 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pre-Trained Image Processing Transformer
Dec 03, 2020
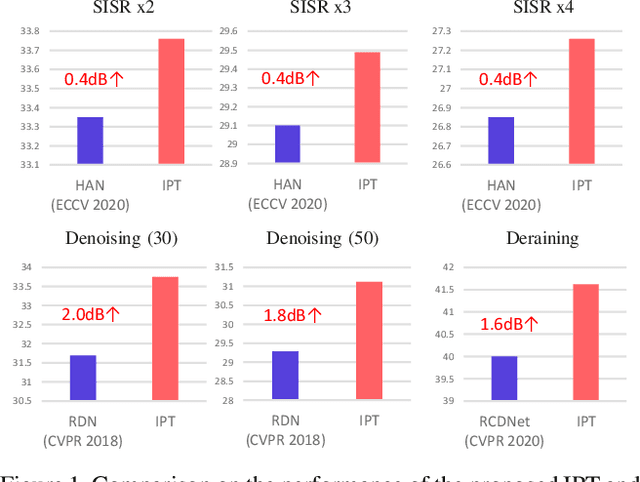

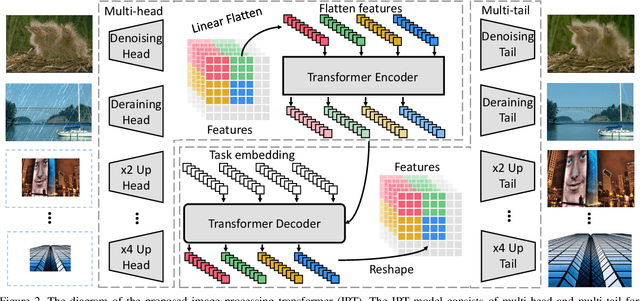
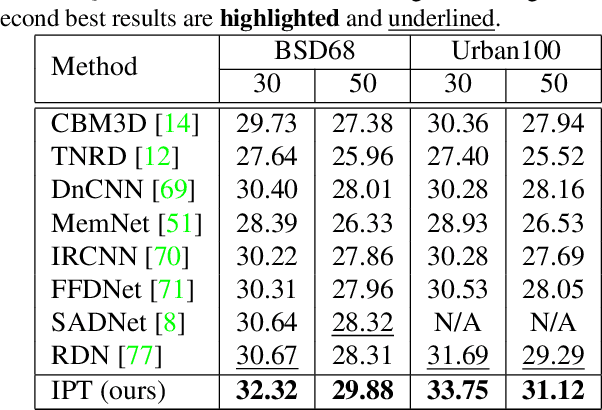
As the computing power of modern hardware is increasing strongly, pre-trained deep learning models (e.g., BERT, GPT-3) learned on large-scale datasets have shown their effectiveness over conventional methods. The big progress is mainly contributed to the representation ability of transformer and its variant architectures. In this paper, we study the low-level computer vision task (e.g., denoising, super-resolution and deraining) and develop a new pre-trained model, namely, image processing transformer (IPT). To maximally excavate the capability of transformer, we present to utilize the well-known ImageNet benchmark for generating a large amount of corrupted image pairs. The IPT model is trained on these images with multi-heads and multi-tails. In addition, the contrastive learning is introduced for well adapting to different image processing tasks. The pre-trained model can therefore efficiently employed on desired task after fine-tuning. With only one pre-trained model, IPT outperforms the current state-of-the-art methods on various low-level benchmarks.
