 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intention-driven Ego-to-Exo Video Generation
Mar 17, 2024


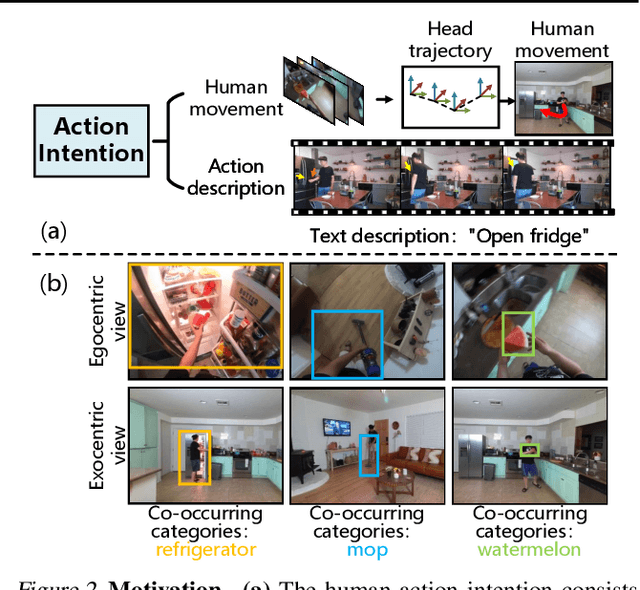
Ego-to-exo video generation refers to generating the corresponding exocentric video according to the egocentric video, providing valuable applications in AR/VR and embodied AI. Benefiting from advancements in diffusion model techniques, notable progress has been achieved in video generation. However, existing methods build upon the spatiotemporal consistency assumptions between adjacent frames, which cannot be satisfied in the ego-to-exo scenarios due to drastic changes in views. To this end, this paper proposes an Intention-Driven Ego-to-exo video generation framework (IDE) that leverages action intention consisting of human movement and action description as view-independent representation to guide video generation, preserving the consistency of content and motion. Specifically, the egocentric head trajectory is first estimated through multi-view stereo matching. Then, cross-view feature perception module is introduced to establish correspondences between exo- and ego- views, guiding the trajectory transformation module to infer human full-body movement from the head trajectory. Meanwhile, we present an action description unit that maps the action semantics into the feature space consistent with the exocentric image. Finally, the inferred human movement and high-level action descriptions jointly guide the generation of exocentric motion and interaction content (i.e., corresponding optical flow and occlusion maps) in the backward process of the diffusion model, ultimately warping them into the corresponding exocentric video. We conduct extensive experiments on the relevant dataset with diverse exo-ego video pairs, and our IDE outperforms state-of-the-art models in both subjective and objective assessments, demonstrating its efficacy in ego-to-exo video generation.
BrightDreamer: Generic 3D Gaussian Generative Framework for Fast Text-to-3D Synthesis
Mar 17, 2024

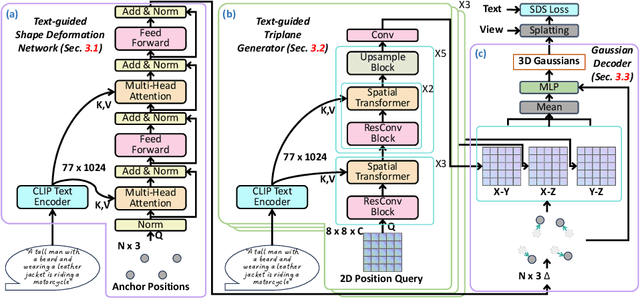
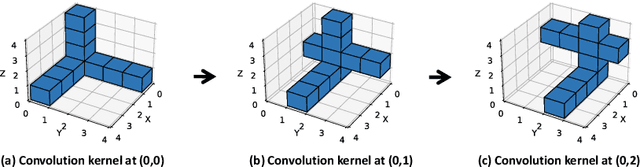
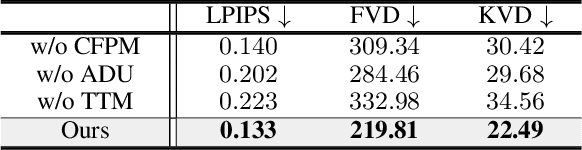
Text-to-3D synthesis has recently seen intriguing advances by combining the text-to-image models with 3D representation methods, e.g., Gaussian Splatting (GS), via Score Distillation Sampling (SDS). However, a hurdle of existing methods is the low efficiency, per-prompt optimization for a single 3D object. Therefore, it is imperative for a paradigm shift from per-prompt optimization to one-stage generation for any unseen text prompts, which yet remains challenging. A hurdle is how to directly generate a set of millions of 3D Gaussians to represent a 3D object. This paper presents BrightDreamer, an end-to-end single-stage approach that can achieve generalizable and fast (77 ms) text-to-3D