 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Remote Sensing Super-Resolution via Migration Image Prior
May 08, 2021
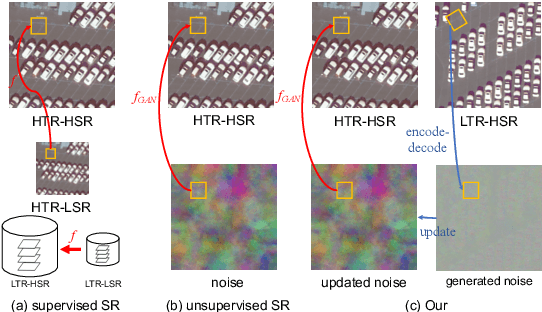
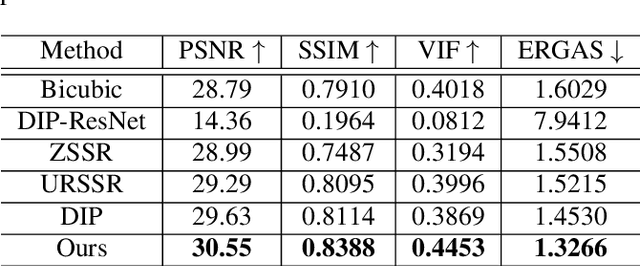
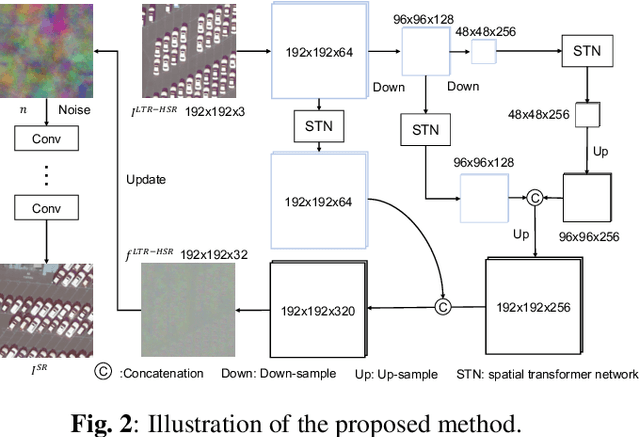
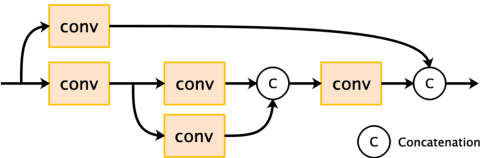
Recently, satellites with high temporal resolution have fostered wide attention in various practical applications. Due to limitations of bandwidth and hardware cost, however, the spatial resolution of such satellites is considerably low, largely limiting their potentials in scenarios that require spatially explicit information. To improve image resolution, numerous approaches based on training low-high resolution pairs have been proposed to address the super-resolution (SR) task. Despite their success, however, low/high spatial resolution pairs are usually difficult to obtain in satellites with a high temporal resolution, making such approaches in SR impractical to use. In this paper, we proposed a new unsupervised learning framework, called "MIP", which achieves SR tasks without low/high resolution image pairs. First, random noise maps are fed into a designed generative adversarial network (GAN) for reconstruction. Then, the proposed method converts the reference image to latent space as the migration image prior. Finally, we update the input noise via an implicit method, and further transfer the texture and structured information from the reference image. Extensive experimental results on the Draper dataset show that MIP achieves significant improvements over state-of-the-art methods both quantitatively and qualitatively. The proposed MIP is open-sourced at http://github.com/jiaming-wang/MIP.
