 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Clustering with Contrastive Learning and Multi-scale Graph Convolutional Networks
Jul 14, 2022
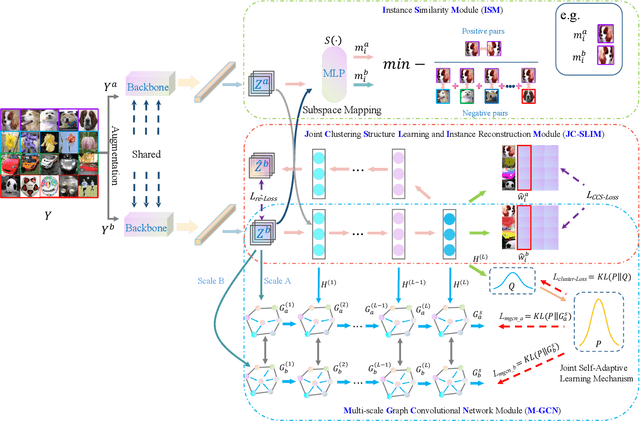

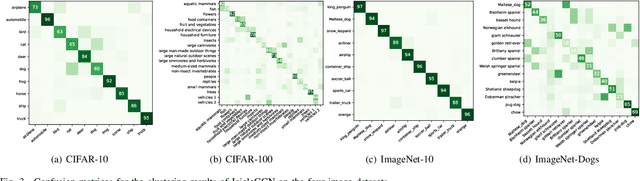

Deep clustering has recently attracted significant attention. Despite the remarkable progress, most of the previous deep clustering works still suffer from two limitations. First, many of them focus on some distribution-based clustering loss, lacking the ability to exploit sample-wise (or augmentation-wise) relationships via contrastive learning. Second, they often neglect the indirect sample-wise structure information, overlooking the rich possibilities of multi-scale neighborhood structure learning. In view of this, this paper presents a new deep clustering approach termed Image clustering with contrastive learning and multi-scale Graph Convolutional Networks (IcicleGCN), which bridges the gap between convolutional neural network (CNN) and graph convolutional network (GCN) as well as the gap between contrastive learning and multi-scale neighborhood structure learning for the image clustering task. The proposed IcicleGCN framework consists of four main modules, namely, the CNN-based backbone, the Instance Similarity Module (ISM), the Joint Cluster Structure Learning and Instance reconstruction Module (JC-SLIM), and the Multi-scale GCN module (M-GCN). Specifically, with two random augmentations performed on each image, the backbone network with two weight-sharing views is utilized to learn the representations for the augmented samples, which are then fed to ISM and JC-SLIM for instance-level and cluster-level contrastive learning, respectively. Further, to enforce multi-scale neighborhood structure learning, two streams of GCNs and an auto-encoder are simultaneously trained via (i) the layer-wise interaction with representation fusion and (ii) the joint self-adaptive learning that ensures their last-layer output distributions to be consistent. Experiments on multiple image datasets demonstrate the superior clustering performance of IcicleGCN over the state-of-the-art.
Hierarchical Average Precision Training for Pertinent Image Retrieval
Jul 05, 2022
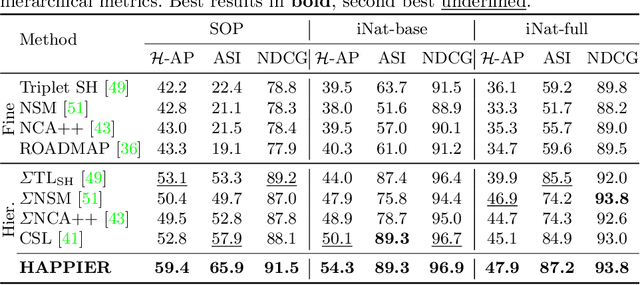
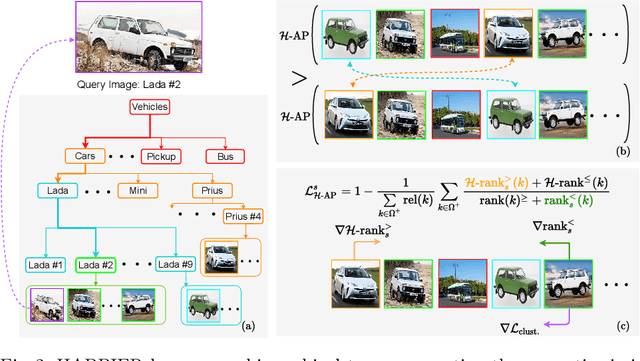
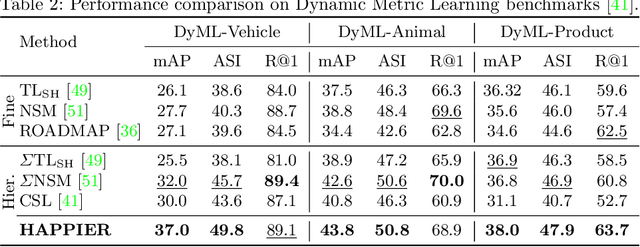
