 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Personalized Showcases: Generating Multi-Modal Explanations for Recommendations
Jun 30, 2022
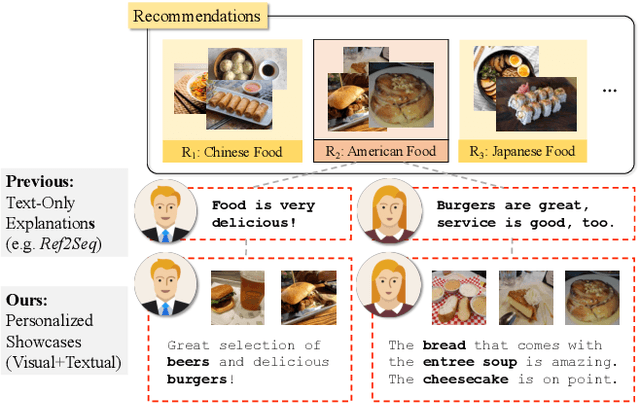
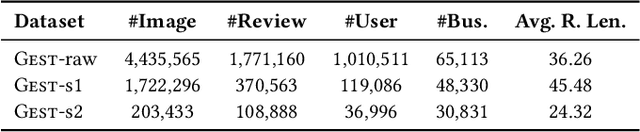

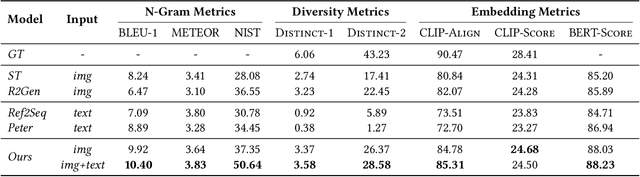
Existing explanation models generate only text for recommendations but still struggle to produce diverse contents. In this paper, to further enrich explanations, we propose a new task named personalized showcases, in which we provide both textual and visual information to explain our recommendations. Specifically, we first select a personalized image set that is the most relevant to a user's interest toward a recommended item. Then, natural language explanations are generated accordingly given our selected images. For this new task, we collect a large-scale dataset from Google Local (i.e.,~maps) and construct a high-quality subset for generating multi-modal explanations. We propose a personalized multi-modal framework which can generate diverse and visually-aligned explanations via contrastive learning. Experiments show that our framework benefits from different modalities as inputs, and is able to produce more diverse and expressive explanations compared to previous methods on a variety of evaluation metrics.
Contrastive Semi-Supervised Learning for 2D Medical Image Segmentation
Jul 10, 2021



Contrastive Learning (CL) is a recent representation learning approach, which encourages inter-class separability and intra-class compactness in learned image representations. Since medical images often contain multiple semantic classes in an image, using CL to learn representations of local features (as opposed to global) is important. In this work, we present a novel semi-supervised 2D medical segmentation solution that applies CL on image patches, instead of full images. These patches are meaningfully constructed using the semantic information of different classes obtained via pseudo labeling. We also propose a novel consistency regularization (CR) scheme, which works in synergy with CL. It addresses the problem of confirmation bias, and encourages better clustering in the feature space. We evaluate our method on four public medical segmentation datasets and a novel histopathology dataset that we introduce. Our method obtains consistent improvements over state-of-the-art semi-supervised segmentation approaches for all datasets.
