 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Temporal Disentanglement of Representations for Improved Generalisation in Reinforcement Learning
Jul 12, 2022
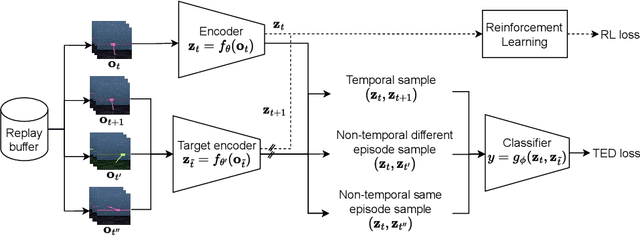

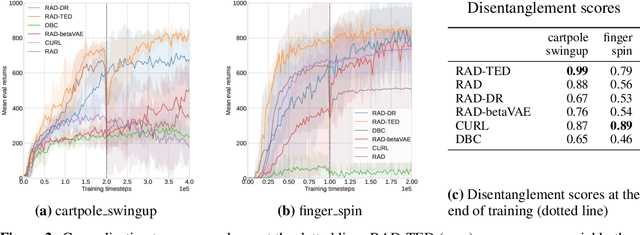
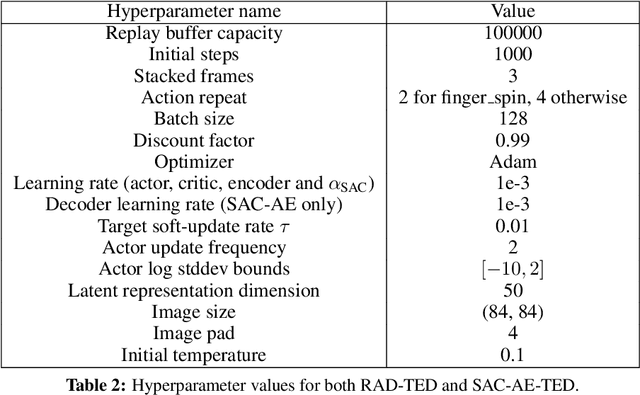
In real-world robotics applications, Reinforcement Learning (RL) agents are often unable to generalise to environment variations that were not observed during training. This issue is intensified for image-based RL where a change in one variable, such as the background colour, can change many pixels in the image, and in turn can change all values in the agent's internal representation of the image. To learn more robust representations, we introduce TEmporal Disentanglement (TED), a self-supervised auxiliary task that leads to disentangled representations using the sequential nature of RL observations. We find empirically that RL algorithms with TED as an auxiliary task adapt more quickly to changes in environment variables with continued training compared to state-of-the-art representation learning methods. Due to the disentangled structure of the representation, we also find that policies trained with TED generalise better to unseen values of variables irrelevant to the task (e.g. background colour) as well as unseen values of variables that affect the optimal policy (e.g. goal positions).
Graph Signal Processing for Heterogeneous Change Detection Part II: Spectral Domain Analysis
