 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion Adversarial Representation Learning for Self-supervised Vessel Segmentation
Sep 29, 2022
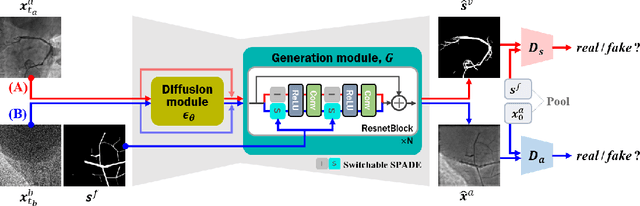
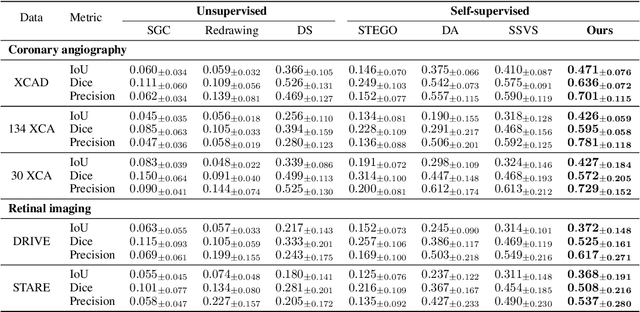
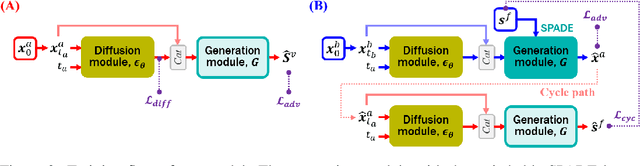
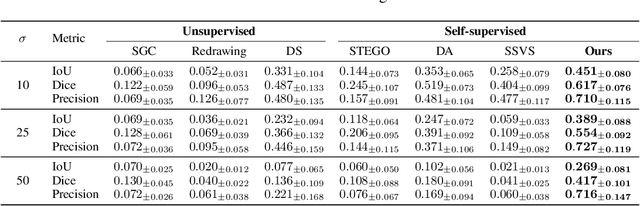
Vessel segmentation in medical images is one of the important tasks in the diagnosis of vascular diseases and therapy planning. Although learning-based segmentation approaches have been extensively studied, a large amount of ground-truth labels are required in supervised methods and confusing background structures make neural networks hard to segment vessels in an unsupervised manner. To address this, here we introduce a novel diffusion adversarial representation learning (DARL) model that leverages a denoising diffusion probabilistic model with adversarial learning, and apply it for vessel segmentation. In particular, for self-supervised vessel segmentation, DARL learns background image distribution using a diffusion module, which lets a generation module effectively provide vessel representations. Also, by adversarial learning based on the proposed switchable spatially-adaptive denormalization, our model estimates synthetic fake vessel images as well as vessel segmentation masks, which further makes the model capture vessel-relevant semantic information. Once the proposed model is trained, the model generates segmentation masks by one step and can be applied to general vascular structure segmentation of coronary angiography and retinal images. Experimental results on various datasets show that our method significantly outperforms existing unsupervised and self-supervised methods in vessel segmentation.
How Does Frequency Bias Affect the Robustness of Neural Image Classifiers against Common Corruption and Adversarial Perturbations?
