 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Symbiosis of an artificial neural network and models of biological neurons: training and testing
Feb 03, 2023
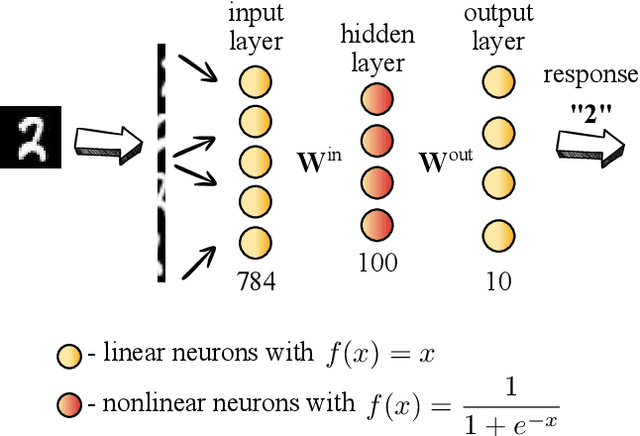
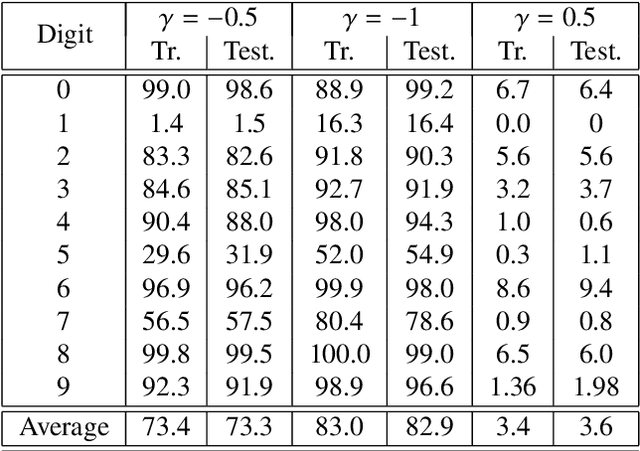
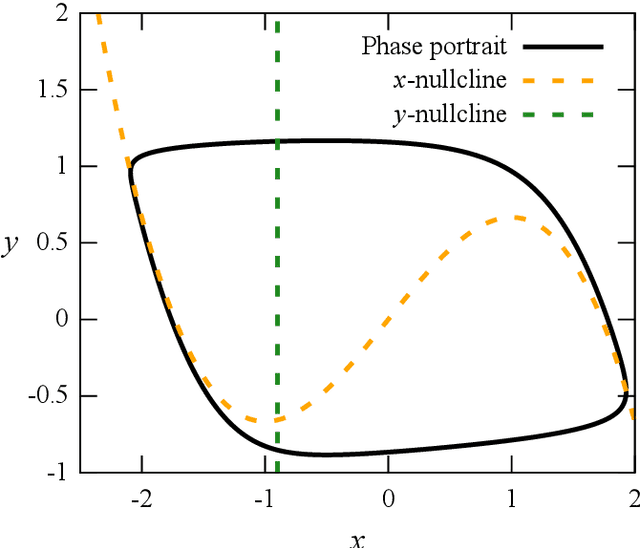
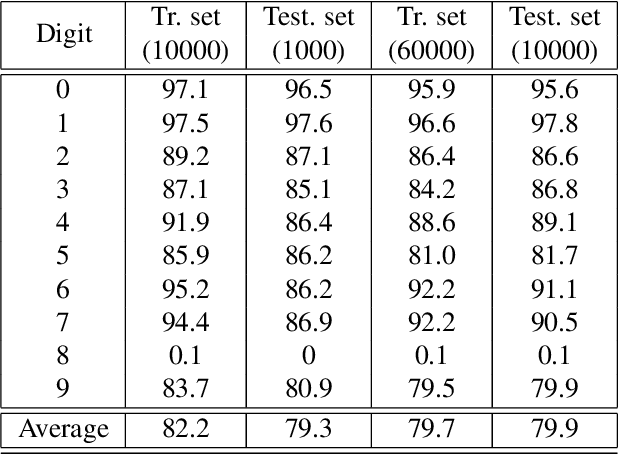
In this paper we show the possibility of creating and identifying the features of an artificial neural network (ANN) which consists of mathematical models of biological neurons. The FitzHugh--Nagumo (FHN) system is used as an example of model demonstrating simplified neuron activity. First, in order to reveal how biological neurons can be embedded within an ANN, we train the ANN with nonlinear neurons to solve a a basic image recognition problem with MNIST database; and next, we describe how FHN systems can be introduced into this trained ANN. After all, we show that an ANN with FHN systems inside can be successfully trained and its accuracy becomes larger. What has been done above opens up great opportunities in terms of the direction of analog neural networks, in which artificial neurons can be replaced by biological ones. \end{abstract}
Isotopic envelope identification by analysis of the spatial distribution of components in MALDI-MSI data
Feb 14, 2023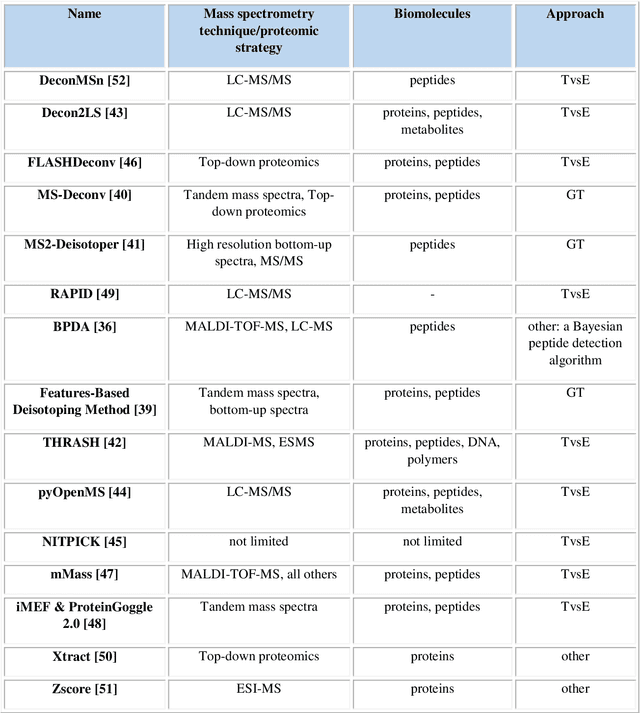
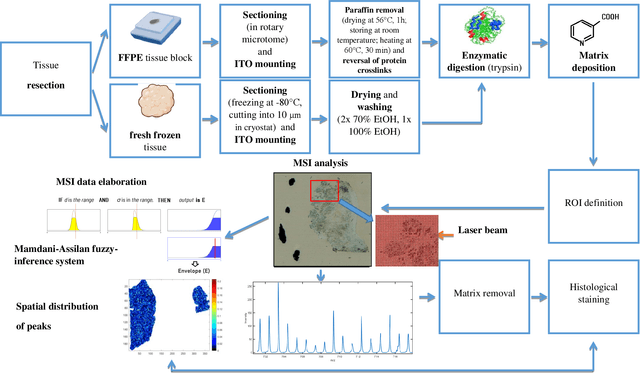
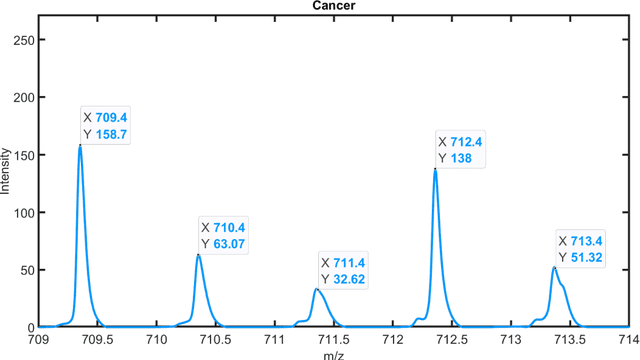
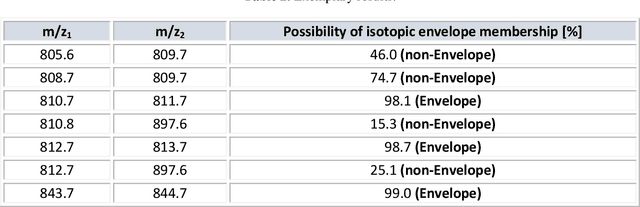
One of the significant steps in the process leading to the identification of proteins is mass spectrometry, which allows for obtaining information about the structure of proteins. Removing isotope peaks from the mass spectrum is vital and it is done in a process called deisotoping. There are different algorithms for deisotoping, but they have their limitations, they are dedicated to different methods of mass spectrometry. Data from experiments performed with the MALDI-ToF technique are characterized by high dimensionality. This paper presents a method for identifying isotope envelopes in MALDI-ToF molecular imaging data based on the Mamdani-Assilan fuzzy system and spatial maps of the molecular distribution of peaks included in the isotopic envelope. Several image texture measures were used to evaluate spatial molecular distribution maps. The algorithm was tested on eight datasets obtained from the MALDI-ToF experiment on samples from the National Institute of Oncology in Gliwice from patients with cancer of the head and neck region. The data were subjected to pre-processing and feature extraction. The results were collected and compared with three existing deisotoping algorithms. The analysis of the obtained results showed that the method for identifying isotopic envelopes proposed in this paper enables the detection of overlapping envelopes by using the approach oriented to study peak pairs. Moreover, the proposed algorithm enables the analysis of large data sets.