Image Retrieval is commonly evaluated with Average Precision (AP) or Recall@k. Yet, those metrics, are limited to binary labels and do not take into account errors' severity. This paper introduces a new hierarchical AP training method for pertinent image retrieval (HAP-PIER). HAPPIER is based on a new H-AP metric, which leverages a concept hierarchy to refine AP by integrating errors' importance and better evaluate rankings. To train deep models with H-AP, we carefully study the problem's structure and design a smooth lower bound surrogate combined with a clustering loss that ensures consistent ordering. Extensive experiments on 6 datasets show that HAPPIER significantly outperforms state-of-the-art methods for hierarchical retrieval, while being on par with the latest approaches when evaluating fine-grained ranking performances. Finally, we show that HAPPIER leads to better organization of the embedding space, and prevents most severe failure cases of non-hierarchical methods. Our code is publicly available at: https://github.com/elias-ramzi/HAPPIER.
Counterfactual Explanations for Land Cover Mapping in a Multi-class Setting
Jan 04, 2023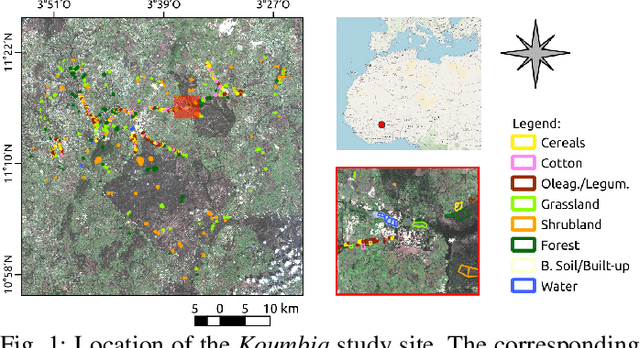
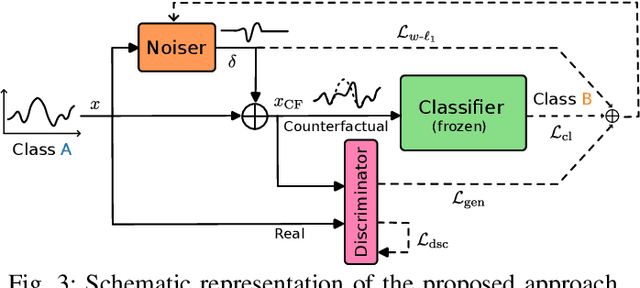
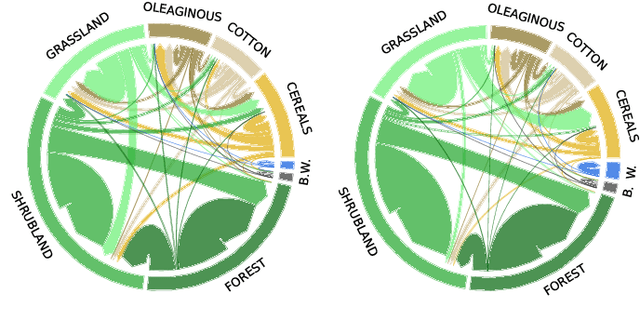
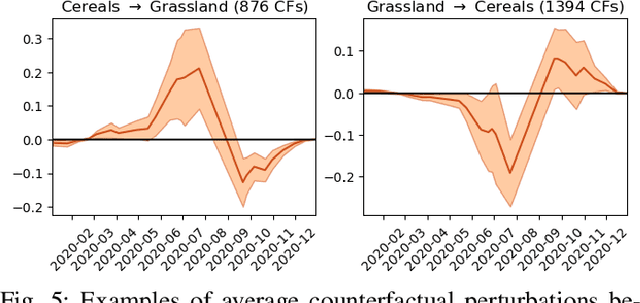
Counterfactual explanations are an emerging tool to enhance interpretability of deep learning models. Given a sample, these methods seek to find and display to the user similar samples across the decision boundary. In this paper, we propose a generative adversarial counterfactual approach for satellite image time series in a multi-class setting for the land cover classification task. One of the distinctive features of the proposed approach is the lack of prior assumption on the targeted class for a given counterfactual explanation. This inherent flexibility allows for the discovery of interesting information on the relationship between land cover classes. The other feature consists of encouraging the counterfactual to differ from the original sample only in a small and compact temporal segment. These time-contiguous perturbations allow for a much sparser and, thus, interpretable solution. Furthermore, plausibility/realism of the generated counterfactual explanations is enforced via the proposed adversarial learning strategy.