May 09, 2022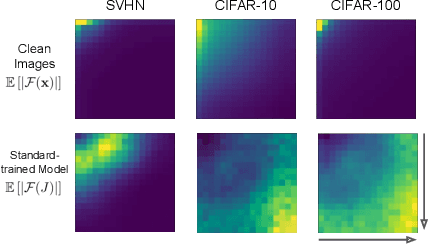
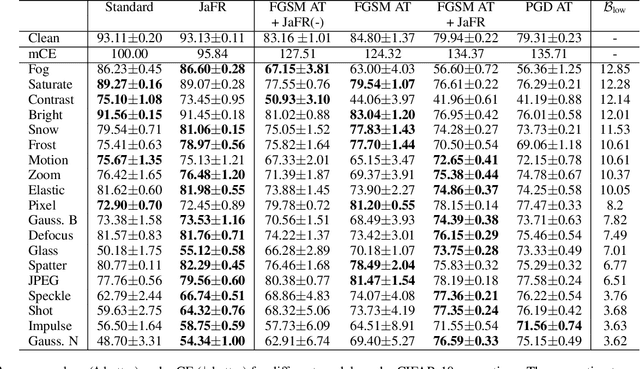
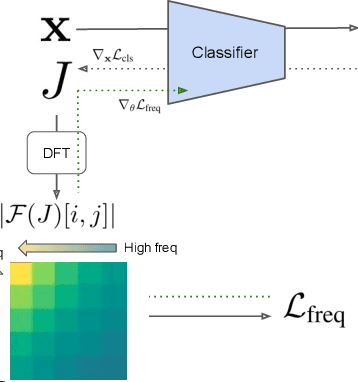
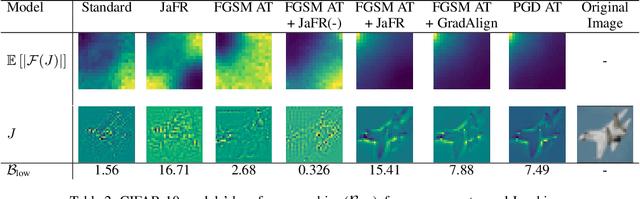
Model robustness is vital for the reliable deployment of machine learning models in real-world applications. Recent studies have shown that data augmentation can result in model over-relying on features in the low-frequency domain, sacrificing performance against low-frequency corruptions, highlighting a connection between frequency and robustness. Here, we take one step further to more directly study the frequency bias of a model through the lens of its Jacobians and its implication to model robustness. To achieve this, we propose Jacobian frequency regularization for models' Jacobians to have a larger ratio of low-frequency components. Through experiments on four image datasets, we show that biasing classifiers towards low (high)-frequency components can bring performance gain against high (low)-frequency corruption and adversarial perturbation, albeit with a tradeoff in performance for low (high)-frequency corruption. Our approach elucidates a more direct connection between the frequency bias and robustness of deep learning models.
StyleGAN Encoder-Based Attack for Block Scrambled Face Images
Sep 16, 2022
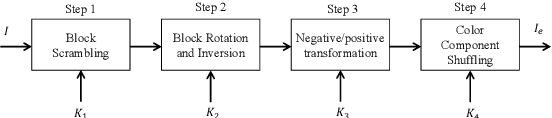

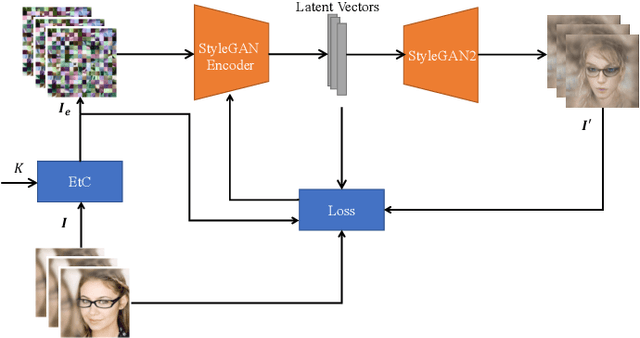
In this paper, we propose an attack method to block scrambled face images, particularly Encryption-then-Compression (EtC) applied images by utilizing the existing powerful StyleGAN encoder and decoder for the first time. Instead of reconstructing identical images as plain ones from encrypted images, we focus on recovering styles that can reveal identifiable information from the encrypted images. The proposed method trains an encoder by using plain and encrypted image pairs with a particular training strategy. While state-of-the-art attack methods cannot recover any perceptual information from EtC images, the proposed method discloses personally identifiable information such as hair color, skin color, eyeglasses, gender, etc. Experiments were carried out on the CelebA dataset, and results show that reconstructed images have some perceptual similarities compared to plain images.