Mimicking non-ideal instrument behavior for hologram processing using neural style translation
Jan 07, 2023

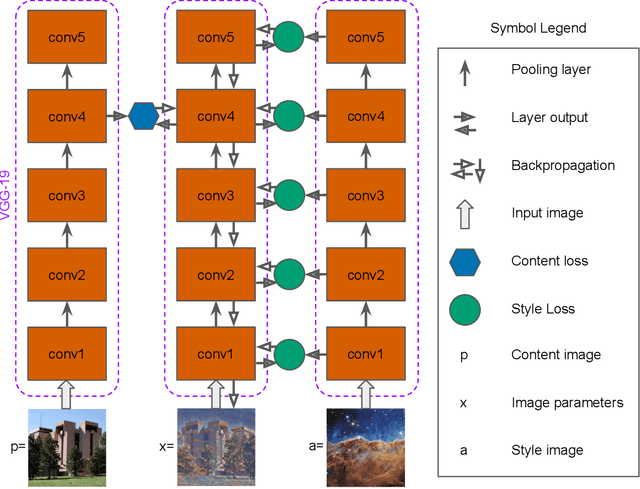
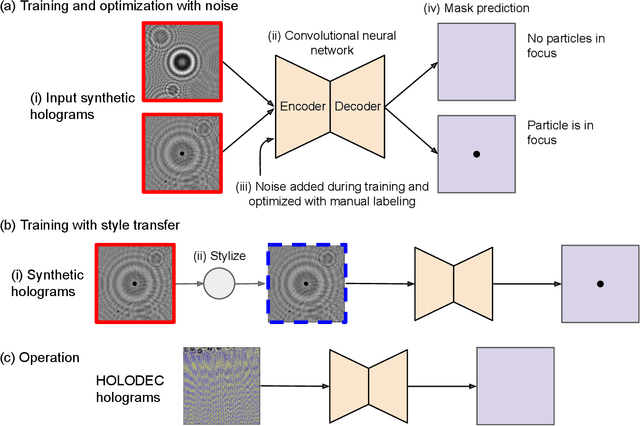
Holographic cloud probes provide unprecedented information on cloud particle density, size and position. Each laser shot captures particles within a large volume, where images can be computationally refocused to determine particle size and shape. However, processing these holograms, either with standard methods or with machine learning (ML) models, requires considerable computational resources, time and occasional human intervention. ML models are trained on simulated holograms obtained from the physical model of the probe since real holograms have no absolute truth labels. Using another processing method to produce labels would be subject to errors that the ML model would subsequently inherit. Models perform well on real holograms only when image corruption is performed on the simulated images during training, thereby mimicking non-ideal conditions in the actual probe (Schreck et. al, 2022). Optimizing image corruption requires a cumbersome manual labeling effort. Here we demonstrate the application of the neural style translation approach (Gatys et. al, 2016) to the simulated holograms. With a pre-trained convolutional neural network (VGG-19), the simulated holograms are ``stylized'' to resemble the real ones obtained from the probe, while at the same time preserving the simulated image ``content'' (e.g. the particle locations and sizes). Two image similarity metrics concur that the stylized images are more like real holograms than the synthetic ones. With an ML model trained to predict particle locations and shapes on the stylized data sets, we observed comparable performance on both simulated and real holograms, obviating the need to perform manual labeling. The described approach is not specific to hologram images and could be applied in other domains for capturing noise and imperfections in observational instruments to make simulated data more like real world observations.
