 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Design of an Adaptive Lightweight LiDAR to Decouple Robot-Camera Geometry
Feb 28, 2023
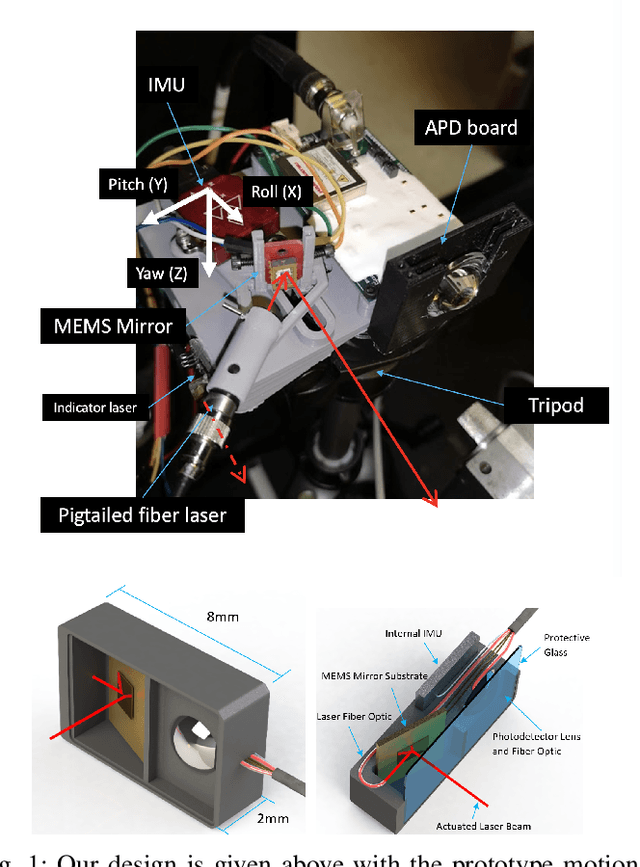
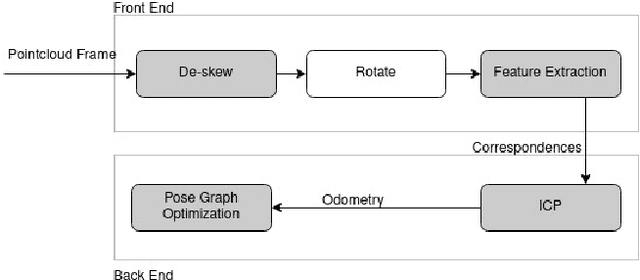
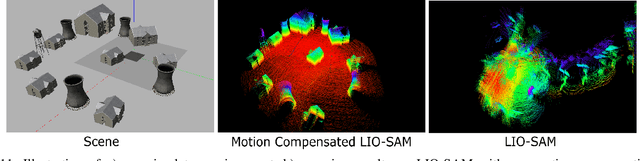
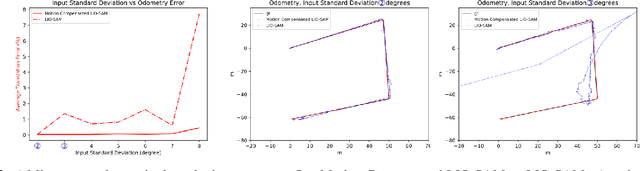
A fundamental challenge in robot perception is the coupling of the sensor pose and robot pose. This has led to research in active vision where robot pose is changed to reorient the sensor to areas of interest for perception. Further, egomotion such as jitter, and external effects such as wind and others affect perception requiring additional effort in software such as image stabilization. This effect is particularly pronounced in micro-air vehicles and micro-robots who typically are lighter and subject to larger jitter but do not have the computational capability to perform stabilization in real-time. We present a novel microelectromechanical (MEMS) mirror LiDAR system to change the field of view of the LiDAR independent of the robot motion. Our design has the potential for use on small, low-power systems where the expensive components of the LiDAR can be placed external to the small robot. We show the utility of our approach in simulation and on prototype hardware mounted on a UAV. We believe that this LiDAR and its compact movable scanning design provide mechanisms to decouple robot and sensor geometry allowing us to simplify robot perception. We also demonstrate examples of motion compensation using IMU and external odometry feedback in hardware.