generation. Our key idea is to formulate the generation process as estimating the 3D deformation from an anchor shape with predefined positions. For this, we first propose a Text-guided Shape Deformation (TSD) network to predict the deformed shape and its new positions, used as the centers (one attribute) of 3D Gaussians. To estimate the other four attributes (i.e., scaling, rotation, opacity, and SH coefficient), we then design a novel Text-guided Triplane Generator (TTG) to generate a triplane representation for a 3D object. The center of each Gaussian enables us to transform the triplane feature into the four attributes. The generated 3D Gaussians can be finally rendered at 705 frames per second. Extensive experiments demonstrate the superiority of our method over existing methods. Also, BrightDreamer possesses a strong semantic understanding capability even for complex text prompts. The project code is available at https://vlislab22.github.io/BrightDreamer.
Domain-Guided Masked Autoencoders for Unique Player Identification
Mar 17, 2024
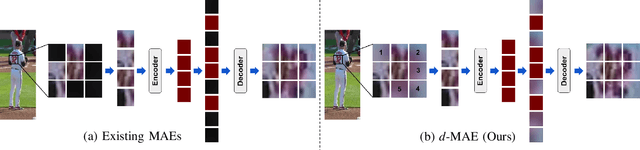
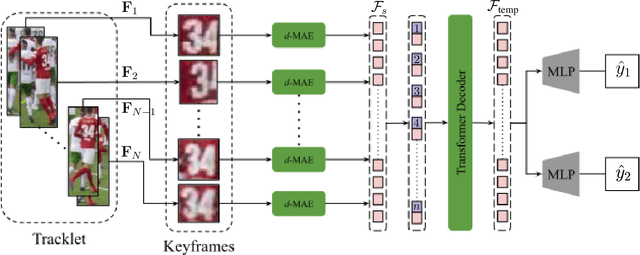

Unique player identification is a fundamental module in vision-driven sports analytics. Identifying players from broadcast videos can aid with various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatic detection of jersey numbers using deep features is challenging primarily due to: a) motion blur, b) low resolution video feed, and c) occlusions. With their recent success in various vision tasks, masked autoencoders (MAEs) have emerged as a superior alternative to conventional feature extractors. However, most MAEs simply zero-out image patches either randomly or focus on where to mask rather than how to mask. Motivated by human vision, we devise a novel domain-guided masking policy for MAEs termed d-MAE to facilitate robust feature extraction in the presence of motion blur for player identification. We further introduce a new spatio-temporal network leveraging our novel d-MAE for unique player identification. We conduct experiments on three large-scale sports datasets, including a curated baseball dataset, the SoccerNet dataset, and an in-house ice hockey dataset. We preprocess the datasets using an upgraded keyframe identification (KfID) module by focusing on frames containing jersey numbers. Additionally, we propose a keyframe-fusion technique to augment keyframes, preserving spatial and temporal context. Our spatio-temporal network showcases significant improvements, surpassing the current state-of-the-art by 8.58%, 4.29%, and 1.20% in the test set accuracies, respectively. Rigorous ablations highlight the effectiveness of our domain-guided masking approach and the refined KfID module, resulting in performance enhancements of 1.48% and 1.84% respectively, compared to original architectures.