Fast improvement of TEM image with low-dose electrons by deep learning
Jun 03, 2021
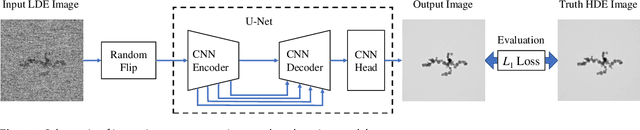
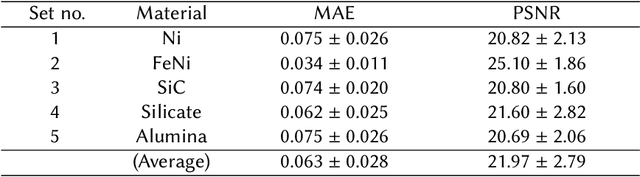
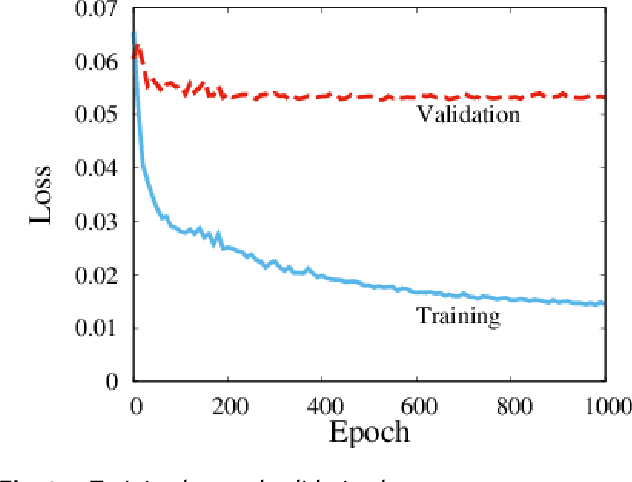
Low-electron-dose observation is indispensable for observing various samples using a transmission electron microscope; consequently, image processing has been used to improve transmission electron microscopy (TEM) images. To apply such image processing to in situ observations, we here apply a convolutional neural network to TEM imaging. Using a dataset that includes short-exposure images and long-exposure images, we develop a pipeline for processed short-exposure images, based on end-to-end training. The quality of images acquired with a total dose of approximately 5 e- per pixel becomes comparable to that of images acquired with a total dose of approximately 1000 e- per pixel. Because the conversion time is approximately 8 ms, in situ observation at 125 fps is possible. This imaging technique enables in situ observation of electron-beam-sensitive specimens.
PhD Thesis. Computer-Aided Assessment of Tuberculosis with Radiological Imaging: From rule-based methods to Deep Learning
May 31, 2022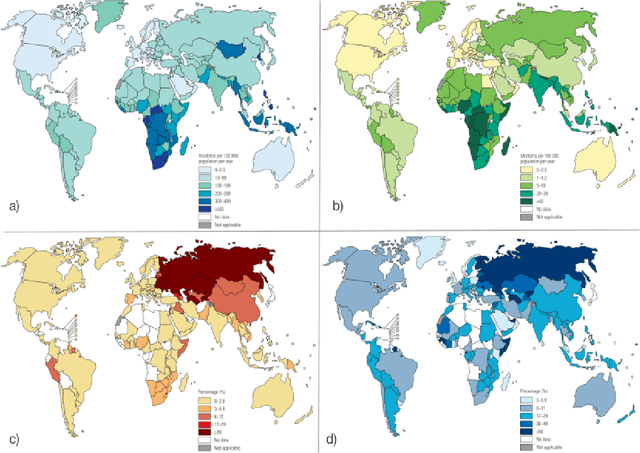
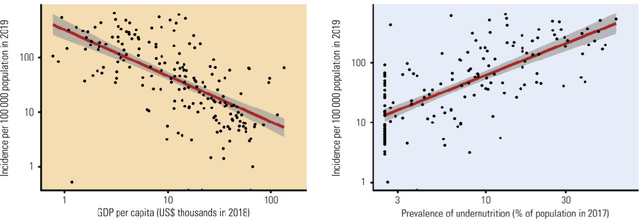
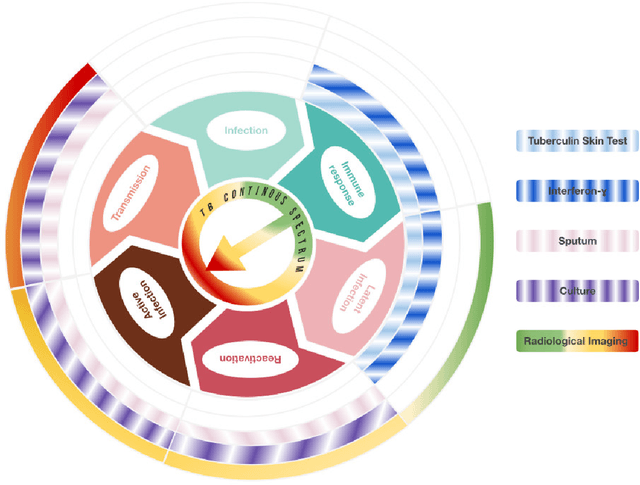
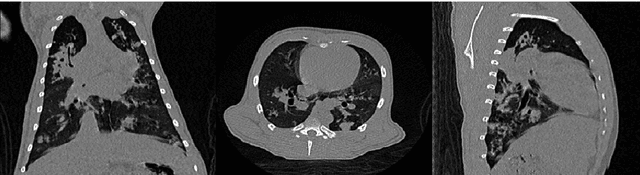
Tuberculosis (TB) is an infectious disease caused by Mycobacterium tuberculosis (Mtb.) that produces pulmonary damage due to its airborne nature. This fact facilitates the disease fast-spreading, which, according to the World Health Organization (WHO), in 2021 caused 1.2 million deaths and 9.9 million new cases. Fortunately, X-Ray Computed Tomography (CT) images enable capturing specific manifestations of TB that are undetectable using regular diagnostic tests. However, this procedure is unfeasible to process the thousands of volume images belonging to the different TB animal models and humans required