 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Screen-Shooting Resilient Document Image Watermarking Scheme using Deep Neural Network
Mar 10, 2022
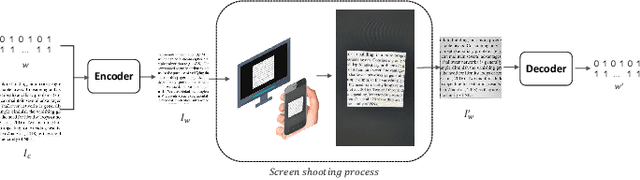
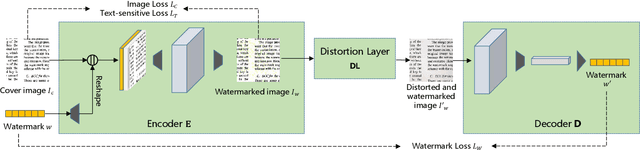
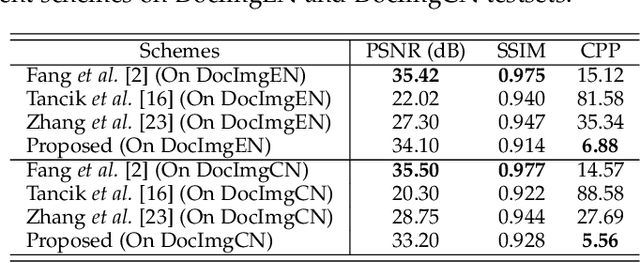
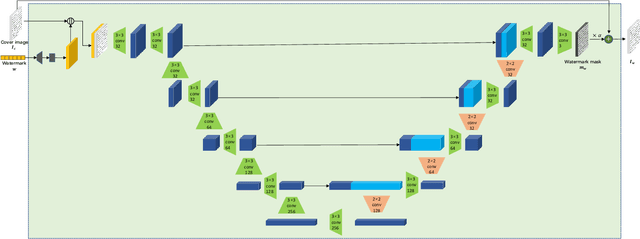
With the advent of the screen-reading era, the confidential documents displayed on the screen can be easily captured by a camera without leaving any traces. Thus, this paper proposes a novel screen-shooting resilient watermarking scheme for document image using deep neural network. By applying this scheme, when the watermarked image is displayed on the screen and captured by a camera, the watermark can be still extracted from the captured photographs. Specifically, our scheme is an end-to-end neural network with an encoder to embed watermark and a decoder to extract watermark. During the training process, a distortion layer between encoder and decoder is added to simulate the distortions introduced by screen-shooting process in real scenes, such as camera distortion, shooting distortion, light source distortion. Besides, an embedding strength adjustment strategy is designed to improve the visual quality of the watermarked image with little loss of extraction accuracy. The experimental results show that the scheme has higher robustness and visual quality than other three recent state-of-the-arts. Specially, even if the shooting distances and angles are in extreme, our scheme can also obtain high extraction accuracy.