3D Human Reconstruction in the Wild with Synthetic Data Using Generative Models
Mar 17, 2024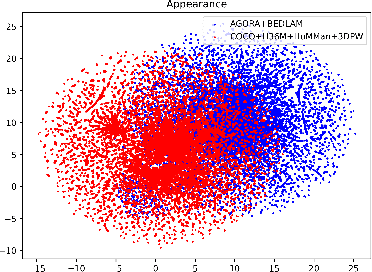
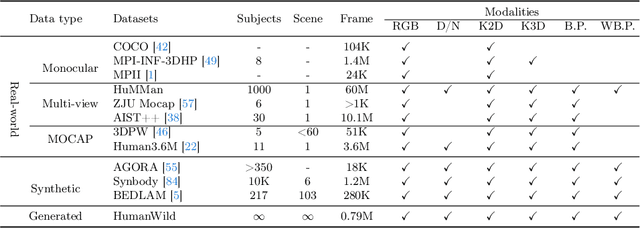
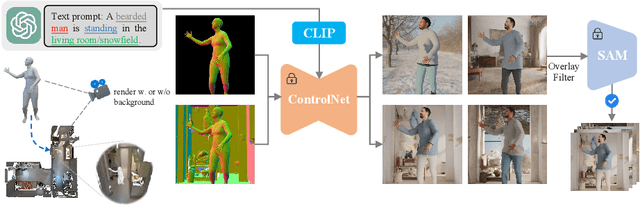
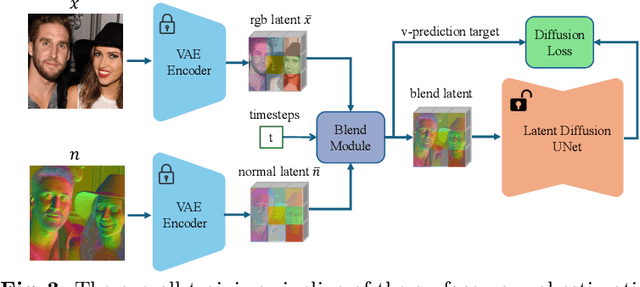
In this work, we show that synthetic data created by generative models is complementary to computer graphics (CG) rendered data for achieving remarkable generalization performance on diverse real-world scenes for 3D human pose and shape estimation (HPS). Specifically, we propose an effective approach based on recent diffusion models, termed HumanWild, which can effortlessly generate human images and corresponding 3D mesh annotations. We first collect a large-scale human-centric dataset with comprehensive annotations, e.g., text captions and surface normal images. Then, we train a customized ControlNet model upon this dataset to generate diverse human images and initial ground-truth labels. At the core of this step is that we can easily obtain numerous surface normal images from a 3D human parametric model, e.g., SMPL-X, by rendering the 3D mesh onto the image plane. As there exists inevitable noise in the initial labels, we then apply an off-the-shelf foundation segmentation model, i.e., SAM, to filter negative data samples. Our data generation pipeline is flexible and customizable to facilitate different real-world tasks, e.g., ego-centric scenes and perspective-distortion scenes. The generated dataset comprises 0.79M images with corresponding 3D annotations, covering versatile viewpoints, scenes, and human identities. We train various HPS regressors on top of the generated data and evaluate them on a wide range of benchmarks (3DPW, RICH, EgoBody, AGORA, SSP-3D) to verify the effectiveness of the generated data. By exclusively employing generative models, we generate large-scale in-the-wild human images and high-quality annotations, eliminating the need for real-world data collection.