for a suitable (pre-)clinical trial. To achieve suitable results, automatization of different image analysis processes is a must to quantify TB. Thus, in this thesis, we introduce a set of novel methods based on the state of the art Artificial Intelligence (AI) and Computer Vision (CV). Initially, we present an algorithm to assess Pathological Lung Segmentation (PLS). Next, a Gaussian Mixture Model ruled by an Expectation-Maximization (EM) algorithm is employed to automatically. Chapter 3 introduces a model to automate the identification of TB lesions and the characterization of disease progression. Chapter 4 extends the classification of TB lesions. Namely, we introduce a computational model to infer TB manifestations present in each lung lobe of CT scans by employing the associated radiologist reports as ground truth. In Chapter 5, we present a DL model capable of extracting disentangled information from images of different animal models, as well as information of the mechanisms that generate the CT volumes. To sum up, the thesis presents a collection of valuable tools to automate the quantification of pathological lungs. Chapter 6 elaborates on these conclusions.
Beyond Bounding Box: Multimodal Knowledge Learning for Object Detection
May 09, 2022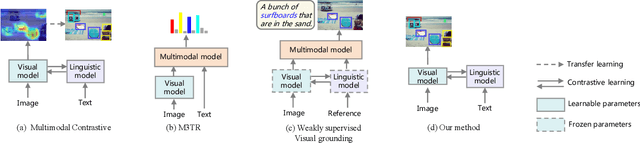
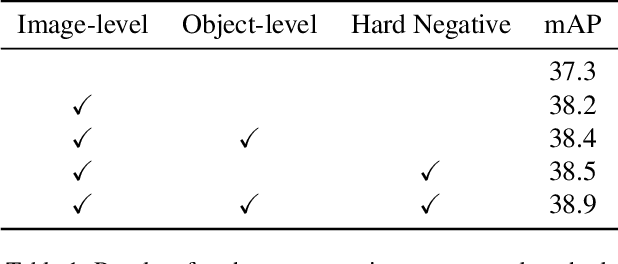
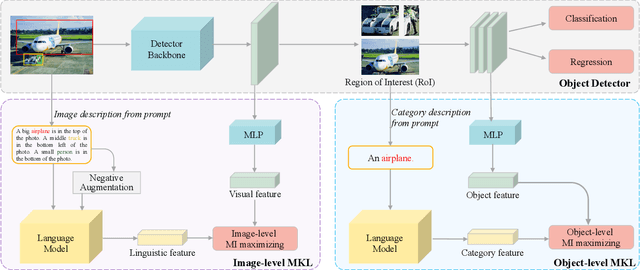
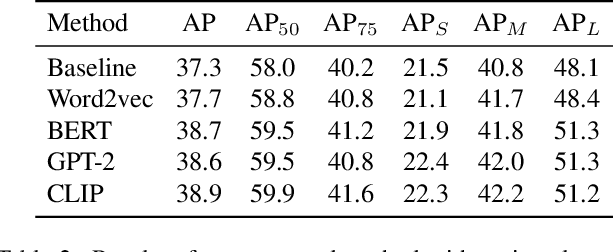
Multimodal supervision has achieved promising results in many visual language understanding tasks, where the language plays an essential role as a hint or context for recognizing and locating instances. However, due to the defects of the human-annotated language corpus, multimodal supervision remains unexplored in fully supervised object detection scenarios. In this paper, we take advantage of language prompt to introduce effective and unbiased linguistic supervision into object detection, and propose a new mechanism called multimodal knowledge