Fine-tuning or top-tuning? Transfer learning with pretrained features and fast kernel methods
Sep 16, 2022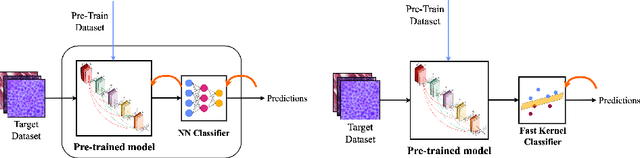
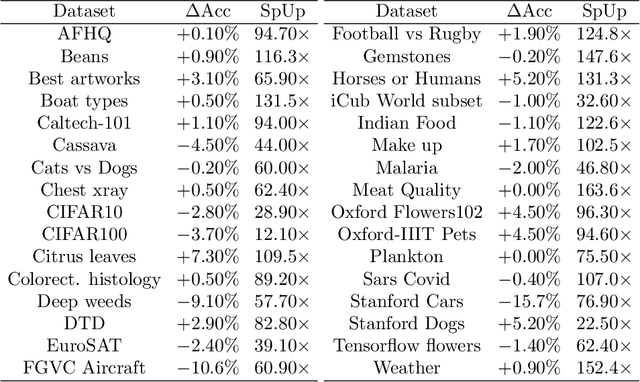
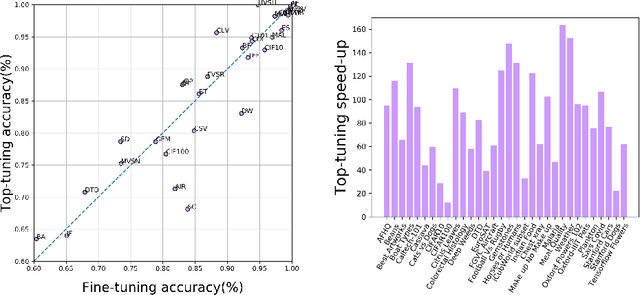
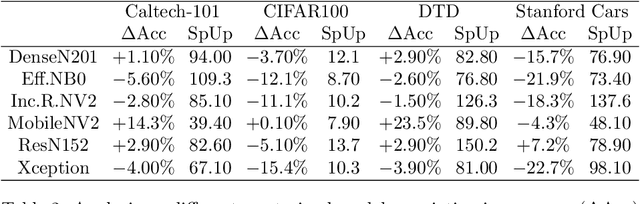
The impressive performances of deep learning architectures is associated to massive increase of models complexity. Millions of parameters need be tuned, with training and inference time scaling accordingly. But is massive fine-tuning necessary? In this paper, focusing on image classification, we consider a simple transfer learning approach exploiting pretrained convolutional features as input for a fast kernel method. We refer to this approach as top-tuning, since only the kernel classifier is trained. By performing more than 2500 training processes we show that this top-tuning approach provides comparable accuracy w.r.t. fine-tuning, with a training time that is between one and two orders of magnitude smaller. These results suggest that top-tuning provides a useful alternative to fine-tuning in small/medium datasets, especially when training efficiency is crucial.
Thermal hand image segmentation for biometric recognition
Feb 23, 2022
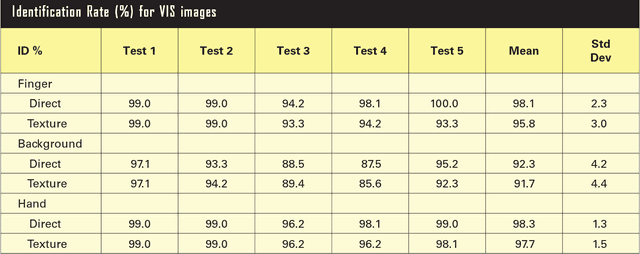
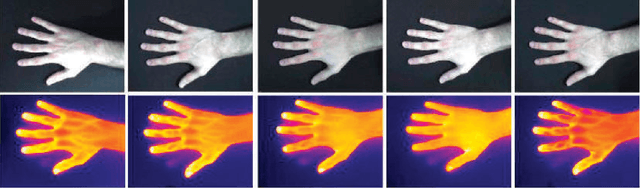

In this paper we present a method to identify people by means of thermal (TH) and visible (VIS) hand images acquired simultaneously with a TESTO 882-3 camera. In addition, we also present a new database specially acquired for this work. The real challenge when dealing with TH images is the cold finger areas, which can be confused with the acquisition surface. This problem is solved by taking advantage of the VIS information. We have performed different tests to show how TH and VIS images work in identification problems. Experimental results reveal that TH hand image is as suitable for biometric recognition systems as VIS hand images, and better results are obtained when combining this information. A Biometric Dispersion Matcher has been used as a feature vector dimensionality reduction technique as well as a classification task. Its selection criteria helps to reduce the length of the vectors used to perform identification up to a hundred measurements. Identification rates reach a maximum value of 98.3% under these conditions, when using a database of 104 people.