DPPE: Dense Pose Estimation in a Plenoxels Environment using Gradient Approximation
Mar 16, 2024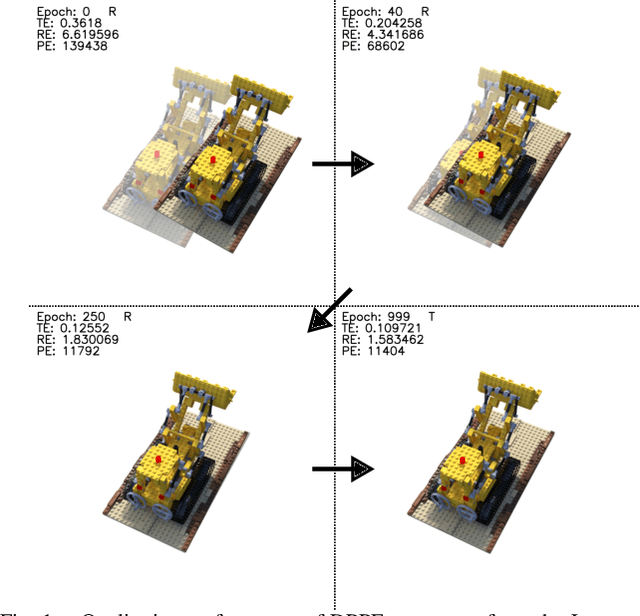
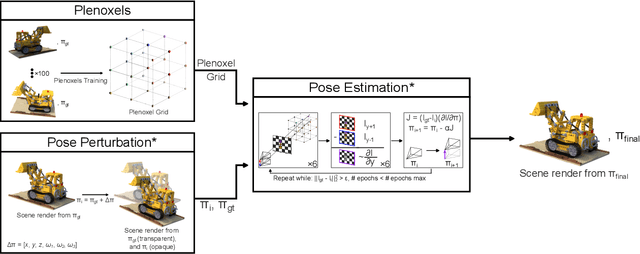
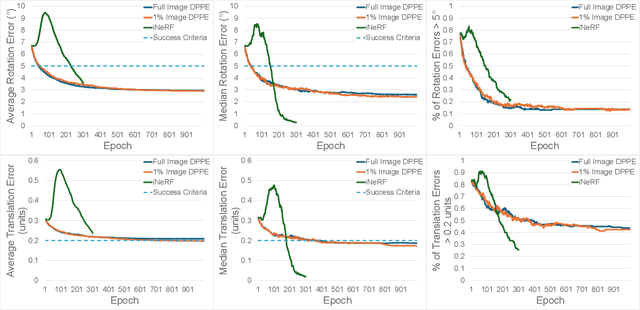

We present DPPE, a dense pose estimation algorithm that functions over a Plenoxels environment. Recent advances in neural radiance field techniques have shown that it is a powerful tool for environment representation. More recent neural rendering algorithms have significantly improved both training duration and rendering speed. Plenoxels introduced a fully-differentiable radiance field technique that uses Plenoptic volume elements contained in voxels for rendering, offering reduced training times and better rendering accuracy, while also eliminating the neural net component. In this work, we introduce a 6-DoF monocular RGB-only pose estimation procedure for Plenoxels, which seeks to recover the ground truth camera pose after a perturbation. We employ a variation on classical template matching techniques, using stochastic gradient descent to optimize the pose by minimizing errors in re-rendering. In particular, we examine an approach that takes advantage of the rapid rendering speed of Plenoxels to numerically approximate part of the pose gradient, using a central differencing technique. We show that such methods are effective in pose estimation. Finally, we perform ablations over key components of the problem space, with a particular focus on image subsampling and Plenoxel grid resolution. Project website: https://sites.google.com/view/dppe
