 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LWA-HAND: Lightweight Attention Hand for Interacting Hand Reconstruction
Aug 23, 2022
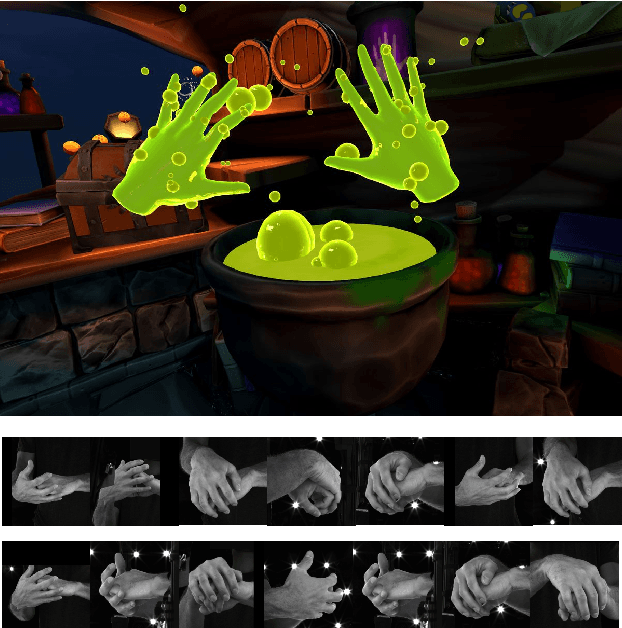

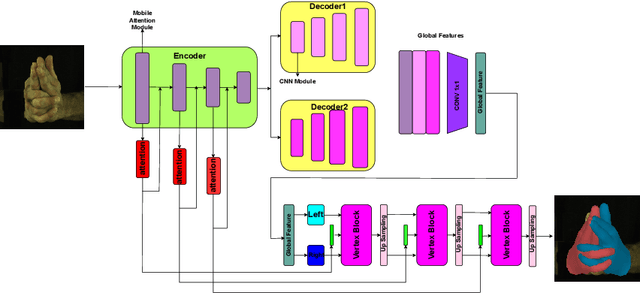

Hand reconstruction has achieved great success in real-time applications such as visual reality and augmented reality while interacting with two-hand reconstruction through efficient transformers is left unexplored. In this paper, we propose a method called lightweight attention hand (LWA-HAND) to reconstruct hands in low flops from a single RGB image. To solve the occlusion and interaction challenges in efficient attention architectures, we introduce three mobile attention modules. The first module is a lightweight feature attention module that extracts both local occlusion representation and global image patch representation in a coarse-to-fine manner. The second module is a cross image and graph bridge module which fuses image context and hand vertex. The third module is a lightweight cross-attention mechanism that uses element-wise operation for cross attention of two hands in linear complexity. The resulting model achieves comparable performance on the InterHand2.6M benchmark in comparison with the state-of-the-art models. Simultaneously, it reduces the flops to $0.47GFlops$ while the state-of-the-art models have heavy computations between $10GFlops$ and $20GFlops$.
