 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Robust 2D Convolution for Reliable Visual Recognition
Mar 18, 2022
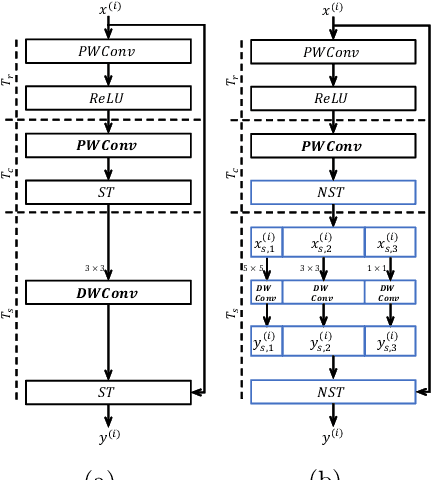

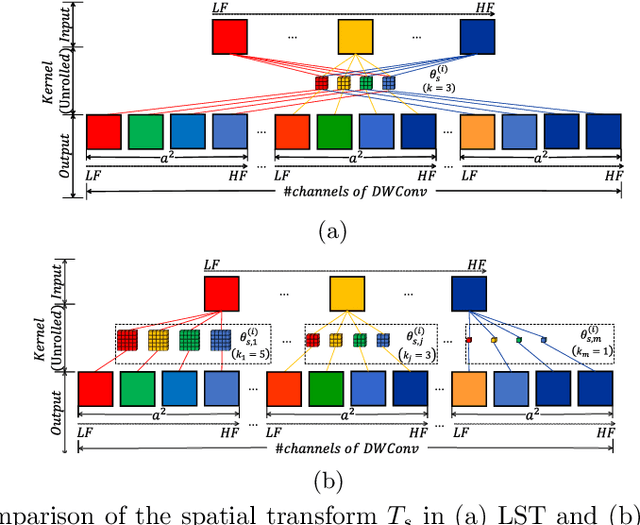
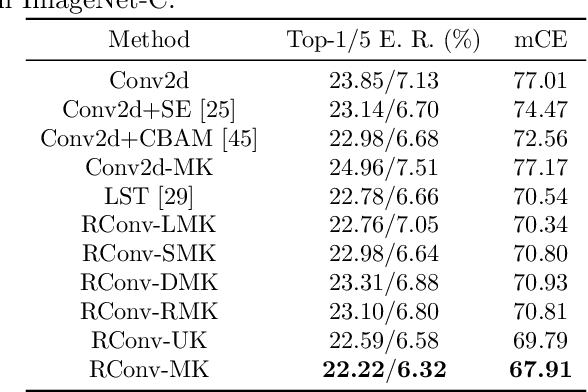
2D convolution (Conv2d), which is responsible for extracting features from the input image, is one of the key modules of a convolutional neural network (CNN). However, Conv2d is vulnerable to image corruptions and adversarial samples. It is an important yet rarely investigated problem that whether we can design a more robust alternative of Conv2d for more reliable feature extraction. In this paper, inspired by the recently developed learnable sparse transform that learns to convert the CNN features into a compact and sparse latent space, we design a novel building block, denoted by RConv-MK, to strengthen the robustness of extracted convolutional features. Our method leverages a set of learnable kernels of different sizes to extract features at different frequencies and employs a normalized soft thresholding operator to adaptively remove noises and trivial features at different corruption levels. Extensive experiments on clean images, corrupted images as well as adversarial samples validate the effectiveness of the proposed robust module for reliable visual recognition. The source codes are enclosed in the submission.