Aug 08, 2022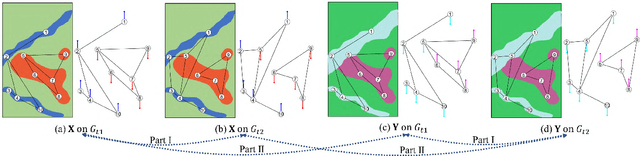
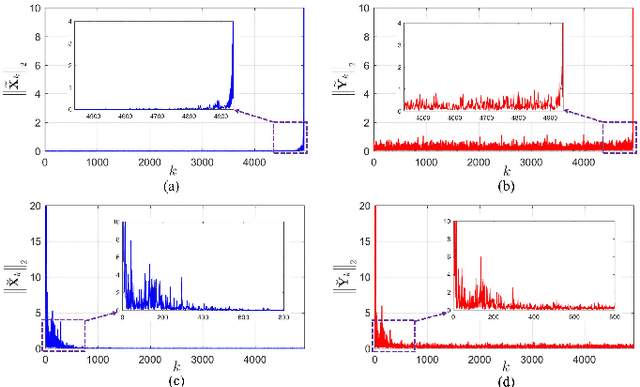
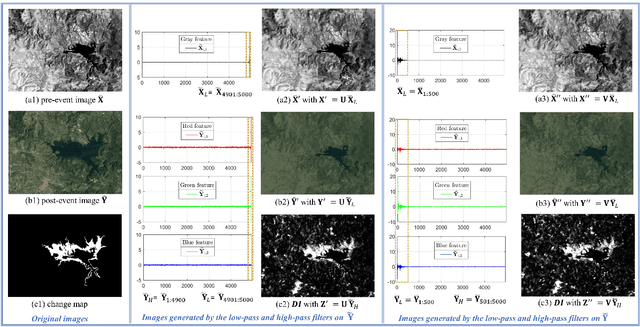
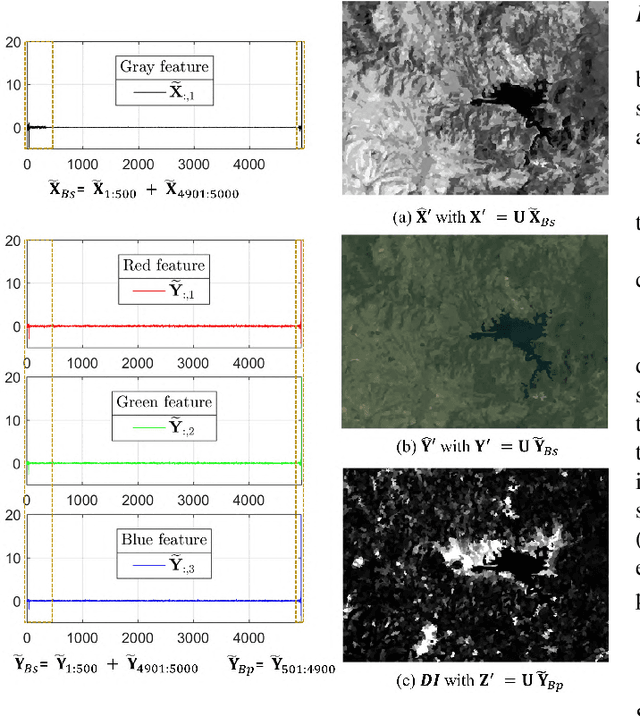
This is the second part of the paper that provides a new strategy for the heterogeneous change detection (HCD) problem, that is, solving HCD from the perspective of graph signal processing (GSP). We construct a graph to represent the structure of each image, and treat each image as a graph signal defined on the graph. In this way, we can convert the HCD problem into a comparison of responses of signals on systems defined on the graphs. In the part I, the changes are measured by comparing the structure difference between the graphs from the vertex domain. In this part II, we analyze the GSP for HCD from the spectral domain. We first analyze the spectral properties of the different images on the same graph, and show that their spectra exhibit commonalities and dissimilarities. Specially, it is the change that leads to the dissimilarities of their spectra. Then, we propose a regression model for the HCD, which decomposes the source signal into the regressed signal and changed signal, and requires the regressed signal have the same spectral property as the target signal on the same graph. With the help of graph spectral analysis, the proposed regression model is flexible and scalable. Experiments conducted on seven real data sets show the effectiveness of the proposed method.
