 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning refinement of in situ images acquired by low electron dose LC-TEM
Oct 31, 2023We study a machine learning (ML) technique for refining images acquired during in situ observation using liquid-cell transmission electron microscopy (LC-TEM). Our model is constructed using a U-Net architecture and a ResNet encoder. For training our ML model, we prepared an original image dataset that contained pairs of images of samples acquired with and without a solution present. The former images were used as noisy images and the latter images were used as corresponding ground truth images. The number of pairs of image sets was $1,204$ and the image sets included images acquired at several different magnifications and electron doses. The trained model converted a noisy image into a clear image. The time necessary for the conversion was on the order of 10ms, and we applied the model to in situ observations using the software Gatan DigitalMicrograph (DM). Even if a nanoparticle was not visible in a view window in the DM software because of the low electron dose, it was visible in a successive refined image generated by our ML model.
Fast improvement of TEM image with low-dose electrons by deep learning
Jun 03, 2021
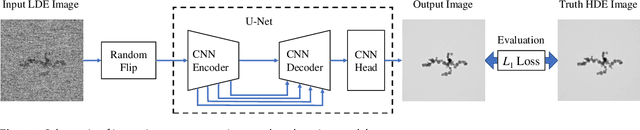
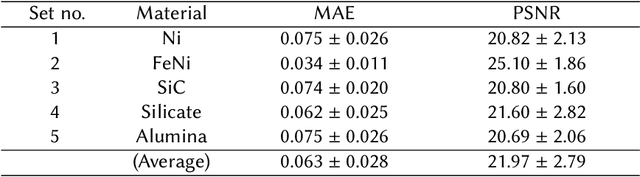
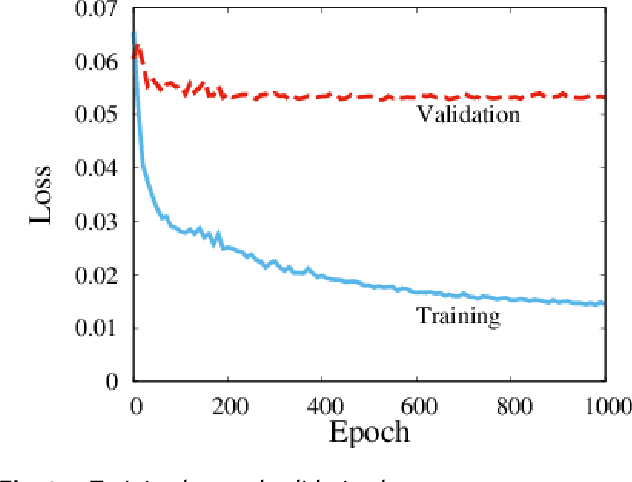
Low-electron-dose observation is indispensable for observing various samples using a transmission electron microscope; consequently, image processing has been used to improve transmission electron microscopy (TEM) images. To apply such image processing to in situ observations, we here apply a convolutional neural network to TEM imaging. Using a dataset that includes short-exposure images and long-exposure images, we develop a pipeline for processed short-exposure images, based on end-to-end training. The quality of images acquired with a total dose of approximately 5 e- per pixel becomes comparable to that of images acquired with a total dose of approximately 1000 e- per pixel. Because the conversion time is approximately 8 ms, in situ observation at 125 fps is possible. This imaging technique enables in situ observation of electron-beam-sensitive specimens.