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 10, 2023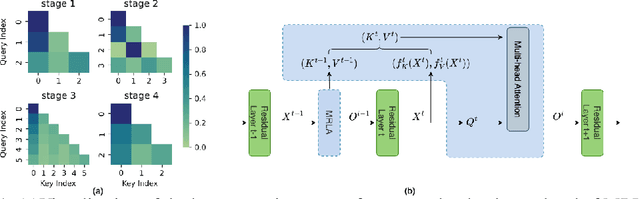
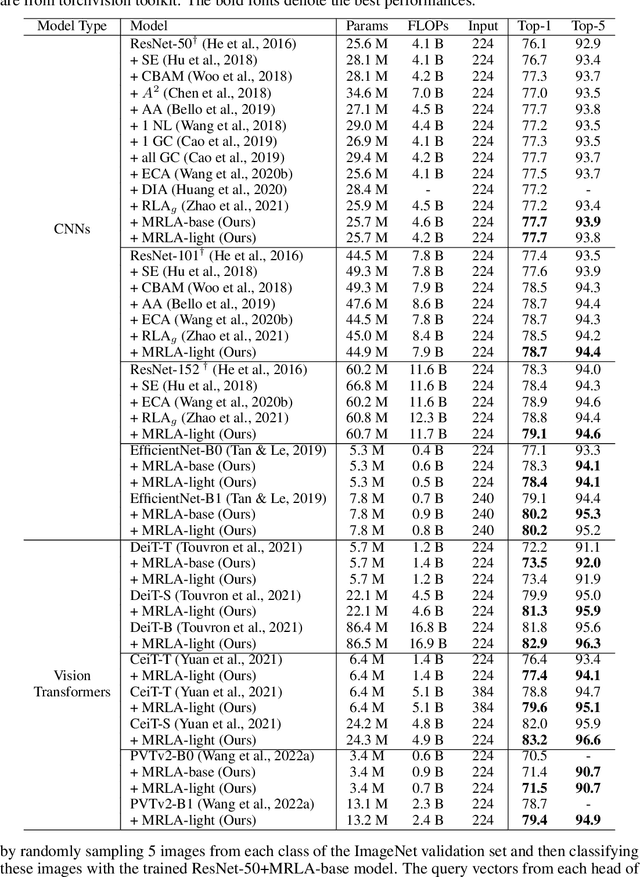
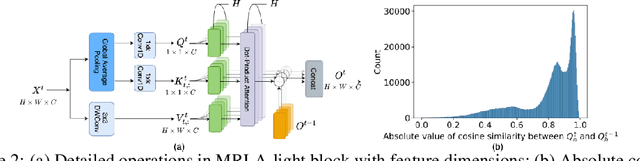
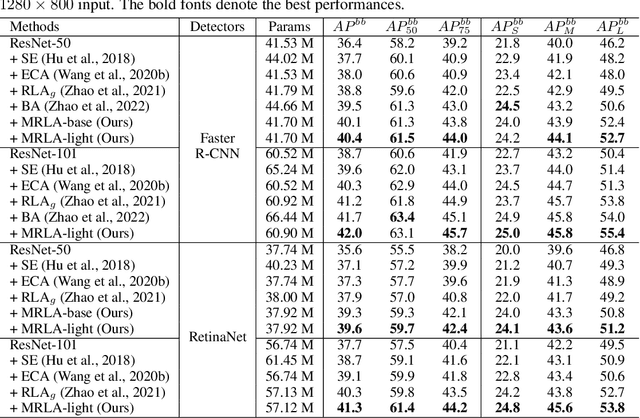
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
Confidence-based Reliable Learning under Dual Noises
Feb 10, 2023
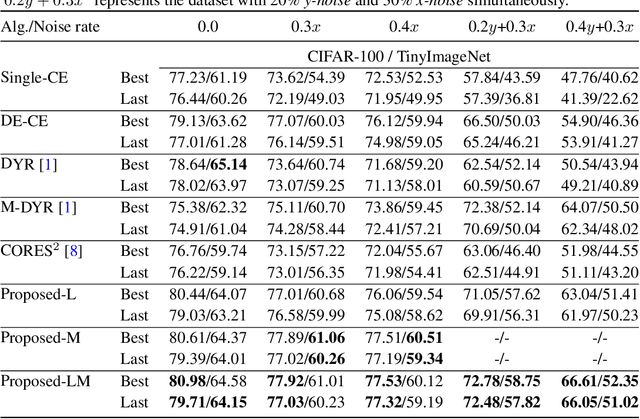
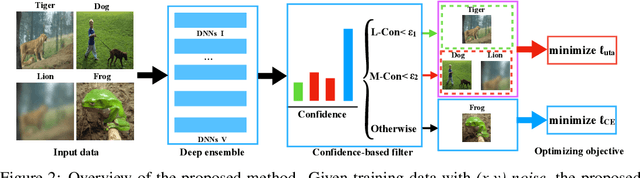

Deep neural networks (DNNs) have achieved remarkable success in a variety of computer vision tasks, where massive labeled images are routinely required for model optimization. Yet, the data collected from the open world are unavoidably polluted by noise, which may significantly undermine the efficacy of the learned models. Various attempts have been made to reliably train DNNs under data noise, but they separately account for either the noise existing in the labels or that existing in the images. A naive combination of the two lines of works would suffer from the limitations in both sides, and miss the opportunities to handle the two kinds of noise in parallel. This work provides a first, unified framework for reliable learning under the joint (image, label)-noise. Technically, we develop a confidence-based sample filter to progressively filter out noisy data without the need of pre-specifying noise ratio. Then, we penalize the model uncertainty of the detected noisy data instead of letting the model continue over-fitting the misleading information in them. Experimental results on various challenging synthetic and real-world noisy datasets verify that the proposed method can outperform competing baselines in the aspect of classification performance.
Characterizing the Entities in Harmful Memes: Who is the Hero, the Villain, the Victim?
