 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explainable Analysis of Deep Learning Methods for SAR Image Classification
Apr 14, 2022
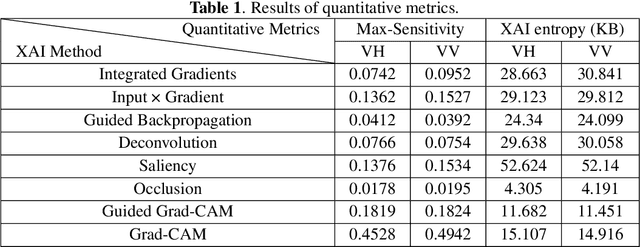
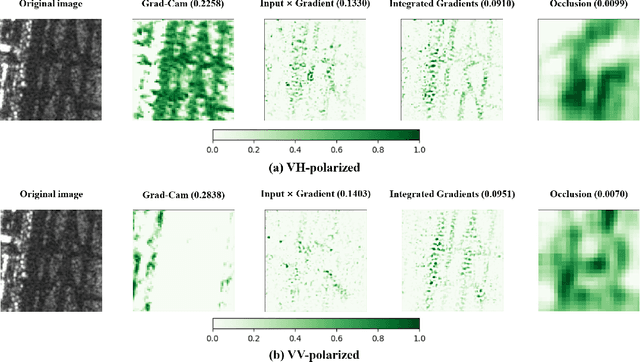
Deep learning methods exhibit outstanding performance in synthetic aperture radar (SAR) image interpretation tasks. However, these are black box models that limit the comprehension of their predictions. Therefore, to meet this challenge, we have utilized explainable artificial intelligence (XAI) methods for the SAR image classification task. Specifically, we trained state-of-the-art convolutional neural networks for each polarization format on OpenSARUrban dataset and then investigate eight explanation methods to analyze the predictions of the CNN classifiers of SAR images. These XAI methods are also evaluated qualitatively and quantitatively which shows that Occlusion achieves the most reliable interpretation performance in terms of Max-Sensitivity but with a low-resolution explanation heatmap. The explanation results provide some insights into the internal mechanism of black-box decisions for SAR image classification.
Robustness of Fusion-based Multimodal Classifiers to Cross-Modal Content Dilutions
Nov 04, 2022
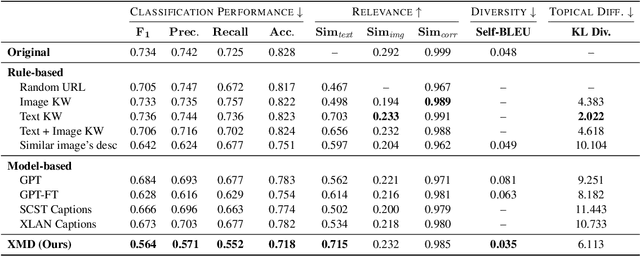
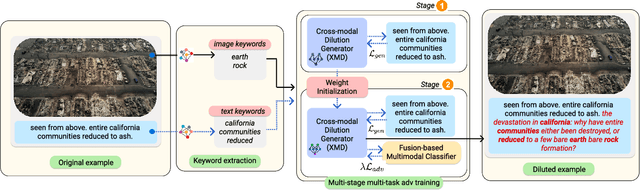
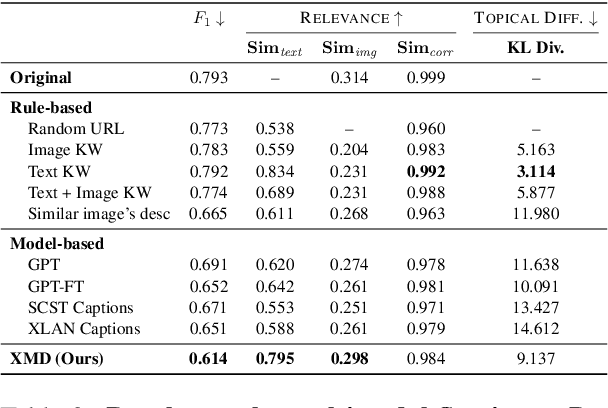
As multimodal learning finds applications in a wide variety of high-stakes societal tasks, investigating their robustness becomes important. Existing work has focused on understanding the robustness of vision-and-language models to imperceptible variations on benchmark tasks. In this work, we investigate the robustness of multimodal classifiers to cross-modal dilutions - a plausible variation. We develop a model that, given a multimodal (image + text) input, generates additional dilution text that (a) maintains relevance and topical coherence with the image and existing text, and (b) when added to the original text, leads to misclassification of the multimodal input. Via experiments on Crisis