Vector Quantized Diffusion Model for Text-to-Image Synthesis
Dec 20, 2021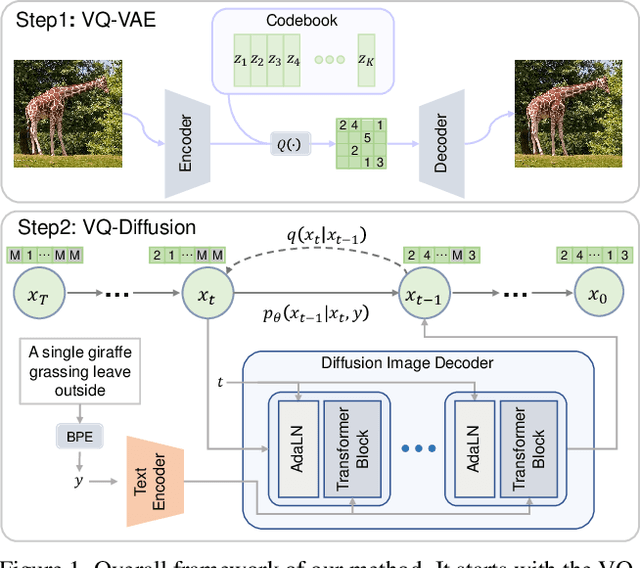
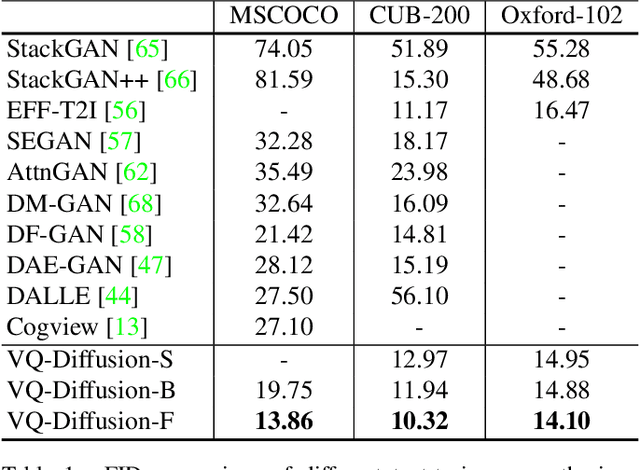

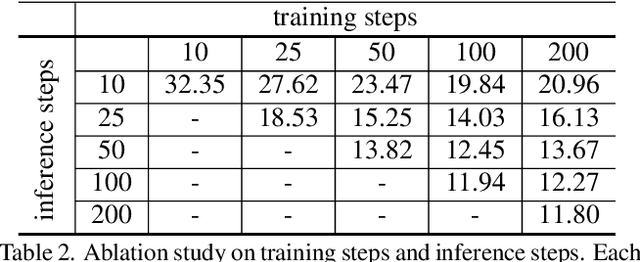
We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
A Comparative Attention Framework for Better Few-Shot Object Detection on Aerial Images
Oct 25, 2022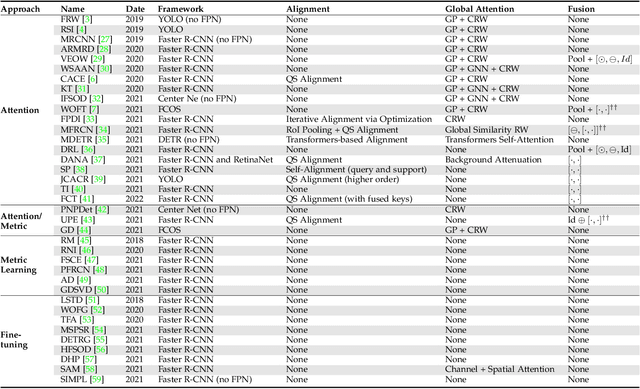
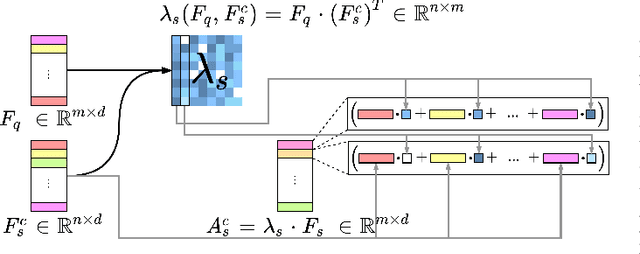
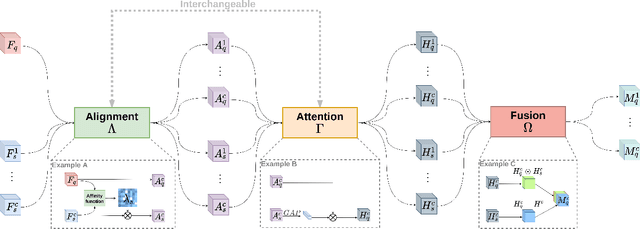

Few-Shot Object Detection (FSOD) methods are mainly designed and evaluated on natural image datasets such as Pascal VOC and MS COCO. However, it is not clear whether the best methods for natural images are also the best for aerial images. Furthermore, direct comparison of performance between FSOD methods is difficult due to the wide variety of detection frameworks and training strategies. Therefore, we propose a benchmarking framework that provides a flexible environment to implement and compare attention-based FSOD methods. The proposed framework focuses on attention mechanisms and is divided into three modules: spatial alignment, global attention, and fusion layer. To remain competitive with existing methods, which often leverage complex training, we propose new augmentation techniques designed for object detection. Using this framework, several FSOD methods are reimplemented and compared. This comparison highlights two distinct performance regimes on aerial and natural images: FSOD performs worse on aerial images. Our experiments suggest that small objects, which are harder to detect in the few-shot setting, account for the poor performance. Finally, we develop a novel multiscale alignment method, Cross-Scales Query-Support Alignment (XQSA) for FSOD, to improve the detection of small objects. XQSA outperforms the state-of-the-art significantly on DOTA and DIOR.