learning (\textbf{MKL}), which is required to learn knowledge from language supervision. Specifically, we design prompts and fill them with the bounding box annotations to generate descriptions containing extensive hints and context for instances recognition and localization. The knowledge from language is then distilled into the detection model via maximizing cross-modal mutual information in both image- and object-level. Moreover, the generated descriptions are manipulated to produce hard negatives to further boost the detector performance. Extensive experiments demonstrate that the proposed method yields a consistent performance gain by 1.6\% $\sim$ 2.1\% and achieves state-of-the-art on MS-COCO and OpenImages datasets.
Efficient Deep Image Denoising via Class Specific Convolution
Mar 02, 2021


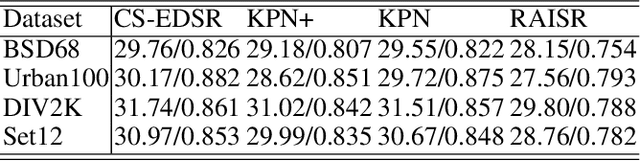
Deep neural networks have been widely used in image denoising during the past few years. Even though they achieve great success on this problem, they are computationally inefficient which makes them inappropriate to be implemented in mobile devices. In this paper, we propose an efficient deep neural network for image denoising based on pixel-wise classification. Despite using a computationally efficient network cannot effectively remove the noises from any content, it is still capable to denoise from a specific type of pattern or texture. The proposed method follows such a divide and conquer scheme. We first use an efficient U-net to pixel-wisely classify pixels in the noisy image based on the local gradient statistics. Then we replace part of the convolution layers in existing denoising networks by the proposed Class Specific Convolution layers (CSConv) which use different weights for different classes of pixels. Quantitative and qualitative evaluations on public datasets demonstrate that the proposed method can reduce the computational costs without sacrificing the performance compared to state-of-the-art algorithms.