GeoCLR: Georeference Contrastive Learning for Efficient Seafloor Image Interpretation
Aug 13, 2021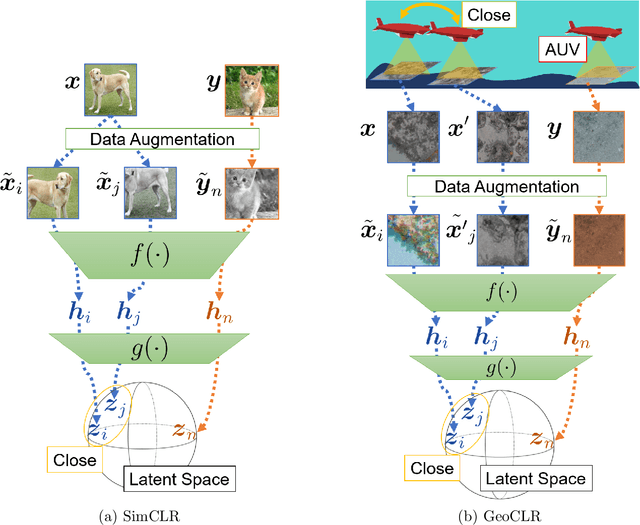
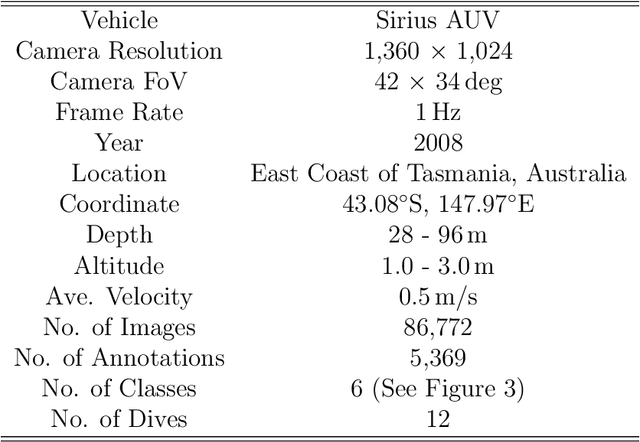
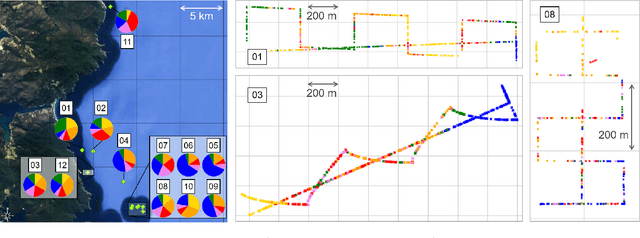
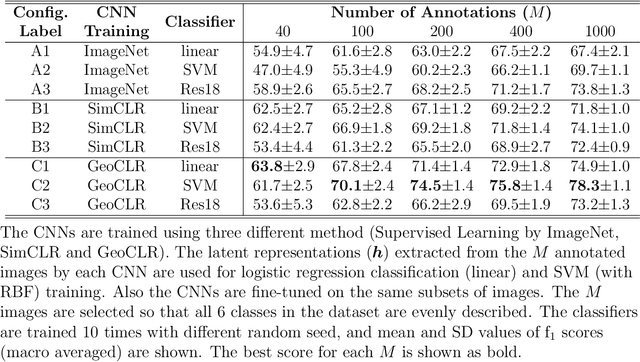
This paper describes Georeference Contrastive Learning of visual Representation (GeoCLR) for efficient training of deep-learning Convolutional Neural Networks (CNNs). The method leverages georeference information by generating a similar image pair using images taken of nearby locations, and contrasting these with an image pair that is far apart. The underlying assumption is that images gathered within a close distance are more likely to have similar visual appearance, where this can be reasonably satisfied in seafloor robotic imaging applications where image footprints are limited to edge lengths of a few metres and are taken so that they overlap along a vehicle's trajectory, whereas seafloor substrates and habitats have patch sizes that are far larger. A key advantage of this method is that it is self-supervised and does not require any human input for CNN training. The method is computationally efficient, where results can be generated between dives during multi-day AUV missions using computational resources that would be accessible during most oceanic field trials. We apply GeoCLR to habitat classification on a dataset that consists of ~86k images gathered using an Autonomous Underwater Vehicle (AUV). We demonstrate how the latent representations generated by GeoCLR can be used to efficiently guide human annotation efforts, where the semi-supervised framework improves classification accuracy by an average of 11.8 % compared to state-of-the-art transfer learning using the same CNN and equivalent number of human annotations for training.