* 12 pages
Realistic Blur Synthesis for Learning Image Deblurring
Feb 17, 2022
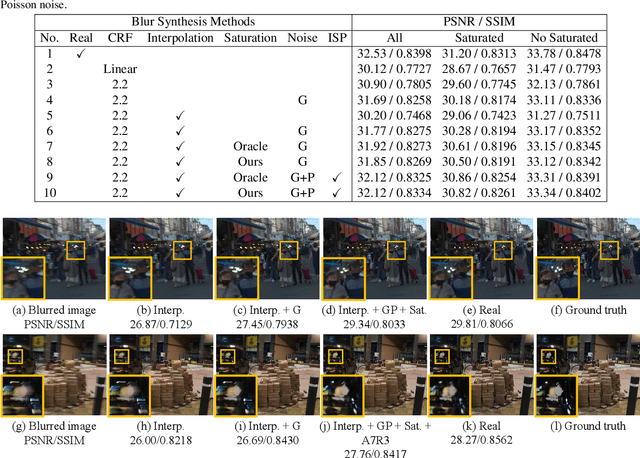
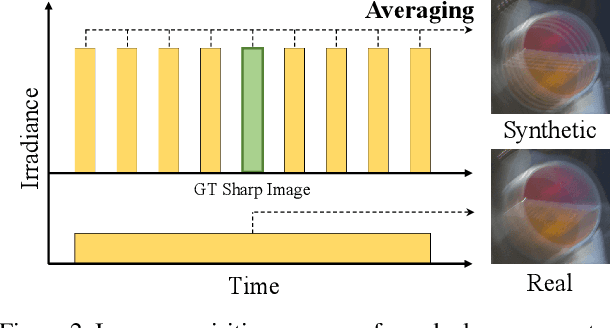

Training learning-based deblurring methods demands a significant amount of blurred and sharp image pairs. Unfortunately, existing synthetic datasets are not realistic enough, and existing real-world blur datasets provide limited diversity of scenes and camera settings. As a result, deblurring models trained on them still suffer from the lack of generalization ability for handling real blurred images. In this paper, we analyze various factors that introduce differences between real and synthetic blurred images, and present a novel blur synthesis pipeline that can synthesize more realistic blur. We also present RSBlur, a novel dataset that contains real blurred images and the corresponding sequences of sharp images. The RSBlur dataset can be used for generating synthetic blurred images to enable detailed analysis on the differences between real and synthetic blur. With our blur synthesis pipeline and RSBlur dataset, we reveal the effects of different factors in the blur synthesis. We also show that our synthesis method can improve the deblurring performance on real blurred images.