MonoDVPS: A Self-Supervised Monocular Depth Estimation Approach to Depth-aware Video Panoptic Segmentation
Oct 14, 2022


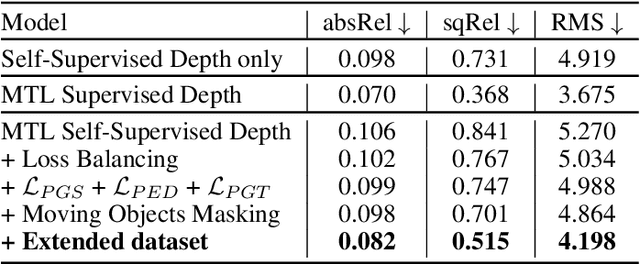
Depth-aware video panoptic segmentation tackles the inverse projection problem of restoring panoptic 3D point clouds from video sequences, where the 3D points are augmented with semantic classes and temporally consistent instance identifiers. We propose a novel solution with a multi-task network that performs monocular depth estimation and video panoptic segmentation. Since acquiring ground truth labels for both depth and image segmentation has a relatively large cost, we leverage the power of unlabeled video sequences with self-supervised monocular depth estimation and semi-supervised learning from pseudo-labels for video panoptic segmentation. To further improve the depth prediction, we introduce panoptic-guided depth losses and a novel panoptic masking scheme for moving objects to avoid corrupting the training signal. Extensive experiments on the Cityscapes-DVPS and SemKITTI-DVPS datasets demonstrate that our model with the proposed improvements achieves competitive results and fast inference speed.
TokenMixup: Efficient Attention-guided Token-level Data Augmentation for Transformers
Oct 14, 2022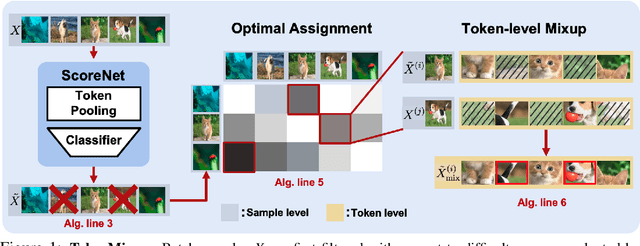
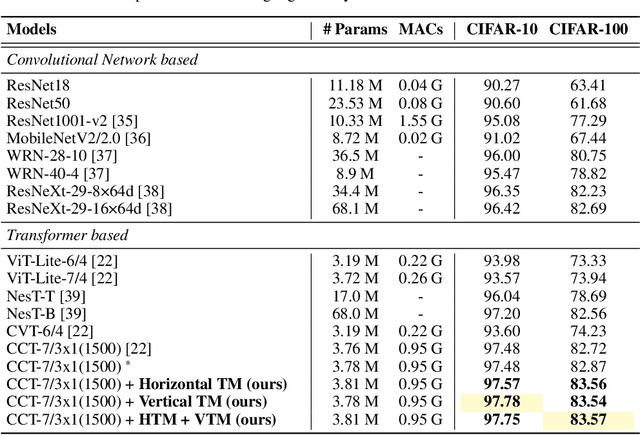
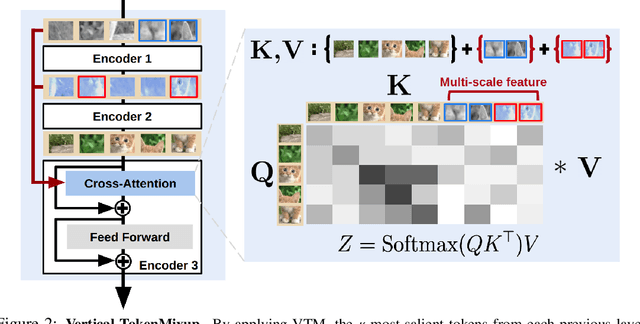
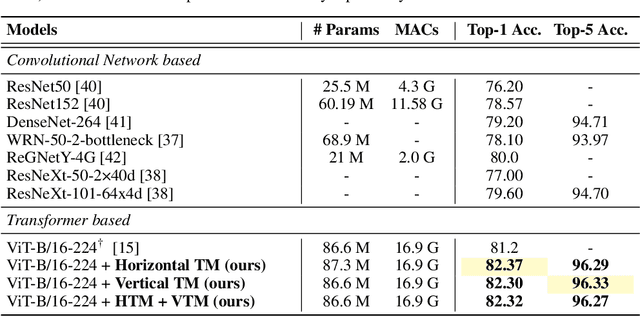
Mixup is a commonly adopted data augmentation technique for image classification. Recent advances in mixup methods primarily focus on mixing based on saliency. However, many saliency detectors require intense computation and are especially burdensome for parameter-heavy transformer models. To this end, we propose TokenMixup, an efficient attention-guided token-level data augmentation method that aims to maximize the saliency of a mixed set of tokens. TokenMixup provides x15 faster saliency-aware data augmentation compared to gradient-based methods. Moreover, we introduce a variant of TokenMixup which mixes tokens within a single instance, thereby enabling multi-scale feature augmentation. Experiments show that our methods significantly improve the baseline models' performance on CIFAR and ImageNet-1K, while being more efficient than previous methods. We also reach state-of-the-art performance on CIFAR-100 among from-scratch transformer models. Code is available at https://github.com/mlvlab/TokenMixup.
CoV-TI-Net: Transferred Initialization with Modified End Layer for COVID-19 Diagnosis