Open-Vocabulary Multi-Label Classification via Multi-modal Knowledge Transfer
Jul 05, 2022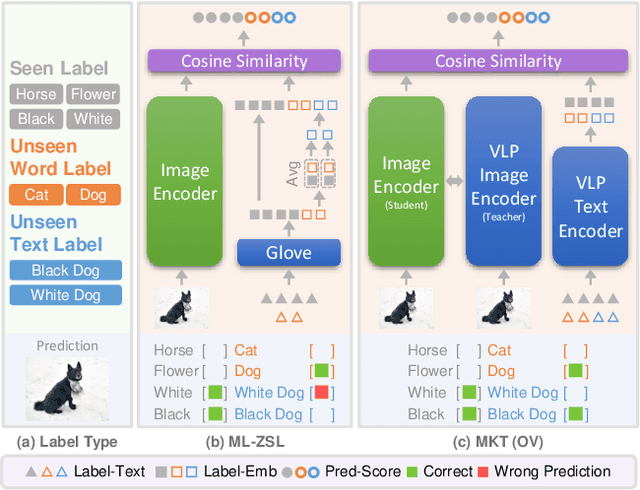



Real-world recognition system often encounters a plenty of unseen labels in practice. To identify such unseen labels, multi-label zero-shot learning (ML-ZSL) focuses on transferring knowledge by a pre-trained textual label embedding (e.g., GloVe). However, such methods only exploit singlemodal knowledge from a language model, while ignoring the rich semantic information inherent in image-text pairs. Instead, recently developed open-vocabulary (OV) based methods succeed in exploiting such information of image-text pairs in object detection, and achieve impressive performance. Inspired by the success of OV-based methods, we propose a novel open-vocabulary framework, named multimodal knowledge transfer (MKT), for multi-label classification. Specifically, our method exploits multi-modal knowledge of image-text pairs based on a vision and language pretraining (VLP) model. To facilitate transferring the imagetext matching ability of VLP model, knowledge distillation is used to guarantee the consistency of image and label embeddings, along with prompt tuning to further update the label embeddings. To further recognize multiple objects, a simple but effective two-stream module is developed to capture both local and global features. Extensive experimental results show that our method significantly outperforms state-of-theart methods on public benchmark datasets. Code will be available at https://github.com/seanhe97/MKT.
ViTBIS: Vision Transformer for Biomedical Image Segmentation
Jan 15, 2022In this paper, we propose a novel network named Vision Transformer for Biomedical Image Segmentation (ViTBIS). Our network splits the input feature maps into three parts with $1\times 1$, $3\times 3$ and $5\times 5$ convolutions in both encoder and decoder. Concat operator is used to merge the features before being fed to three consecutive transformer blocks with attention mechanism embedded inside it. Skip connections are used to connect encoder and decoder transformer blocks. Similarly, transformer blocks and multi scale architecture is used in decoder before being linearly projected to produce the output segmentation map. We test the performance of our network using Synapse multi-organ segmentation dataset, Automated cardiac diagnosis challenge dataset, Brain tumour MRI segmentation dataset and Spleen CT segmentation dataset. Without bells and whistles, our network outperforms most of the previous state of the art CNN and transformer based models using Dice score and the Hausdorff distance as the evaluation metrics.
* Published at Clinical Image-Based Procedures, Distributed and Collaborative Learning, Artificial Intelligence for Combating COVID-19 and Secure and Privacy-Preserving Machine Learning workshop at MICCAI 2021
Automated Classification of Nanoparticles with Various Ultrastructures and Sizes
Jul 28, 2022
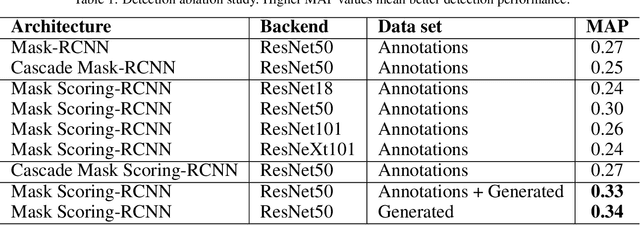
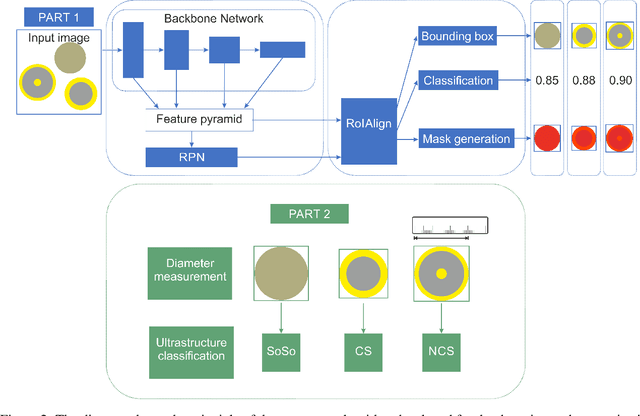
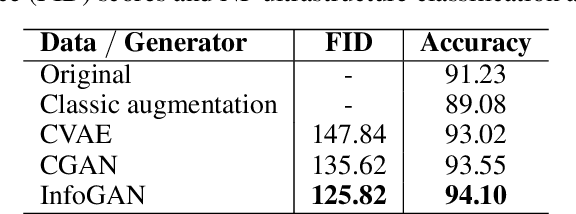
Accurately measuring the size, morphology, and structure of nanoparticles is very important, because they are strongly dependent on their properties for many applications. In this paper, we present a deep-learning based method for nanoparticle measurement and classification trained from a small data set of scanning transmission electron microscopy images. Our approach is comprised of two stages: localization, i.e., detection of nanoparticles, and classification, i.e., categorization of their ultrastructure. For each stage, we optimize the segmentation and classification by analysis of the different state-of-the-art neural networks. We show how the generation of synthetic images, either using image processing or using various image generation neural networks, can be used to improve the results in both stages. Finally, the application of the algorithm to bimetallic nanoparticles demonstrates the automated data collection of size distributions including classification of complex ultrastructures. The developed method can be easily transferred to other material systems and nanoparticle structures.