HYLDA: End-to-end Hybrid Learning Domain Adaptation for LiDAR Semantic Segmentation
Jan 14, 2022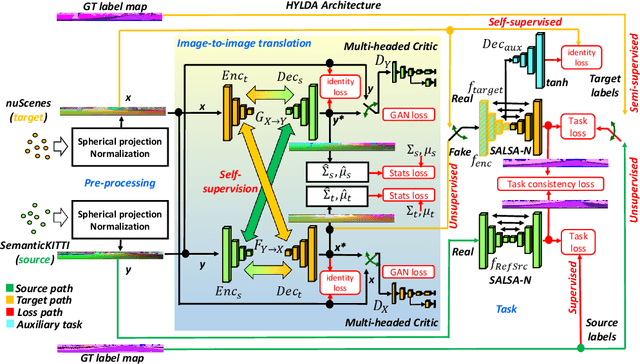
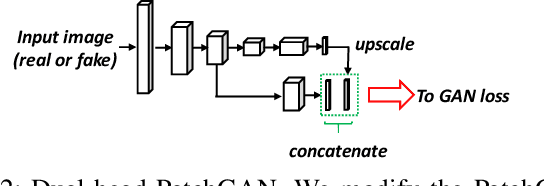

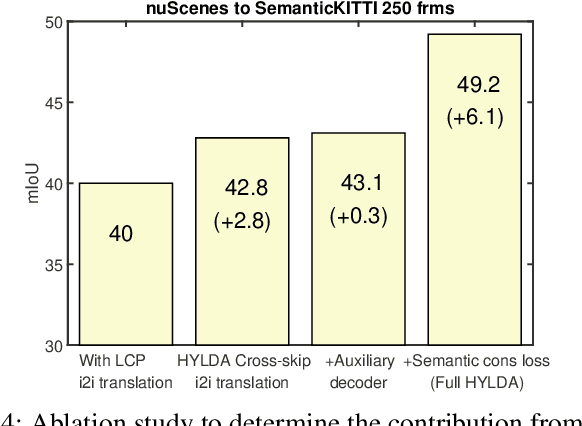
In this paper we address the problem of training a LiDAR semantic segmentation network using a fully-labeled source dataset and a target dataset that only has a small number of labels. To this end, we develop a novel image-to-image translation engine, and couple it with a LiDAR semantic segmentation network, resulting in an integrated domain adaptation architecture we call HYLDA. To train the system end-to-end, we adopt a diverse set of learning paradigms, including 1) self-supervision on a simple auxiliary reconstruction task, 2) semi-supervised training using a few available labeled target domain frames, and 3) unsupervised training on the fake translated images generated by the image-to-image translation stage, together with the labeled frames from the source domain. In the latter case, the semantic segmentation network participates in the updating of the image-to-image translation engine. We demonstrate experimentally that HYLDA effectively addresses the challenging problem of improving generalization on validation data from the target domain when only a few target labeled frames are available for training. We perform an extensive evaluation where we compare HYLDA against strong baseline methods using two publicly available LiDAR semantic segmentation datasets.
ObjectMix: Data Augmentation by Copy-Pasting Objects in Videos for Action Recognition
Apr 01, 2022
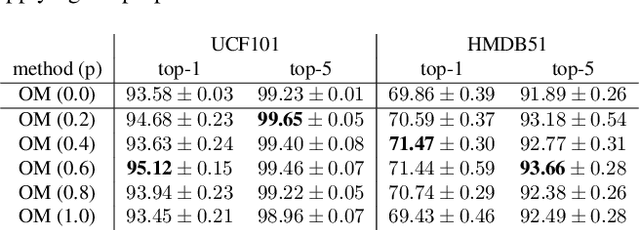

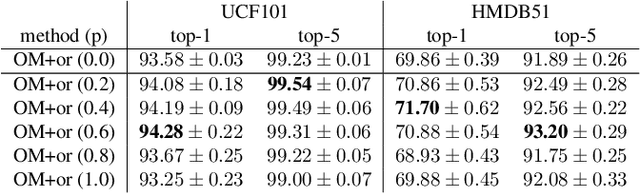
In this paper, we propose a data augmentation method for action recognition using instance segmentation. Although many data augmentation methods have been proposed for image recognition, few methods have been proposed for action recognition. Our proposed method, ObjectMix, extracts each object region from two videos using instance segmentation and combines them to create new videos. Experiments on two action recognition datasets, UCF101 and HMDB51, demonstrate the effectiveness of the proposed method and show its superiority over VideoMix, a prior work.