Sep 20, 2022
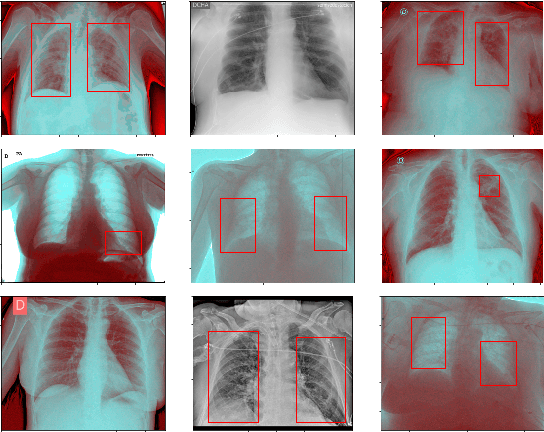
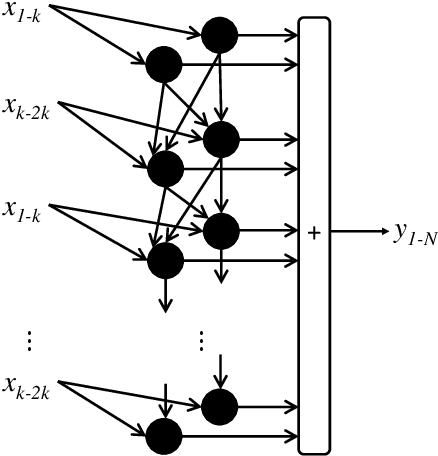
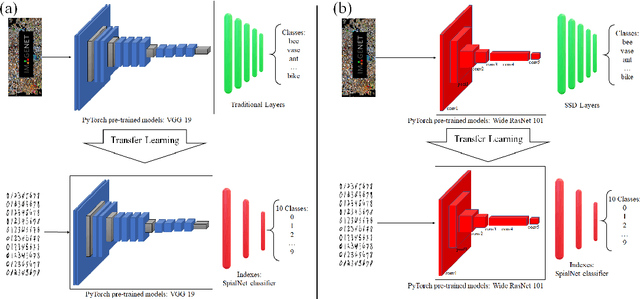
This paper proposes transferred initialization with modified fully connected layers for COVID-19 diagnosis. Convolutional neural networks (CNN) achieved a remarkable result in image classification. However, training a high-performing model is a very complicated and time-consuming process because of the complexity of image recognition applications. On the other hand, transfer learning is a relatively new learning method that has been employed in many sectors to achieve good performance with fewer computations. In this research, the PyTorch pre-trained models (VGG19\_bn and WideResNet -101) are applied in the MNIST dataset for the first time as initialization and with modified fully connected layers. The employed PyTorch pre-trained models were previously trained in ImageNet. The proposed model is developed and verified in the Kaggle notebook, and it reached the outstanding accuracy of 99.77% without taking a huge computational time during the training process of the network. We also applied the same methodology to the SIIM-FISABIO-RSNA COVID-19 Detection dataset and achieved 80.01% accuracy. In contrast, the previous methods need a huge compactional time during the training process to reach a high-performing model. Codes are available at the following link: github.com/dipuk0506/SpinalNet
MLSeg: Image and Video Segmentation as Multi-Label Classification and Selected-Label Pixel Classification
Mar 08, 2022

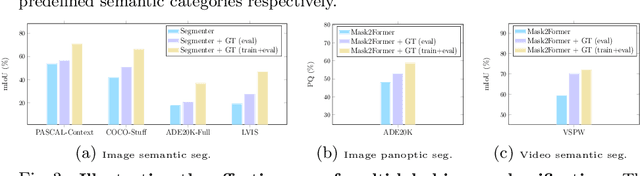
For a long period of time, research studies on segmentation have typically formulated the task as pixel classification that predicts a class for each pixel from a set of predefined, fixed number of semantic categories. Yet standard architectures following this formulation will inevitably encounter various challenges under more realistic settings where the total number of semantic categories scales up (e.g., beyond $1\rm{k}$ classes). On the other hand, a standard image or video usually contains only a small number of semantic categories from the entire label set. Motivated by this intuition, in this paper, we propose to decompose segmentation into two sub-problems: (i) image-level or video-level multi-label classification and (ii) pixel-level selected-label classification. Given an input image or video, our framework first conducts multi-label classification over the large complete label set