 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reinforcement Learning with Automated Auxiliary Loss Search
Oct 12, 2022
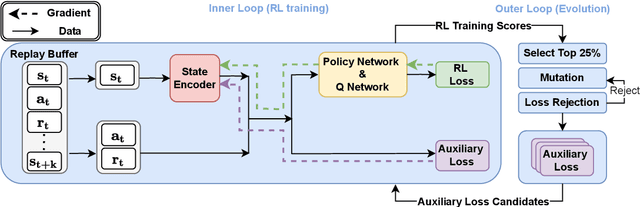

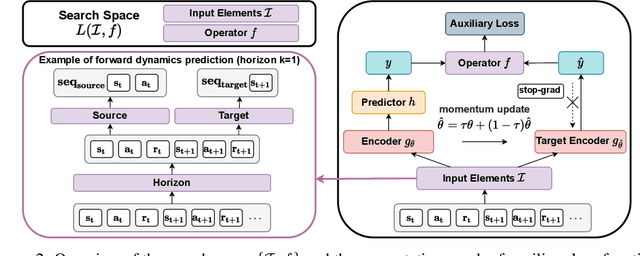
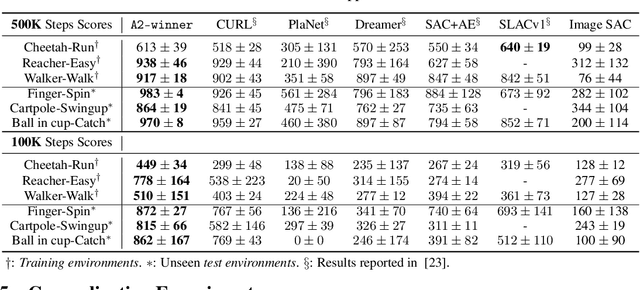
A good state representation is crucial to solving complicated reinforcement learning (RL) challenges. Many recent works focus on designing auxiliary losses for learning informative representations. Unfortunately, these handcrafted objectives rely heavily on expert knowledge and may be sub-optimal. In this paper, we propose a principled and universal method for learning better representations with auxiliary loss functions, named Automated Auxiliary Loss Search (A2LS), which automatically searches for top-performing auxiliary loss functions for RL. Specifically, based on the collected trajectory data, we define a general auxiliary loss space of size $7.5 \times 10^{20}$ and explore the space with an efficient evolutionary search strategy. Empirical results show that the discovered auxiliary loss (namely, A2-winner) significantly improves the performance on both high-dimensional (image) and low-dimensional (vector) unseen tasks with much higher efficiency, showing promising generalization ability to different settings and even different benchmark domains. We conduct a statistical analysis to reveal the relations between patterns of auxiliary losses and RL performance.
FitCLIP: Refining Large-Scale Pretrained Image-Text Models for Zero-Shot Video Understanding Tasks
Mar 24, 2022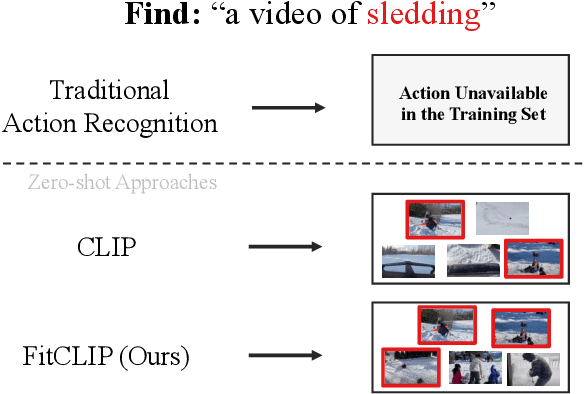
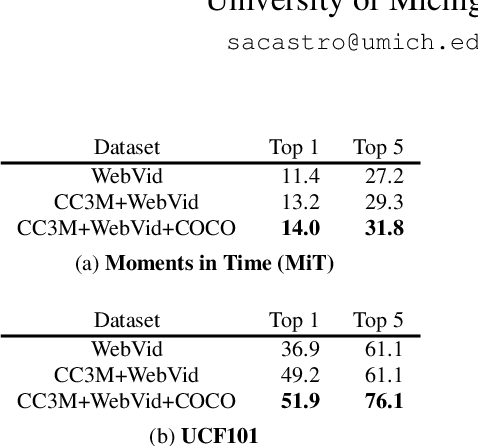
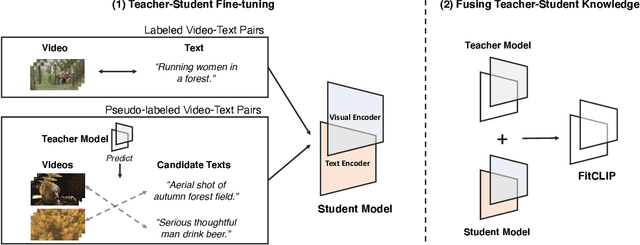
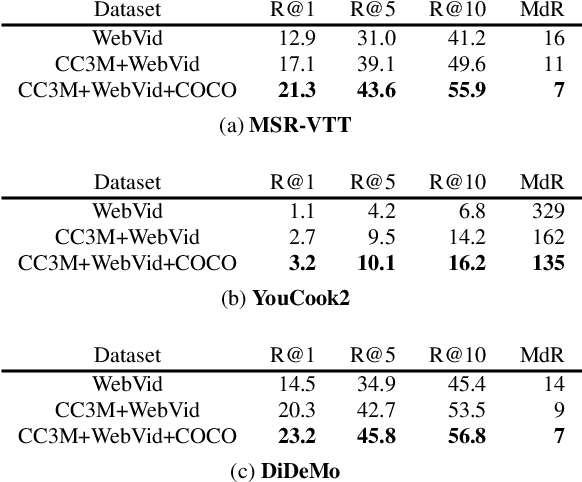