Jan 26, 2023
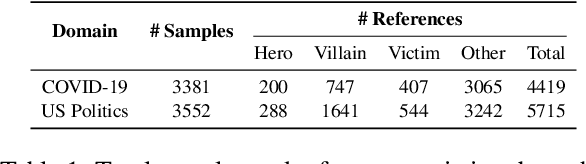
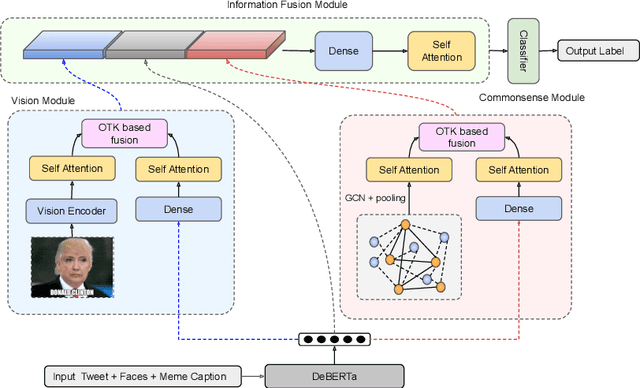
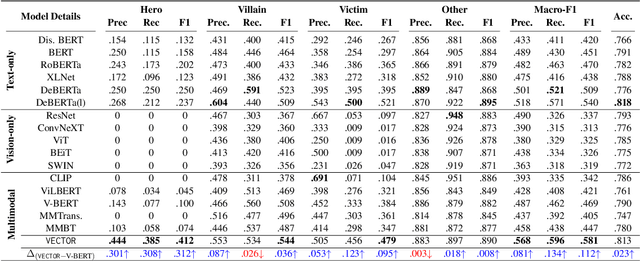
Memes can sway people's opinions over social media as they combine visual and textual information in an easy-to-consume manner. Since memes instantly turn viral, it becomes crucial to infer their intent and potentially associated harmfulness to take timely measures as needed. A common problem associated with meme comprehension lies in detecting the entities referenced and characterizing the role of each of these entities. Here, we aim to understand whether the meme glorifies, vilifies, or victimizes each entity it refers to. To this end, we address the task of role identification of entities in harmful memes, i.e., detecting who is the 'hero', the 'villain', and the 'victim' in the meme, if any. We utilize HVVMemes - a memes dataset on US Politics and Covid-19 memes, released recently as part of the CONSTRAINT@ACL-2022 shared-task. It contains memes, entities referenced, and their associated roles: hero, villain, victim, and other. We further design VECTOR (Visual-semantic role dEteCToR), a robust multi-modal framework for the task, which integrates entity-based contextual information in the multi-modal representation and compare it to several standard unimodal (text-only or image-only) or multi-modal (image+text) models. Our experimental results show that our proposed model achieves an improvement of 4% over the best baseline and 1% over the best competing stand-alone submission from the shared-task. Besides divulging an extensive experimental setup with comparative analyses, we finally highlight the challenges encountered in addressing the complex task of semantic role labeling within memes.
Real Image Restoration via Structure-preserving Complementarity Attention
Jul 28, 2022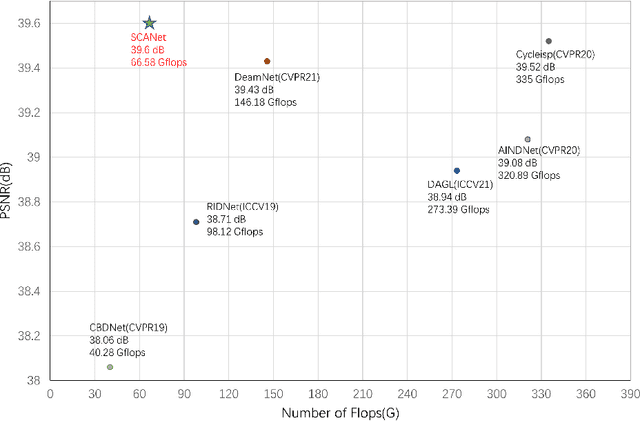
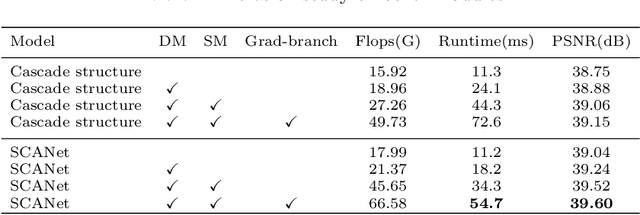
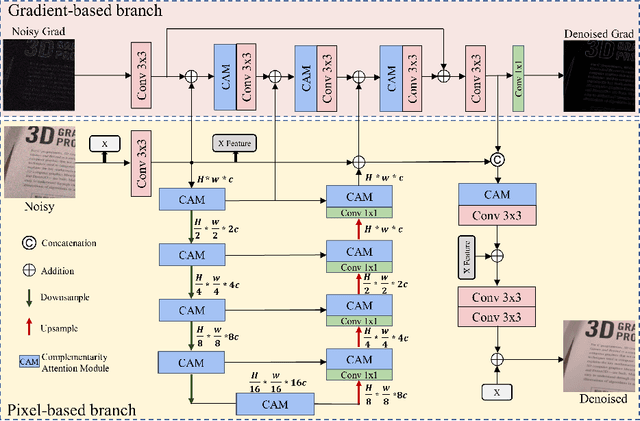

Since convolutional neural networks perform well in learning generalizable image priors from large-scale data, these models have been widely used in image denoising tasks. However, the computational complexity increases dramatically as well on complex model. In this paper, We propose a novel lightweight Complementary Attention Module, which includes a density module and a sparse module, which can cooperatively mine dense and sparse features for feature complementary learning to build an efficient lightweight architecture. Moreover, to reduce the loss of details caused