Anomaly Detection Based on Isolation Mechanisms: A Survey
Mar 16, 2024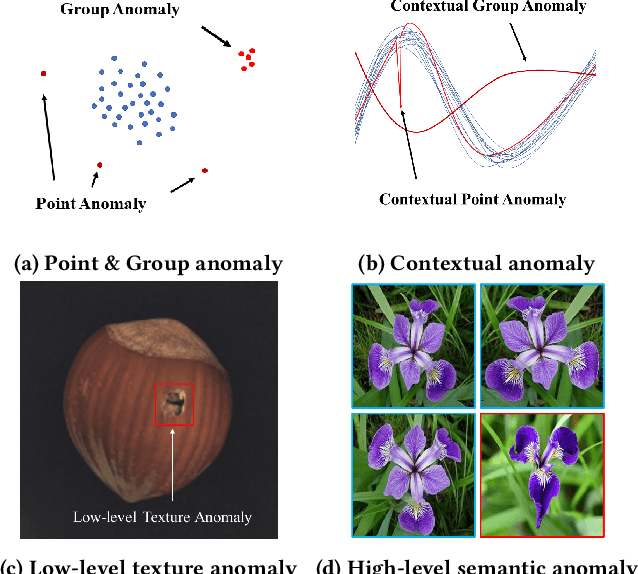
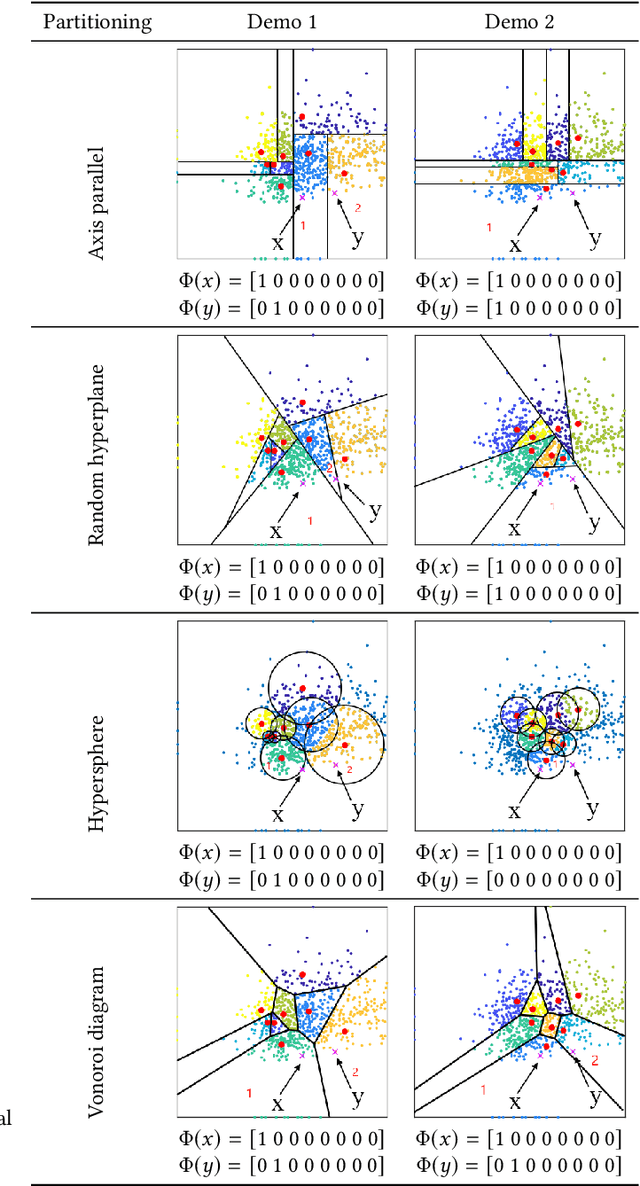
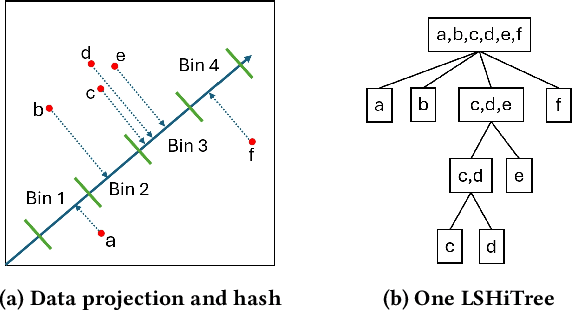

Anomaly detection is a longstanding and active research area that has many applications in domains such as finance, security, and manufacturing. However, the efficiency and performance of anomaly detection algorithms are challenged by the large-scale, high-dimensional, and heterogeneous data that are prevalent in the era of big data. Isolation-based unsupervised anomaly detection is a novel and effective approach for identifying anomalies in data. It relies on the idea that anomalies are few and different from normal instances, and thus can be easily isolated by random partitioning. Isolation-based methods have several advantages over existing methods, such as low computational complexity, low memory usage, high scalability, robustness to noise and irrelevant features, and no need for prior knowledge or heavy parameter tuning. In this survey, we review the state-of-the-art isolation-based anomaly detection methods, including their data partitioning strategies, anomaly score functions, and algorithmic details. We also discuss some extensions and applications of isolation-based methods in different scenarios, such as detecting anomalies in streaming data, time series, trajectory, and image datasets. Finally, we identify some open challenges and future directions for isolation-based anomaly detection research.