MonoEdge: Monocular 3D Object Detection Using Local Perspectives
Jan 04, 2023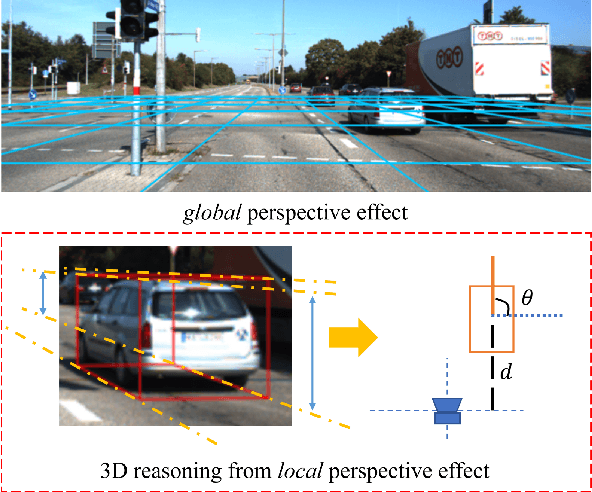
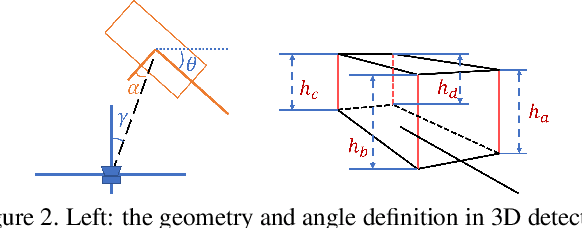
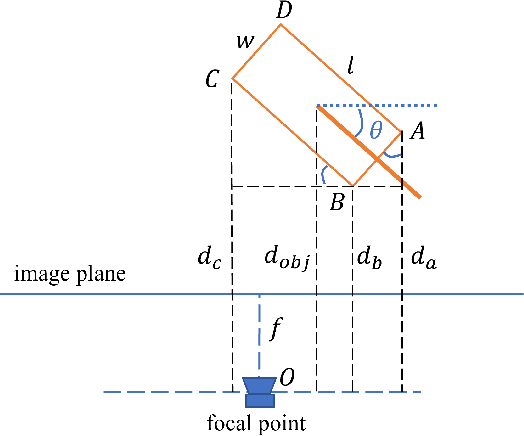
We propose a novel approach for monocular 3D object detection by leveraging local perspective effects of each object. While the global perspective effect shown as size and position variations has been exploited for monocular 3D detection extensively, the local perspectives has long been overlooked. We design a local perspective module to regress a newly defined variable named keyedge-ratios as the parameterization of the local shape distortion to account for the local perspective, and derive the object depth and yaw angle from it. Theoretically, this module does not rely on the pixel-wise size or position in the image of the objects, therefore independent of the camera intrinsic parameters. By plugging this module in existing monocular 3D object detection frameworks, we incorporate the local perspective distortion with global perspective effect for monocular 3D reasoning, and we demonstrate the effectiveness and superior performance over strong baseline methods in multiple datasets.