Humanitarianism and Sentiment Detection tasks, we find that the performance of task-specific fusion-based multimodal classifiers drops by 23.3% and 22.5%, respectively, in the presence of dilutions generated by our model. Metric-based comparisons with several baselines and human evaluations indicate that our dilutions show higher relevance and topical coherence, while simultaneously being more effective at demonstrating the brittleness of the multimodal classifiers. Our work aims to highlight and encourage further research on the robustness of deep multimodal models to realistic variations, especially in human-facing societal applications. The code and other resources are available at https://claws-lab.github.io/multimodal-robustness/.
Totems: Physical Objects for Verifying Visual Integrity
Sep 26, 2022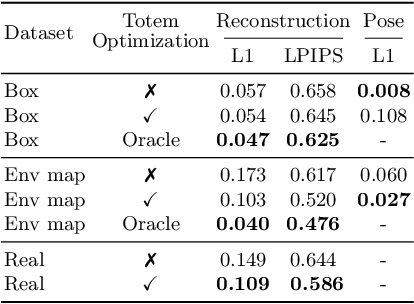
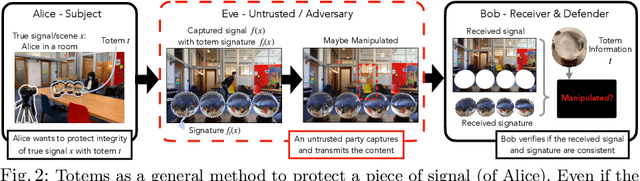

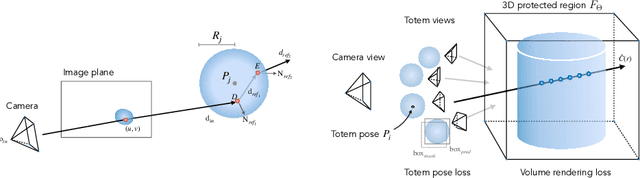
We introduce a new approach to image forensics: placing physical refractive objects, which we call totems, into a scene so as to protect any photograph taken of that scene. Totems bend and redirect light rays, thus providing multiple, albeit distorted, views of the scene within a single image. A defender can use these distorted totem pixels to detect if an image has been manipulated. Our approach unscrambles the light rays passing through the totems by estimating their positions in the scene and using their known geometric and material properties. To verify a totem-protected image, we detect inconsistencies between the scene reconstructed from totem viewpoints and the scene's appearance from the camera viewpoint. Such an approach makes the adversarial manipulation task more difficult, as the adversary must modify both the totem and image pixels in a geometrically consistent manner without knowing the physical properties of the totem. Unlike prior learning-based approaches, our method does not require training on datasets of specific manipulations, and instead uses physical properties of the scene and camera to solve the forensics problem.