RNNPose: Recurrent 6-DoF Object Pose Refinement with Robust Correspondence Field Estimation and Pose Optimization
Apr 10, 2022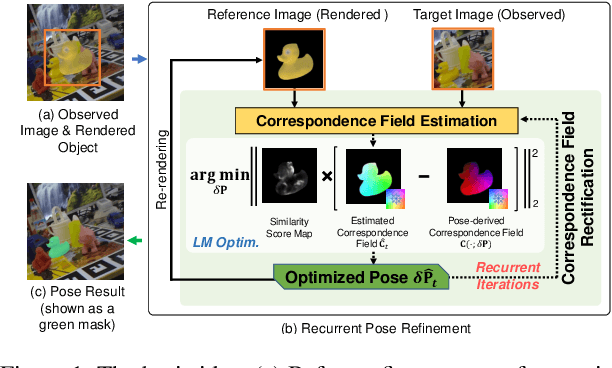
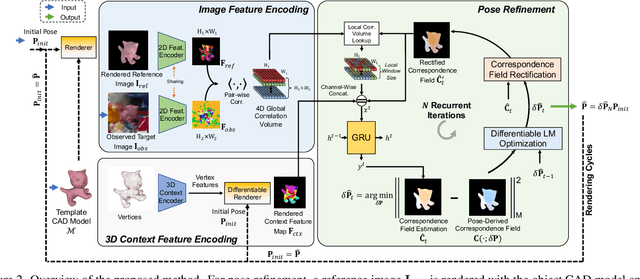
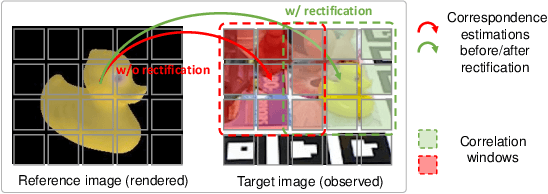
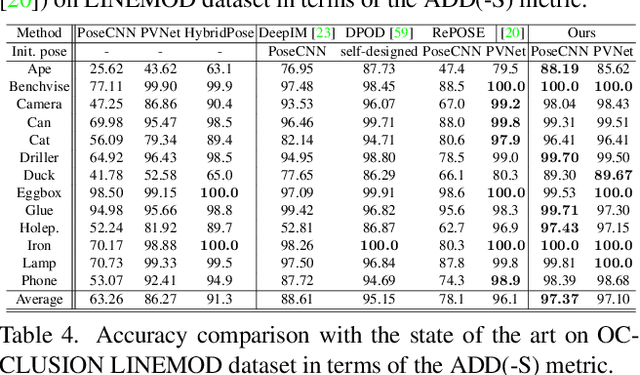
6-DoF object pose estimation from a monocular image is challenging, and a post-refinement procedure is generally needed for high-precision estimation. In this paper, we propose a framework based on a recurrent neural network (RNN) for object pose refinement, which is robust to erroneous initial poses and occlusions. During the recurrent iterations, object pose refinement is formulated as a non-linear least squares problem based on the estimated correspondence field (between a rendered image and the observed image). The problem is then solved by a differentiable Levenberg-Marquardt (LM) algorithm enabling end-to-end training. The correspondence field estimation and pose refinement are conducted alternatively in each iteration to recover the object poses. Furthermore, to improve the robustness to occlusion, we introduce a consistency-check mechanism based on the learned descriptors of the 3D model and observed 2D images, which downweights the unreliable correspondences during pose optimization. Extensive experiments on LINEMOD, Occlusion-LINEMOD, and YCB-Video datasets validate the effectiveness of our method and demonstrate state-of-the-art performance.