Large-scale pretrained image-text models have shown incredible zero-shot performance in a handful of tasks, including video ones such as action recognition and text-to-video retrieval. However, these models haven't been adapted to video, mainly because they don't account for the time dimension but also because video frames are different from the typical images (e.g., containing motion blur, less sharpness). In this paper, we present a fine-tuning strategy to refine these large-scale pretrained image-text models for zero-shot video understanding tasks. We show that by carefully adapting these models we obtain considerable improvements on two zero-shot Action Recognition tasks and three zero-shot Text-to-video Retrieval tasks. The code is available at https://github.com/bryant1410/fitclip
NewsStories: Illustrating articles with visual summaries
Aug 14, 2022
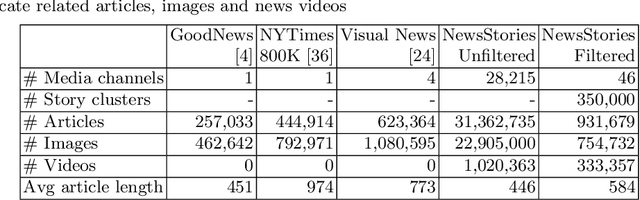
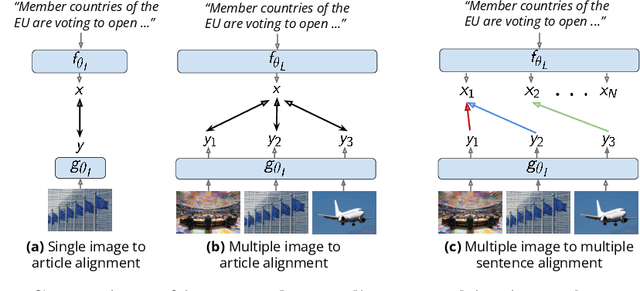
Recent self-supervised approaches have used large-scale image-text datasets to learn powerful representations that transfer to many tasks without finetuning. These methods often assume that there is one-to-one correspondence between its images and their (short) captions. However, many tasks require reasoning about multiple images and long text narratives, such as describing news articles with visual summaries. Thus, we explore a novel setting where the goal is to learn a self-supervised visual-language representation that is robust to varying text length and the number of images. In addition, unlike prior work which assumed captions have a literal relation to the image, we assume images only contain loose illustrative correspondence with the text. To explore this problem, we introduce a large-scale multimodal dataset containing over 31M articles, 22M images and 1M videos. We show that state-of-the-art image-text alignment methods are not robust to longer narratives with multiple images. Finally, we introduce an intuitive baseline that outperforms these methods on zero-shot image-set retrieval by 10% on the GoodNews dataset.