Grafting Vision Transformers
Oct 28, 2022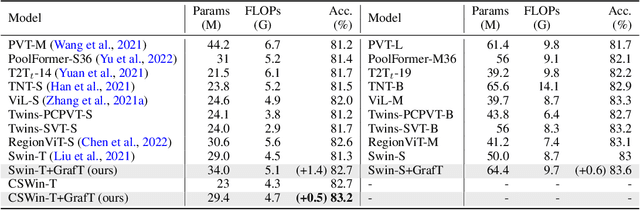
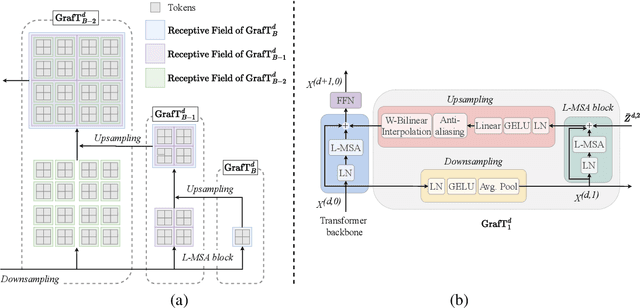
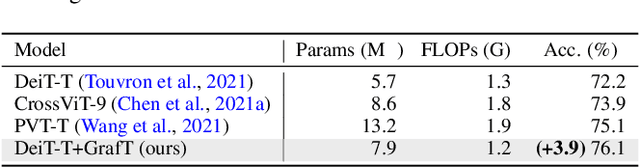
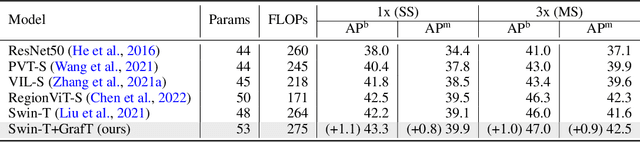
Vision Transformers (ViTs) have recently become the state-of-the-art across many computer vision tasks. In contrast to convolutional networks (CNNs), ViTs enable global information sharing even within shallow layers of a network, i.e., among high-resolution features. However, this perk was later overlooked with the success of pyramid architectures such as Swin Transformer, which show better performance-complexity trade-offs. In this paper, we present a simple and efficient add-on component (termed GrafT) that considers global dependencies and multi-scale information throughout the network, in both high- and low-resolution features alike. GrafT can be easily adopted in both homogeneous and pyramid Transformers while showing consistent gains. It has the flexibility of branching-out at arbitrary depths, widening a network with multiple scales. This grafting operation enables us to share most of the parameters and computations of the backbone, adding only minimal complexity, but with a higher yield. In fact, the process of progressively compounding multi-scale receptive fields in GrafT enables communications between local regions. We show the benefits of the proposed method on multiple benchmarks, including image classification (ImageNet-1K), semantic segmentation (ADE20K), object detection and instance segmentation (COCO2017). Our code and models will be made available.
VLT: Vision-Language Transformer and Query Generation for Referring Segmentation
Oct 28, 2022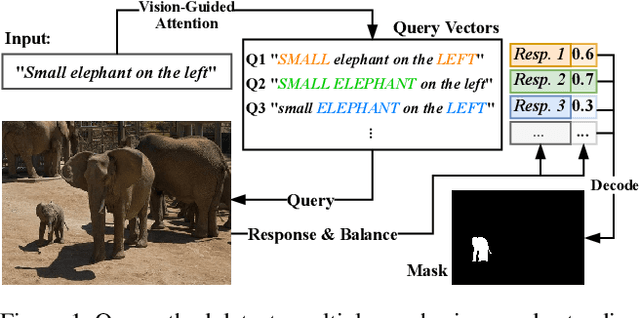
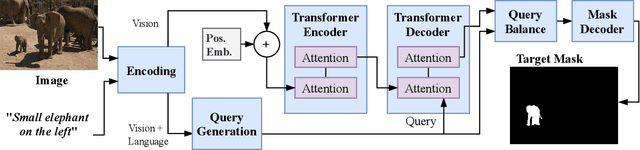

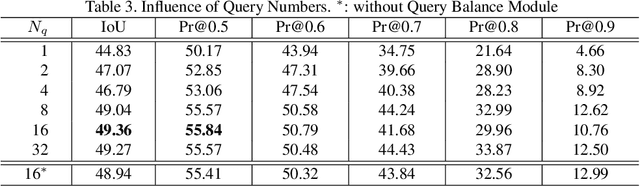
We propose a Vision-Language Transformer (VLT) framework for referring segmentation to facilitate deep interactions among multi-modal information and enhance the holistic understanding to vision-language features. There are different ways to understand the dynamic emphasis of a language expression, especially when interacting with the image. However, the learned queries in existing transformer works are fixed after training, which cannot cope with the randomness and huge diversity of the language expressions. To address this issue, we propose a Query Generation Module, which dynamically produces multiple sets of input-specific queries to represent the diverse comprehensions of language expression. To find the best among these diverse comprehensions, so as to generate a better mask, we propose a Query Balance Module to selectively fuse the corresponding responses of the set of queries. Furthermore, to enhance the model's ability in dealing with diverse language expressions, we consider inter-sample learning to explicitly endow the model with knowledge of understanding different language expressions to the same object. We introduce masked contrastive learning to narrow down the features of different expressions for the same target object while distinguishing the features of different objects. The proposed approach is lightweight and achieves new state-of-the-art referring segmentation results consistently on five datasets.