and selects a small set of labels according to the class confidence scores. Then the follow-up pixel-wise classification is only performed among the selected subset of labels. Our approach is conceptually general and can be applied to various existing segmentation frameworks by simply adding a lightweight multi-label classification branch. We demonstrate the effectiveness of our framework with competitive experimental results across four tasks including image semantic segmentation, image panoptic segmentation, video instance segmentation, and video semantic segmentation. Especially, with our MLSeg, Mask$2$Former gains +$0.8\%$/+$0.7\%$/+$0.7\%$ on ADE$20$K panoptic segmentation/YouTubeVIS $2019$ video instance segmentation/VSPW video semantic segmentation benchmarks respectively. Code will be available at:https://github.com/openseg-group/MLSeg
UDepth: Fast Monocular Depth Estimation for Visually-guided Underwater Robots
Sep 26, 2022
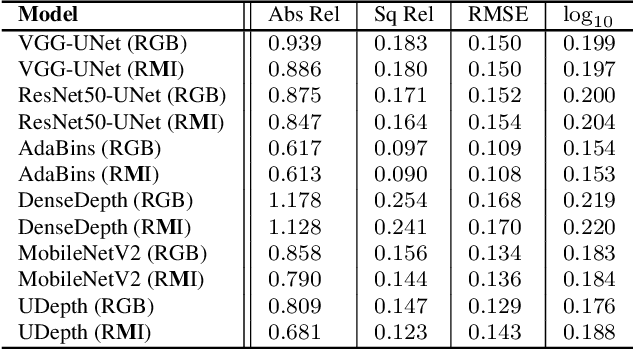
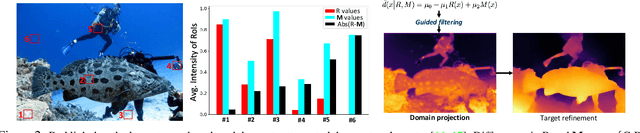
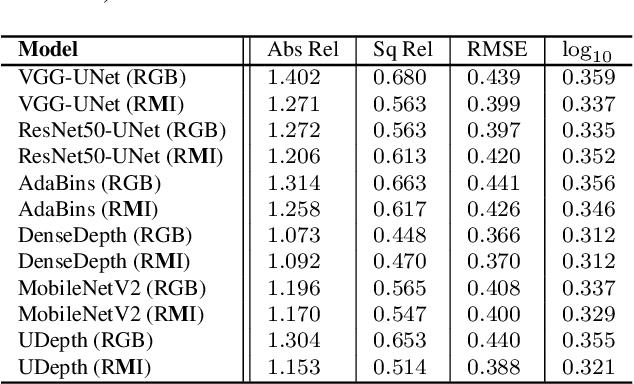
In this paper, we present a fast monocular depth estimation method for enabling 3D perception capabilities of low-cost underwater robots. We formulate a novel end-to-end deep visual learning pipeline named UDepth, which incorporates domain knowledge of image formation characteristics of natural underwater scenes. First, we adapt a new input space from raw RGB image space by exploiting underwater light attenuation prior, and then devise a least-squared formulation for coarse pixel-wise depth prediction. Subsequently, we extend this into a domain projection loss that guides the end-to-end learning of UDepth on over 9K RGB-D training samples. UDepth is designed with a computationally light MobileNetV2 backbone and a Transformer-based optimizer for ensuring fast inference rates on embedded systems. By domain-aware design choices and through comprehensive experimental analyses, we demonstrate that it is possible to achieve state-of-the-art depth estimation performance while ensuring a small computational footprint. Specifically, with 70%-80% less network parameters than existing benchmarks, UDepth achieves comparable and often better depth estimation performance. While the full model offers over 66 FPS (13 FPS) inference rates on a single GPU (CPU core), our domain projection for coarse depth prediction runs at 51.5 FPS rates on single-board NVIDIA Jetson TX2s. The inference pipelines are available at https://github.com/uf-robopi/UDepth.