by denoising, this paper constructs a gradient-based structure-preserving branch. We utilize gradient-based branches to obtain additional structural priors for denoising, and make the model pay more attention to image geometric details through gradient loss optimization.Based on the above, we propose an efficiently Unet structured network with dual branch, the visual results show that can effectively preserve the structural details of the original image, we evaluate benchmarks including SIDD and DND, where SCANet achieves state-of-the-art performance in PSNR and SSIM while significantly reducing computational cost.
Rethinking the Reference-based Distinctive Image Captioning
Jul 22, 2022
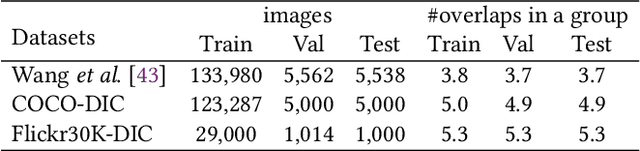
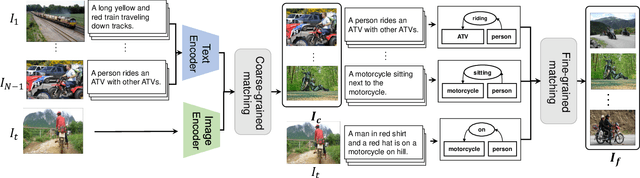
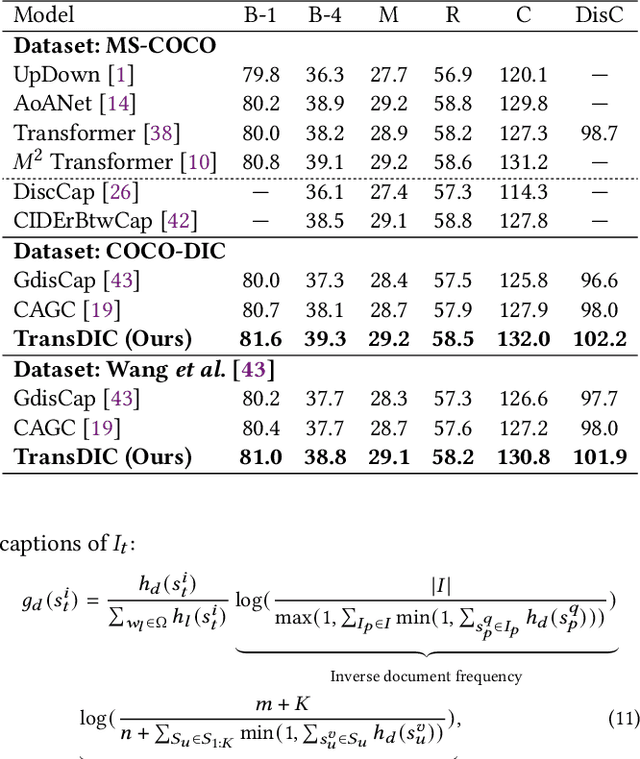
Distinctive Image Captioning (DIC) -- generating distinctive captions that describe the unique details of a target image -- has received considerable attention over the last few years. A recent DIC work proposes to generate distinctive captions by comparing the target image with a set of semantic-similar reference images, i.e., reference-based DIC (Ref-DIC). It aims to make the generated captions can tell apart the target and reference images. Unfortunately, reference images used by existing Ref-DIC works are easy to distinguish: these reference images only resemble the target image at scene-level and have few common objects, such that a Ref-DIC model can trivially generate distinctive captions even without considering the reference images. To ensure Ref-DIC models really perceive the unique objects (or attributes) in target images, we first propose two new Ref-DIC benchmarks. Specifically, we design a two-stage matching mechanism, which strictly controls the similarity between the target and reference images at object-/attribute- level (vs. scene-level). Secondly, to generate distinctive captions, we develop a strong Transformer-based Ref-DIC baseline, dubbed as TransDIC. It not only extracts visual features from the target image, but also encodes the differences between objects in the target and reference images. Finally, for more trustworthy benchmarking, we propose a new evaluation metric named DisCIDEr for Ref-DIC, which evaluates both the accuracy and distinctiveness of the generated captions. Experimental results demonstrate that our TransDIC can generate distinctive captions. Besides, it outperforms several state-of-the-art models on the two new benchmarks over different metrics.