Online Deep Equilibrium Learning for Regularization by Denoising
May 25, 2022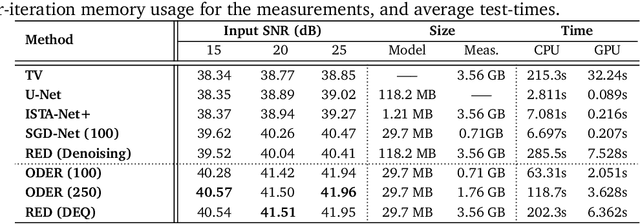
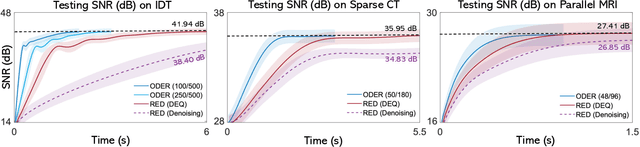
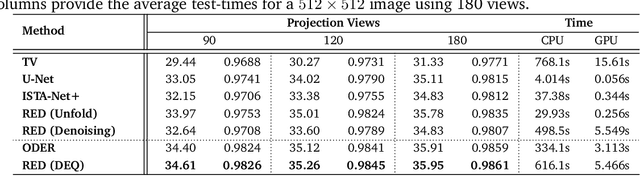
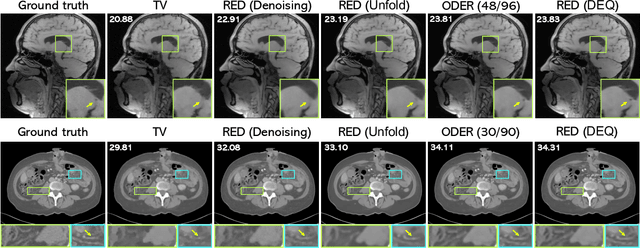
Plug-and-Play Priors (PnP) and Regularization by Denoising (RED) are widely-used frameworks for solving imaging inverse problems by computing fixed-points of operators combining physical measurement models and learned image priors. While traditional PnP/RED formulations have focused on priors specified using image denoisers, there is a growing interest in learning PnP/RED priors that are end-to-end optimal. The recent Deep Equilibrium Models (DEQ) framework has enabled memory-efficient end-to-end learning of PnP/RED priors by implicitly differentiating through the fixed-point equations without storing intermediate activation values. However, the dependence of the computational/memory complexity of the measurement models in PnP/RED on the total number of measurements leaves DEQ impractical for many imaging applications. We propose ODER as a new strategy for improving the efficiency of DEQ through stochastic approximations of the measurement models. We theoretically analyze ODER giving insights into its convergence and ability to approximate the traditional DEQ approach. Our numerical results suggest the potential improvements in training/testing complexity due to ODER on three distinct imaging applications.