Neural Collapse in Deep Linear Network: From Balanced to Imbalanced Data
Jan 01, 2023
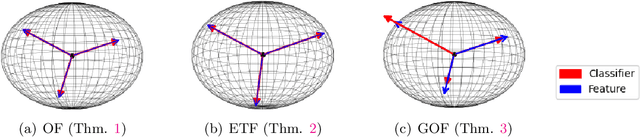
Modern deep neural networks have achieved superhuman performance in tasks from image classification to game play. Surprisingly, these various complex systems with massive amounts of parameters exhibit the same remarkable structural properties in their last-layer features and classifiers across canonical datasets. This phenomenon is known as "Neural Collapse," and it was discovered empirically by Papyan et al. \cite{Papyan20}. Recent papers have theoretically shown the global solutions to the training network problem under a simplified "unconstrained feature model" exhibiting this phenomenon. We take a step further and prove the Neural Collapse occurrence for deep linear network for the popular mean squared error (MSE) and cross entropy (CE) loss. Furthermore, we extend our research to imbalanced data for MSE loss and present the first geometric analysis for Neural Collapse under this setting.
Self-Supervised Object Segmentation with a Cut-and-Pasting GAN
Jan 01, 2023
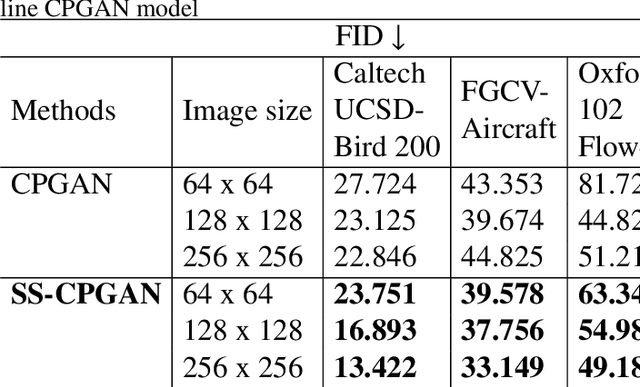
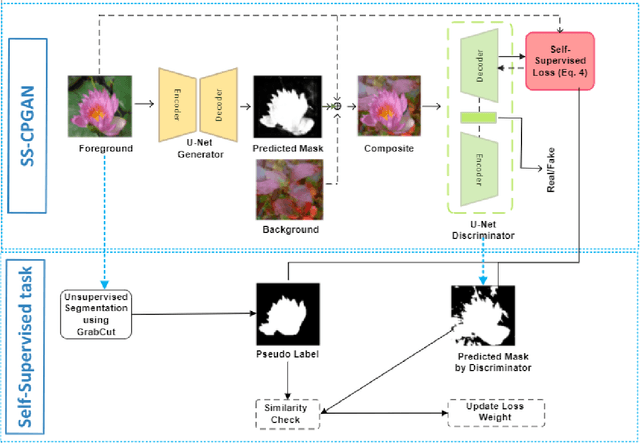
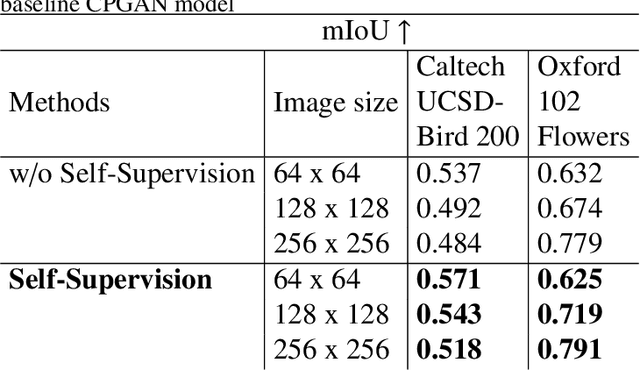
This paper proposes a novel self-supervised based Cut-and-Paste GAN to perform foreground object segmentation and generate realistic composite images without manual annotations. We accomplish this goal by a simple yet effective self-supervised approach coupled with the U-Net based discriminator. The proposed method extends the ability of the standard discriminators to learn not only the global data representations via classification (real/fake) but also learn semantic and structural information through pseudo labels created using the self-supervised task. The proposed method empowers the generator to create meaningful masks by forcing it to learn informative per-pixel as well as global image feedback from the discriminator. Our experiments demonstrate that our proposed method significantly outperforms the state-of-the-art methods on the standard benchmark datasets.