Visual Exploration of Large-Scale Image Datasets for Machine Learning with Treemaps
May 14, 2022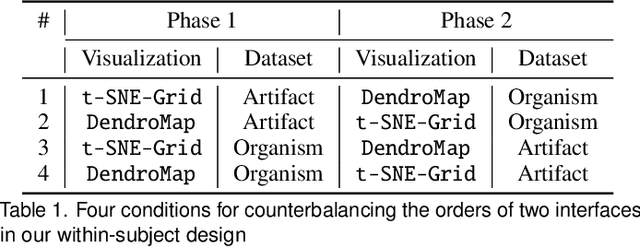


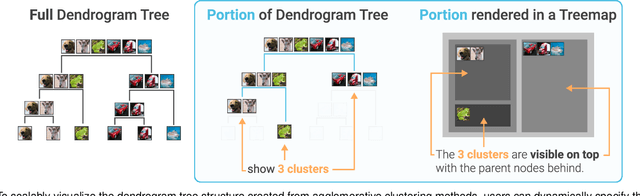
In this paper, we present DendroMap, a novel approach to interactively exploring large-scale image datasets for machine learning. Machine learning practitioners often explore image datasets by generating a grid of images or projecting high-dimensional representations of images into 2-D using dimensionality reduction techniques (e.g., t-SNE). However, neither approach effectively scales to large datasets because images are ineffectively organized and interactions are insufficiently supported. To address these challenges, we develop DendroMap by adapting Treemaps, a well-known visualization technique. DendroMap effectively organizes images by extracting hierarchical cluster structures from high-dimensional representations of images. It enables users to make sense of the overall distributions of datasets and interactively zoom into specific areas of interests at multiple levels of abstraction. Our case studies with widely-used image datasets for deep learning demonstrate that users can discover insights about datasets and trained models by examining the diversity of images, identifying underperforming subgroups, and analyzing classification errors. We conducted a user study that evaluates the effectiveness of DendroMap in grouping and searching tasks by comparing it with a gridified version of t-SNE and found that participants preferred DendroMap over the compared method.
City-Wide Perceptions of Neighbourhood Quality using Street View Images
Nov 24, 2022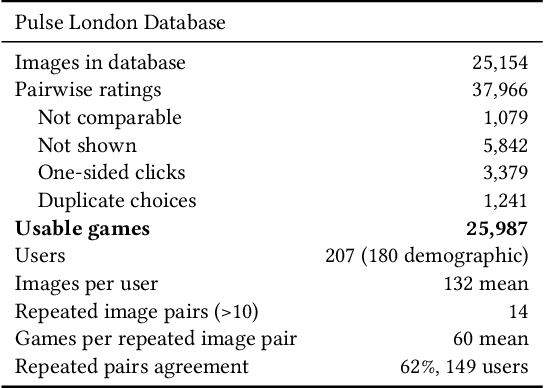
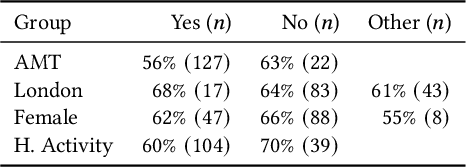
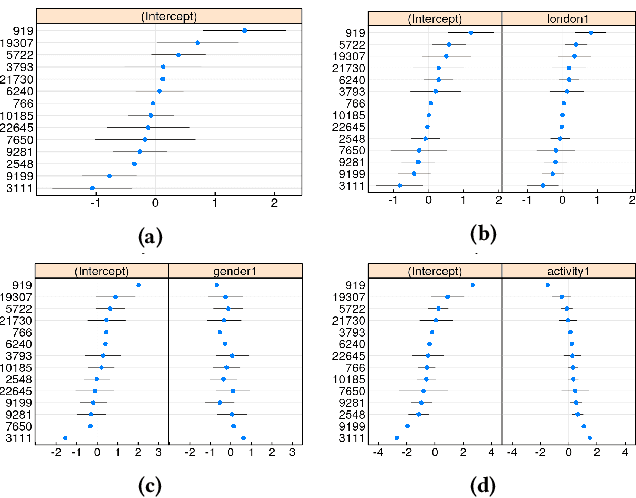

The interactions of individuals with city neighbourhoods is determined, in part, by the perceived quality of urban environments. Perceived neighbourhood quality is a core component of urban vitality, influencing social cohesion, sense of community, safety, activity and mental health of residents. Large-scale assessment of perceptions of neighbourhood quality was pioneered by the Place Pulse projects. Researchers demonstrated the efficacy of crowd-sourcing perception ratings of image pairs across 56 cities and training a model to predict perceptions from street-view images. Variation across cities may limit Place Pulse's usefulness for assessing within-city perceptions. In this paper, we set forth a protocol for city-specific dataset collection for the perception: 'On which street would you prefer to walk?'. This paper describes our methodology, based in London, including collection of images and ratings, web development, model training and mapping. Assessment of within-city perceptions of neighbourhoods can identify inequities, inform planning priorities, and identify temporal dynamics. Code available: https://emilymuller1991.github.io/urban-perceptions/.