Regularizing CNNs using Confusion Penalty Based Label Smoothing for Histopathology Images
Mar 16, 2024
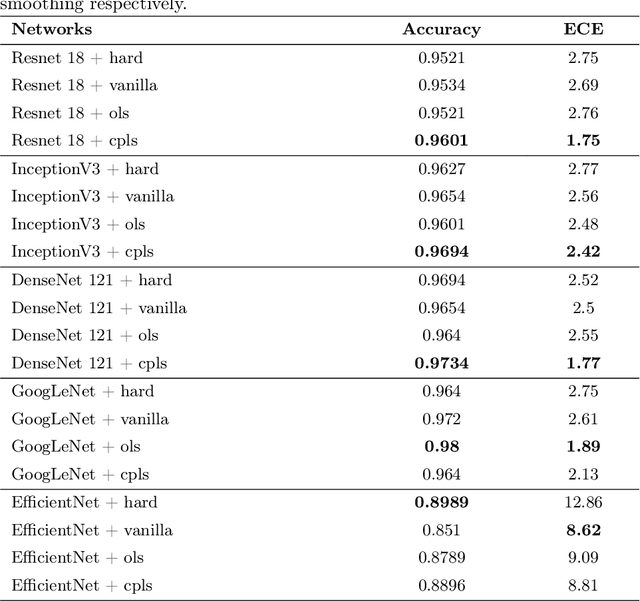
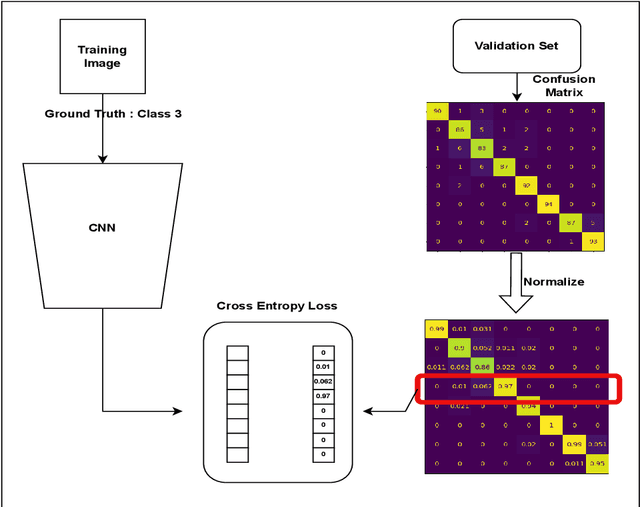
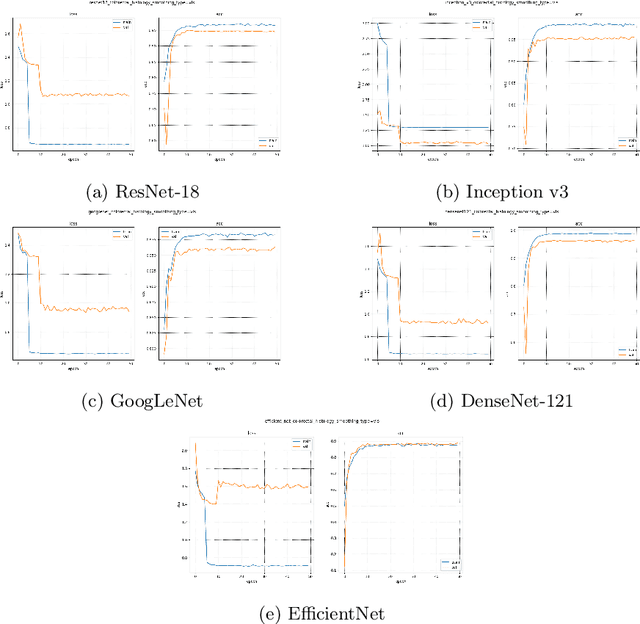
Deep Learning, particularly Convolutional Neural Networks (CNN), has been successful in computer vision tasks and medical image analysis. However, modern CNNs can be overconfident, making them difficult to deploy in real-world scenarios. Researchers propose regularizing techniques, such as Label Smoothing (LS), which introduces soft labels for training data, making the classifier more regularized. LS captures disagreements or lack of confidence in the training phase, making the classifier more regularized. Although LS is quite simple and effective, traditional LS techniques utilize a weighted average between target distribution and a uniform distribution across the classes, which limits the objective of LS as well as the performance. This paper introduces a novel LS technique based on the confusion penalty, which treats model confusion for each class with more importance than others. We have performed extensive experiments with well-known CNN architectures with this technique on publicly available Colorectal Histology datasets and got satisfactory results. Also, we have compared our findings with the State-of-the-art and shown our method's efficacy with Reliability diagrams and t-distributed Stochastic Neighbor Embedding (t-SNE) plots of feature space.
