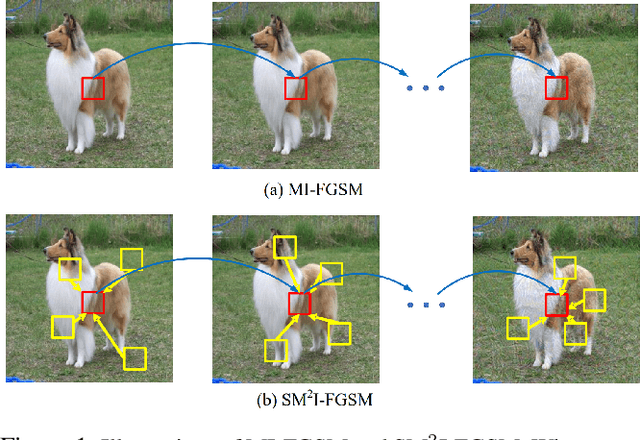
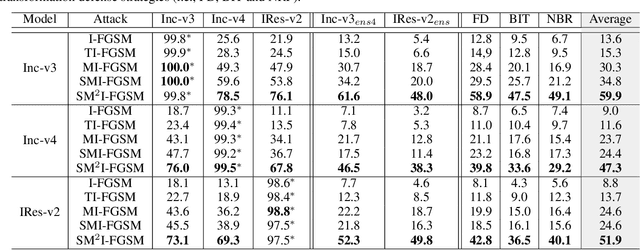
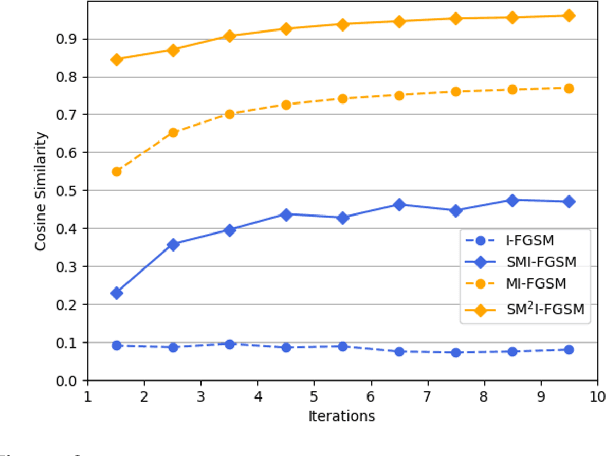
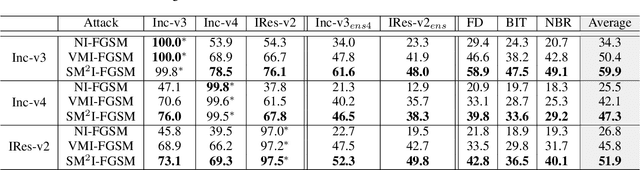
Deep Neural Networks (DNN) are vulnerable to adversarial examples. Although many adversarial attack methods achieve satisfactory attack success rates under the white-box setting, they usually show poor transferability when attacking other DNN models. Momentum-based attack (MI-FGSM) is one effective method to improve transferability. It integrates the momentum term into the iterative process, which can stabilize the update directions by adding the gradients' temporal correlation for each pixel. We argue that only this temporal momentum is not enough, the gradients from the spatial domain within an image, i.e. gradients from the context pixels centered on the target pixel are also important to the stabilization. For that, in this paper, we propose a novel method named Spatial Momentum Iterative FGSM Attack (SMI-FGSM), which introduces the mechanism of momentum accumulation from temporal domain to spatial domain by considering the context gradient information from different regions within the image. SMI-FGSM is then integrated with MI-FGSM to simultaneously stabilize the gradients' update direction from both the temporal and spatial domain. The final method is called SM$^2$I-FGSM. Extensive experiments are conducted on the ImageNet dataset and results show that SM$^2$I-FGSM indeed further enhances the transferability. It achieves the best transferability success rate for multiple mainstream undefended and defended models, which outperforms the state-of-the-art methods by a large margin.
The Surprising Effectiveness of Linear Unsupervised Image-to-Image Translation
Jul 24, 2020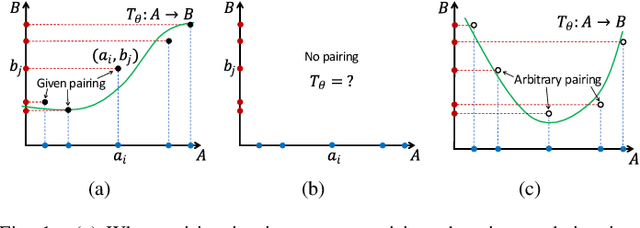



Unsupervised image-to-image translation is an inherently ill-posed problem. Recent methods based on deep encoder-decoder architectures have shown impressive results, but we show that they only succeed due to a strong locality bias, and they fail to learn very simple nonlocal transformations (e.g. mapping upside down faces to upright faces). When the locality bias is removed, the methods are too powerful and may fail to learn simple local transformations. In this paper we introduce linear encoder-decoder architectures for unsupervised image to image translation. We show that learning is much easier and faster with these architectures and yet the results are surprisingly effective. In particular, we show a number of local problems for which the results of the linear methods are comparable to those of state-of-the-art architectures but with a fraction of the training time, and a number of nonlocal problems for which the state-of-the-art fails while linear methods succeed.