A Benchmark of Long-tailed Instance Segmentation with Noisy Labels (Short Version)
Nov 24, 2022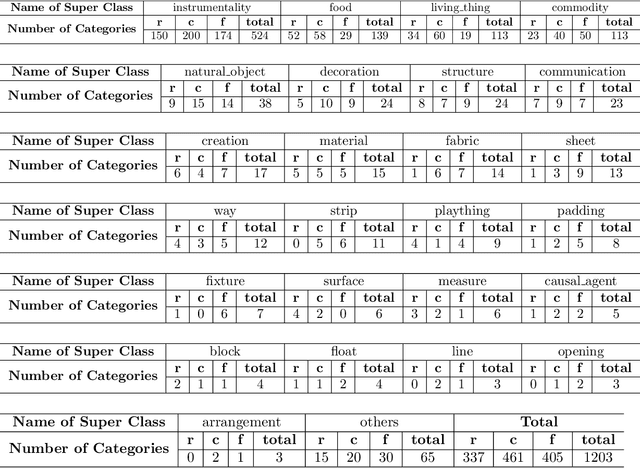
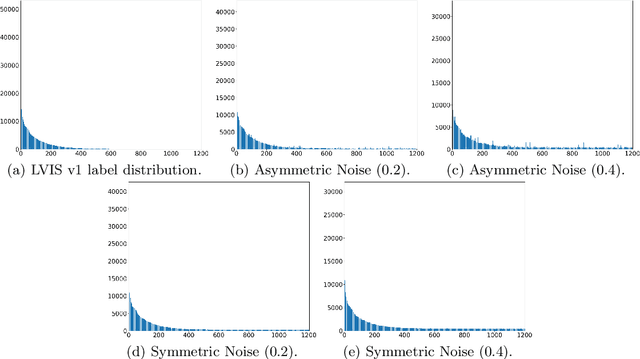
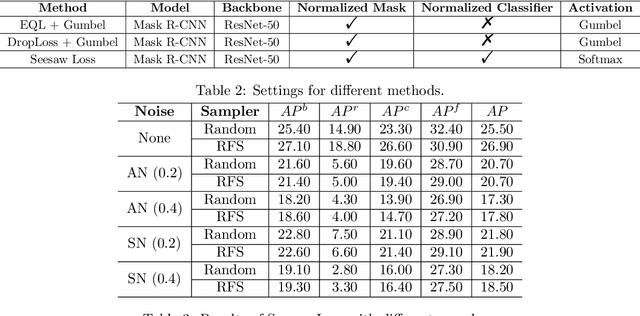
In this paper, we consider the instance segmentation task on a long-tailed dataset, which contains label noise, i.e., some of the annotations are incorrect. There are two main reasons making this case realistic. First, datasets collected from real world usually obey a long-tailed distribution. Second, for instance segmentation datasets, as there are many instances in one image and some of them are tiny, it is easier to introduce noise into the annotations. Specifically, we propose a new dataset, which is a large vocabulary long-tailed dataset containing label noise for instance segmentation. Furthermore, we evaluate previous proposed instance segmentation algorithms on this dataset. The results indicate that the noise in the training dataset will hamper the model in learning rare categories and decrease the overall performance, and inspire us to explore more effective approaches to address this practical challenge. The code and dataset are available in https://github.com/GuanlinLee/Noisy-LVIS.