Linear Revolution-Invariance: Modeling and Deblurring Spatially-Varying Imaging Systems
Jun 17, 2022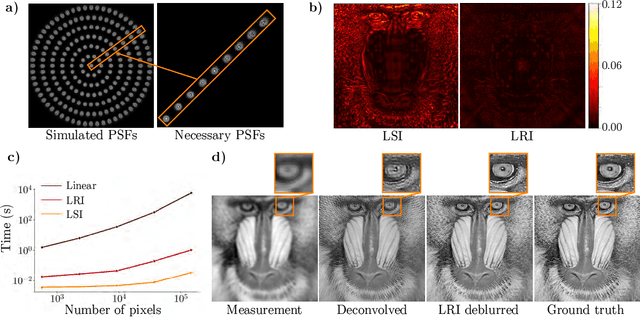
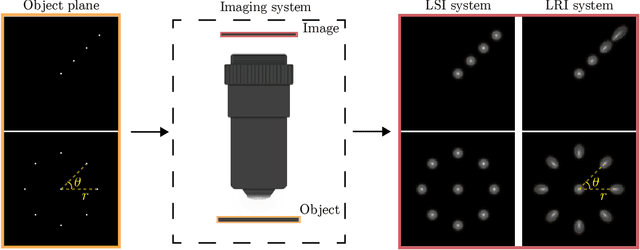
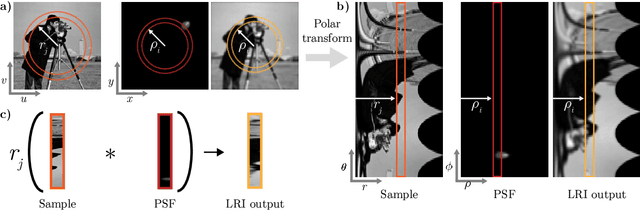
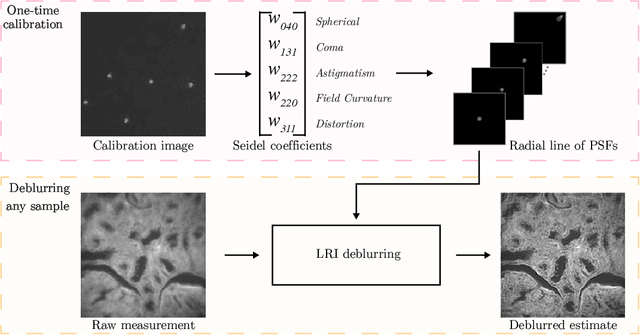
We develop theory and algorithms for modeling and deblurring imaging systems that are composed of rotationally-symmetric optics. Such systems have point spread functions (PSFs) which are spatially-varying, but only vary radially, a property we call linear revolution-invariance (LRI). From the LRI property we develop an exact theory for linear imaging with radially-varying optics, including an analog of the Fourier Convolution Theorem. This theory, in tandem with a calibration procedure using Seidel aberration coefficients, yields an efficient forward model and deblurring algorithm which requires only a single calibration image -- one that is easier to measure than a single PSF. We test these methods in simulation and experimentally on images of resolution targets, rabbit liver tissue, and live tardigrades obtained using the UCLA Miniscope v3. We find that the LRI forward model generates accurate radially-varying blur, and LRI deblurring improves resolution, especially near the edges of the field-of-view. These methods are available for use as a Python package at https://github.com/apsk14/lri.
PSO-Convolutional Neural Networks with Heterogeneous Learning Rate
May 20, 2022
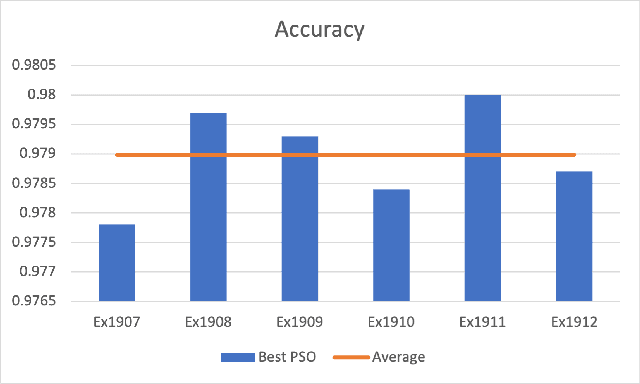
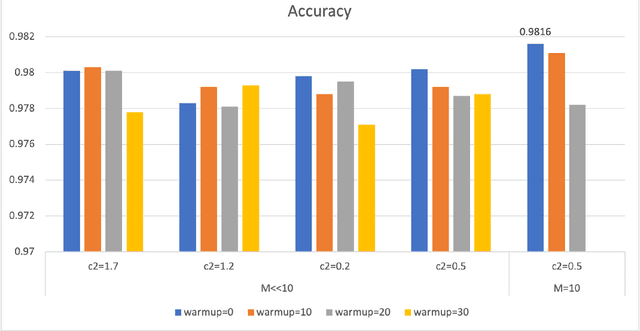
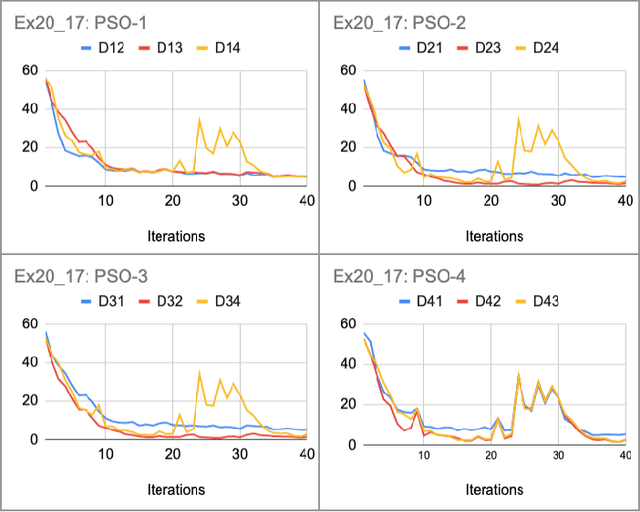
Convolutional Neural Networks (ConvNets) have been candidly deployed in the scope of computer vision and related fields. Nevertheless, the dynamics of training of these neural networks lie still elusive: it is hard and computationally expensive to train them. A myriad of architectures and training strategies have been proposed to overcome this challenge and address several problems in image processing such as speech, image and action recognition as well as object detection. In this article, we propose a novel Particle Swarm Optimization (PSO) based training for ConvNets. In such framework, the vector of weights of each ConvNet is typically cast as the position of a particle in phase space