Interventional Multi-Instance Learning with Deconfounded Instance-Level Prediction
Apr 22, 2022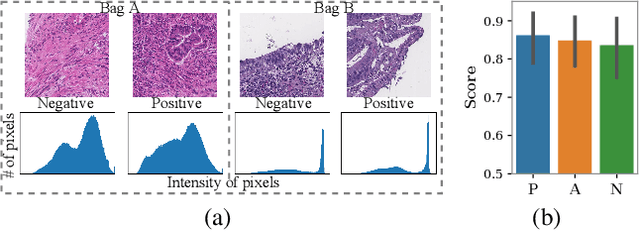
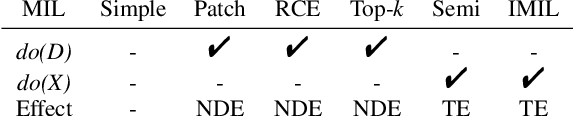
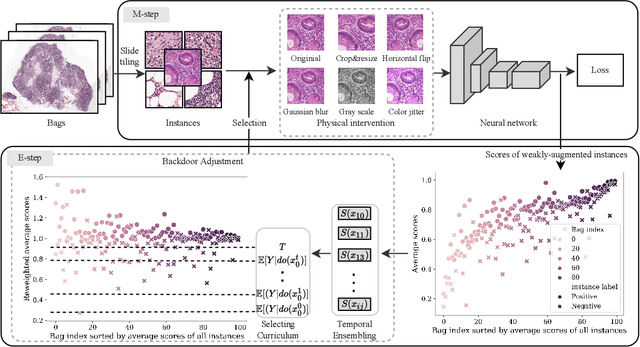
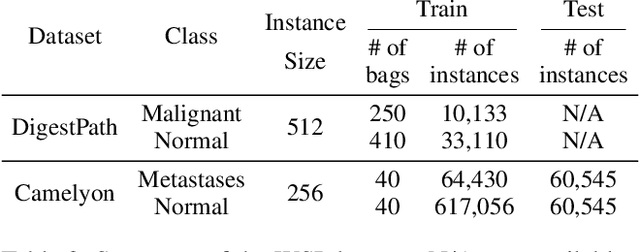
When applying multi-instance learning (MIL) to make predictions for bags of instances, the prediction accuracy of an instance often depends on not only the instance itself but also its context in the corresponding bag. From the viewpoint of causal inference, such bag contextual prior works as a confounder and may result in model robustness and interpretability issues. Focusing on this problem, we propose a novel interventional multi-instance learning (IMIL) framework to achieve deconfounded instance-level prediction. Unlike traditional likelihood-based strategies, we design an Expectation-Maximization (EM) algorithm based on causal intervention, providing a robust instance selection in the training phase and suppressing the bias caused by the bag contextual prior. Experiments on pathological image analysis demonstrate that our IMIL method substantially reduces false positives and outperforms state-of-the-art MIL methods.
GOSS: Towards Generalized Open-set Semantic Segmentation
Mar 23, 2022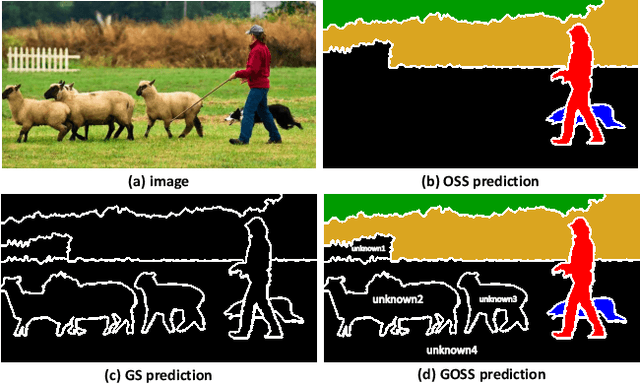

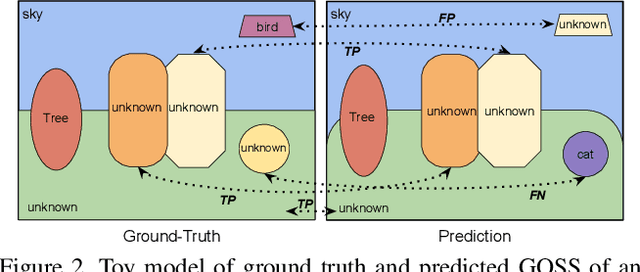

In this paper, we present and study a new image segmentation task, called Generalized Open-set Semantic Segmentation (GOSS). Previously, with the well-known open-set semantic segmentation (OSS), the intelligent agent only detects the unknown regions without further processing, limiting their perception of the environment. It stands to reason that a further analysis of the detected unknown pixels would be beneficial. Therefore, we propose GOSS, which unifies the abilities of two well-defined segmentation tasks, OSS and generic segmentation (GS), in a holistic way. Specifically, GOSS classifies pixels as belonging to known classes, and clusters (or groups) of pixels of unknown class are labelled as such. To evaluate this new expanded task, we further propose a metric which balances the pixel classification and clustering aspects. Moreover, we build benchmark tests on top of existing datasets and propose a simple neural architecture as a baseline, which jointly predicts pixel classification and clustering under open-set settings. Our experiments on multiple benchmarks demonstrate the effectiveness of our baseline. We believe our new GOSS task can produce an expressive image understanding for future research. Code will be made available.