Imbalanced Data Classification via Generative Adversarial Network with Application to Anomaly Detection in Additive Manufacturing Process
Oct 28, 2022
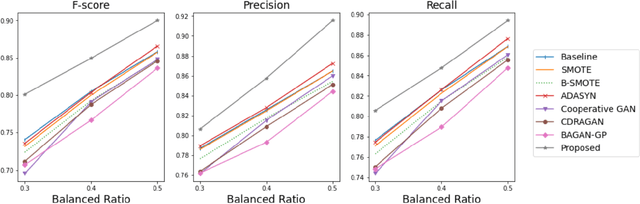

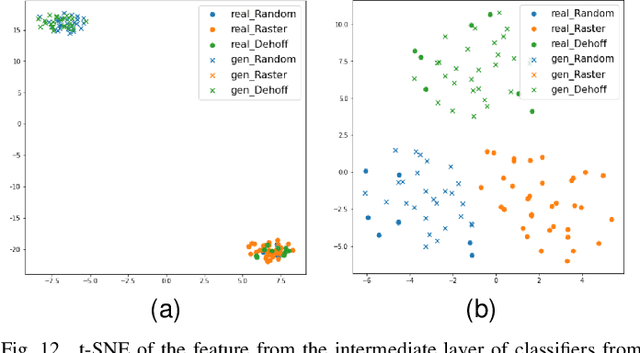
Supervised classification methods have been widely utilized for the quality assurance of the advanced manufacturing process, such as additive manufacturing (AM) for anomaly (defects) detection. However, since abnormal states (with defects) occur much less frequently than normal ones (without defects) in the manufacturing process, the number of sensor data samples collected from a normal state outweighs that from an abnormal state. This issue causes imbalanced training data for classification models, thus deteriorating the performance of detecting abnormal states in the process. It is beneficial to generate effective artificial sample data for the abnormal states to make a more balanced training set. To achieve this goal, this paper proposes a novel data augmentation method based on a generative adversarial network (GAN) using additive manufacturing process image sensor data. The novelty of our approach is that a standard GAN and classifier are jointly optimized with techniques to stabilize the learning process of standard GAN. The diverse and high-quality generated samples provide balanced training data to the classifier. The iterative optimization between GAN and classifier provides the high-performance classifier. The effectiveness of the proposed method is validated by both open-source data and real-world case studies in polymer and metal AM processes.