LiDAR-guided Stereo Matching with a Spatial Consistency Constraint
Feb 21, 2022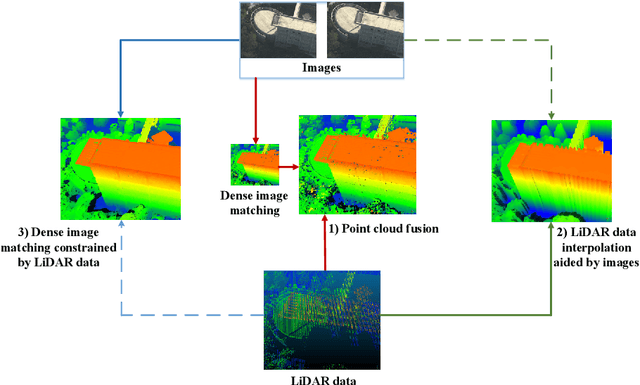
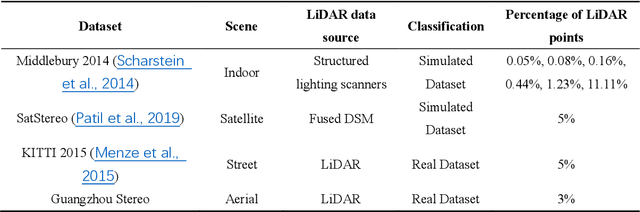
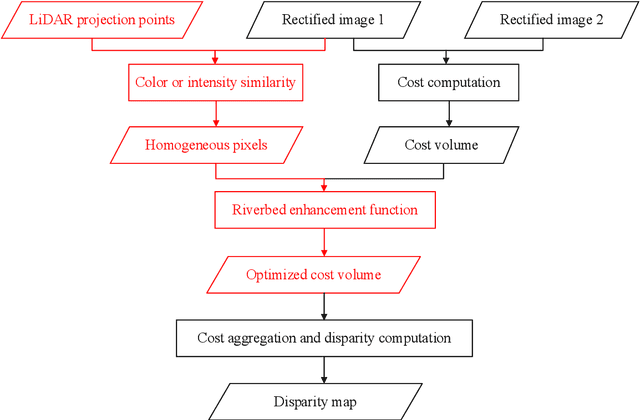
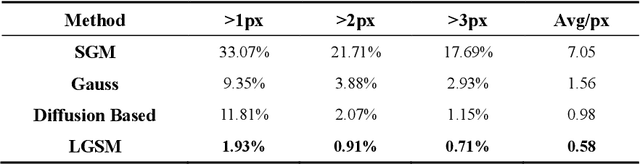
The complementary fusion of light detection and ranging (LiDAR) data and image data is a promising but challenging task for generating high-precision and high-density point clouds. This study proposes an innovative LiDAR-guided stereo matching approach called LiDAR-guided stereo matching (LGSM), which considers the spatial consistency represented by continuous disparity or depth changes in the homogeneous region of an image. The LGSM first detects the homogeneous pixels of each LiDAR projection point based on their color or intensity similarity. Next, we propose a riverbed enhancement function to optimize the cost volume of the LiDAR projection points and their homogeneous pixels to improve the matching robustness. Our formulation expands the constraint scopes of sparse LiDAR projection points with the guidance of image information to optimize the cost volume of pixels as much as possible. We applied LGSM to semi-global matching and AD-Census on both simulated and real datasets. When the percentage of LiDAR points in the simulated datasets was 0.16%, the matching accuracy of our method achieved a subpixel level, while that of the original stereo matching algorithm was 3.4 pixels. The experimental results show that LGSM is suitable for indoor, street, aerial, and satellite image datasets and provides good transferability across semi-global matching and AD-Census. Furthermore, the qualitative and quantitative evaluations demonstrate that LGSM is superior to two state-of-the-art optimizing cost volume methods, especially in reducing mismatches in difficult matching areas and refining the boundaries of objects.