Interpretation of Neural Networks is Susceptible to Universal Adversarial Perturbations
Nov 30, 2022
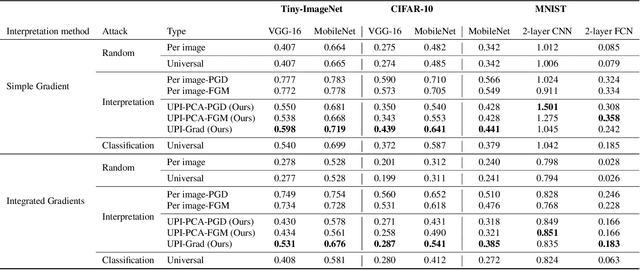
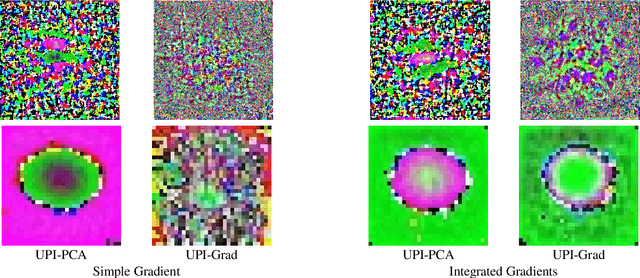
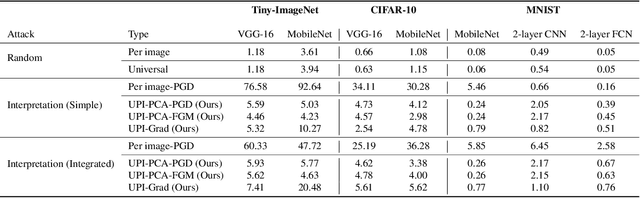
Interpreting neural network classifiers using gradient-based saliency maps has been extensively studied in the deep learning literature. While the existing algorithms manage to achieve satisfactory performance in application to standard image recognition datasets, recent works demonstrate the vulnerability of widely-used gradient-based interpretation schemes to norm-bounded perturbations adversarially designed for every individual input sample. However, such adversarial perturbations are commonly designed using the knowledge of an input sample, and hence perform sub-optimally in application to an unknown or constantly changing data point. In this paper, we show the existence of a Universal Perturbation for Interpretation (UPI) for standard image datasets, which can alter a gradient-based feature map of neural networks over a significant fraction of test samples. To design such a UPI, we propose a gradient-based optimization method as well as a principal component analysis (PCA)-based approach to compute a UPI which can effectively alter a neural network's gradient-based interpretation on different samples. We support the proposed UPI approaches by presenting several numerical results of their successful applications to standard image datasets.
Impact of Scaled Image on Robustness of Deep Neural Networks
Sep 02, 2022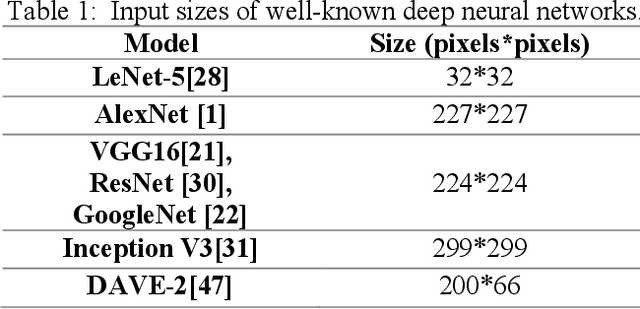


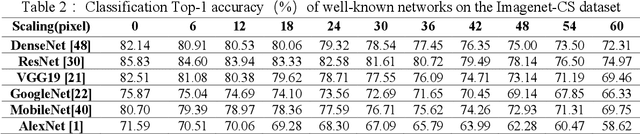
Deep neural networks (DNNs) have been widely used in computer vision tasks like image classification, object detection and segmentation. Whereas recent studies have shown their vulnerability to manual digital perturbations or distortion in the input images. The accuracy of the networks is remarkably influenced by the data distribution of their training dataset. Scaling the raw images creates out-of-distribution data, which makes it a possible adversarial attack to fool the networks. In this work, we propose a Scaling-distortion dataset ImageNet-CS by Scaling a subset of the ImageNet Challenge dataset by different multiples. The aim of our work is to study the impact of scaled images on the performance of advanced DNNs. We perform experiments on several state-of-the-art deep neural network architectures on the proposed ImageNet-CS, and the results show a significant positive correlation between scaling size and accuracy decline. Moreover, based on ResNet50 architecture, we demonstrate some tests on the performance of recent proposed robust training techniques and strategies like Augmix, Revisiting and Normalizer Free on our proposed ImageNet-CS. Experiment results have shown that these robust training techniques can improve networks' robustness to scaling transformation.