whereby PSO collaborative dynamics intertwines with Stochastic Gradient Descent (SGD) in order to boost training performance and generalization. Our approach goes as follows: i) [warm-up phase] each ConvNet is trained independently via SGD; ii) [collaborative phase] ConvNets share among themselves their current vector of weights (or particle-position) along with their gradient estimates of the Loss function. Distinct step sizes are coined by distinct ConvNets. By properly blending ConvNets with large (possibly random) step-sizes along with more conservative ones, we propose an algorithm with competitive performance with respect to other PSO-based approaches on Cifar-10 (accuracy of 98.31%). These accuracy levels are obtained by resorting to only four ConvNets -- such results are expected to scale with the number of collaborative ConvNets accordingly. We make our source codes available for download https://github.com/leonlha/PSO-ConvNet-Dynamics.
Image Collation: Matching illustrations in manuscripts
Aug 18, 2021
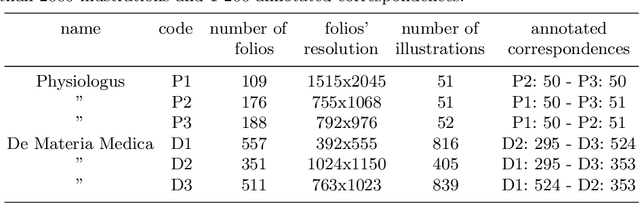


Illustrations are an essential transmission instrument. For an historian, the first step in studying their evolution in a corpus of similar manuscripts is to identify which ones correspond to each other. This image collation task is daunting for manuscripts separated by many lost copies, spreading over centuries, which might have been completely re-organized and greatly modified to adapt to novel knowledge or belief and include hundreds of illustrations. Our contributions in this paper are threefold. First, we introduce the task of illustration collation and a large annotated public dataset to evaluate solutions, including 6 manuscripts of 2 different texts with more than 2 000 illustrations and 1 200 annotated correspondences. Second, we analyze state of the art similarity measures for this task and show that they succeed in simple cases but struggle for large manuscripts when the illustrations have undergone very significant changes and are discriminated only by fine details. Finally, we show clear evidence that significant performance boosts can be expected by exploiting cycle-consistent correspondences. Our code and data are available on http://imagine.enpc.fr/~shenx/ImageCollation.