Semi-supervised Body Parsing and Pose Estimation for Enhancing Infant General Movement Assessment
Oct 14, 2022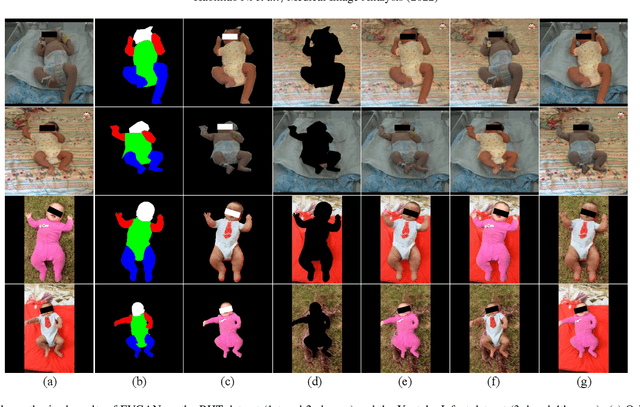
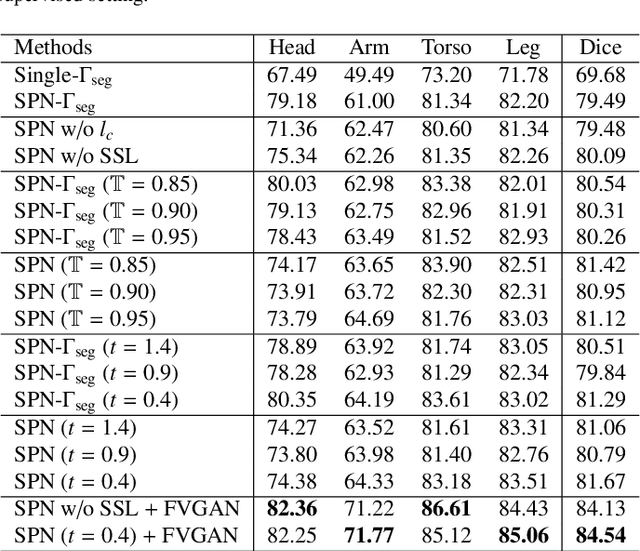
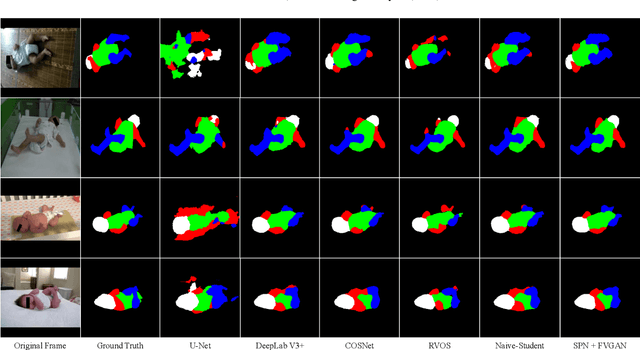
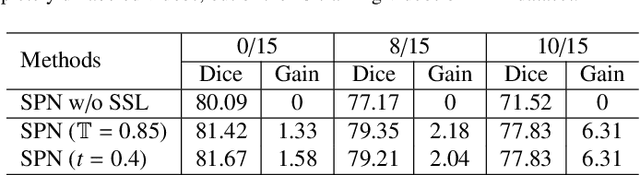
General movement assessment (GMA) of infant movement videos (IMVs) is an effective method for early detection of cerebral palsy (CP) in infants. We demonstrate in this paper that end-to-end trainable neural networks for image sequence recognition can be applied to achieve good results in GMA, and more importantly, augmenting raw video with infant body parsing and pose estimation information can significantly improve performance. To solve the problem of efficiently utilizing partially labeled IMVs for body parsing, we propose a semi-supervised model, termed SiamParseNet (SPN), which consists of two branches, one for intra-frame body parts segmentation and another for inter-frame label propagation. During training, the two branches are jointly trained by alternating between using input pairs of only labeled frames and input of both labeled and unlabeled frames. We also investigate training data augmentation by proposing a factorized video generative adversarial network (FVGAN) to synthesize novel labeled frames for training. When testing, we employ a multi-source inference mechanism, where the final result for a test frame is either obtained via the segmentation branch or via propagation from a nearby key frame. We conduct extensive experiments for body parsing using SPN on two infant movement video datasets, where SPN coupled with FVGAN achieves state-of-the-art performance. We further demonstrate that SPN can be easily adapted to the infant pose estimation task with superior performance. Last but not least, we explore the clinical application of our method for GMA. We collected a new clinical IMV dataset with GMA annotations, and our experiments show that SPN models for body parsing and pose estimation trained on the first two datasets generalize well to the new clinical dataset and their results can significantly boost the CRNN-based GMA prediction performance.