The applicability of transperceptual and deep learning approaches to the study and mimicry of complex cartilaginous tissues
Nov 21, 2022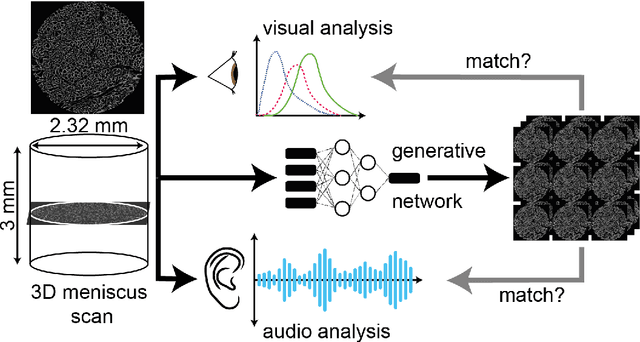

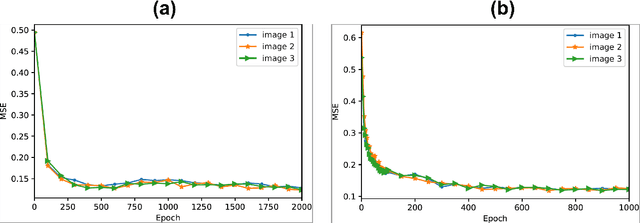
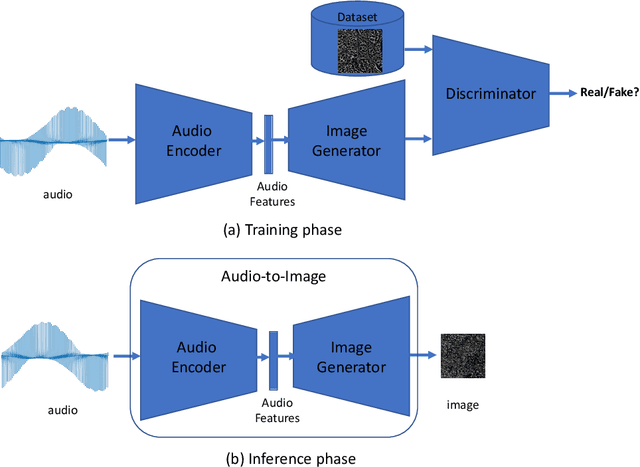
Complex soft tissues, for example the knee meniscus, play a crucial role in mobility and joint health, but when damaged are incredibly difficult to repair and replace. This is due to their highly hierarchical and porous nature which in turn leads to their unique mechanical properties. In order to design tissue substitutes, the internal architecture of the native tissue needs to be understood and replicated. Here we explore a combined audio-visual approach - so called transperceptual - to generate artificial architectures mimicking the native ones. The proposed method uses both traditional imagery, and sound generated from each image as a method of rapidly comparing and contrasting the porosity and pore size within the samples. We have trained and tested a generative adversarial network (GAN) on the 2D image stacks. The impact of the training set of images on the similarity of the artificial to the original dataset was assessed by analyzing two samples. The first consisting of n=478 pairs of audio and image files for which the images were downsampled to 64 $\times$ 64 pixels, the second one consisting of n=7640 pairs of audio and image files for which the full resolution 256 $\times$ 256 pixels is retained but each image is divided into 16 squares to maintain the limit of 64 $\times$ 64 pixels required by the GAN. We reconstruct the 2D stacks of artificially generated datasets into 3D objects and run image analysis algorithms to characterize statistically the architectural parameters - pore size, tortuosity and pore connectivity - and compare them with the original dataset. Results show that the artificially generated dataset that undergoes downsampling performs better in terms of parameter matching. Our audiovisual approach has the potential to be extended to larger data sets to explore both how similarities and differences can be audibly recognized across multiple samples.