Memory-aided Contrastive Consensus Learning for Co-salient Object Detection
Feb 28, 2023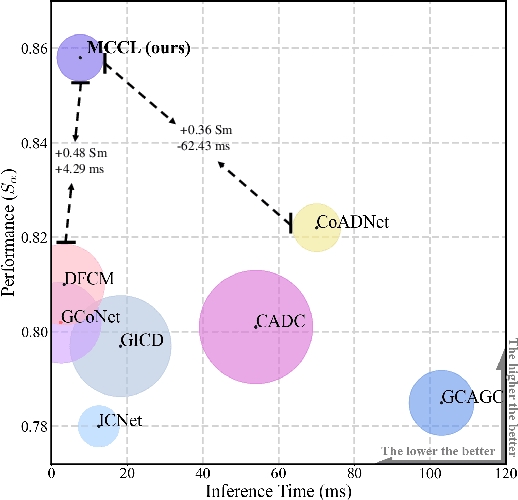
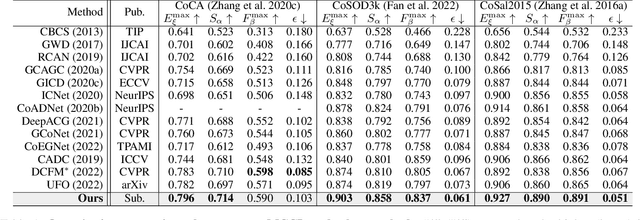
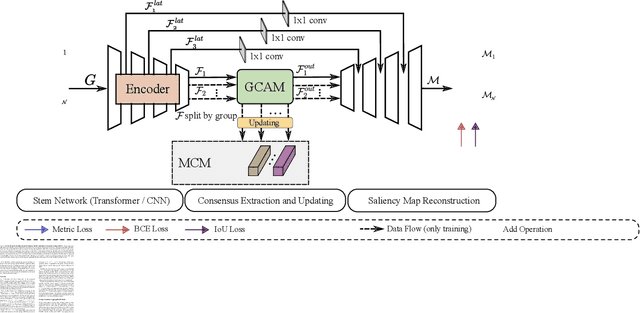

Co-Salient Object Detection (CoSOD) aims at detecting common salient objects within a group of relevant source images. Most of the latest works employ the attention mechanism for finding common objects. To achieve accurate CoSOD results with high-quality maps and high efficiency, we propose a novel Memory-aided Contrastive Consensus Learning (MCCL) framework, which is capable of effectively detecting co-salient objects in real time (~110 fps). To learn better group consensus, we propose the Group Consensus Aggregation Module (GCAM) to abstract the common features of each image group; meanwhile, to make the consensus representation more discriminative, we introduce the Memory-based Contrastive Module (MCM), which saves and updates the consensus of images from different groups in a queue of memories. Finally, to improve the quality and integrity of the predicted maps, we develop an Adversarial Integrity Learning (AIL) strategy to make the segmented regions more likely composed of complete objects with less surrounding noise. Extensive experiments on all the latest CoSOD benchmarks demonstrate that our lite MCCL outperforms 13 cutting-edge models, achieving the new state of the art (~5.9% and ~6.2% improvement in S-measure on CoSOD3k and CoSal2015, respectively). Our source codes, saliency maps, and online demos are publicly available at https://github.com/ZhengPeng7/MCCL.