Depth Estimation with Simplified Transformer
Apr 28, 2022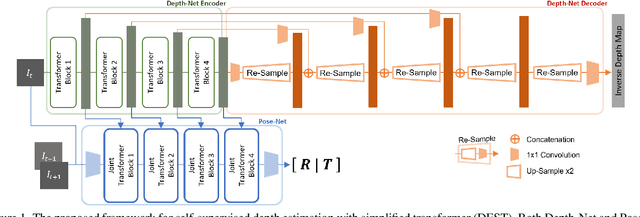
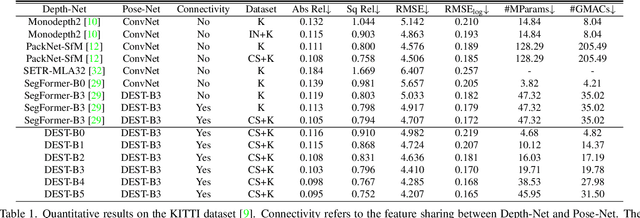
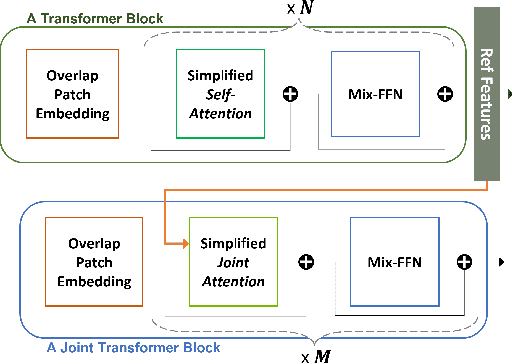
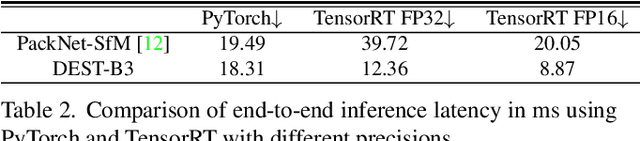
Transformer and its variants have shown state-of-the-art results in many vision tasks recently, ranging from image classification to dense prediction. Despite of their success, limited work has been reported on improving the model efficiency for deployment in latency-critical applications, such as autonomous driving and robotic navigation. In this paper, we aim at improving upon the existing transformers in vision, and propose a method for self-supervised monocular Depth Estimation with Simplified Transformer (DEST), which is efficient and particularly suitable for deployment on GPU-based platforms. Through strategic design choices, our model leads to significant reduction in model size, complexity, as well as inference latency, while achieving superior accuracy as compared to state-of-the-art. We also show that our design generalize well to other dense prediction task without bells and whistles.
Generating Embroidery Patterns Using Image-to-Image Translation
Mar 05, 2020
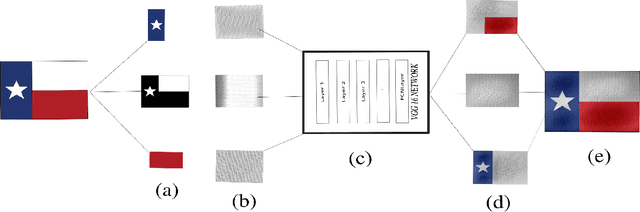

In many scenarios in computer vision, machine learning, and computer graphics, there is a requirement to learn the mapping from an image of one domain to an image of another domain, called Image-to-image translation. For example, style transfer, object transfiguration, visually altering the appearance of weather conditions in an image, changing the appearance of a day image into a night image or vice versa, photo enhancement, to name a few. In this paper, we propose two machine learning techniques to solve the embroidery image-to-image translation. Our goal is to generate a preview image which looks similar to an embroidered image, from a user-uploaded image. Our techniques are modifications of two existing techniques, neural style transfer, and cycle-consistent generative-adversarial network. Neural style transfer renders the semantic content of an image from one domain in the style of a different image in another domain, whereas a cycle-consistent generative adversarial network learns the mapping from an input image to output image without any paired training data, and also learn a loss function to train this mapping. Furthermore, the techniques we propose are independent of any embroidery attributes, such as elevation of the image, light-source, start, and endpoints of a stitch, type of stitch used, fabric type, etc. Given the user image, our techniques can generate a preview image which looks similar to an embroidered image. We train and test our propose techniques on an embroidery dataset which consist of simple 2D images. To do so, we prepare an unpaired embroidery dataset with more than 8000 user-uploaded images along with embroidered images. Empirical results show that these techniques successfully generate an approximate preview of an embroidered version of a user image, which can help users in decision making.