Feature Selective Transformer for Semantic Image Segmentation
Apr 01, 2022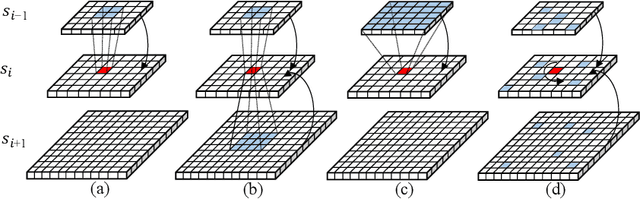
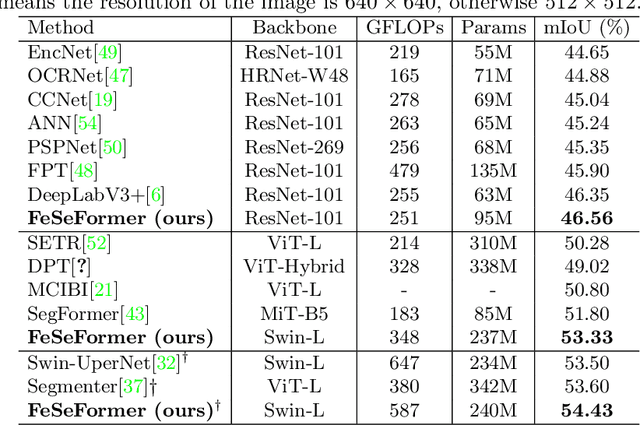
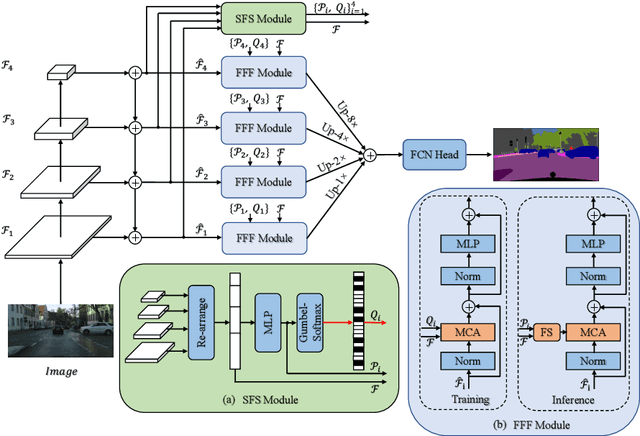
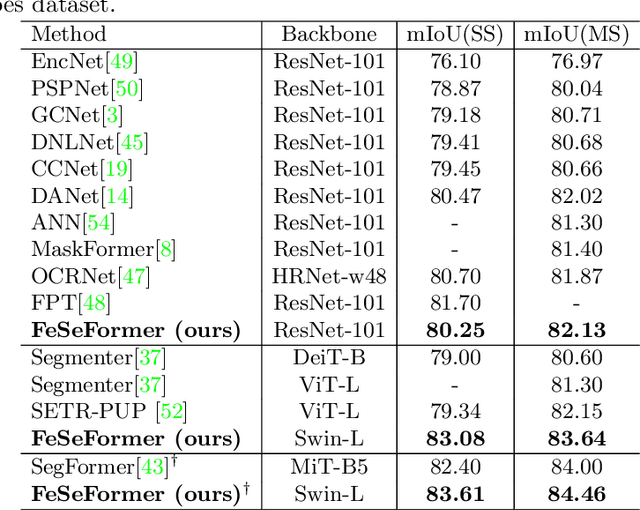
Recently, it has attracted more and more attentions to fuse multi-scale features for semantic image segmentation. Various works were proposed to employ progressive local or global fusion, but the feature fusions are not rich enough for modeling multi-scale context features. In this work, we focus on fusing multi-scale features from Transformer-based backbones for semantic segmentation, and propose a Feature Selective Transformer (FeSeFormer), which aggregates features from all scales (or levels) for each query feature. Specifically, we first propose a Scale-level Feature Selection (SFS) module, which can choose an informative subset from the whole multi-scale feature set for each scale, where those features that are important for the current scale (or level) are selected and the redundant are discarded. Furthermore, we propose a Full-scale Feature Fusion (FFF) module, which can adaptively fuse features of all scales for queries. Based on the proposed SFS and FFF modules, we develop a Feature Selective Transformer (FeSeFormer), and evaluate our FeSeFormer on four challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K, COCO-Stuff 10K, and Cityscapes, outperforming the state-of-the-art.