Deep Constrained Least Squares for Blind Image Super-Resolution
Feb 15, 2022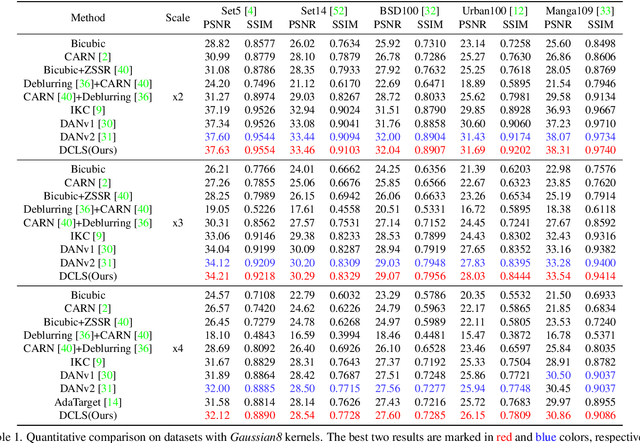

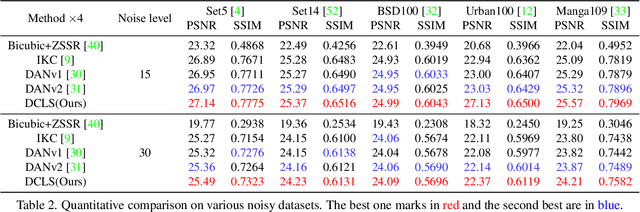
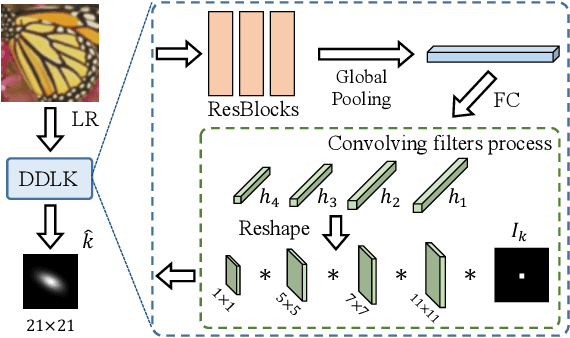
In this paper, we tackle the problem of blind image super-resolution(SR) with a reformulated degradation model and two novel modules. Following the common practices of blind SR, our method proposes to improve both the kernel estimation as well as the kernel based high resolution image restoration. To be more specific, we first reformulate the degradation model such that the deblurring kernel estimation can be transferred into the low resolution space. On top of this, we introduce a dynamic deep linear filter module. Instead of learning a fixed kernel for all images, it can adaptively generate deblurring kernel weights conditional on the input and yields more robust kernel estimation. Subsequently, a deep constrained least square filtering module is applied to generate clean features based on the reformulation and estimated kernel. The deblurred feature and the low input image feature are then fed into a dual-path structured SR network and restore the final high resolution result. To evaluate our method, we further conduct evaluations on several benchmarks, including Gaussian8 and DIV2KRK. Our experiments demonstrate that the proposed method achieves better accuracy and visual improvements against state-of-the-art methods.
OpenGlue: Open Source Graph Neural Net Based Pipeline for Image Matching
Apr 19, 2022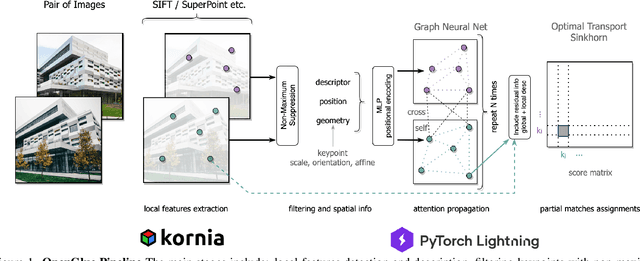
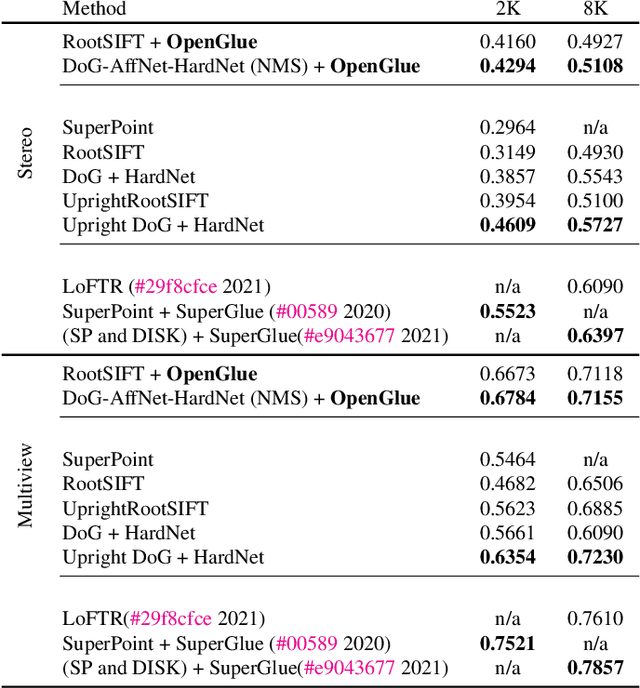
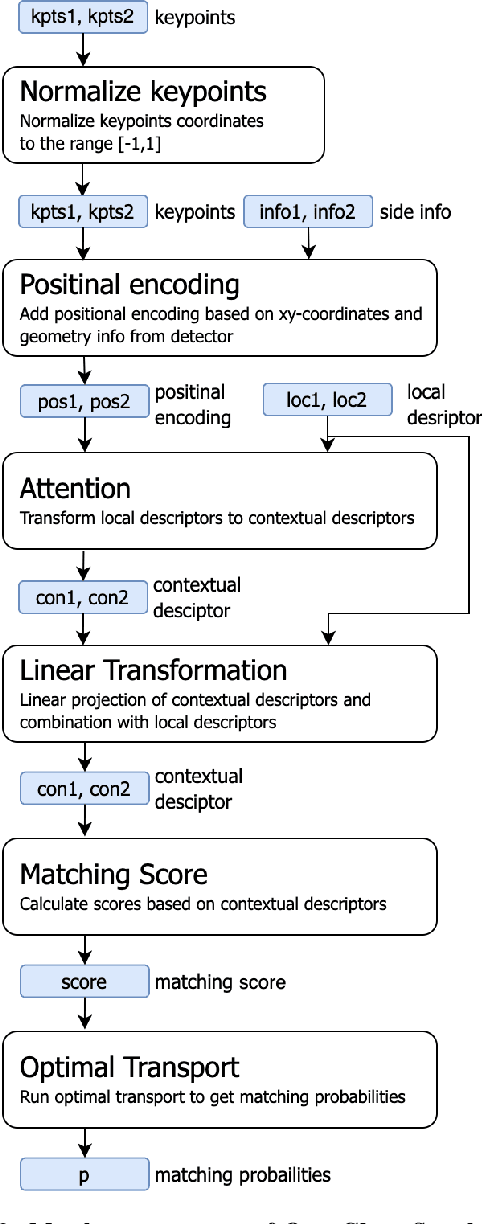
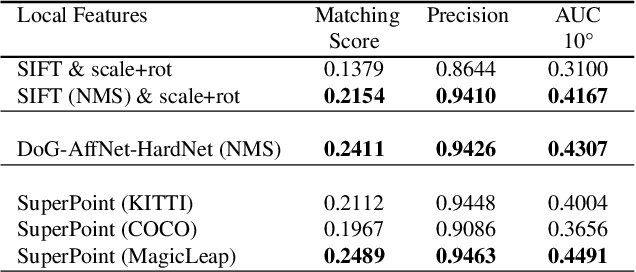