N2F2: Hierarchical Scene Understanding with Nested Neural Feature Fields
Mar 16, 2024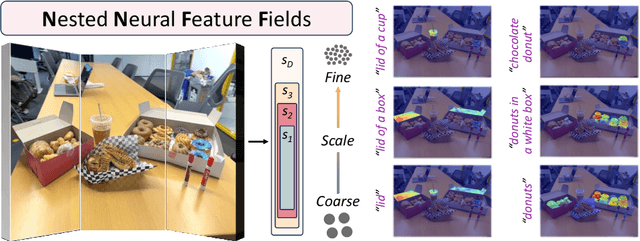
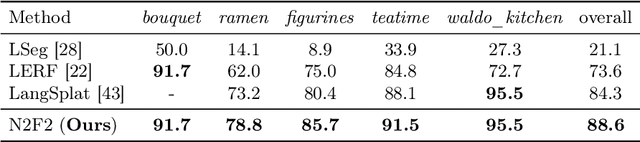
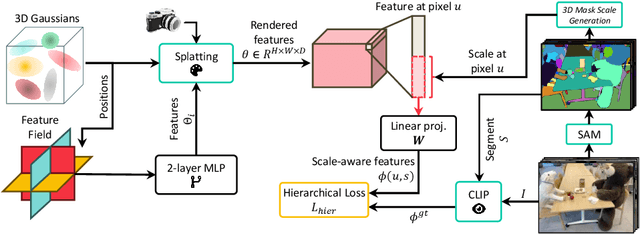
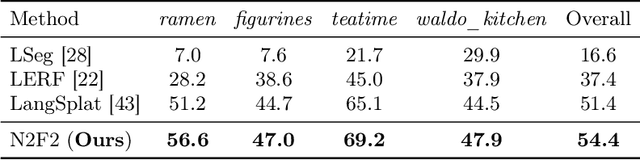
Understanding complex scenes at multiple levels of abstraction remains a formidable challenge in computer vision. To address this, we introduce Nested Neural Feature Fields (N2F2), a novel approach that employs hierarchical supervision to learn a single feature field, wherein different dimensions within the same high-dimensional feature encode scene properties at varying granularities. Our method allows for a flexible definition of hierarchies, tailored to either the physical dimensions or semantics or both, thereby enabling a comprehensive and nuanced understanding of scenes. We leverage a 2D class-agnostic segmentation model to provide semantically meaningful pixel groupings at arbitrary scales in the image space, and query the CLIP vision-encoder to obtain language-aligned embeddings for each of these segments. Our proposed hierarchical supervision method then assigns different nested dimensions of the feature field to distill the CLIP embeddings using deferred volumetric rendering at varying physical scales, creating a coarse-to-fine representation. Extensive experiments show that our approach outperforms the state-of-the-art feature field distillation methods on tasks such as open-vocabulary 3D segmentation and localization, demonstrating the effectiveness of the learned nested feature field.
From Canteen Food to Daily Meals: Generalizing Food Recognition to More Practical Scenarios
Mar 12, 2024


The precise recognition of food categories plays a pivotal role for intelligent health management, attracting significant research attention in recent years. Prominent benchmarks, such as Food-101 and VIREO Food-172, provide abundant food image resources that catalyze the prosperity of research in this field. Nevertheless, these datasets are well-curated from canteen scenarios and thus deviate from food appearances in daily life. This discrepancy poses great challenges in effectively transferring classifiers trained on these canteen datasets to broader daily-life scenarios encountered by humans. Toward this end, we present two new benchmarks, namely DailyFood-172 and DailyFood-16, specifically designed to curate food images from everyday meals. These two datasets are used to evaluate the transferability of approaches from the well-curated food image domain to the everyday-life food image domain. In addition, we also propose a simple yet effective baseline method named Multi-Cluster Reference Learning (MCRL) to tackle the aforementioned domain gap. MCRL is motivated by the observation that food images in daily-life scenarios exhibit greater intra-class appearance variance compared with those in well-curated benchmarks. Notably, MCRL can be seamlessly coupled with existing approaches, yielding non-trivial performance enhancements. We hope our new benchmarks can inspire the community to explore the transferability of food recognition models trained on well-curated datasets toward practical real-life applications.