Deep Residual Axial Networks
Jan 11, 2023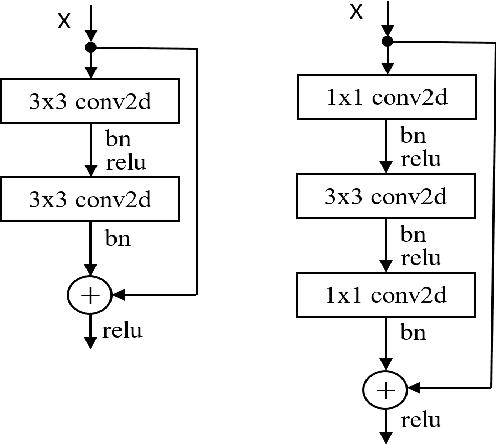
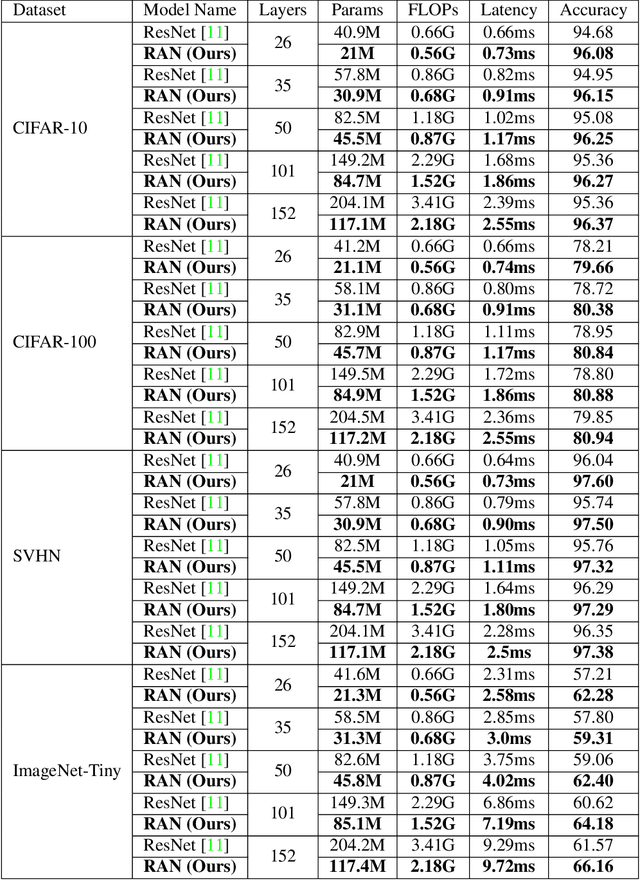
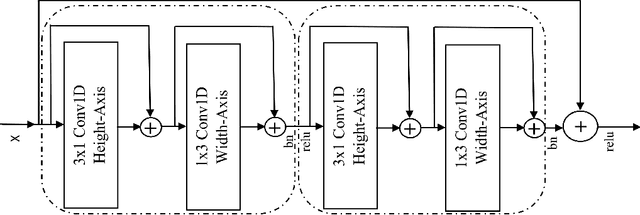
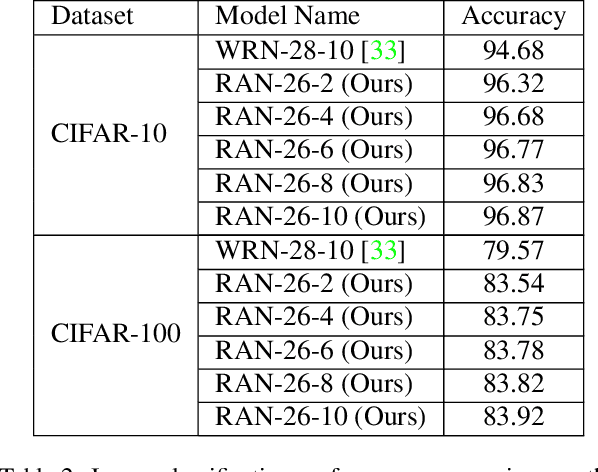
While residual networks (ResNets) demonstrate outstanding performance on computer vision tasks, their computational cost still remains high. Here, we focus on reducing this cost by proposing a new network architecture, axial ResNet, which replaces spatial 2D convolution operations with two consecutive 1D convolution operations. Convergence of very deep axial ResNets has faced degradation problems which prevent the networks from performing efficiently. To mitigate this, we apply a residual connection to each 1D convolutional operation and propose our final novel architecture namely residual axial networks (RANs). Extensive benchmark evaluation shows that RANs outperform with about 49% fewer parameters than ResNets on CIFAR benchmarks, SVHN, and Tiny ImageNet image classification datasets. Moreover, our proposed RANs show significant improvement in validation performance in comparison to the wide ResNets on CIFAR benchmarks and the deep recursive residual networks on image super-resolution dataset.