We present OpenGlue: a free open-source framework for image matching, that uses a Graph Neural Network-based matcher inspired by SuperGlue \cite{sarlin20superglue}. We show that including additional geometrical information, such as local feature scale, orientation, and affine geometry, when available (e.g. for SIFT features), significantly improves the performance of the OpenGlue matcher. We study the influence of the various attention mechanisms on accuracy and speed. We also present a simple architectural improvement by combining local descriptors with context-aware descriptors. The code and pretrained OpenGlue models for the different local features are publicly available.
Image-based Stroke Assessment for Multi-site Preclinical Evaluation of Cerebroprotectants
Mar 11, 2022

Ischemic stroke is a leading cause of death worldwide, but there has been little success translating putative cerebroprotectants from preclinical trials to patients. We investigated computational image-based assessment tools for practical improvement of the quality, scalability, and outlook for large scale preclinical screening for potential therapeutic interventions. We developed, evaluated, and deployed a pipeline for image-based stroke outcome quantification for the Stroke Prelinical Assessment Network (SPAN), which is a multi-site, multi-arm, multi-stage study evaluating a suite of cerebroprotectant interventions. Our fully automated pipeline combines state-of-the-art algorithmic and data analytic approaches to assess stroke outcomes from multi-parameter MRI data collected longitudinally from a rodent model of middle cerebral artery occlusion (MCAO), including measures of infarct volume, brain atrophy, midline shift, and data quality. We tested our approach with 1,368 scans and report population level results of lesion extent and longitudinal changes from injury. We validated our system by comparison with manual annotations of coronal MRI slices and tissue sections from the same brain, using crowdsourcing from blinded stroke experts from the network. Our results demonstrate the efficacy and robustness of our image-based stroke assessments. The pipeline may provide a promising resource for ongoing preclinical studies conducted by SPAN and other networks in the future.