Fluorescence molecular optomic signatures improve identification of tumors in head and neck specimens
Aug 29, 2022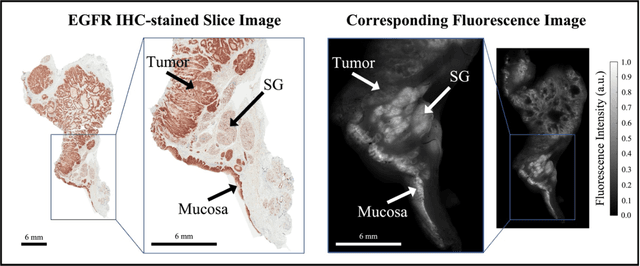
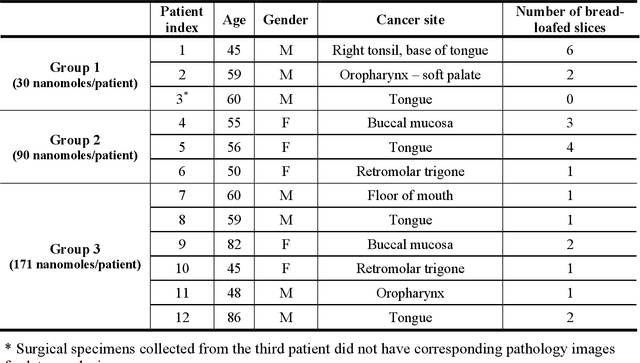
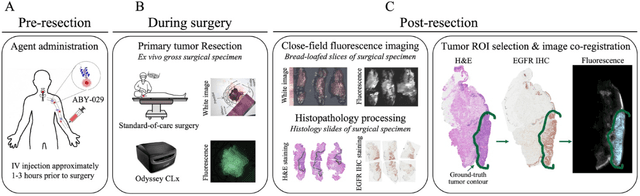
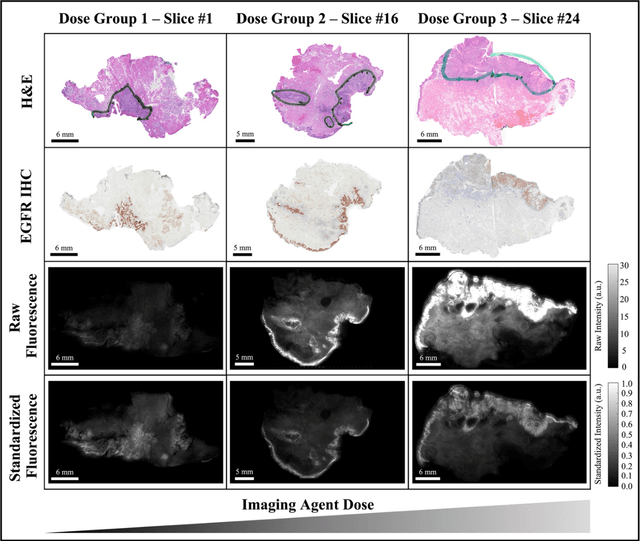
In this study, a radiomics approach was extended to optical fluorescence molecular imaging data for tissue classification, termed 'optomics'. Fluorescence molecular imaging is emerging for precise surgical guidance during head and neck squamous cell carcinoma (HNSCC) resection. However, the tumor-to-normal tissue contrast is confounded by intrinsic physiological limitations of heterogeneous expression of the target molecule, epidermal growth factor receptor (EGFR). Optomics seek to improve tumor identification by probing textural pattern differences in EGFR expression conveyed by fluorescence. A total of 1,472 standardized optomic features were extracted from fluorescence image samples. A supervised machine learning pipeline involving a support vector machine classifier was trained with 25 top-ranked features selected by minimum redundancy maximum relevance criterion. Model predictive performance was compared to fluorescence intensity thresholding method by classifying testing set image patches of resected tissue with histologically confirmed malignancy status. The optomics approach provided consistent improvement in prediction accuracy on all test set samples, irrespective of dose, compared to fluorescence intensity thresholding method (mean accuracies of 89% vs. 81%; P = 0.0072). The improved performance demonstrates that extending the radiomics approach to fluorescence molecular imaging data offers a promising image analysis technique for cancer detection in fluorescence-guided surgery.