Deep Learning for Event-based Vision: A Comprehensive Survey and Benchmarks
Feb 17, 2023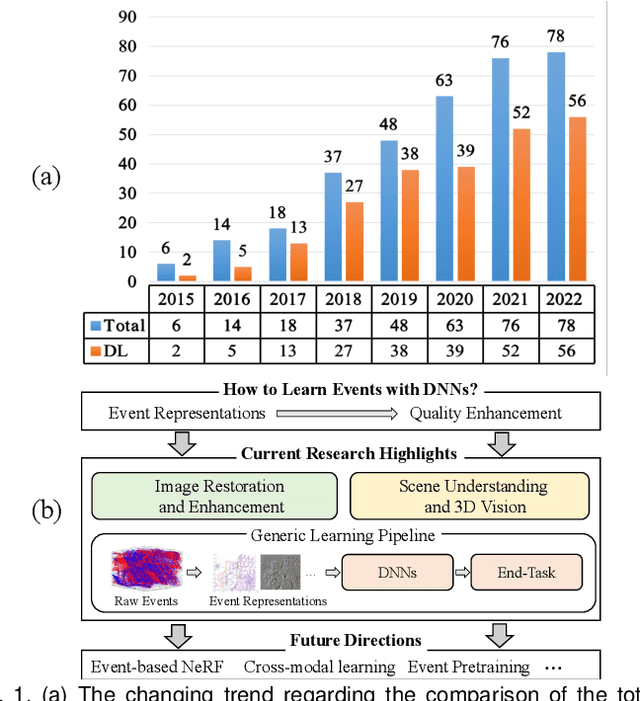
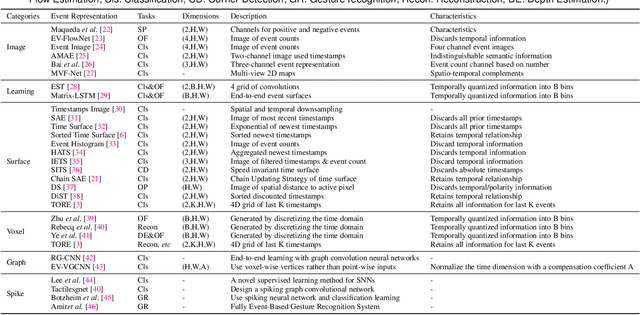

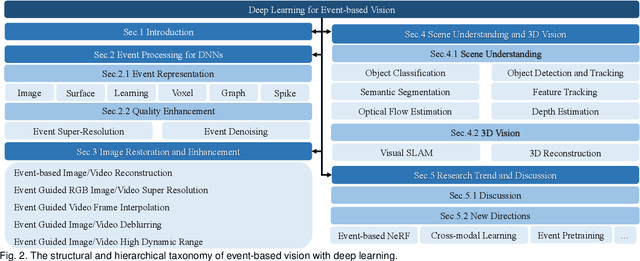
Event cameras are bio-inspired sensors that capture the per-pixel intensity changes asynchronously and produce event streams encoding the time, pixel position, and polarity (sign) of the intensity changes. Event cameras possess a myriad of advantages over canonical frame-based cameras, such as high temporal resolution, high dynamic range, low latency, etc. Being capable of capturing information in challenging visual conditions, event cameras have the potential to overcome the limitations of frame-based cameras in the computer vision and robotics community. In very recent years, deep learning (DL) has been brought to this emerging field and inspired active research endeavors in mining its potential. However, the technical advances still remain unknown, thus making it urgent and necessary to conduct a systematic overview. To this end, we conduct the first yet comprehensive and in-depth survey, with a focus on the latest developments of DL techniques for event-based vision. We first scrutinize the typical event representations with quality enhancement methods as they play a pivotal role as inputs to the DL models. We then provide a comprehensive taxonomy for existing DL-based methods by structurally grouping them into two major categories: 1) image reconstruction and restoration; 2) event-based scene understanding 3D vision. Importantly, we conduct benchmark experiments for the existing methods in some representative research directions (eg, object recognition and optical flow estimation) to identify some critical insights and problems. Finally, we make important discussions regarding the challenges and provide new perspectives for motivating future research studies.