Articulated Objects in Free-form Hand Interaction
Apr 28, 2022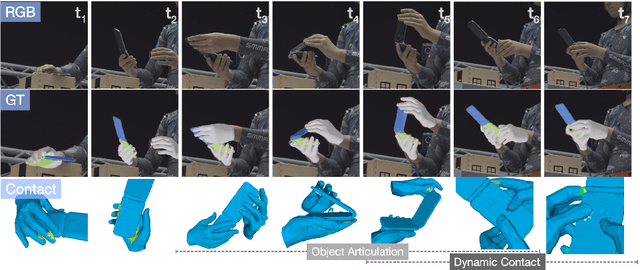

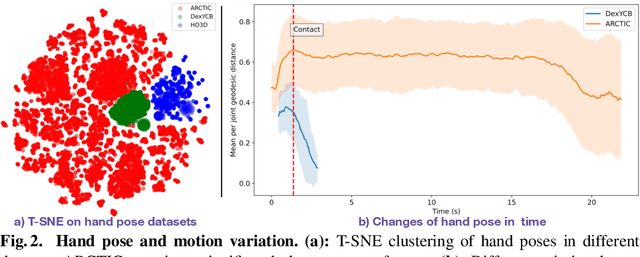
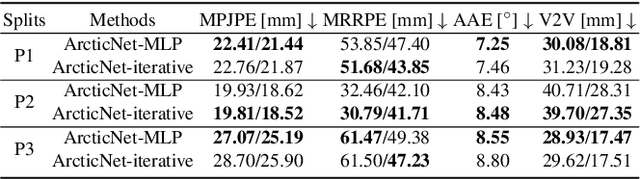
We use our hands to interact with and to manipulate objects. Articulated objects are especially interesting since they often require the full dexterity of human hands to manipulate them. To understand, model, and synthesize such interactions, automatic and robust methods that reconstruct hands and articulated objects in 3D from a color image are needed. Existing methods for estimating 3D hand and object pose from images focus on rigid objects. In part, because such methods rely on training data and no dataset of articulated object manipulation exists. Consequently, we introduce ARCTIC - the first dataset of free-form interactions of hands and articulated objects. ARCTIC has 1.2M images paired with accurate 3D meshes for both hands and for objects that move and deform over time. The dataset also provides hand-object contact information. To show the value of our dataset, we perform two novel tasks on ARCTIC: (1) 3D reconstruction of two hands and an articulated object in interaction; (2) an estimation of dense hand-object relative distances, which we call interaction field estimation. For the first task, we present ArcticNet, a baseline method for the task of jointly reconstructing two hands and an articulated object from an RGB image. For interaction field estimation, we predict the relative distances from each hand vertex to the object surface, and vice versa. We introduce InterField, the first method that estimates such distances from a single RGB image. We provide qualitative and quantitative experiments for both tasks, and provide detailed analysis on the data. Code and data will be available at https://arctic.is.tue.mpg.de.
Towards a Design Framework for TNN-Based Neuromorphic Sensory Processing Units
May 27, 2022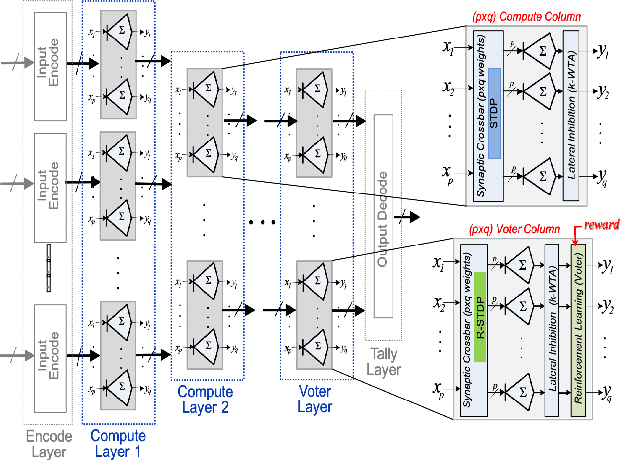
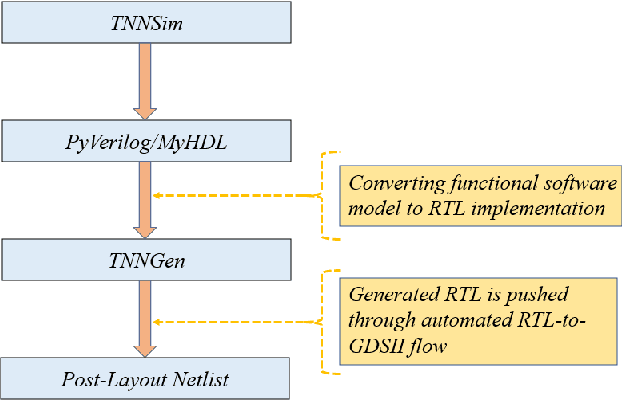
Temporal Neural Networks (TNNs) are spiking neural networks that exhibit brain-like sensory processing with high energy efficiency. This work presents the ongoing research towards developing a custom design framework for designing efficient application-specific TNN-based Neuromorphic Sensory Processing Units (NSPUs). This paper examines previous works on NSPU designs for UCR time-series clustering and MNIST image classification applications. Current ideas for a custom design framework and tools that enable efficient software-to-hardware design flow for rapid design space exploration of application-specific NSPUs while leveraging EDA tools to obtain post-layout netlist and power-performance-area (PPA) metrics are described. Future research directions are also outlined.