Jointly learning relevant subgraph patterns and nonlinear models of their indicators
Jul 09, 2018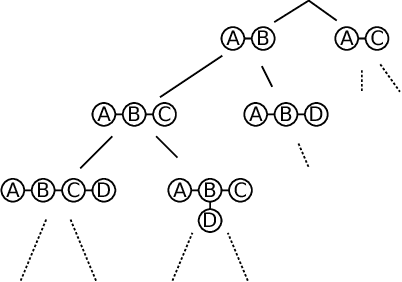



Classification and regression in which the inputs are graphs of arbitrary size and shape have been paid attention in various fields such as computational chemistry and bioinformatics. Subgraph indicators are often used as the most fundamental features, but the number of possible subgraph patterns are intractably large due to the combinatorial explosion. We propose a novel efficient algorithm to jointly learn relevant subgraph patterns and nonlinear models of their indicators. Previous methods for such joint learning of subgraph features and models are based on search for single best subgraph features with specific pruning and boosting procedures of adding their indicators one by one, which result in linear models of subgraph indicators. In contrast, the proposed approach is based on directly learning regression trees for graph inputs using a newly derived bound of the total sum of squares for data partitions by a given subgraph feature, and thus can learn nonlinear models through standard gradient boosting. An illustrative example we call the Graph-XOR problem to consider nonlinearity, numerical experiments with real datasets, and scalability comparisons to naive approaches using explicit pattern enumeration are also presented.
Sparse Learning over Infinite Subgraph Features
Mar 20, 2014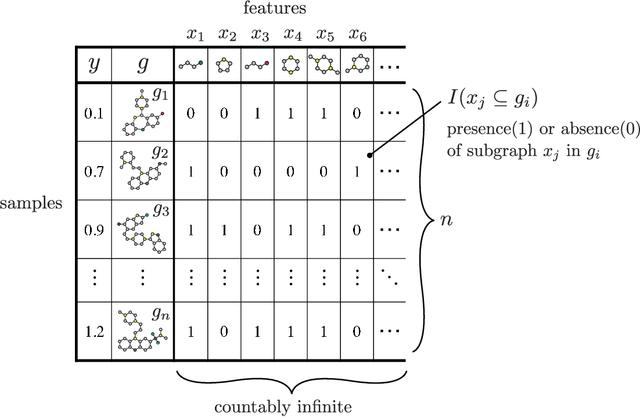
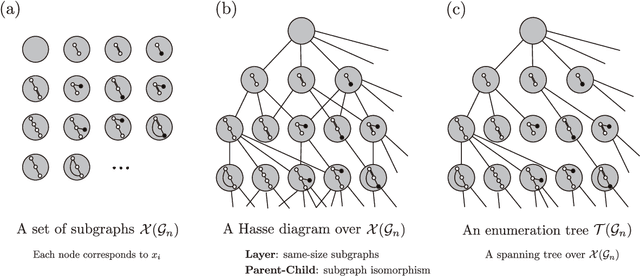
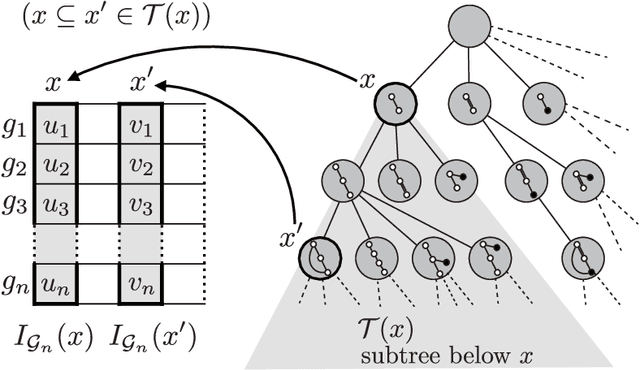
We present a supervised-learning algorithm from graph data (a set of graphs) for arbitrary twice-differentiable loss functions and sparse linear models over all possible subgraph features. To date, it has been shown that under all possible subgraph features, several types of sparse learning, such as Adaboost, LPBoost, LARS/LASSO, and sparse PLS regression, can be performed. Particularly emphasis is placed on simultaneous learning of relevant features from an infinite set of candidates. We first generalize techniques used in all these preceding studies to derive an unifying bounding technique for arbitrary separable functions. We then carefully use this bounding to make block coordinate gradient descent feasible over infinite subgraph features, resulting in a fast converging algorithm that can solve a wider class of sparse learning problems over graph data. We also empirically study the differences from the existing approaches in convergence property, selected subgraph features, and search-space sizes. We further discuss several unnoticed issues in sparse learning over all possible subgraph features.