CEKD:Cross Ensemble Knowledge Distillation for Augmented Fine-grained Data
Mar 13, 2022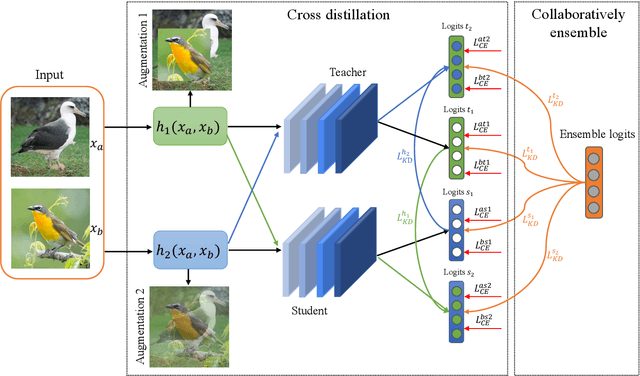
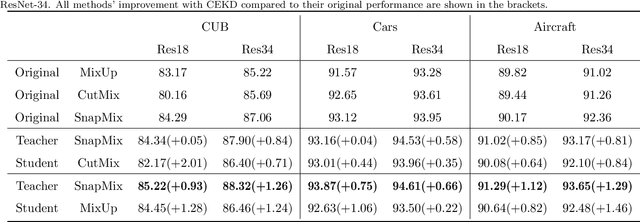
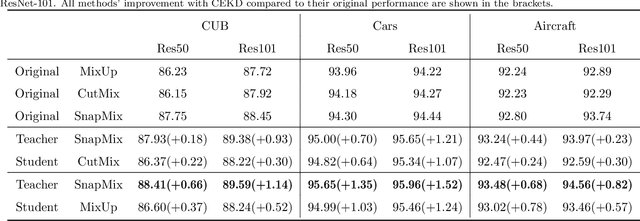

Data augmentation has been proved effective in training deep models. Existing data augmentation methods tackle the fine-grained problem by blending image pairs and fusing corresponding labels according to the statistics of mixed pixels, which produces additional noise harmful to the performance of networks. Motivated by this, we present a simple yet effective cross ensemble knowledge distillation (CEKD) model for fine-grained feature learning. We innovatively propose a cross distillation module to provide additional supervision to alleviate the noise problem, and propose a collaborative ensemble module to overcome the target conflict problem. The proposed model can be trained in an end-to-end manner, and only requires image-level label supervision. Extensive experiments on widely used fine-grained benchmarks demonstrate the effectiveness of our proposed model. Specifically, with the backbone of ResNet-101, CEKD obtains the accuracy of 89.59%, 95.96% and 94.56% in three datasets respectively, outperforming state-of-the-art API-Net by 0.99%, 1.06% and 1.16%.