Vit-GAN: Image-to-image Translation with Vision Transformes and Conditional GANS
Oct 11, 2021



In this paper, we have developed a general-purpose architecture, Vit-Gan, capable of performing most of the image-to-image translation tasks from semantic image segmentation to single image depth perception. This paper is a follow-up paper, an extension of generator-based model [1] in which the obtained results were very promising. This opened the possibility of further improvements with adversarial architecture. We used a unique vision transformers-based generator architecture and Conditional GANs(cGANs) with a Markovian Discriminator (PatchGAN) (https://github.com/YigitGunduc/vit-gan). In the present work, we use images as conditioning arguments. It is observed that the obtained results are more realistic than the commonly used architectures.
L-Verse: Bidirectional Generation Between Image and Text
Nov 22, 2021
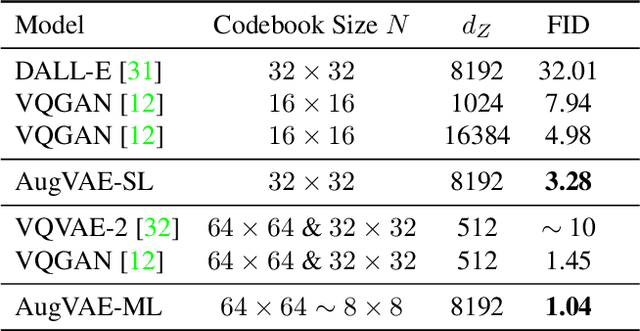
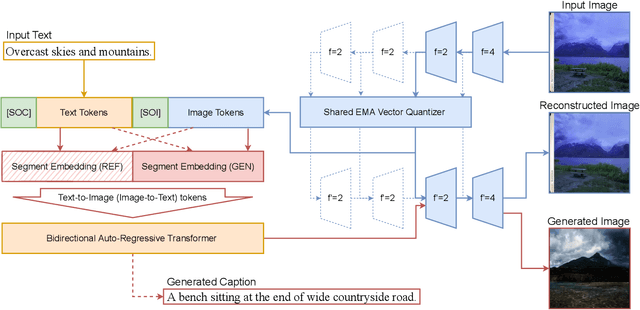
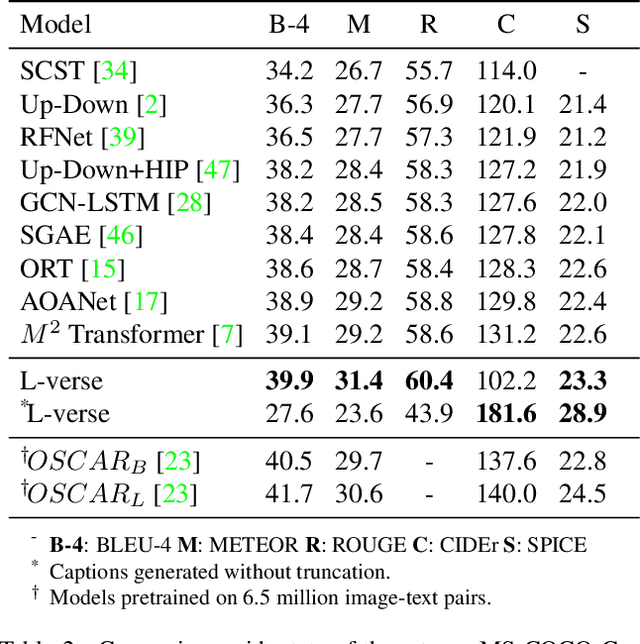
Far beyond learning long-range interactions of natural language, transformers are becoming the de-facto standard for many vision tasks with their power and scalabilty. Especially with cross-modal tasks between image and text, vector quantized variational autoencoders (VQ-VAEs) are widely used to make a raw RGB image into a sequence of feature vectors. To better leverage the correlation between image and text, we propose L-Verse, a novel architecture consisting of feature-augmented variational autoencoder (AugVAE) and bidirectional auto-regressive transformer (BiART) for text-to-image and image-to-text generation. Our AugVAE shows the state-of-the-art reconstruction performance on ImageNet1K validation set, along with the robustness to unseen images in the wild. Unlike other models, BiART can distinguish between image (or text) as a conditional reference and a generation target. L-Verse can be directly used for image-to-text or text-to-image generation tasks without any finetuning or extra