Unsupervised Discovery of Semantic Latent Directions in Diffusion Models
Feb 24, 2023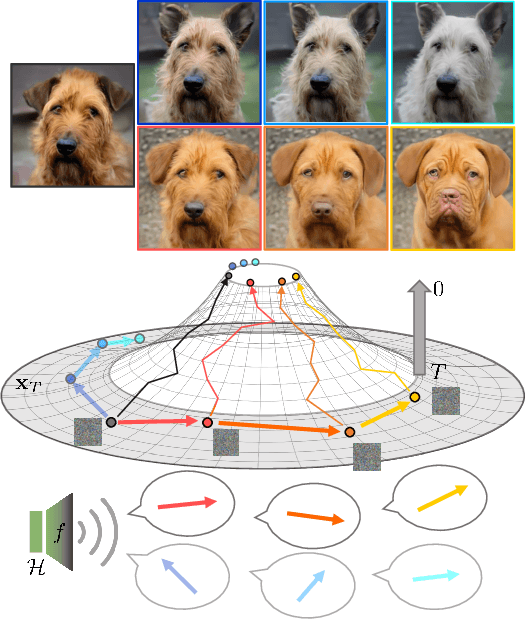
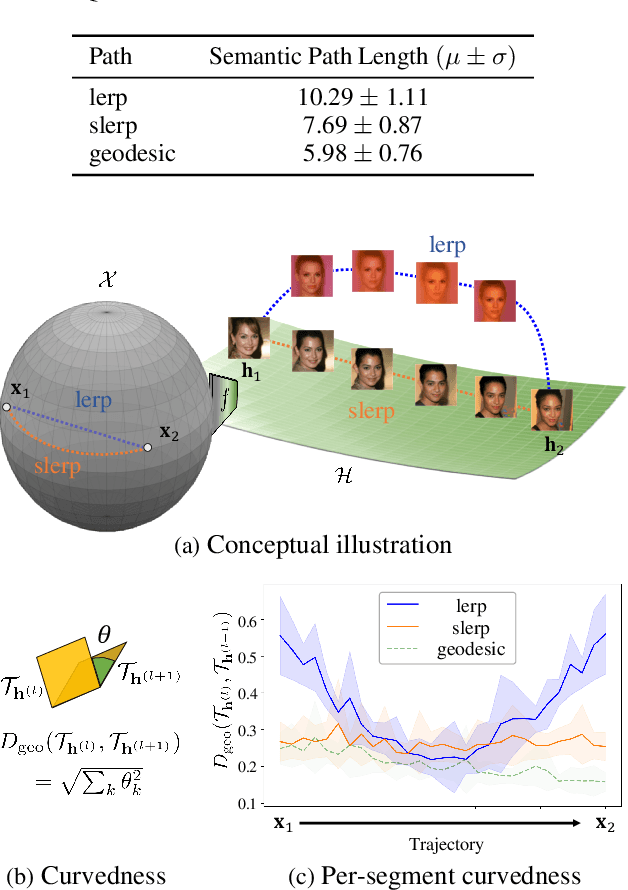


Despite the success of diffusion models (DMs), we still lack a thorough understanding of their latent space. While image editing with GANs builds upon latent space, DMs rely on editing the conditions such as text prompts. We present an unsupervised method to discover interpretable editing directions for the latent variables $\mathbf{x}_t \in \mathcal{X}$ of DMs. Our method adopts Riemannian geometry between $\mathcal{X}$ and the intermediate feature maps $\mathcal{H}$ of the U-Nets to provide a deep understanding over the geometrical structure of $\mathcal{X}$. The discovered semantic latent directions mostly yield disentangled attribute changes, and they are globally consistent across different samples. Furthermore, editing in earlier timesteps edits coarse attributes, while ones in later timesteps focus on high-frequency details. We define the curvedness of a line segment between samples to show that $\mathcal{X}$ is a curved manifold. Experiments on different baselines and datasets demonstrate the effectiveness of our method even on Stable Diffusion. Our source code will be publicly available for the future researchers.
A relaxed proximal gradient descent algorithm for convergent plug-and-play with proximal denoiser
Jan 31, 2023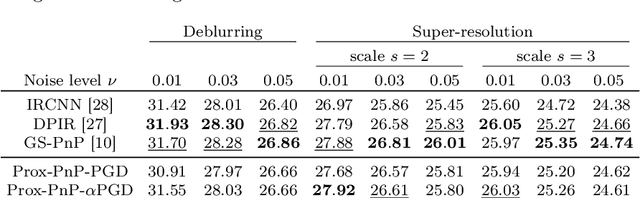
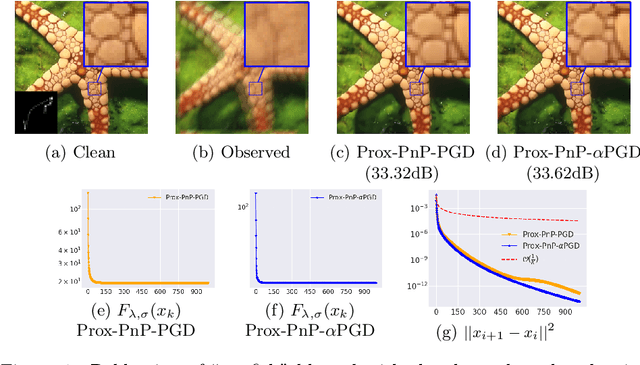
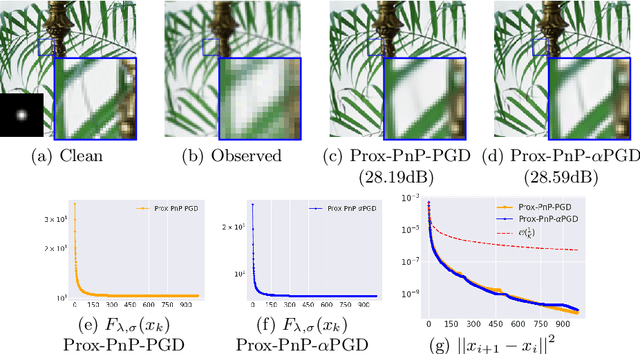
This paper presents a new convergent Plug-and-Play (PnP) algorithm. PnP methods are efficient iterative algorithms for solving image inverse problems formulated as the minimization of the sum of a data-fidelity term and a regularization term. PnP methods perform regularization by plugging a pre-trained denoiser in a proximal algorithm, such as Proximal Gradient Descent (PGD). To ensure convergence of PnP schemes, many works study