Long-Range Feature Propagating for Natural Image Matting
Sep 25, 2021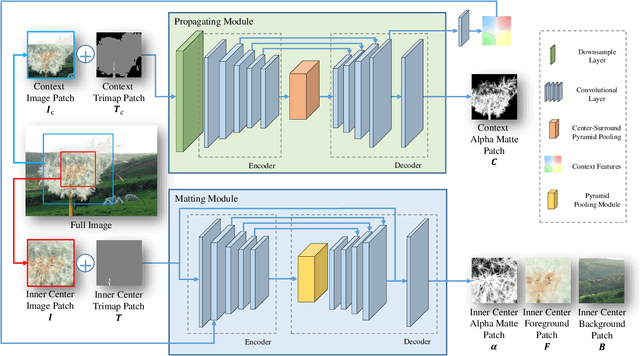
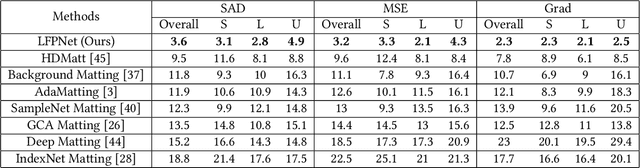
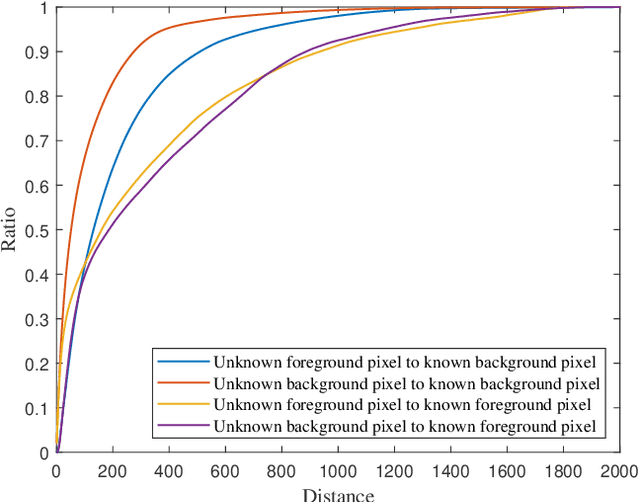
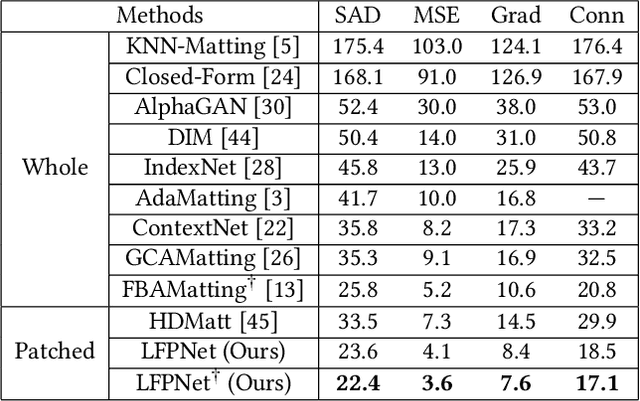
Natural image matting estimates the alpha values of unknown regions in the trimap. Recently, deep learning based methods propagate the alpha values from the known regions to unknown regions according to the similarity between them. However, we find that more than 50\% pixels in the unknown regions cannot be correlated to pixels in known regions due to the limitation of small effective reception fields of common convolutional neural networks, which leads to inaccurate estimation when the pixels in the unknown regions cannot be inferred only with pixels in the reception fields. To solve this problem, we propose Long-Range Feature Propagating Network (LFPNet), which learns the long-range context features outside the reception fields for alpha matte estimation. Specifically, we first design the propagating module which extracts the context features from the downsampled image. Then, we present Center-Surround Pyramid Pooling (CSPP) that explicitly propagates the context features from the surrounding context image patch to the inner center image patch. Finally, we use the matting module which takes the image, trimap and context features to estimate the alpha matte. Experimental results demonstrate that the proposed method performs favorably against the state-of-the-art methods on the AlphaMatting and Adobe Image Matting datasets.