object detection frameworks. In quantitative and qualitative experiments, L-Verse shows impressive results against previous methods in both image-to-text and text-to-image generation on MS-COCO Captions. We furthermore assess the scalability of L-Verse architecture on Conceptual Captions and present the initial results of bidirectional vision-language representation learning on general domain. Codes available at: https://github.com/tgisaturday/L-Verse
Self-Improving SLAM in Dynamic Environments: Learning When to Mask
Oct 15, 2022
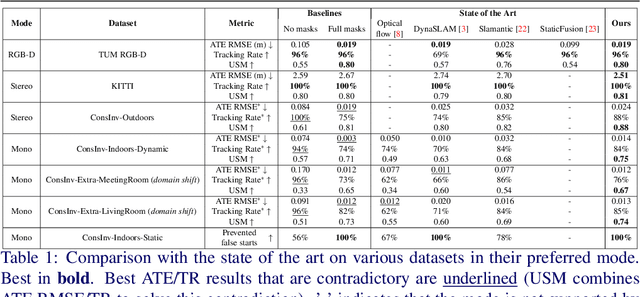
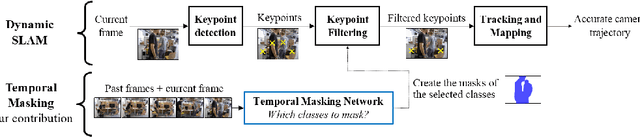

Visual SLAM -- Simultaneous Localization and Mapping -- in dynamic environments typically relies on identifying and masking image features on moving objects to prevent them from negatively affecting performance. Current approaches are suboptimal: they either fail to mask objects when needed or, on the contrary, mask objects needlessly. Thus, we propose a novel SLAM that learns when masking objects improves its performance in dynamic scenarios. Given a method to segment objects and a SLAM, we give the latter the ability of Temporal Masking, i.e., to infer when certain classes of objects should be masked to maximize any given SLAM metric. We do not make any priors on motion: our method learns to mask moving objects by itself. To prevent high annotations costs, we created an automatic annotation method for self-supervised training. We constructed a new dataset, named ConsInv, which includes challenging real-world dynamic sequences respectively indoors and outdoors. Our method reaches the state of the art on the TUM RGB-D dataset and outperforms it on KITTI and ConsInv datasets.
HUDD: A tool to debug DNNs for safety analysis
Oct 15, 2022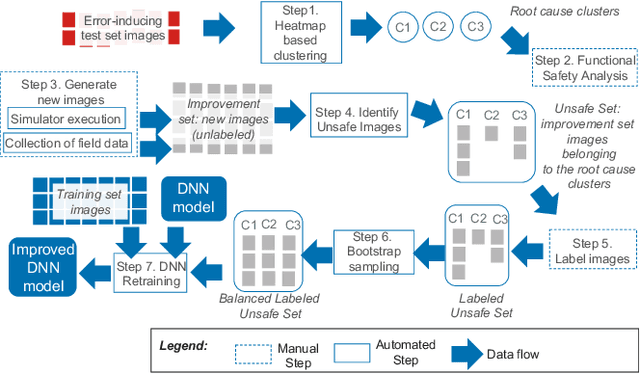
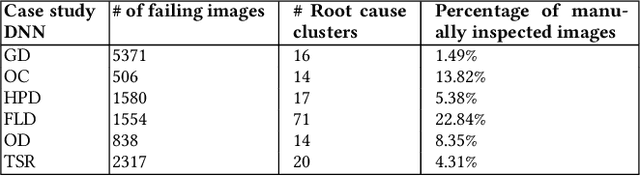
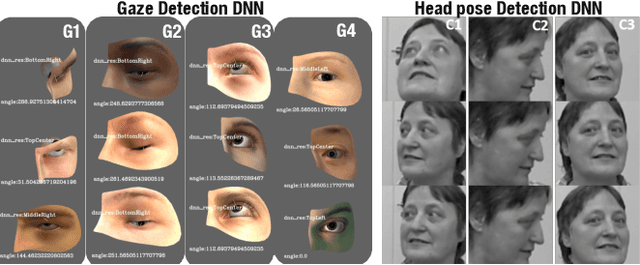
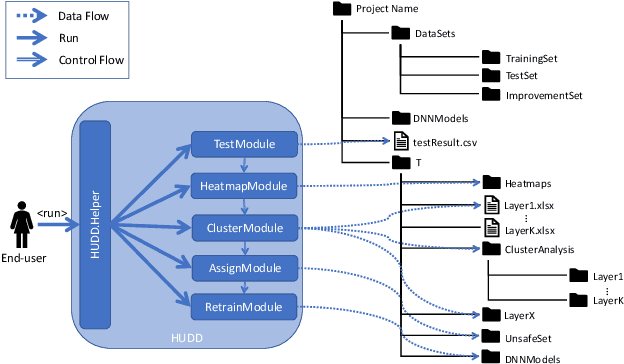