specific parametrizations of deep denoisers. However, existing results require either unverifiable or suboptimal hypotheses on the denoiser, or assume restrictive conditions on the parameters of the inverse problem. Observing that these limitations can be due to the proximal algorithm in use, we study a relaxed version of the PGD algorithm for minimizing the sum of a convex function and a weakly convex one. When plugged with a relaxed proximal denoiser, we show that the proposed PnP-$\alpha$PGD algorithm converges for a wider range of regularization parameters, thus allowing more accurate image restoration.
Few-shot Image Generation via Adaptation-Aware Kernel Modulation
Nov 13, 2022
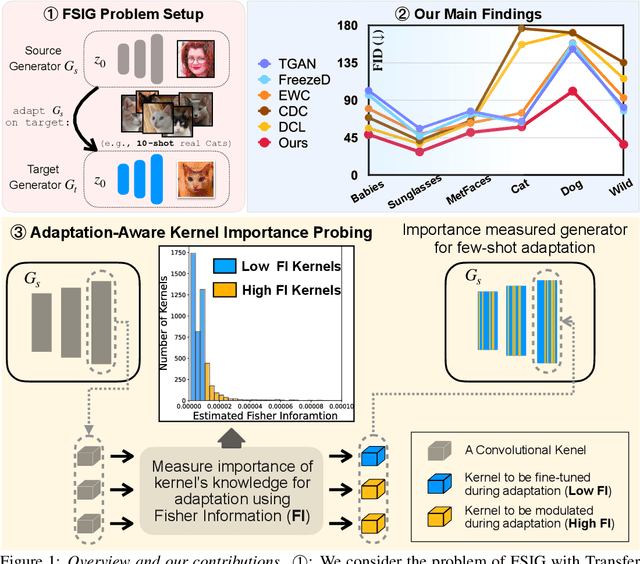
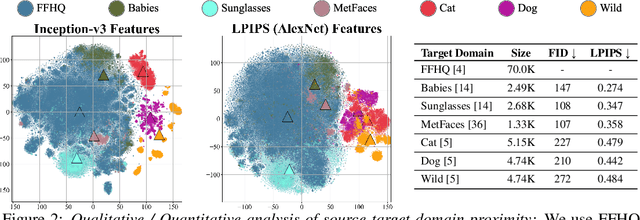
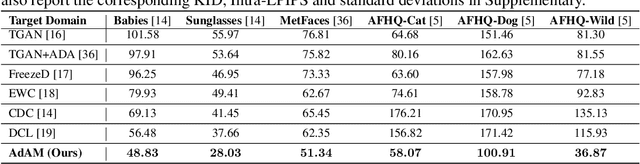
Few-shot image generation (FSIG) aims to learn to generate new and diverse samples given an extremely limited number of samples from a domain, e.g., 10 training samples. Recent work has addressed the problem using transfer learning approach, leveraging a GAN pretrained on a large-scale source domain dataset and adapting that model to the target domain based on very limited target domain samples. Central to recent FSIG methods are knowledge preserving criteria, which aim to select a subset of source model's knowledge to be preserved into the adapted model. However, a major limitation of existing methods is that their knowledge preserving criteria consider only source domain/source task, and they fail to consider target domain/adaptation task in selecting source model's knowledge, casting doubt on their suitability for setups of different proximity between source and target domain. Our work makes two contributions. As our first contribution, we re-visit recent FSIG works and their experiments. Our important finding is that, under setups which assumption of close proximity between source and target domains is relaxed, existing state-of-the-art (SOTA) methods which consider only source domain/source task in knowledge preserving perform no better than a baseline fine-tuning method. To address the limitation of existing methods, as our second contribution, we propose Adaptation-Aware kernel Modulation (AdAM) to address general FSIG of different source-target domain proximity. Extensive experimental results show that the proposed method consistently achieves SOTA performance across source/target domains of different proximity, including challenging setups when source and target domains are more apart. Project Page: https://yunqing-me.github.io/AdAM/
Multi-domain stain normalization for digital pathology: A cycle-consistent adversarial network for whole slide images
Jan 23, 2023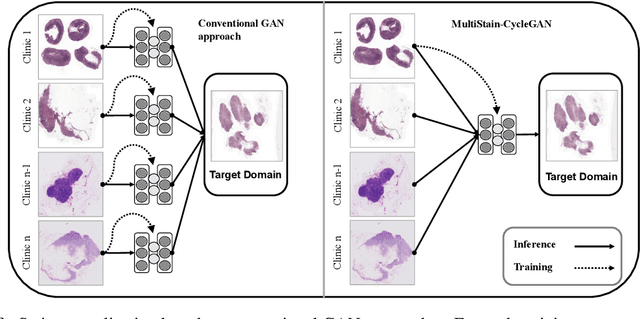
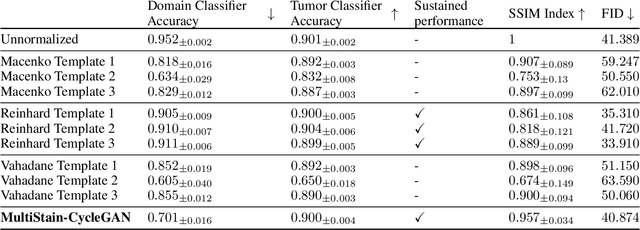
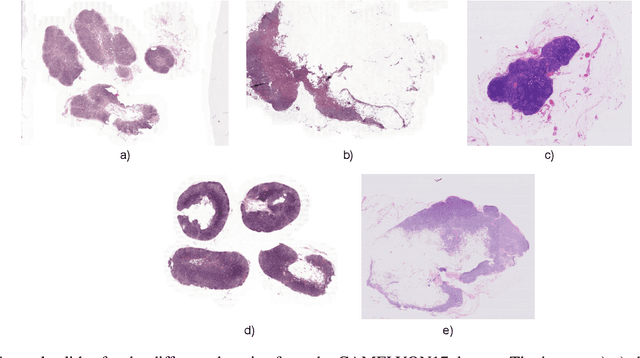
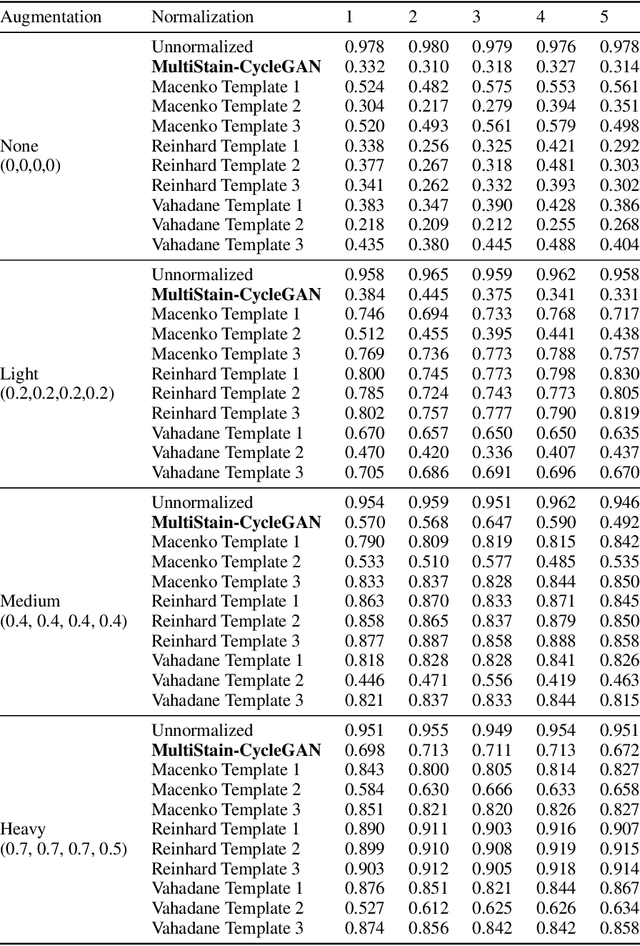
The variation in histologic staining between different medical centers is one of the most profound challenges in the field of computer-aided diagnosis. The appearance disparity of pathological whole slide images causes algorithms to become less reliable, which in turn impedes the wide-spread applicability of downstream tasks like cancer diagnosis. Furthermore, different stainings lead to biases in the training which in case of domain shifts negatively affect the test performance. Therefore, in this paper we propose MultiStain-CycleGAN, a multi-domain approach to stain normalization based on CycleGAN. Our modifications to CycleGAN allow us to normalize images of different origins without retraining or using different models. We perform an extensive evaluation of our method using various metrics and compare it to commonly used methods that are multi-domain capable. First, we evaluate how well our method fools a domain classifier that tries to assign a medical center to an image. Then, we test our normalization on the tumor classification performance of a downstream