 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTBStar-Edit: From Image Editing Pattern Shifting to Consistency Enhancement
Oct 06, 2025Recent advances in image generation and editing technologies have enabled state-of-the-art models to achieve impressive results in general domains. However, when applied to e-commerce scenarios, these general models often encounter consistency limitations. To address this challenge, we introduce TBStar-Edit, an new image editing model tailored for the e-commerce domain. Through rigorous data engineering, model architecture design and training strategy, TBStar-Edit achieves precise and high-fidelity image editing while maintaining the integrity of product appearance and layout. Specifically, for data engineering, we establish a comprehensive data construction pipeline, encompassing data collection, construction, filtering, and augmentation, to acquire high-quality, instruction-following, and strongly consistent editing data to support model training. For model architecture design, we design a hierarchical model framework consisting of a base model, pattern shifting modules, and consistency enhancement modules. For model training, we adopt a two-stage training strategy to enhance the consistency preservation: first stage for editing pattern shifting, and second stage for consistency enhancement. Each stage involves training different modules with separate datasets. Finally, we conduct extensive evaluations of TBStar-Edit on a self-proposed e-commerce benchmark, and the results demonstrate that TBStar-Edit outperforms existing general-domain editing models in both objective metrics (VIE Score) and subjective user preference.
DMM: Building a Versatile Image Generation Model via Distillation-Based Model Merging
Apr 16, 2025The success of text-to-image (T2I) generation models has spurred a proliferation of numerous model checkpoints fine-tuned from the same base model on various specialized datasets. This overwhelming specialized model production introduces new challenges for high parameter redundancy and huge storage cost, thereby necessitating the development of effective methods to consolidate and unify the capabilities of diverse powerful models into a single one. A common practice in model merging adopts static linear interpolation in the parameter space to achieve the goal of style mixing. However, it neglects the features of T2I generation task that numerous distinct models cover sundry styles which may lead to incompatibility and confusion in the merged model. To address this issue, we introduce a style-promptable image generation pipeline which can accurately generate arbitrary-style images under the control of style vectors. Based on this design, we propose the score distillation based model merging paradigm (DMM), compressing multiple models into a single versatile T2I model. Moreover, we rethink and reformulate the model merging task in the context of T2I generation, by presenting new merging goals and evaluation protocols. Our experiments demonstrate that DMM can compactly reorganize the knowledge from multiple teacher models and achieve controllable arbitrary-style generation.
Accelerating Image Generation with Sub-path Linear Approximation Model
Apr 23, 2024



Diffusion models have significantly advanced the state of the art in image, audio, and video generation tasks. However, their applications in practical scenarios are hindered by slow inference speed. Drawing inspiration from the approximation strategies utilized in consistency models, we propose the Sub-path Linear Approximation Model (SLAM), which accelerates diffusion models while maintaining high-quality image generation. SLAM treats the PF-ODE trajectory as a series of PF-ODE sub-paths divided by sampled points, and harnesses sub-path linear (SL) ODEs to form a progressive and continuous error estimation along each individual PF-ODE sub-path. The optimization on such SL-ODEs allows SLAM to construct denoising mappings with smaller cumulative approximated errors. An efficient distillation method is also developed to facilitate the incorporation of more advanced diffusion models, such as latent diffusion models. Our extensive experimental results demonstrate that SLAM achieves an efficient training regimen, requiring only 6 A100 GPU days to produce a high-quality generative model capable of 2 to 4-step generation with high performance. Comprehensive evaluations on LAION, MS COCO 2014, and MS COCO 2017 datasets also illustrate that SLAM surpasses existing acceleration methods in few-step generation tasks, achieving state-of-the-art performance both on FID and the quality of the generated images.
Beyond Bounding Box: Multimodal Knowledge Learning for Object Detection
May 09, 2022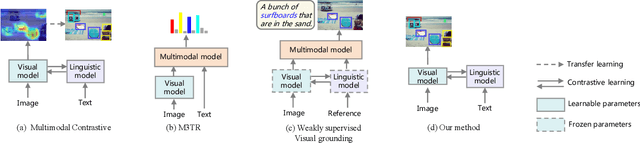
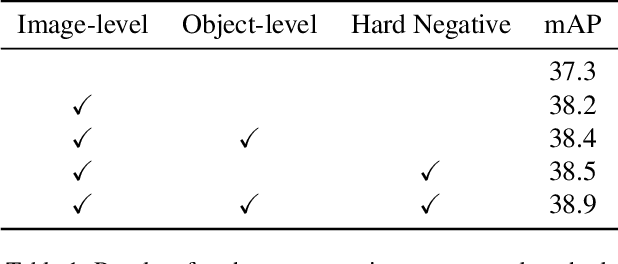
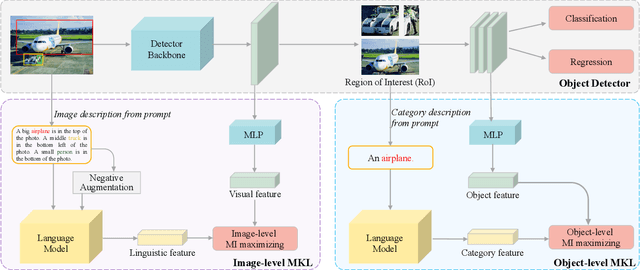
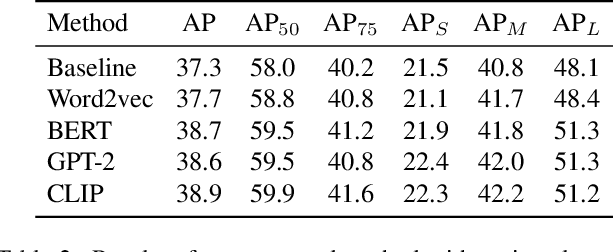
Multimodal supervision has achieved promising results in many visual language understanding tasks, where the language plays an essential role as a hint or context for recognizing and locating instances. However, due to the defects of the human-annotated language corpus, multimodal supervision remains unexplored in fully supervised object detection scenarios. In this paper, we take advantage of language prompt to introduce effective and unbiased linguistic supervision into object detection, and propose a new mechanism called multimodal knowledge learning (\textbf{MKL}), which is required to learn knowledge from language supervision. Specifically, we design prompts and fill them with the bounding box annotations to generate descriptions containing extensive hints and context for instances recognition and localization. The knowledge from language is then distilled into the detection model via maximizing cross-modal mutual information in both image- and object-level. Moreover, the generated descriptions are manipulated to produce hard negatives to further boost the detector performance. Extensive experiments demonstrate that the proposed method yields a consistent performance gain by 1.6\% $\sim$ 2.1\% and achieves state-of-the-art on MS-COCO and OpenImages datasets.