Delving into Deep Image Prior for Adversarial Defense: A Novel Reconstruction-based Defense Framework
Jul 31, 2021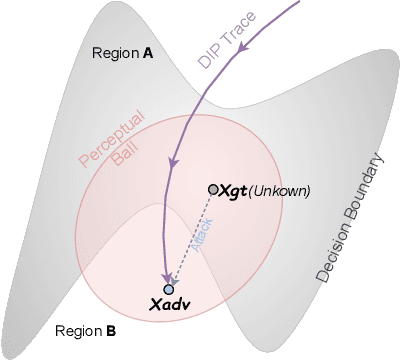
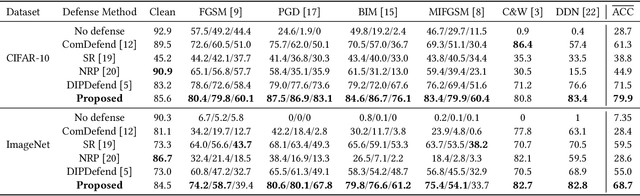
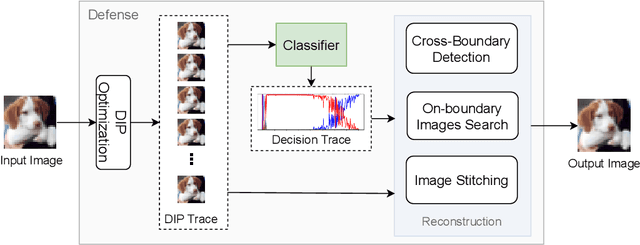
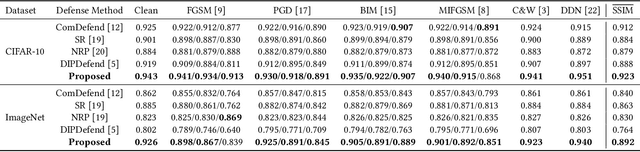
Deep learning based image classification models are shown vulnerable to adversarial attacks by injecting deliberately crafted noises to clean images. To defend against adversarial attacks in a training-free and attack-agnostic manner, this work proposes a novel and effective reconstruction-based defense framework by delving into deep image prior (DIP). Fundamentally different from existing reconstruction-based defenses, the proposed method analyzes and explicitly incorporates the model decision process into our defense. Given an adversarial image, firstly we map its reconstructed images during DIP optimization to the model decision space, where cross-boundary images can be detected and on-boundary images can be further localized. Then, adversarial noise is purified by perturbing on-boundary images along the reverse direction to the adversarial image. Finally, on-manifold images are stitched to construct an image that can be correctly predicted by the victim classifier. Extensive experiments demonstrate that the proposed method outperforms existing state-of-the-art reconstruction-based methods both in defending white-box attacks and defense-aware attacks. Moreover, the proposed method can maintain a high visual quality during adversarial image reconstruction.
Perceptual Quality Assessment of Omnidirectional Images
Jul 06, 2022



Omnidirectional images and videos can provide immersive experience of real-world scenes in Virtual Reality (VR) environment. We present a perceptual omnidirectional image quality assessment (IQA) study in this paper since it is extremely important to provide a good quality of experience under the VR environment. We first establish an omnidirectional IQA (OIQA) database, which includes 16 source images and 320 distorted images degraded by 4 commonly encountered distortion types, namely JPEG compression, JPEG2000 compression, Gaussian blur and Gaussian noise. Then a subjective quality evaluation study is conducted on the OIQA database in the VR environment. Considering that humans can only see a part of the scene at one movement in the VR environment, visual attention becomes extremely important. Thus we also track head and eye movement data during the quality rating experiments. The original and distorted omnidirectional images, subjective quality ratings, and the head and eye movement data together constitute the OIQA database. State-of-the-art full-reference (FR) IQA measures are tested on the OIQA database, and some new observations different from traditional IQA are made.