classifier. Furthermore, we evaluate the image quality of the normalized images using the Structural similarity index and the ability to reduce the domain shift using the Fr\'echet inception distance. We show that our method proves to be multi-domain capable, provides the highest image quality among the compared methods, and can most reliably fool the domain classifier while keeping the tumor classifier performance high. By reducing the domain influence, biases in the data can be removed on the one hand and the origin of the whole slide image can be disguised on the other, thus enhancing patient data privacy.
Breaking Free from Fusion Rule: A Fully Semantic-driven Infrared and Visible Image Fusion
Nov 22, 2022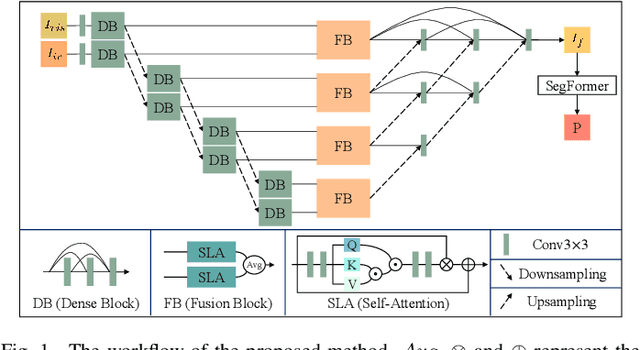

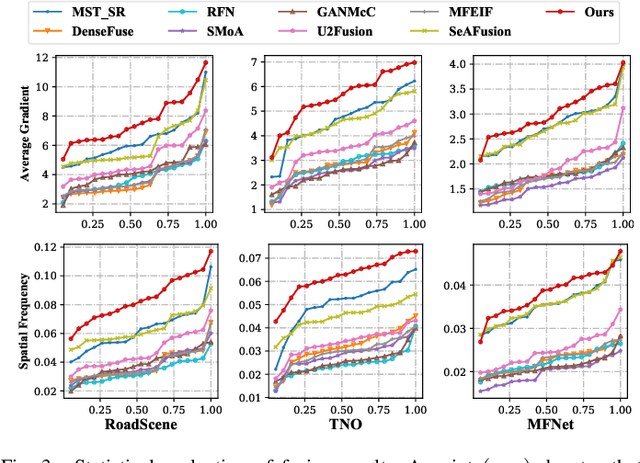
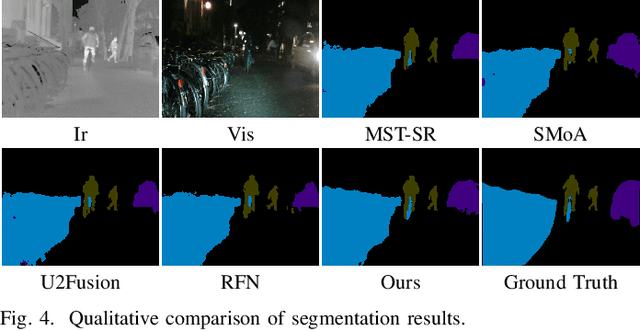
Infrared and visible image fusion plays a vital role in the field of computer vision. Previous approaches make efforts to design various fusion rules in the loss functions. However, these experimental designed fusion rules make the methods more and more complex. Besides, most of them only focus on boosting the visual effects, thus showing unsatisfactory performance for the follow-up high-level vision tasks. To address these challenges, in this letter, we develop a semantic-level fusion network to sufficiently utilize the semantic guidance, emancipating the experimental designed fusion rules. In addition, to achieve a better semantic understanding of the feature fusion process, a fusion block based on the transformer is presented in a multi-scale manner. Moreover, we devise a regularization loss function, together with a training strategy, to fully use semantic guidance from the high-level vision tasks. Compared with state-of-the-art methods, our method does not depend on the hand-crafted fusion loss function. Still, it achieves superior performance on visual quality along with the follow-up high-level vision tasks.