Spectral-Spatial Graph Reasoning Network for Hyperspectral Image Classification
Jun 26, 2021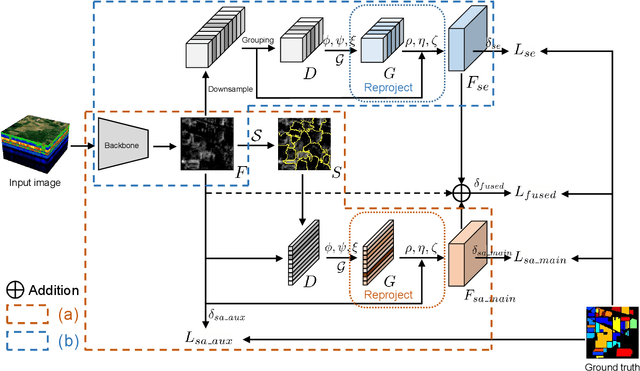


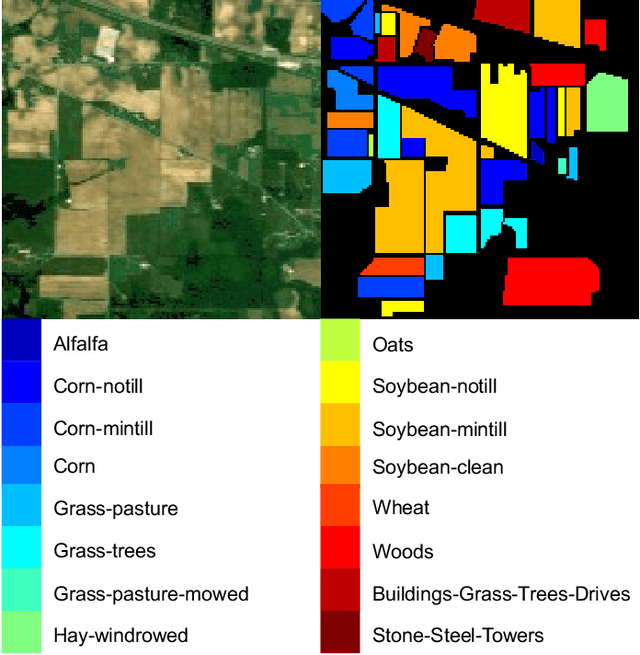
In this paper, we propose a spectral-spatial graph reasoning network (SSGRN) for hyperspectral image (HSI) classification. Concretely, this network contains two parts that separately named spatial graph reasoning subnetwork (SAGRN) and spectral graph reasoning subnetwork (SEGRN) to capture the spatial and spectral graph contexts, respectively. Different from the previous approaches implementing superpixel segmentation on the original image or attempting to obtain the category features under the guide of label image, we perform the superpixel segmentation on intermediate features of the network to adaptively produce the homogeneous regions to get the effective descriptors. Then, we adopt a similar idea in spectral part that reasonably aggregating the channels to generate spectral descriptors for spectral graph contexts capturing. All graph reasoning procedures in SAGRN and SEGRN are achieved through graph convolution. To guarantee the global perception ability of the proposed methods, all adjacent matrices in graph reasoning are obtained with the help of non-local self-attention mechanism. At last, by combining the extracted spatial and spectral graph contexts, we obtain the SSGRN to achieve a high accuracy classification. Extensive quantitative and qualitative experiments on three public HSI benchmarks demonstrate the competitiveness of the proposed methods compared with other state-of-the-art approaches.