Image Classification using Graph Neural Network and Multiscale Wavelet Superpixels
Jan 29, 2022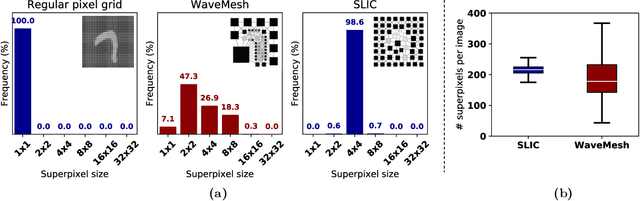
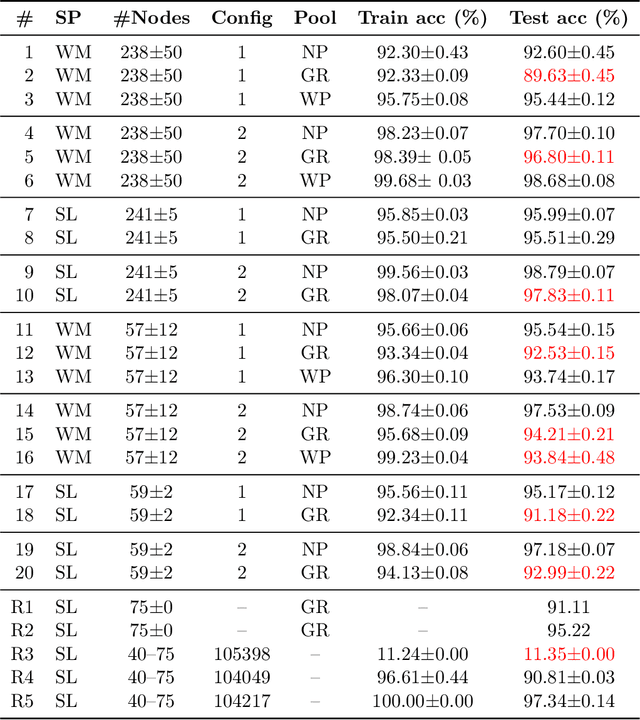

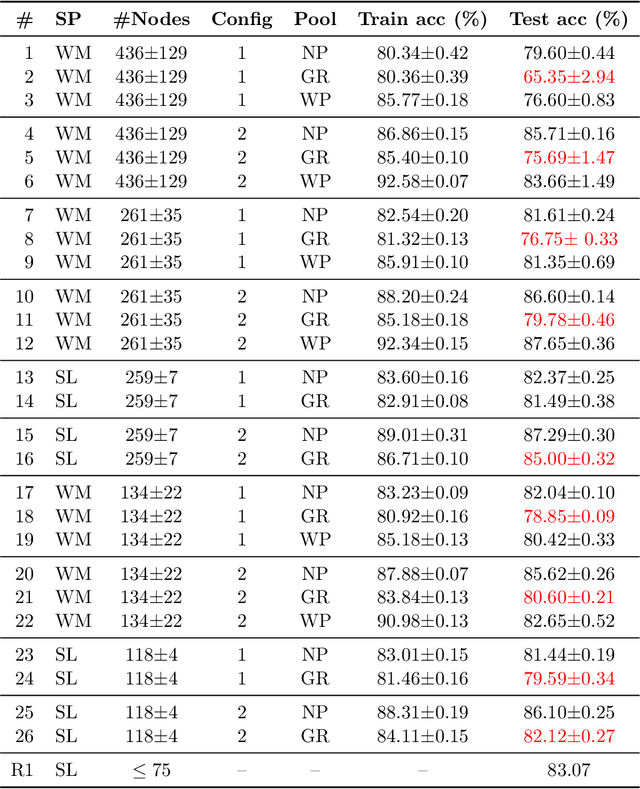
Prior studies using graph neural networks (GNNs) for image classification have focused on graphs generated from a regular grid of pixels or similar-sized superpixels. In the latter, a single target number of superpixels is defined for an entire dataset irrespective of differences across images and their intrinsic multiscale structure. On the contrary, this study investigates image classification using graphs generated from an image-specific number of multiscale superpixels. We propose WaveMesh, a new wavelet-based superpixeling algorithm, where the number and sizes of superpixels in an image are systematically computed based on its content. WaveMesh superpixel graphs are structurally different from similar-sized superpixel graphs. We use SplineCNN, a state-of-the-art network for image graph classification, to compare WaveMesh and similar-sized superpixels. Using SplineCNN, we perform extensive experiments on three benchmark datasets under three local-pooling settings: 1) no pooling, 2) GraclusPool, and 3) WavePool, a novel spatially heterogeneous pooling scheme tailored to WaveMesh superpixels. Our experiments demonstrate that SplineCNN learns from multiscale WaveMesh superpixels on-par with similar-sized superpixels. In all WaveMesh experiments, GraclusPool performs poorer than no pooling / WavePool, indicating that poor choice of pooling can result in inferior performance while learning from multiscale superpixels.