Memory transformers for full context and high-resolution 3D Medical Segmentation
Oct 11, 2022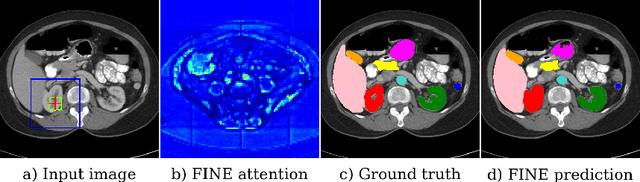
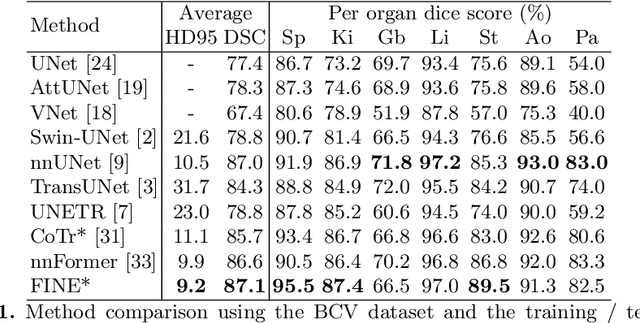
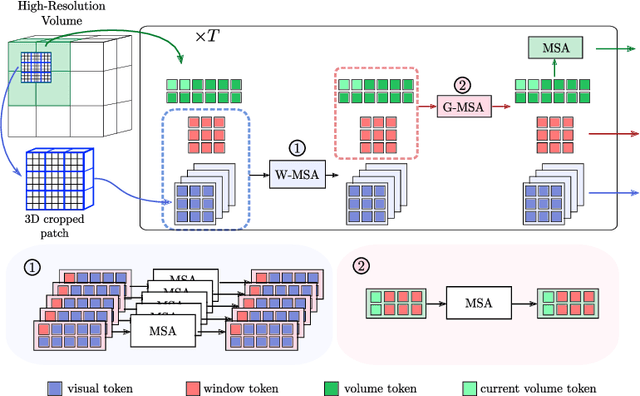

Transformer models achieve state-of-the-art results for image segmentation. However, achieving long-range attention, necessary to capture global context, with high-resolution 3D images is a fundamental challenge. This paper introduces the Full resolutIoN mEmory (FINE) transformer to overcome this issue. The core idea behind FINE is to learn memory tokens to indirectly model full range interactions while scaling well in both memory and computational costs. FINE introduces memory tokens at two levels: the first one allows full interaction between voxels within local image regions (patches), the second one allows full interactions between all regions of the 3D volume. Combined, they allow full attention over high resolution images, e.g. 512 x 512 x 256 voxels and above. Experiments on the BCV image segmentation dataset shows better performances than state-of-the-art CNN and transformer baselines, highlighting the superiority of our full attention mechanism compared to recent transformer baselines, e.g. CoTr, and nnFormer.