Remote Sensing Image Classification with the SEN12MS Dataset
Apr 01, 2021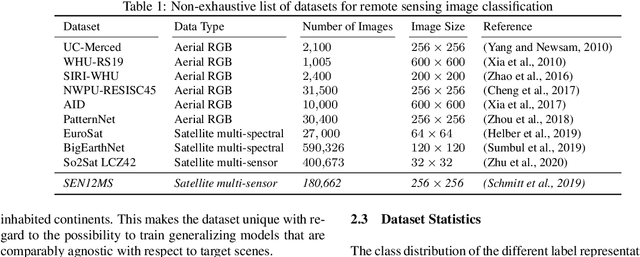
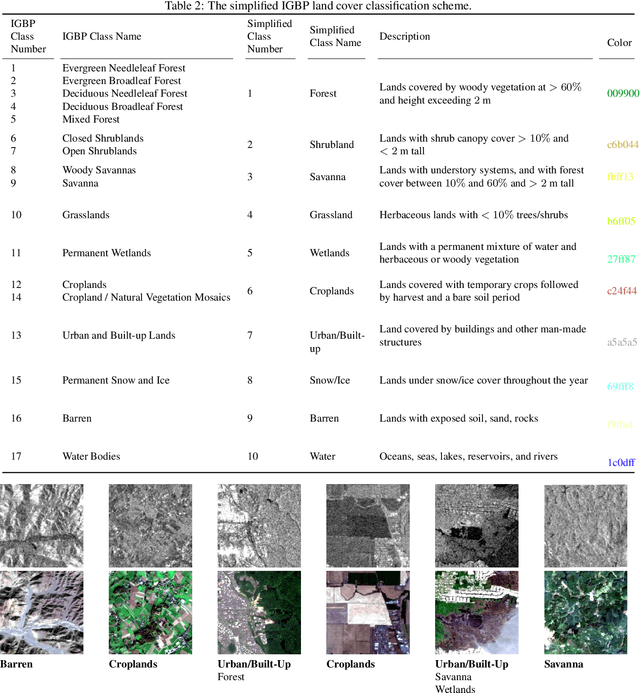
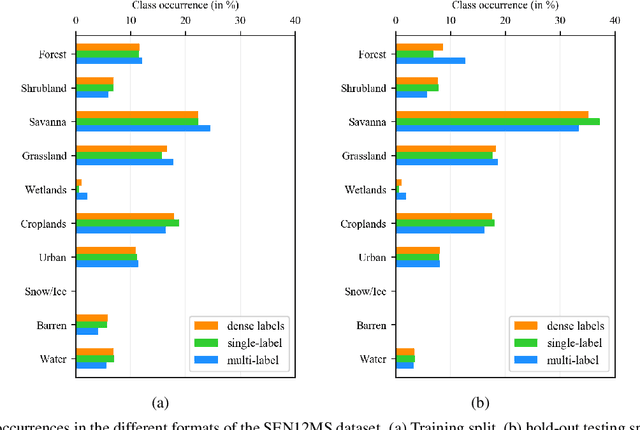
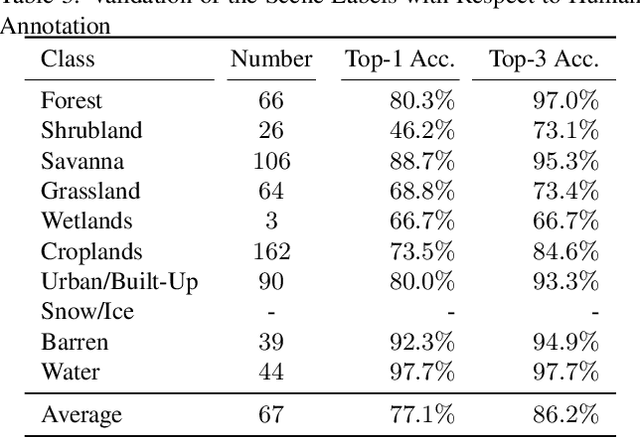
Image classification is one of the main drivers of the rapid developments in deep learning with convolutional neural networks for computer vision. So is the analogous task of scene classification in remote sensing. However, in contrast to the computer vision community that has long been using well-established, large-scale standard datasets to train and benchmark high-capacity models, the remote sensing community still largely relies on relatively small and often application-dependend datasets, thus lacking comparability. With this letter, we present a classification-oriented conversion of the SEN12MS dataset. Using that, we provide results for several baseline models based on two standard CNN architectures and different input data configurations. Our results support the benchmarking of remote sensing image classification and provide insights to the benefit of multi-spectral data and multi-sensor data fusion over conventional RGB imagery.