We present HUDD, a tool that supports safety analysis practices for systems enabled by Deep Neural Networks (DNNs) by automatically identifying the root causes for DNN errors and retraining the DNN. HUDD stands for Heatmap-based Unsupervised Debugging of DNNs, it automatically clusters error-inducing images whose results are due to common subsets of DNN neurons. The intent is for the generated clusters to group error-inducing images having common characteristics, that is, having a common root cause. HUDD identifies root causes by applying a clustering algorithm to matrices (i.e., heatmaps) capturing the relevance of every DNN neuron on the DNN outcome. Also, HUDD retrains DNNs with images that are automatically selected based on their relatedness to the identified image clusters. Our empirical evaluation with DNNs from the automotive domain have shown that HUDD automatically identifies all the distinct root causes of DNN errors, thus supporting safety analysis. Also, our retraining approach has shown to be more effective at improving DNN accuracy than existing approaches. A demo video of HUDD is available at https://youtu.be/drjVakP7jdU.
Universal Efficient Variable-rate Neural Image Compression
Dec 01, 2021
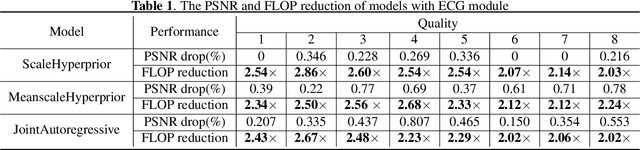
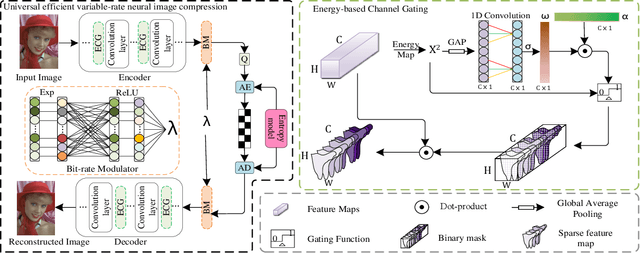
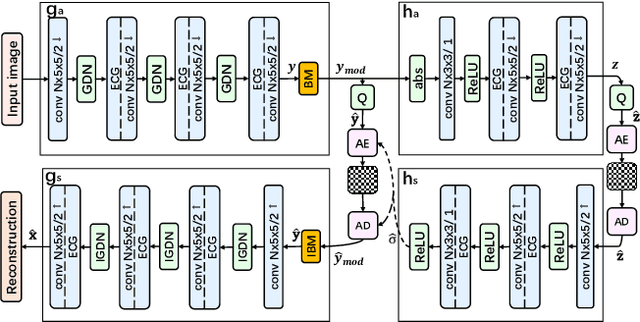
Recently, Learning-based image compression has reached comparable performance with traditional image codecs(such as JPEG, BPG, WebP). However, computational complexity and rate flexibility are still two major challenges for its practical deployment. To tackle these problems, this paper proposes two universal modules named Energy-based Channel Gating(ECG) and Bit-rate Modulator(BM), which can be directly embedded into existing end-to-end image compression models. ECG uses dynamic pruning to reduce FLOPs for more than 50\% in convolution layers, and a BM pair can modulate the latent representation to control the bit-rate in a channel-wise manner. By implementing these two modules, existing learning-based image codecs can obtain ability to output arbitrary bit-rate with a single model and reduced computation.