Temporal Knowledge Consistency for Unsupervised Visual Representation Learning
Aug 24, 2021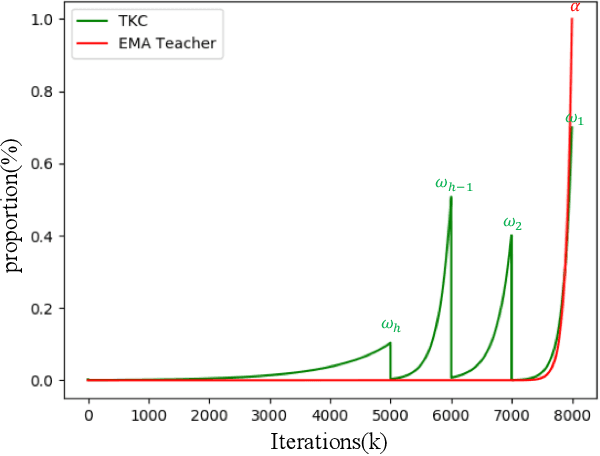
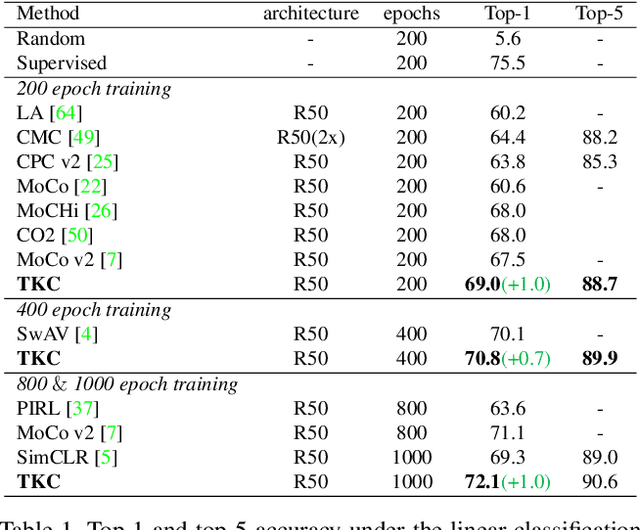
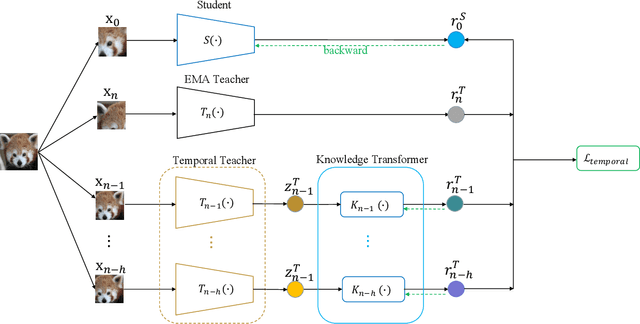

The instance discrimination paradigm has become dominant in unsupervised learning. It always adopts a teacher-student framework, in which the teacher provides embedded knowledge as a supervision signal for the student. The student learns meaningful representations by enforcing instance spatial consistency with the views from the teacher. However, the outputs of the teacher can vary dramatically on the same instance during different training stages, introducing unexpected noise and leading to catastrophic forgetting caused by inconsistent objectives. In this paper, we first integrate instance temporal consistency into current instance discrimination paradigms, and propose a novel and strong algorithm named Temporal Knowledge Consistency (TKC). Specifically, our TKC dynamically ensembles the knowledge of temporal teachers and adaptively selects useful information according to its importance to learning instance temporal consistency. Experimental result shows that TKC can learn better visual representations on both ResNet and AlexNet on linear evaluation protocol while transfer well to downstream tasks. All experiments suggest the good effectiveness and generalization of our method.
* To appear in ICCV 2021