An Analysis on Ensemble Learning optimized Medical Image Classification with Deep Convolutional Neural Networks
Jan 27, 2022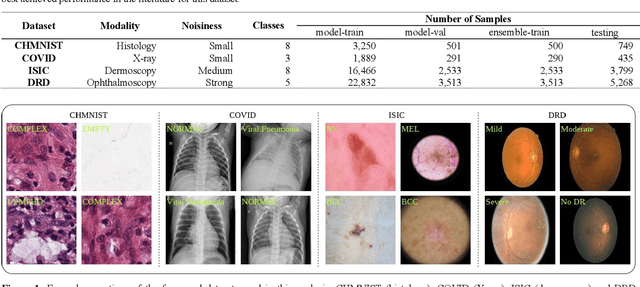
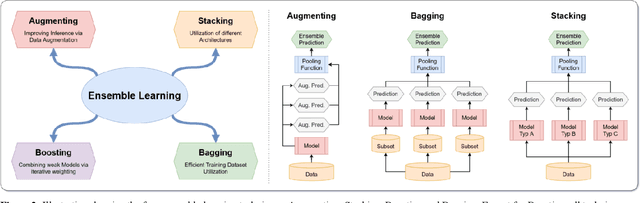
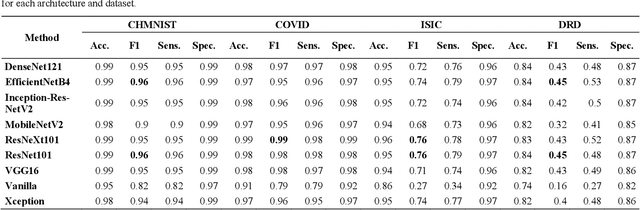
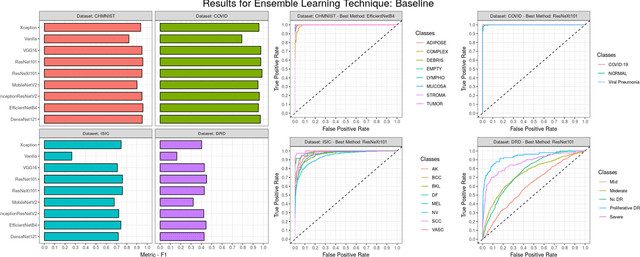
Novel and high-performance medical image classification pipelines are heavily utilizing ensemble learning strategies. The idea of ensemble learning is to assemble diverse models or multiple predictions and, thus, boost prediction performance. However, it is still an open question to what extent as well as which ensemble learning strategies are beneficial in deep learning based medical image classification pipelines. In this work, we proposed a reproducible medical image classification pipeline for analyzing the performance impact of the following ensemble learning techniques: Augmenting, Stacking, and Bagging. The pipeline consists of state-of-the-art preprocessing and image augmentation methods as well as 9 deep convolution neural network architectures. It was applied on four popular medical imaging datasets with varying complexity. Furthermore, 12 pooling functions for combining multiple predictions were analyzed, ranging from simple statistical functions like unweighted averaging up to more complex learning-based functions like support vector machines. Our results revealed that Stacking achieved the largest performance gain of up to 13% F1-score increase. Augmenting showed consistent improvement capabilities by up to 4% and is also applicable to single model based pipelines. Cross-validation based Bagging demonstrated to be the most complex ensemble learning method, which resulted in an F1-score decrease in all analyzed datasets (up to -10%). Furthermore, we demonstrated that simple statistical pooling functions are equal or often even better than more complex pooling functions. We concluded that the integration of Stacking and Augmentation ensemble learning techniques is a powerful method for any medical image classification pipeline to improve robustness and boost performance.