Towards Adversarially Robust Deep Image Denoising
Jan 13, 2022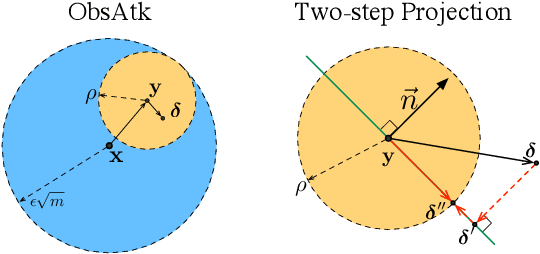
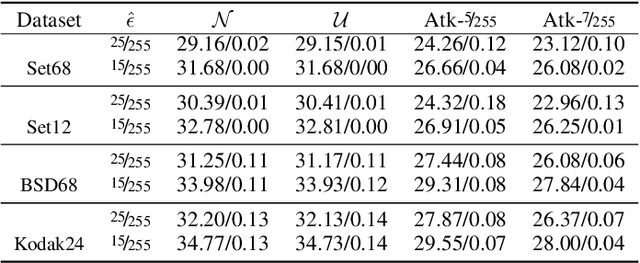

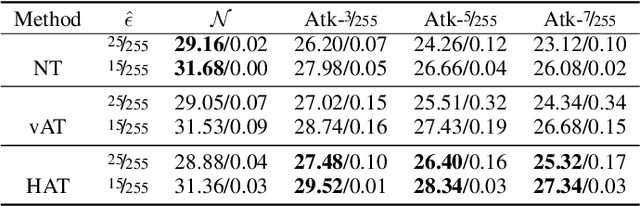
This work systematically investigates the adversarial robustness of deep image denoisers (DIDs), i.e, how well DIDs can recover the ground truth from noisy observations degraded by adversarial perturbations. Firstly, to evaluate DIDs' robustness, we propose a novel adversarial attack, namely Observation-based Zero-mean Attack ({\sc ObsAtk}), to craft adversarial zero-mean perturbations on given noisy images. We find that existing DIDs are vulnerable to the adversarial noise generated by {\sc ObsAtk}. Secondly, to robustify DIDs, we propose an adversarial training strategy, hybrid adversarial training ({\sc HAT}), that jointly trains DIDs with adversarial and non-adversarial noisy data to ensure that the reconstruction quality is high and the denoisers around non-adversarial data are locally smooth. The resultant DIDs can effectively remove various types of synthetic and adversarial noise. We also uncover that the robustness of DIDs benefits their generalization capability on unseen real-world noise. Indeed, {\sc HAT}-trained DIDs can recover high-quality clean images from real-world noise even without training on real noisy data. Extensive experiments on benchmark datasets, including Set68, PolyU, and SIDD, corroborate the effectiveness of {\sc ObsAtk} and {\sc HAT}.