MaxViT: Multi-Axis Vision Transformer
Apr 04, 2022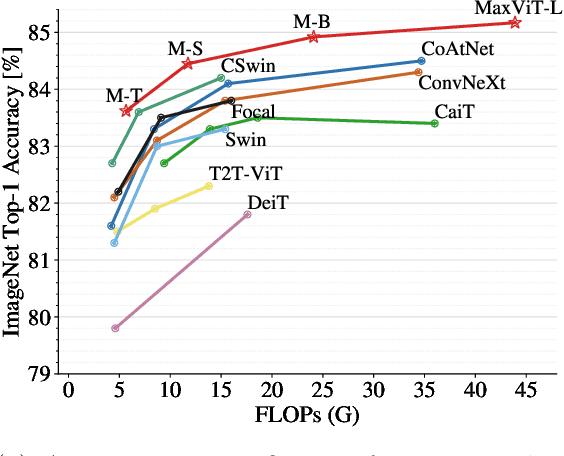

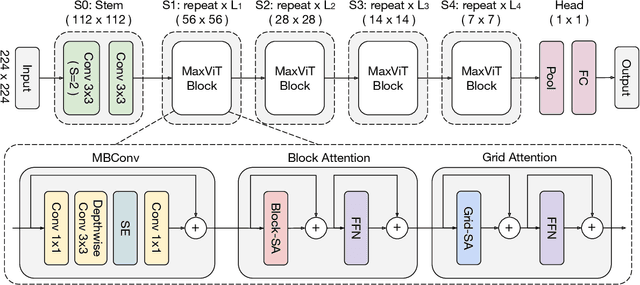
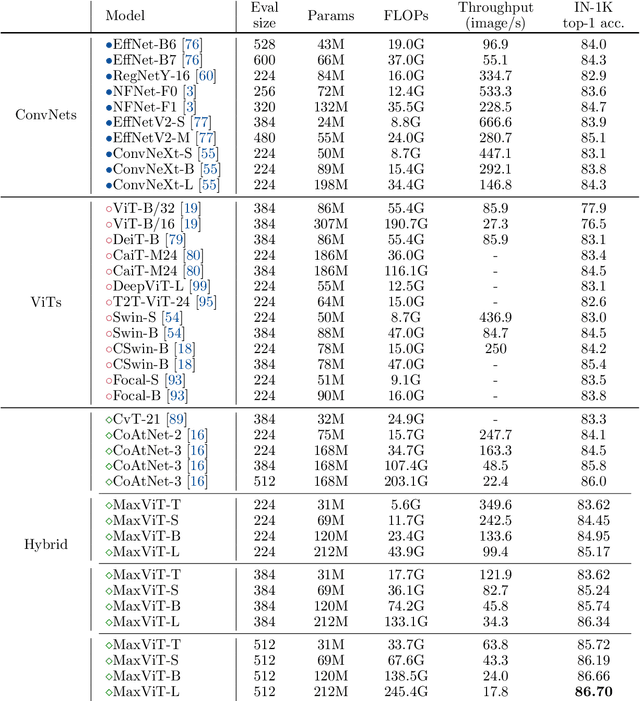
Transformers have recently gained significant attention in the computer vision community. However, the lack of scalability of self-attention mechanisms with respect to image size has limited their wide adoption in state-of-the-art vision backbones. In this paper we introduce an efficient and scalable attention model we call multi-axis attention, which consists of two aspects: blocked local and dilated global attention. These design choices allow global-local spatial interactions on arbitrary input resolutions with only linear complexity. We also present a new architectural element by effectively blending our proposed attention model with convolutions, and accordingly propose a simple hierarchical vision backbone, dubbed MaxViT, by simply repeating the basic building block over multiple stages. Notably, MaxViT is able to "see" globally throughout the entire network, even in earlier, high-resolution stages. We demonstrate the effectiveness of our model on a broad spectrum of vision tasks. On image classification, MaxViT achieves state-of-the-art performance under various settings: without extra data, MaxViT attains 86.5\% ImageNet-1K top-1 accuracy; with ImageNet-21K pre-training, our model achieves 88.7\% top-1 accuracy. For downstream tasks, MaxViT as a backbone delivers favorable performance on object detection as well as visual aesthetic assessment. We also show that our proposed model expresses strong generative modeling capability on ImageNet, demonstrating the superior potential of MaxViT blocks as a universal vision module. We will make the code and models publicly available.
Sketches image analysis: Web image search engine usingLSH index and DNN InceptionV3
May 03, 2021The adoption of an appropriate approximate similarity search method is an essential prereq-uisite for developing a fast and efficient CBIR system, especially when dealing with large amount ofdata. In this study we implement a web image search engine on top of a Locality Sensitive Hashing(LSH) Index to allow fast similarity search on deep features. Specifically, we exploit transfer learningfor deep features extraction from images. Firstly, we adopt InceptionV3 pretrained on ImageNet asfeatures extractor, secondly, we try out several CNNs built on top of InceptionV3 as convolutionalbase fine-tuned on our dataset. In both of the previous cases we index the features extracted within ourLSH index implementation so as to compare the retrieval performances with and without fine-tuning.In our approach we try out two different LSH implementations: the first one working with real numberfeature vectors and the second one with the binary transposed version of those vectors. Interestingly,we obtain the best performances when using the binary LSH, reaching almost the same result, in termsof mean average precision, obtained by performing sequential scan of the features, thus avoiding thebias introduced by the LSH index. Lastly, we carry out a performance analysis class by class in terms ofrecall againstmAPhighlighting, as expected, a strong positive correlation between the two.