Rapid dynamic speech imaging at 3 Tesla using combination of a custom vocal tract coil, variable density spirals and manifold regularization
Sep 06, 2022
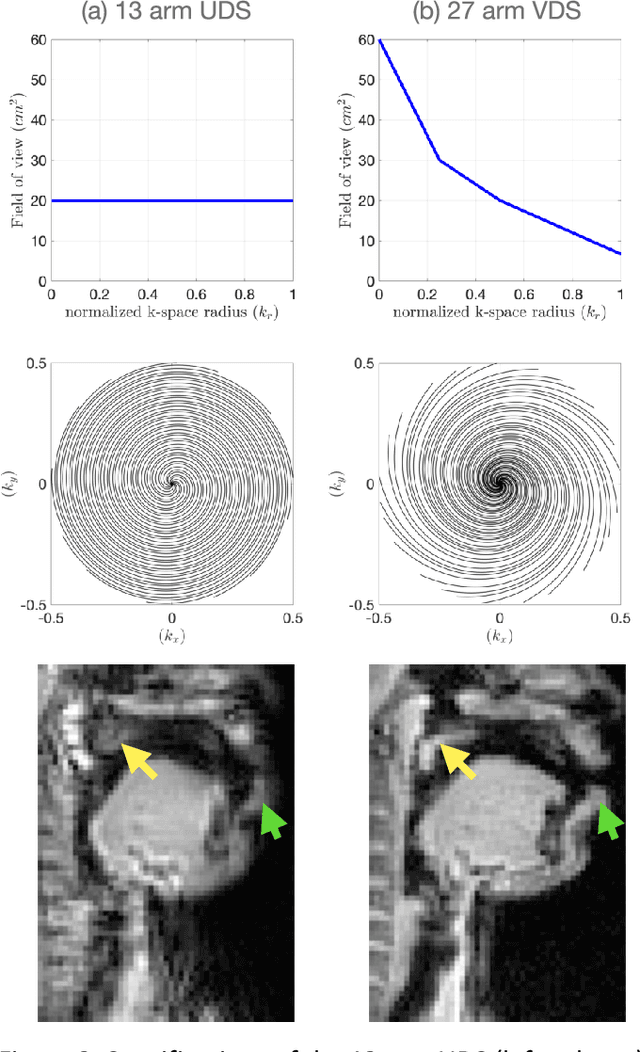
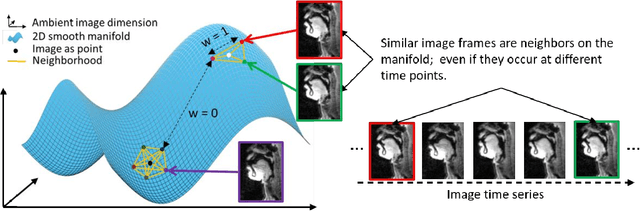
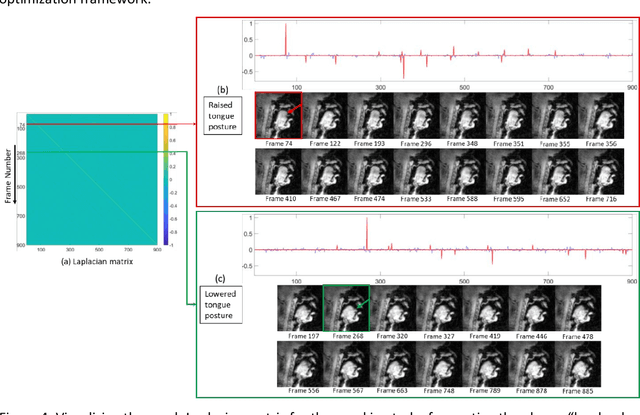
Purpose: To improve dynamic speech imaging at 3 Tesla. Methods: A novel scheme combining a 16-channel vocal tract coil, variable density spirals (VDS), and manifold regularization was developed. Short readout duration spirals (1.3 ms long) were used to minimize sensitivity to off-resonance. The manifold model leveraged similarities between frames sharing similar vocal tract postures without explicit motion binning. Reconstruction was posed as a SENSE-based non-local soft weighted temporal regularization scheme. The self-navigating capability of VDS was leveraged to learn the structure of the manifold. Our approach was compared against low-rank and finite difference reconstruction constraints on two volunteers performing repetitive and arbitrary speaking tasks. Blinded image quality evaluation in the categories of alias artifacts, spatial blurring, and temporal blurring were performed by three experts in voice research. Results: We achieved a spatial resolution of 2.4mm2/pixel and a temporal resolution of 17.4 ms/frame for single slice imaging, and 52.2 ms/frame for concurrent 3-slice imaging. Implicit motion binning of the manifold scheme for both repetitive and fluent speaking tasks was demonstrated. The manifold scheme provided superior fidelity in modeling articulatory motion compared to low rank and temporal finite difference schemes. This was reflected by higher image quality scores in spatial and temporal blurring categories. Our technique exhibited faint alias artifacts, but offered a reduced interquartile range of scores compared to other methods in alias artifact category. Conclusion: Synergistic combination of a custom vocal-tract coil, variable density spirals and manifold regularization enables robust dynamic speech imaging at 3 Tesla.