AIGCs Confuse AI Too: Investigating and Explaining Synthetic Image-induced Hallucinations in Large Vision-Language Models
Mar 13, 2024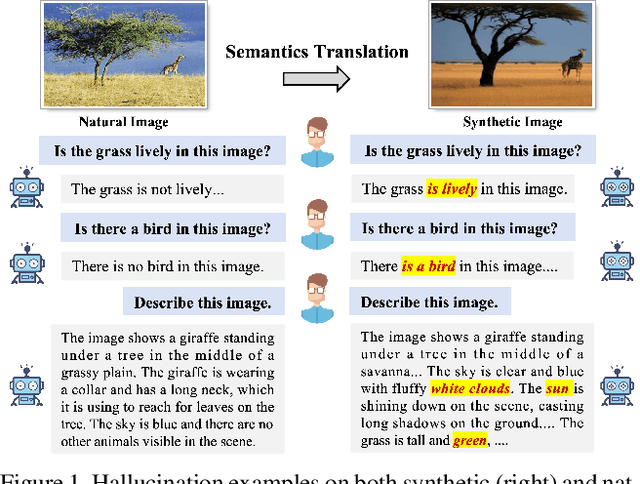
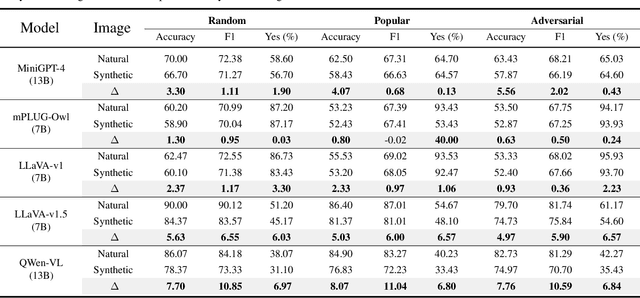

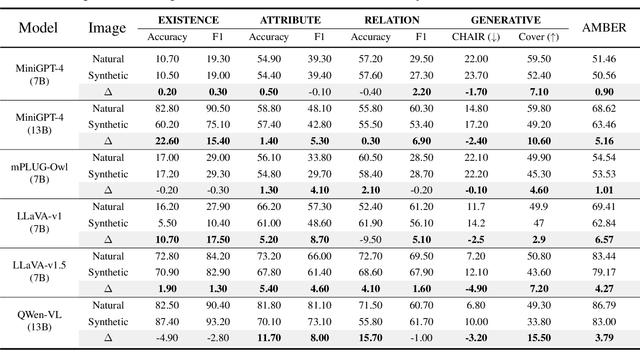
The evolution of Artificial Intelligence Generated Contents (AIGCs) is advancing towards higher quality. The growing interactions with AIGCs present a new challenge to the data-driven AI community: While AI-generated contents have played a crucial role in a wide range of AI models, the potential hidden risks they introduce have not been thoroughly examined. Beyond human-oriented forgery detection, AI-generated content poses potential issues for AI models originally designed to process natural data. In this study, we underscore the exacerbated hallucination phenomena in Large Vision-Language Models (LVLMs) caused by AI-synthetic images. Remarkably, our findings shed light on a consistent AIGC \textbf{hallucination bias}: the object hallucinations induced by synthetic images are characterized by a greater quantity and a more uniform position distribution, even these synthetic images do not manifest unrealistic or additional relevant visual features compared to natural images. Moreover, our investigations on Q-former and Linear projector reveal that synthetic images may present token deviations after visual projection, thereby amplifying the hallucination bias.