CACTUSS: Common Anatomical CT-US Space for US examinations
Jul 18, 2022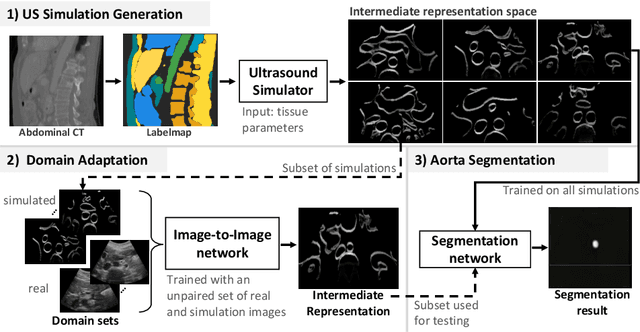
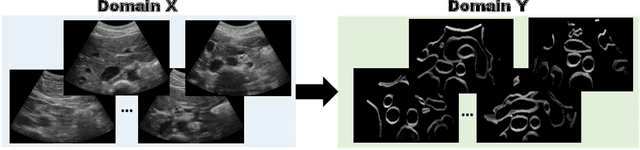
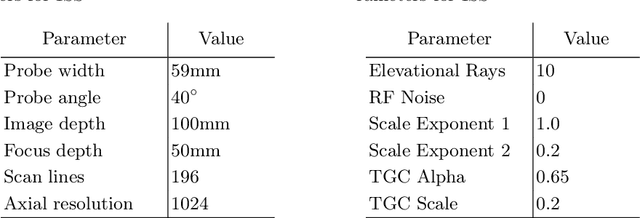
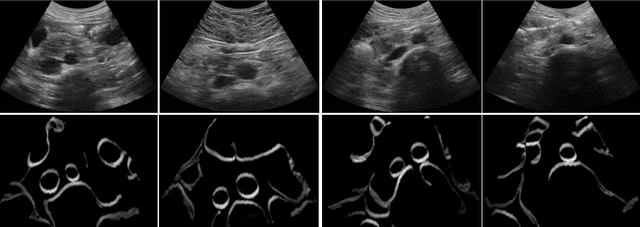
Abdominal aortic aneurysm (AAA) is a vascular disease in which a section of the aorta enlarges, weakening its walls and potentially rupturing the vessel. Abdominal ultrasound has been utilized for diagnostics, but due to its limited image quality and operator dependency, CT scans are usually required for monitoring and treatment planning. Recently, abdominal CT datasets have been successfully utilized to train deep neural networks for automatic aorta segmentation. Knowledge gathered from this solved task could therefore be leveraged to improve US segmentation for AAA diagnosis and monitoring. To this end, we propose CACTUSS: a common anatomical CT-US space, which acts as a virtual bridge between CT and US modalities to enable automatic AAA screening sonography. CACTUSS makes use of publicly available labelled data to learn to segment based on an intermediary representation that inherits properties from both US and CT. We train a segmentation network in this new representation and employ an additional image-to-image translation network which enables our model to perform on real B-mode images. Quantitative comparisons against fully supervised methods demonstrate the capabilities of CACTUSS in terms of Dice Score and diagnostic metrics, showing that our method also meets the clinical requirements for AAA scanning and diagnosis.
Multiscale Convolutional Transformer with Center Mask Pretraining for Hyperspectral Image Classification
Mar 21, 2022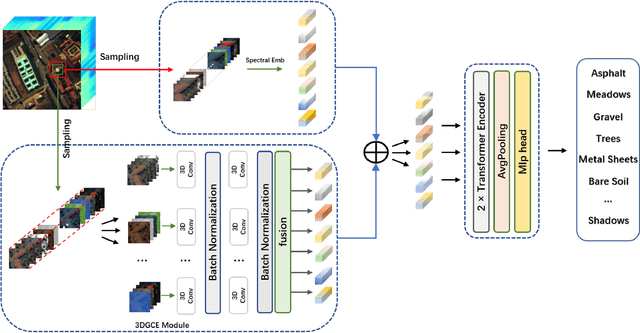
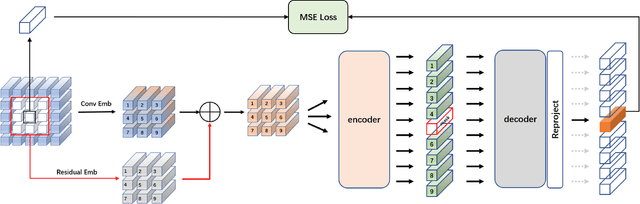
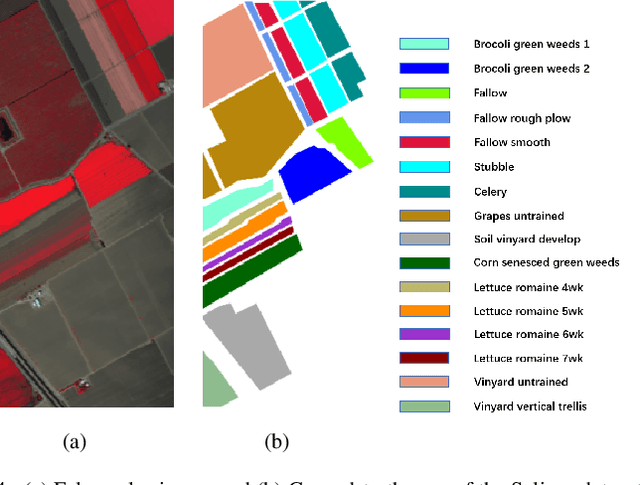
Hyperspectral images (HSI) not only have a broad macroscopic field of view but also contain rich spectral information, and the types of surface objects can be identified through spectral information, which is one of the main applications in hyperspectral image related research.In recent years, more and more deep learning methods have been proposed, among which convolutional neural networks (CNN) are the most influential. However, CNN-based methods are difficult to capture long-range dependencies, and also require a large amount of labeled data for model training.Besides, most of the self-supervised training methods