Facial Expression Translation using Landmark Guided GANs
Sep 05, 2022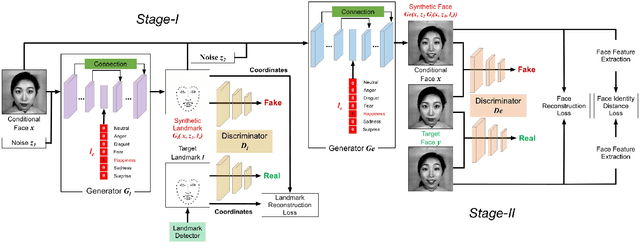
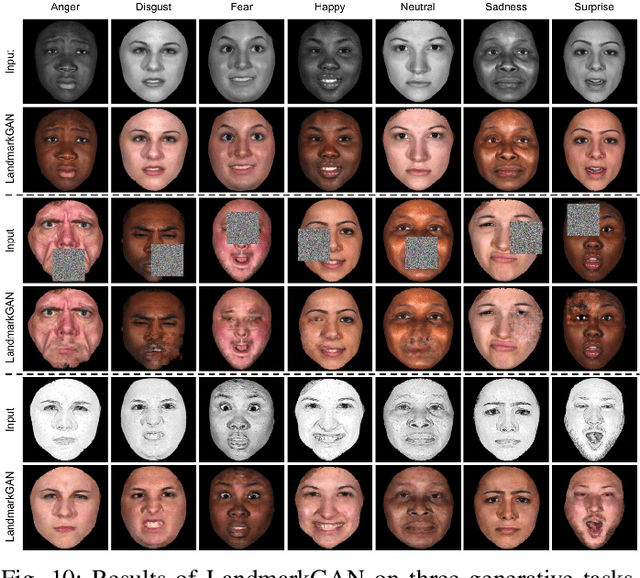
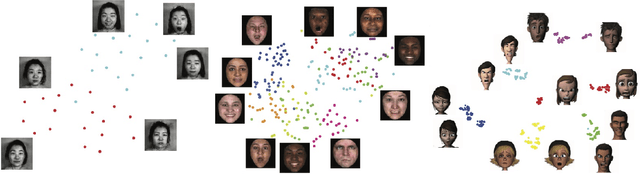
We propose a simple yet powerful Landmark guided Generative Adversarial Network (LandmarkGAN) for the facial expression-to-expression translation using a single image, which is an important and challenging task in computer vision since the expression-to-expression translation is a non-linear and non-aligned problem. Moreover, it requires a high-level semantic understanding between the input and output images since the objects in images can have arbitrary poses, sizes, locations, backgrounds, and self-occlusions. To tackle this problem, we propose utilizing facial landmark information explicitly. Since it is a challenging problem, we split it into two sub-tasks, (i) category-guided landmark generation, and (ii) landmark-guided expression-to-expression translation. Two sub-tasks are trained in an end-to-end fashion that aims to enjoy the mutually improved benefits from the generated landmarks and expressions. Compared with current keypoint-guided approaches, the proposed LandmarkGAN only needs a single facial image to generate various expressions. Extensive experimental results on four public datasets demonstrate that the proposed LandmarkGAN achieves better results compared with state-of-the-art approaches only using a single image. The code is available at https://github.com/Ha0Tang/LandmarkGAN.