Neural Estimation of the Rate-Distortion Function With Applications to Operational Source Coding
Apr 04, 2022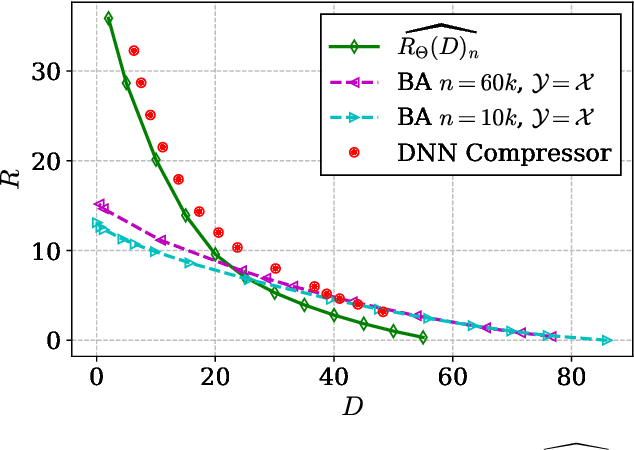
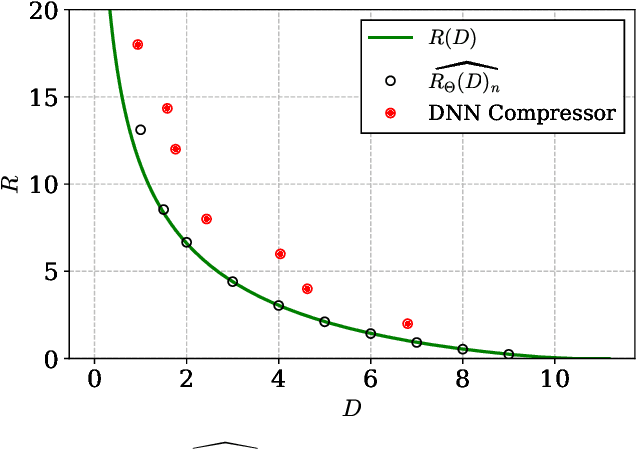
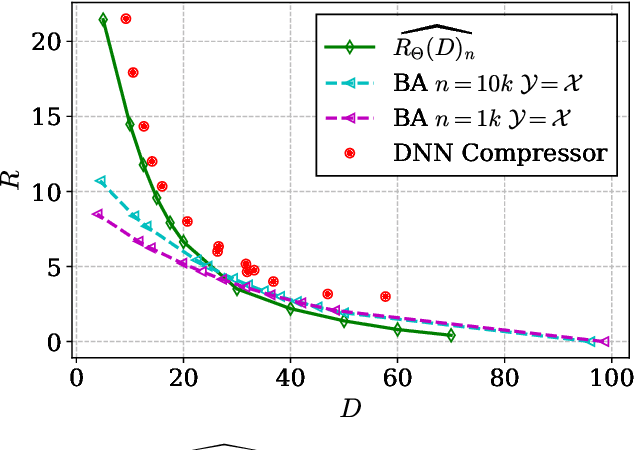

A fundamental question in designing lossy data compression schemes is how well one can do in comparison with the rate-distortion function, which describes the known theoretical limits of lossy compression. Motivated by the empirical success of deep neural network (DNN) compressors on large, real-world data, we investigate methods to estimate the rate-distortion function on such data, which would allow comparison of DNN compressors with optimality. While one could use the empirical distribution of the data and apply the Blahut-Arimoto algorithm, this approach presents several computational challenges and inaccuracies when the datasets are large and high-dimensional, such as the case of modern image datasets. Instead, we re-formulate the rate-distortion objective, and solve the resulting functional optimization problem using neural networks. We apply the resulting rate-distortion estimator, called NERD, on popular image datasets, and provide evidence that NERD can accurately estimate the rate-distortion function. Using our estimate, we show that the rate-distortion achievable by DNN compressors are within several bits of the rate-distortion function for real-world datasets. Additionally, NERD provides access to the rate-distortion achieving channel, as well as samples from its output marginal. Therefore, using recent results in reverse channel coding, we describe how NERD can be used to construct an operational one-shot lossy compression scheme with guarantees on the achievable rate and distortion. Experimental results demonstrate competitive performance with DNN compressors.