Vision Pair Learning: An Efficient Training Framework for Image Classification
Dec 02, 2021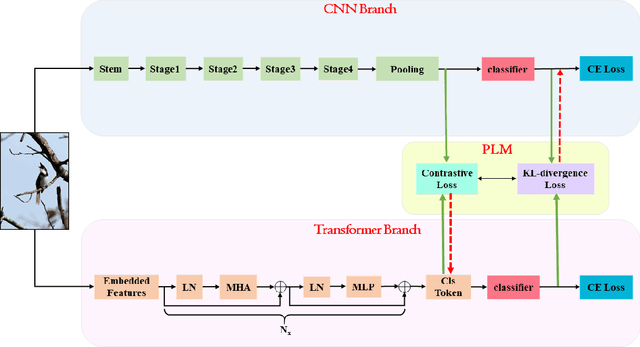
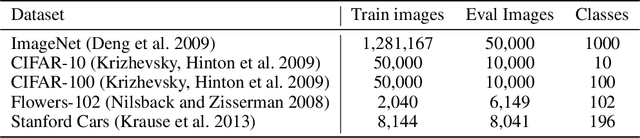
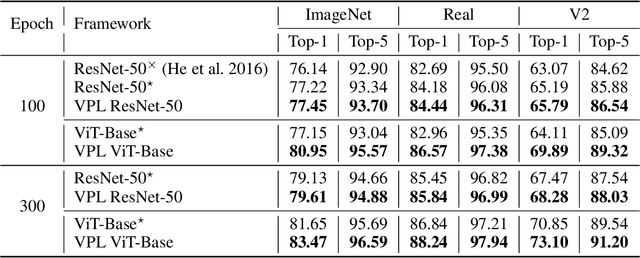
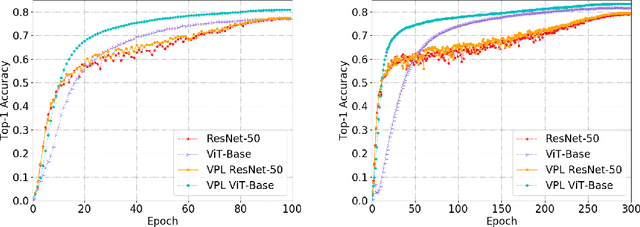
Transformer is a potentially powerful architecture for vision tasks. Although equipped with more parameters and attention mechanism, its performance is not as dominant as CNN currently. CNN is usually computationally cheaper and still the leading competitor in various vision tasks. One research direction is to adopt the successful ideas of CNN and improve transformer, but it often relies on elaborated and heuristic network design. Observing that transformer and CNN are complementary in representation learning and convergence speed, we propose an efficient training framework called Vision Pair Learning (VPL) for image classification task. VPL builds up a network composed of a transformer branch, a CNN branch and pair learning module. With multi-stage training strategy, VPL enables the branches to learn from their partners during the appropriate stage of the training process, and makes them both achieve better performance with less time cost. Without external data, VPL promotes the top-1 accuracy of ViT-Base and ResNet-50 on the ImageNet-1k validation set to 83.47% and 79.61% respectively. Experiments on other datasets of various domains prove the efficacy of VPL and suggest that transformer performs better when paired with the differently structured CNN in VPL. we also analyze the importance of components through ablation study.
RADNet: Ensemble Model for Robust Glaucoma Classification in Color Fundus Images
May 25, 2022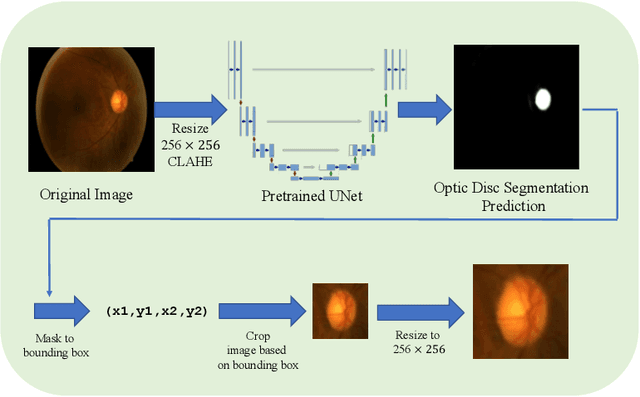
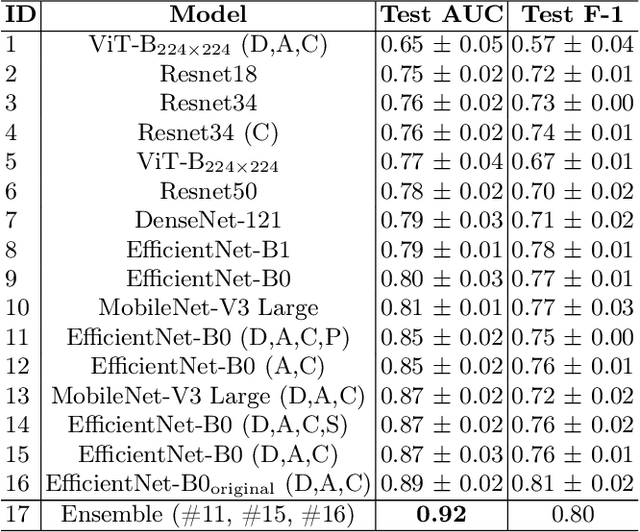
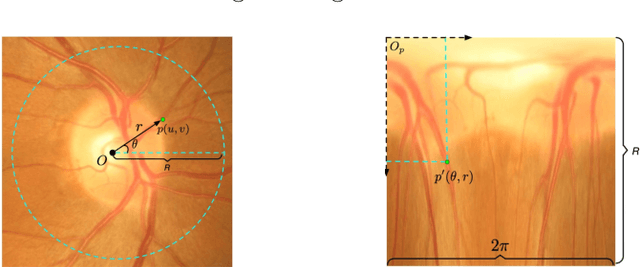
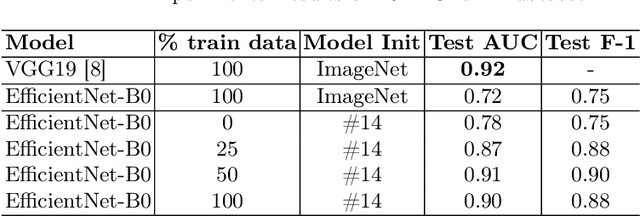
Glaucoma is one of the most severe eye diseases, characterized by rapid progression and leading to irreversible blindness. It is often the case that pathology diagnostics is carried out when the one's sight has already significantly degraded due to the lack of noticeable symptoms at early stage of the disease. Regular glaucoma screenings of the population shall improve early-stage detection, however the desirable frequency of etymological checkups is often not feasible due to