Inharmonious Region Localization via Recurrent Self-Reasoning
Oct 05, 2022
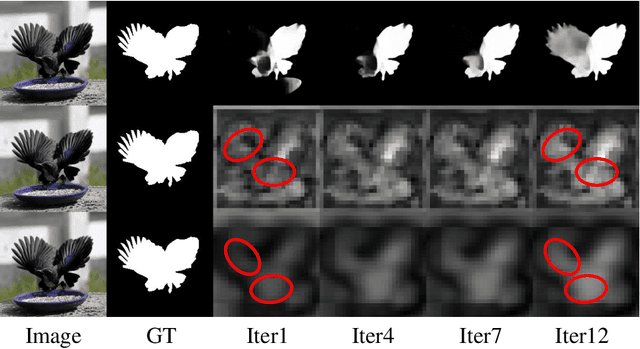
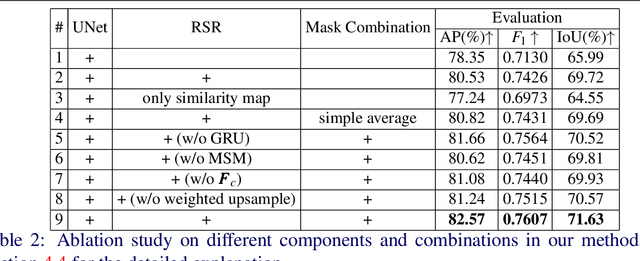
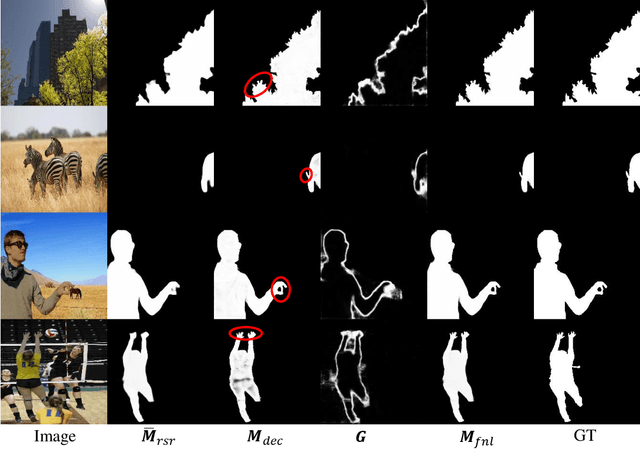
Synthetic images created by image editing operations are prevalent, but the color or illumination inconsistency between the manipulated region and background may make it unrealistic. Thus, it is important yet challenging to localize the inharmonious region to improve the quality of synthetic image. Inspired by the classic clustering algorithm, we aim to group pixels into two clusters: inharmonious cluster and background cluster by inserting a novel Recurrent Self-Reasoning (RSR) module into the bottleneck of UNet structure. The mask output from RSR module is provided for the decoder as attention guidance. Finally, we adaptively combine the masks from RSR and the decoder to form our final mask. Experimental results on the image harmonization dataset demonstrate that our method achieves competitive performance both quantitatively and qualitatively.
StatMix: Data augmentation method that relies on image statistics in federated learning
Jul 08, 2022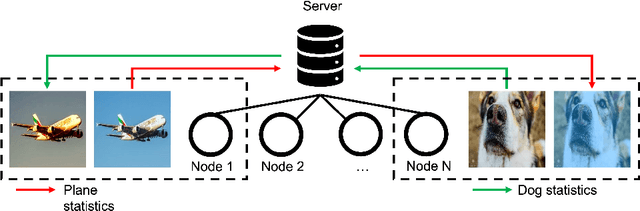
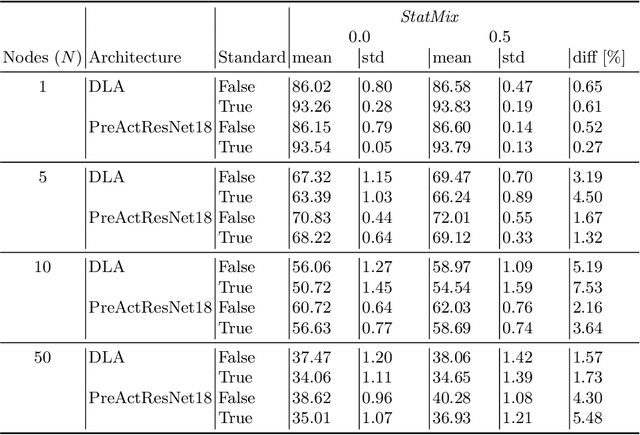

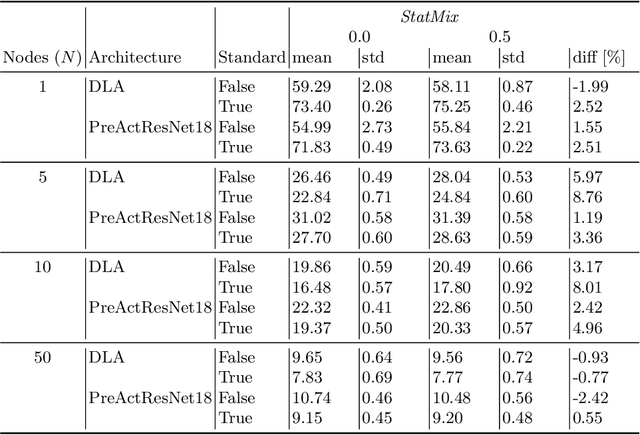
Availability of large amount of annotated data is one of the pillars of deep learning success. Although numerous big datasets have been made available for research, this is often not the case in real life applications (e.g. companies are not able to share data due to GDPR or concerns related to intellectual property rights protection). Federated learning (FL) is a potential solution to this problem, as it enables training a global model on data scattered across multiple nodes, without sharing local data itself. However, even FL methods pose a threat to data privacy, if not handled properly. Therefore, we propose StatMix, an augmentation