Spikformer: When Spiking Neural Network Meets Transformer
Sep 29, 2022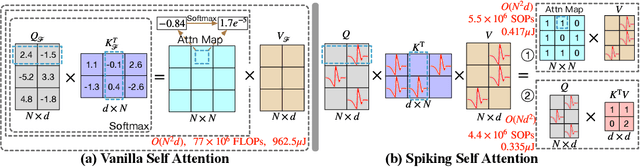
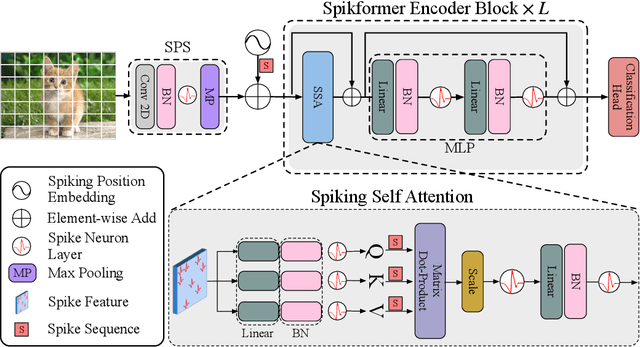
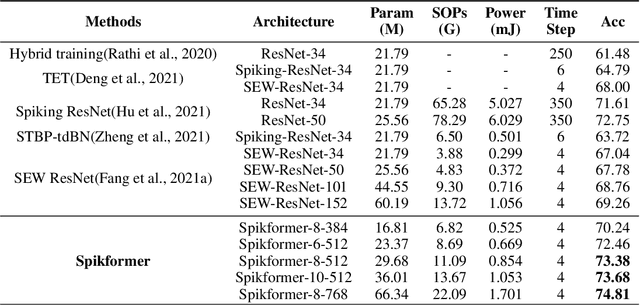
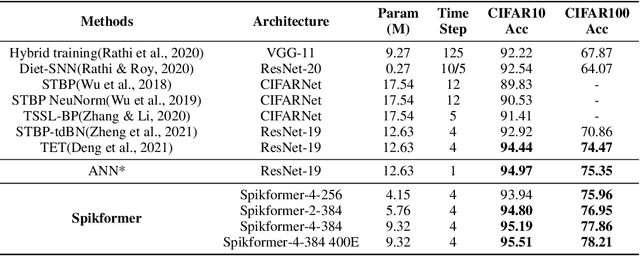
We consider two biologically plausible structures, the Spiking Neural Network (SNN) and the self-attention mechanism. The former offers an energy-efficient and event-driven paradigm for deep learning, while the latter has the ability to capture feature dependencies, enabling Transformer to achieve good performance. It is intuitively promising to explore the marriage between them. In this paper, we consider leveraging both self-attention capability and biological properties of SNNs, and propose a novel Spiking Self Attention (SSA) as well as a powerful framework, named Spiking Transformer (Spikformer). The SSA mechanism in Spikformer models the sparse visual feature by using spike-form Query, Key, and Value without softmax. Since its computation is sparse and avoids multiplication, SSA is efficient and has low computational energy consumption. It is shown that Spikformer with SSA can outperform the state-of-the-art SNNs-like frameworks in image classification on both neuromorphic and static datasets. Spikformer (66.3M parameters) with comparable size to SEW-ResNet-152 (60.2M,69.26%) can achieve 74.81% top1 accuracy on ImageNet using 4 time steps, which is the state-of-the-art in directly trained SNNs models.