excessive load imposed by manual diagnostics on limited number of specialists. Considering the basic methodology to detect glaucoma is to analyze fundus images for the \textit{optic-disc-to-optic-cup ratio}, Machine Learning domain can offer sophisticated tooling for image processing and classification. In our work, we propose an advanced image pre-processing technique combined with an ensemble of deep classification networks. Our \textit{Retinal Auto Detection (RADNet)} model has been successfully tested on Rotterdam EyePACS AIROGS train dataset with AUC of 0.92, and then additionally finetuned and tested on a fraction of RIM-ONE DL dataset with AUC of 0.91.
Object-aware Long-short-range Spatial Alignment for Few-Shot Fine-Grained Image Classification
Aug 30, 2021The goal of few-shot fine-grained image classification is to recognize rarely seen fine-grained objects in the query set, given only a few samples of this class in the support set. Previous works focus on learning discriminative image features from a limited number of training samples for distinguishing various fine-grained classes, but ignore one important fact that spatial alignment of the discriminative semantic features between the query image with arbitrary changes and the support image, is also critical for computing the semantic similarity between each support-query pair. In this work, we propose an object-aware long-short-range spatial alignment approach, which is composed of a foreground object feature enhancement (FOE) module, a long-range semantic correspondence (LSC) module and a short-range spatial manipulation (SSM) module. The FOE is developed to weaken background disturbance and encourage higher foreground object response. To address the problem of long-range object feature misalignment between support-query image pairs, the LSC is proposed to learn the transferable long-range semantic correspondence by a designed feature similarity metric. Further, the SSM module is developed to refine the transformed support feature after the long-range step to align short-range misaligned features (or local details) with the query features. Extensive experiments have been conducted on four benchmark datasets, and the results show superior performance over most state-of-the-art methods under both 1-shot and 5-shot classification scenarios.
