 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Collation: Matching illustrations in manuscripts
Paper and Code
Aug 18, 2021
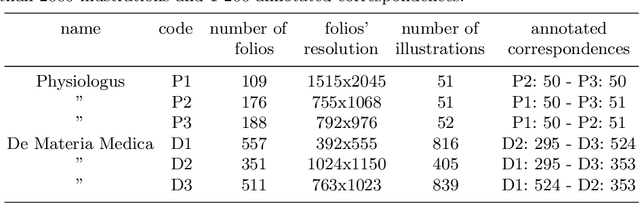


Illustrations are an essential transmission instrument. For an historian, the first step in studying their evolution in a corpus of similar manuscripts is to identify which ones correspond to each other. This image collation task is daunting for manuscripts separated by many lost copies, spreading over centuries, which might have been completely re-organized and greatly modified to adapt to novel knowledge or belief and include hundreds of illustrations. Our contributions in this paper are threefold. First, we introduce the task of illustration collation and a large annotated public dataset to evaluate solutions, including 6 manuscripts of 2 different texts with more than 2 000 illustrations and 1 200 annotated correspondences. Second, we analyze state of the art similarity measures for this task and show that they succeed in simple cases but struggle for large manuscripts when the illustrations have undergone very significant changes and are discriminated only by fine details. Finally, we show clear evidence that significant performance boosts can be expected by exploiting cycle-consistent correspondences. Our code and data are available on http://imagine.enpc.fr/~shenx/ImageCollation.