Medical Transformer: Gated Axial-Attention for Medical Image Segmentation
Feb 21, 2021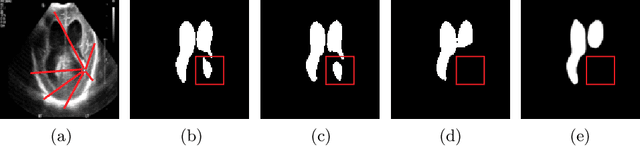
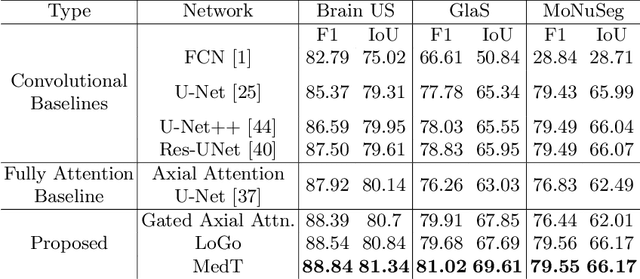
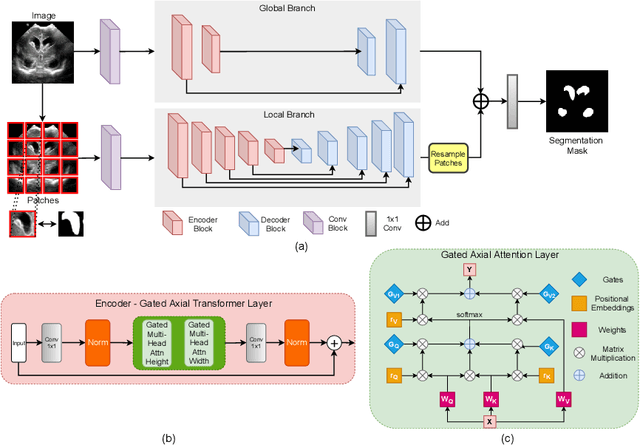

Over the past decade, Deep Convolutional Neural Networks have been widely adopted for medical image segmentation and shown to achieve adequate performance. However, due to the inherent inductive biases present in the convolutional architectures, they lack understanding of long-range dependencies in the image. Recently proposed Transformer-based architectures that leverage self-attention mechanism encode long-range dependencies and learn representations that are highly expressive. This motivates us to explore Transformer-based solutions and study the feasibility of using Transformer-based network architectures for medical image segmentation tasks. Majority of existing Transformer-based network architectures proposed for vision applications require large-scale datasets to train properly. However, compared to the datasets for vision applications, for medical imaging the number of data samples is relatively low, making it difficult to efficiently train transformers for medical applications. To this end, we propose a Gated Axial-Attention model which extends the existing architectures by introducing an additional control mechanism in the self-attention module. Furthermore, to train the model effectively on medical images, we propose a Local-Global training strategy (LoGo) which further improves the performance. Specifically, we operate on the whole image and patches to learn global and local features, respectively. The proposed Medical Transformer (MedT) is evaluated on three different medical image segmentation datasets and it is shown that it achieves better performance than the convolutional and other related transformer-based architectures. Code: https://github.com/jeya-maria-jose/Medical-Transformer