in the field of HSI classification are based on the reconstruction of input samples, and it is difficult to achieve effective use of unlabeled samples. To address the shortcomings of CNN networks, we propose a noval multi-scale convolutional embedding module for HSI to realize effective extraction of spatial-spectral information, which can be better combined with Transformer network.In order to make more efficient use of unlabeled data, we propose a new self-supervised pretask. Similar to Mask autoencoder, but our pre-training method only masks the corresponding token of the central pixel in the encoder, and inputs the remaining token into the decoder to reconstruct the spectral information of the central pixel.Such a pretask can better model the relationship between the central feature and the domain feature, and obtain more stable training results.
iColoriT: Towards Propagating Local Hint to the Right Region in Interactive Colorization by Leveraging Vision Transformer
Jul 15, 2022
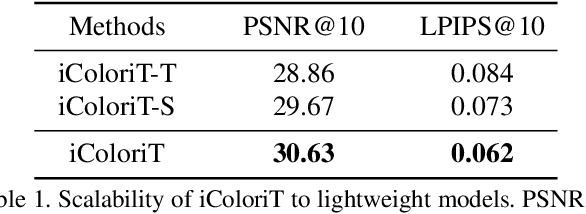

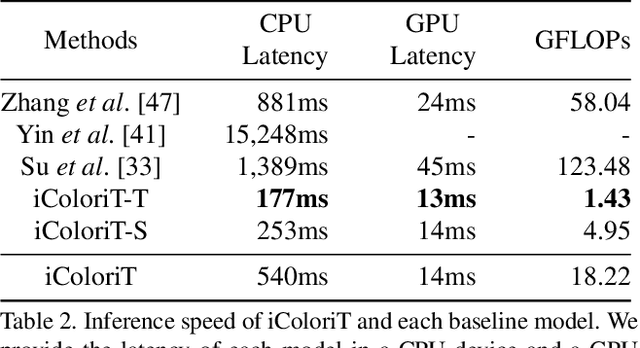
Point-interactive image colorization aims to colorize grayscale images when a user provides the colors for specific locations. It is essential for point-interactive colorization methods to appropriately propagate user-provided colors (i.e., user hints) in the entire image to obtain a reasonably colorized image with minimal user effort. However, existing approaches often produce partially colorized results due to the inefficient design of stacking convolutional layers to propagate hints to distant relevant regions. To address this problem, we present iColoriT, a novel point-interactive colorization Vision Transformer capable of propagating user hints to relevant regions, leveraging the global receptive field of Transformers. The self-attention mechanism of Transformers enables iColoriT to selectively colorize relevant regions with only a few local hints. Our approach colorizes images in real-time by utilizing pixel shuffling, an efficient upsampling technique that replaces the decoder architecture. Also, in order to mitigate the artifacts caused by pixel shuffling with large upsampling ratios, we present the local stabilizing layer. Extensive quantitative and qualitative results demonstrate that our approach highly outperforms existing methods for point-interactive colorization, producing accurately colorized images with a user's minimal effort.