Thinking Two Moves Ahead: Anticipating Other Users Improves Backdoor Attacks in Federated Learning
Oct 17, 2022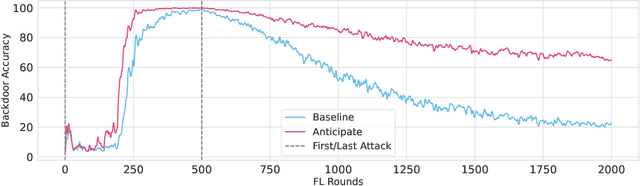
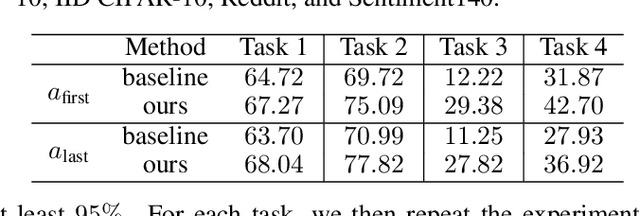
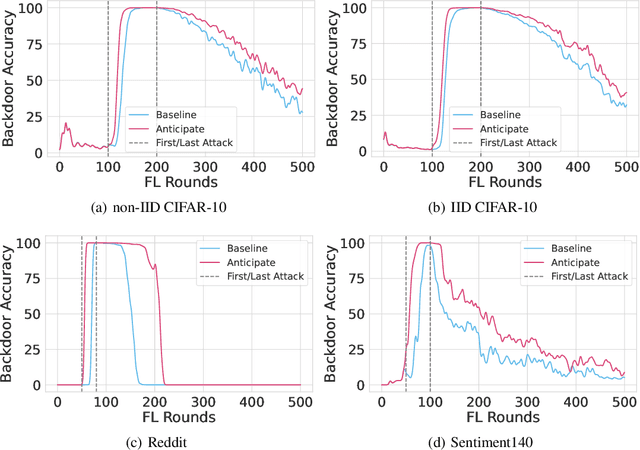
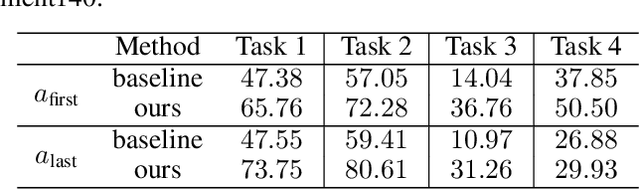
Federated learning is particularly susceptible to model poisoning and backdoor attacks because individual users have direct control over the training data and model updates. At the same time, the attack power of an individual user is limited because their updates are quickly drowned out by those of many other users. Existing attacks do not account for future behaviors of other users, and thus require many sequential updates and their effects are quickly erased. We propose an attack that anticipates and accounts for the entire federated learning pipeline, including behaviors of other clients, and ensures that backdoors are effective quickly and persist even after multiple rounds of community updates. We show that this new attack is effective in realistic scenarios where the attacker only contributes to a small fraction of randomly sampled rounds and demonstrate this attack on image classification, next-word prediction, and sentiment analysis.