ClipCrop: Conditioned Cropping Driven by Vision-Language Model
Nov 21, 2022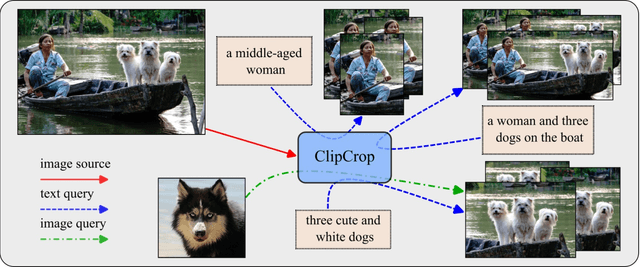
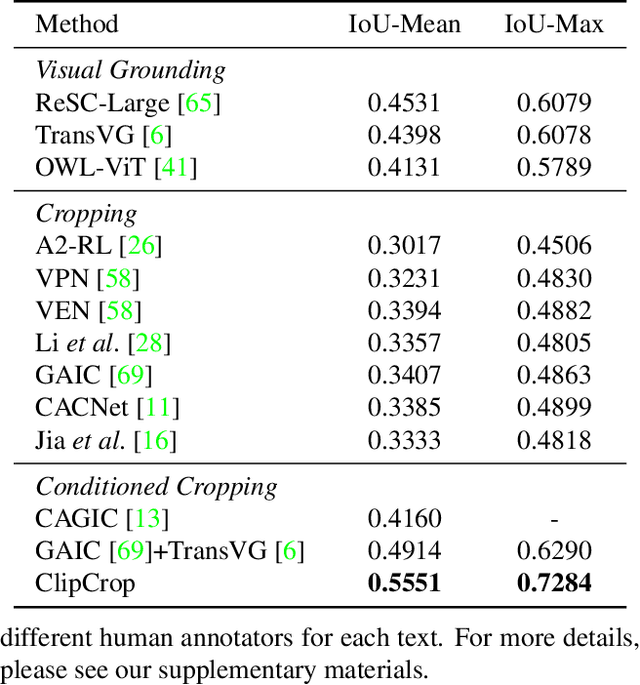
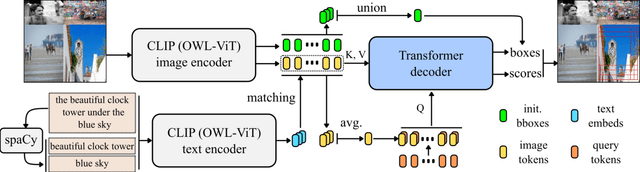
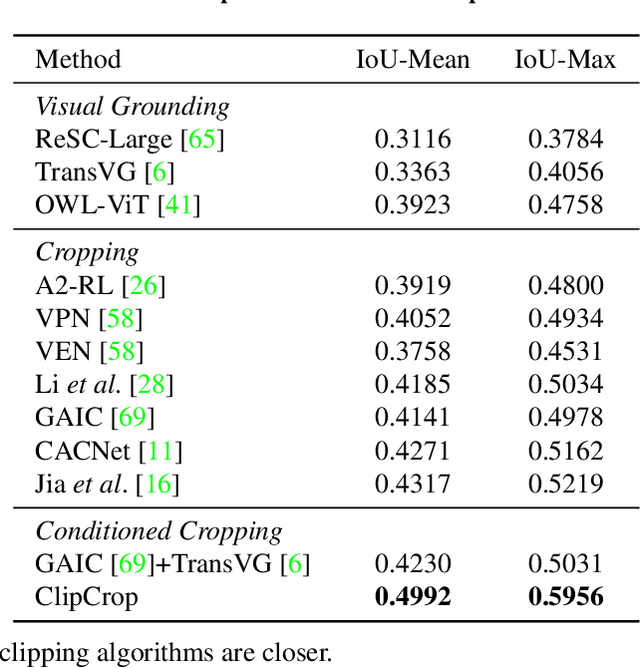
Image cropping has progressed tremendously under the data-driven paradigm. However, current approaches do not account for the intentions of the user, which is an issue especially when the composition of the input image is complex. Moreover, labeling of cropping data is costly and hence the amount of data is limited, leading to poor generalization performance of current algorithms in the wild. In this work, we take advantage of vision-language models as a foundation for creating robust and user-intentional cropping algorithms. By adapting a transformer decoder with a pre-trained CLIP-based detection model, OWL-ViT, we develop a method to perform cropping with a text or image query that reflects the user's intention as guidance. In addition, our pipeline design allows the model to learn text-conditioned aesthetic cropping with a small cropping dataset, while inheriting the open-vocabulary ability acquired from millions of text-image pairs. We validate our model through extensive experiments on existing datasets as well as a new cropping test set we compiled that is characterized by content ambiguity.