Case-based similar image retrieval for weakly annotated large histopathological images of malignant lymphoma using deep metric learning
Jul 08, 2021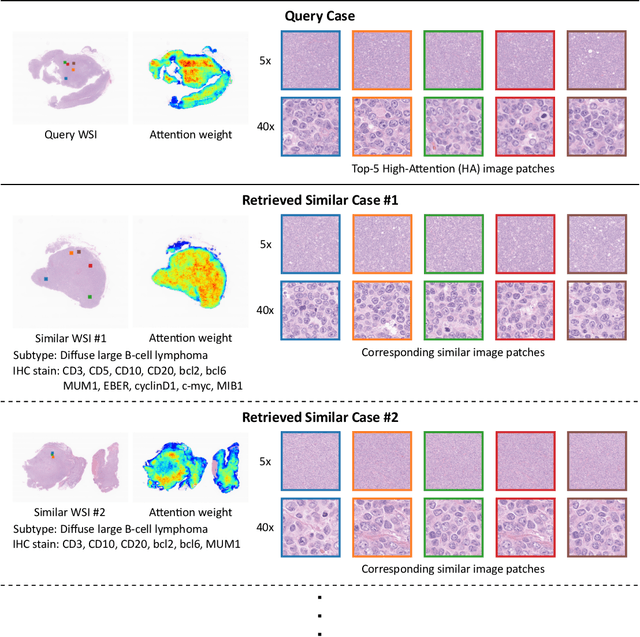
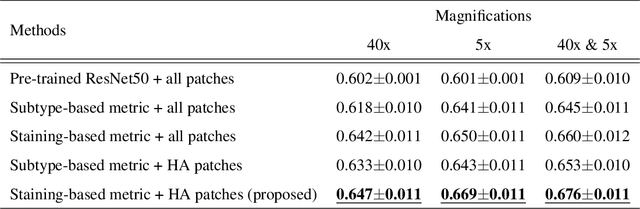
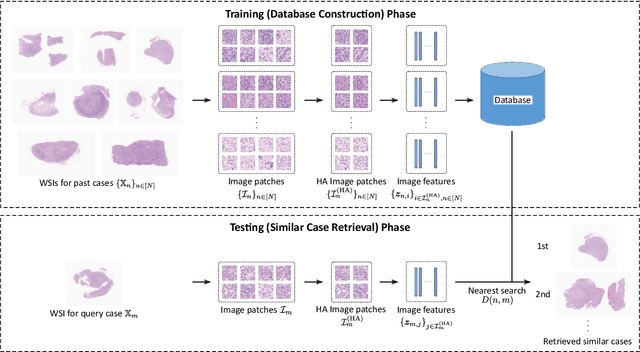
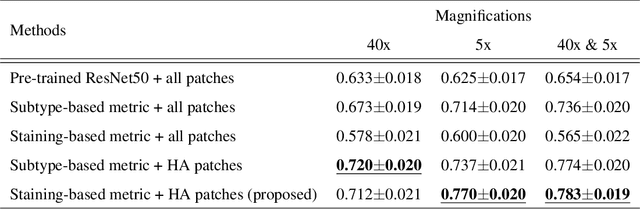
In the present study, we propose a novel case-based similar image retrieval (SIR) method for hematoxylin and eosin (H&E)-stained histopathological images of malignant lymphoma. When a whole slide image (WSI) is used as an input query, it is desirable to be able to retrieve similar cases by focusing on image patches in pathologically important regions such as tumor cells. To address this problem, we employ attention-based multiple instance learning, which enables us to focus on tumor-specific regions when the similarity between cases is computed. Moreover, we employ contrastive distance metric learning to incorporate immunohistochemical (IHC) staining patterns as useful supervised information for defining appropriate similarity between heterogeneous malignant lymphoma cases. In the experiment with 249 malignant lymphoma patients, we confirmed that the proposed method exhibited higher evaluation measures than the baseline case-based SIR methods. Furthermore, the subjective evaluation by pathologists revealed that our similarity measure using IHC staining patterns is appropriate for representing the similarity of H&E-stained tissue images for malignant lymphoma.