approach that uses image statistics, to improve results of FL scenario(s). StatMix is empirically tested on CIFAR-10 and CIFAR-100, using two neural network architectures. In all FL experiments, application of StatMix improves the average accuracy, compared to the baseline training (with no use of StatMix). Some improvement can also be observed in non-FL setups.
Faster Adaptive Federated Learning
Dec 02, 2022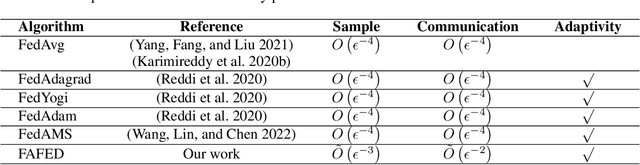
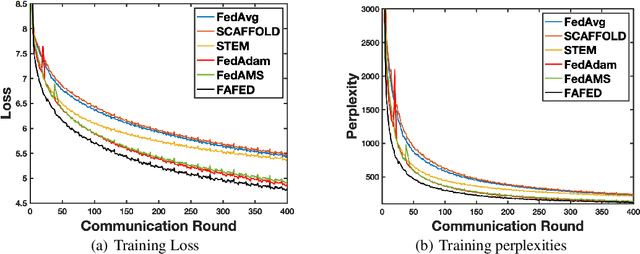
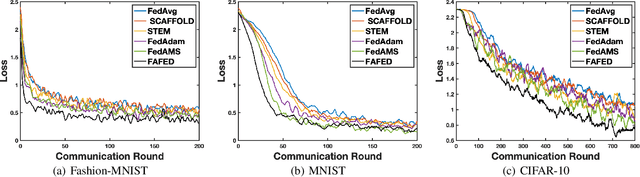
Federated learning has attracted increasing attention with the emergence of distributed data. While extensive federated learning algorithms have been proposed for the non-convex distributed problem, the federated learning in practice still faces numerous challenges, such as the large training iterations to converge since the sizes of models and datasets keep increasing, and the lack of adaptivity by SGD-based model updates. Meanwhile, the study of adaptive methods in federated learning is scarce and existing works either lack a complete theoretical convergence guarantee or have slow sample complexity. In this paper, we propose an efficient adaptive algorithm (i.e., FAFED) based on the momentum-based variance reduced technique in cross-silo FL. We first explore how to design the adaptive algorithm in the FL setting. By providing a counter-example, we prove that a simple combination of FL and adaptive methods could lead to divergence. More importantly, we provide a convergence analysis for our method and prove that our algorithm is the first adaptive FL algorithm to reach the best-known samples $O(\epsilon^{-3})$ and $O(\epsilon^{-2})$ communication rounds to find an $\epsilon$-stationary point without large batches. The experimental results on the language modeling task and image classification task with heterogeneous data demonstrate the efficiency of our algorithms.