Cross-Image Region Mining with Region Prototypical Network for Weakly Supervised Segmentation
Aug 17, 2021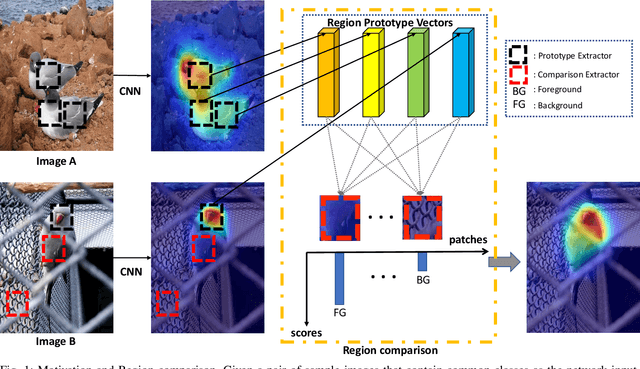
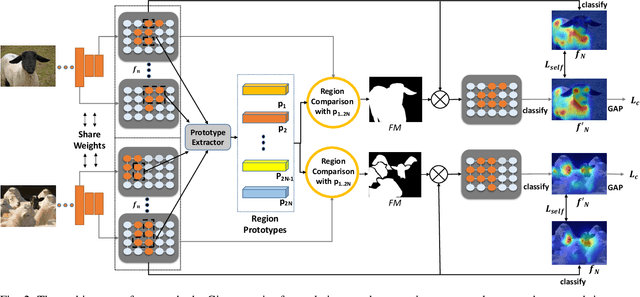
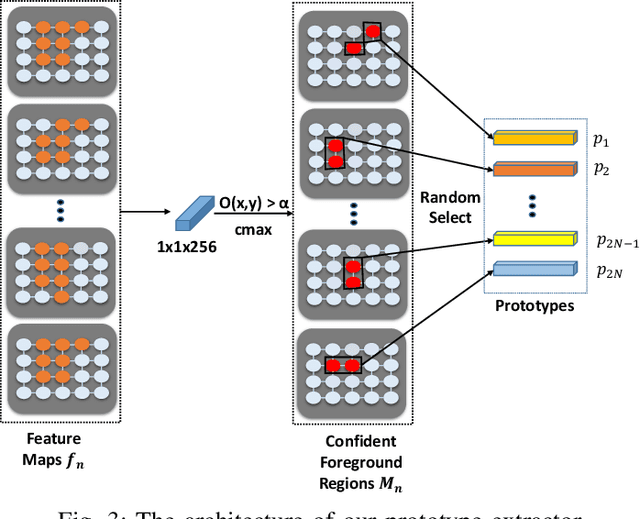
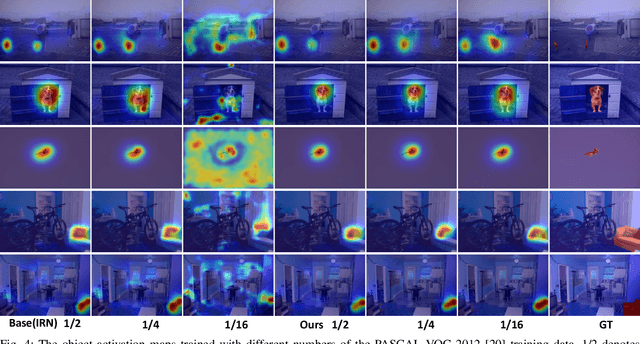
Weakly supervised image segmentation trained with image-level labels usually suffers from inaccurate coverage of object areas during the generation of the pseudo groundtruth. This is because the object activation maps are trained with the classification objective and lack the ability to generalize. To improve the generality of the objective activation maps, we propose a region prototypical network RPNet to explore the cross-image object diversity of the training set. Similar object parts across images are identified via region feature comparison. Object confidence is propagated between regions to discover new object areas while background regions are suppressed. Experiments show that the proposed method generates more complete and accurate pseudo object masks, while achieving state-of-the-art performance on PASCAL VOC 2012 and MS COCO. In addition, we investigate the robustness of the proposed method on reduced training sets.