Retinal-inspired Filtering for Dynamic Image Coding
Mar 22, 2021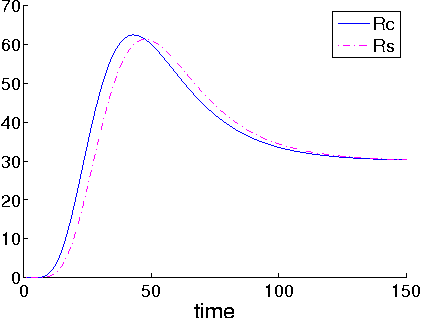


This paper introduces a novel non-Separable sPAtioteMporal filter (non-SPAM) which enables the spatiotemporal decomposition of a still-image. The construction of this filter is inspired by the model of the retina which is able to selectively transmit information to the brain. The non-SPAM filter mimics the retinal-way to extract necessary information for a dynamic encoding/decoding system. We applied the non-SPAM filter on a still image which is flashed for a long time. We prove that the non-SPAM filter decomposes the still image over a set of time-varying difference of Gaussians, which form a frame. We simulate the analysis and synthesis system based on this frame. This system results in a progressive reconstruction of the input image. Both the theoretical and numerical results show that the quality of the reconstruction improves while the time increases.
S3Net: A Single Stream Structure for Depth Guided Image Relighting
May 05, 2021

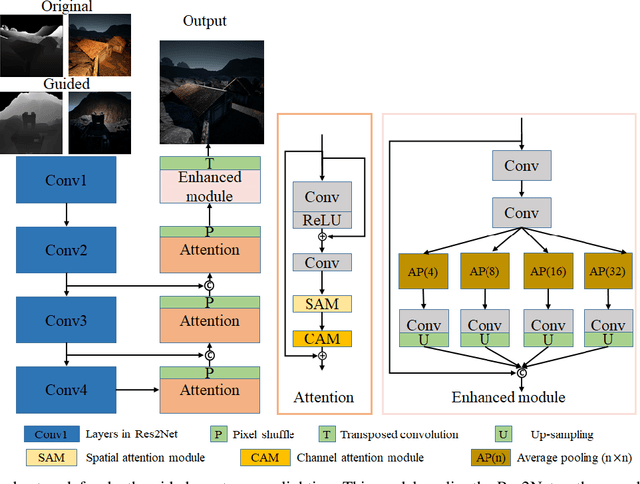
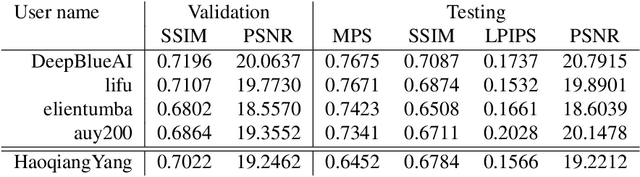
Depth guided any-to-any image relighting aims to generate a relit image from the original image and corresponding depth maps to match the illumination setting of the given guided image and its depth map. To the best of our knowledge, this task is a new challenge that has not been addressed in the previous literature. To address this issue, we propose a deep learning-based neural Single Stream Structure network called S3Net for depth guided image relighting. This network is an encoder-decoder model. We concatenate all images and corresponding depth maps as the input and feed them into the model. The decoder part contains the attention module and the enhanced module to focus on the relighting-related regions in the guided images. Experiments performed on challenging benchmark show that the proposed model achieves the 3 rd highest SSIM in the NTIRE 2021 Depth Guided Any-to-any Relighting Challenge.