Pseudo-LiDAR for Visual Odometry
Sep 04, 2022
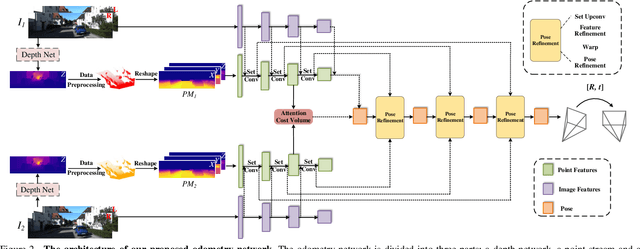
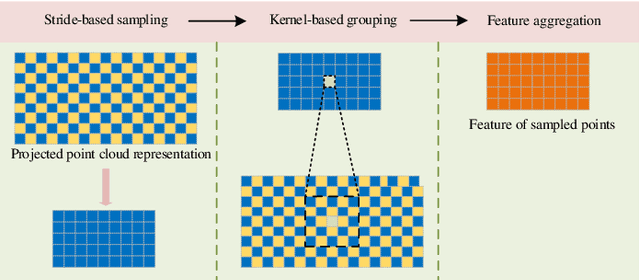
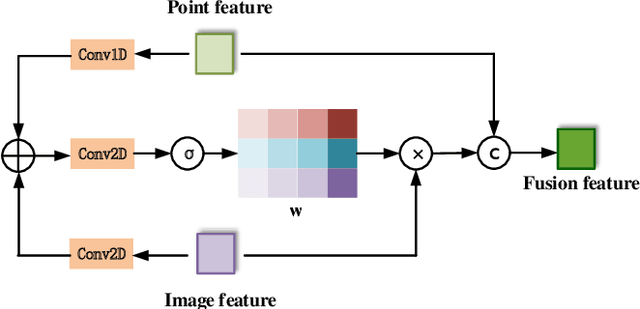
In the existing methods, LiDAR odometry shows superior performance, but visual odometry is still widely used for its price advantage. Conventionally, the task of visual odometry mainly rely on the input of continuous images. However, it is very complicated for the odometry network to learn the epipolar geometry information provided by the images. In this paper, the concept of pseudo-LiDAR is introduced into the odometry to solve this problem. The pseudo-LiDAR point cloud back-projects the depth map generated by the image into the 3D point cloud, which changes the way of image representation. Compared with the stereo images, the pseudo-LiDAR point cloud generated by the stereo matching network can get the explicit 3D coordinates. Since the 6 Degrees of Freedom (DoF) pose transformation occurs in 3D space, the 3D structure information provided by the pseudo-LiDAR point cloud is more direct than the image. Compared with sparse LiDAR, the pseudo-LiDAR has a denser point cloud. In order to make full use of the rich point cloud information provided by the pseudo-LiDAR, a projection-aware dense odometry pipeline is adopted. Most previous LiDAR-based algorithms sampled 8192 points from the point cloud as input to the odometry network. The projection-aware dense odometry pipeline takes all the pseudo-LiDAR point clouds generated from the images except for the error points as the input to the network. While making full use of the 3D geometric information in the images, the semantic information in the images is also used in the odometry task. The fusion of 2D-3D is achieved in an image-only based odometry. Experiments on the KITTI dataset prove the effectiveness of our method. To the best of our knowledge, this is the first visual odometry method using pseudo-LiDAR.
Carbon Footprint of Selecting and Training Deep Learning Models for Medical Image Analysis
Mar 04, 2022

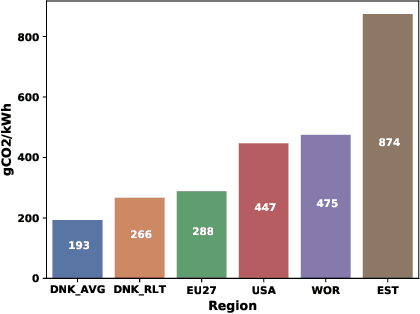

The increasing energy consumption and carbon footprint of deep learning (DL) due to growing compute requirements has become a cause of concern. In this work, we focus on the carbon footprint of developing DL models for medical image analysis (MIA), where volumetric images of high spatial resolution are handled. In this study, we present and compare the features of four tools from literature to quantify the carbon footprint of DL. Using one of these tools we estimate the carbon footprint of medical image segmentation pipelines. We choose nnU-net as the proxy for a medical image segmentation pipeline and experiment on three common datasets. With our work we hope to inform on the increasing energy costs incurred by MIA. We discuss simple strategies to cut-down the environmental impact that can make model selection and training processes more efficient.