Are Diffusion Models Vulnerable to Membership Inference Attacks?
Feb 02, 2023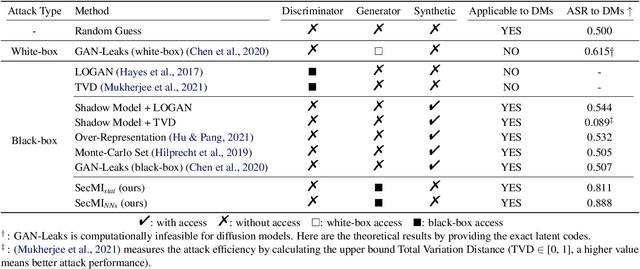
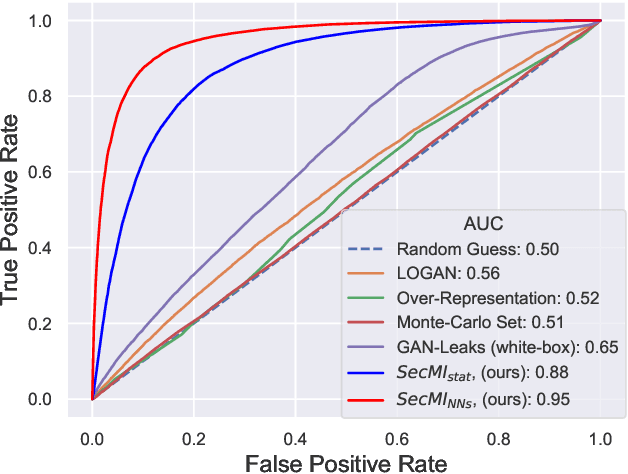
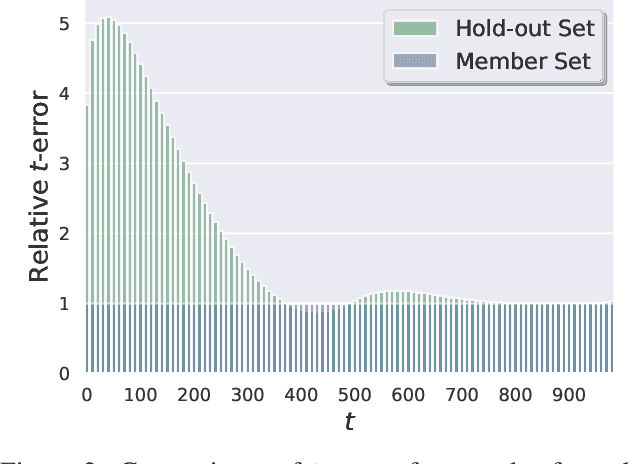
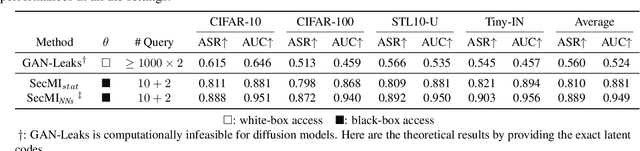
Diffusion-based generative models have shown great potential for image synthesis, but there is a lack of research on the security and privacy risks they may pose. In this paper, we investigate the vulnerability of diffusion models to Membership Inference Attacks (MIAs), a common privacy concern. Our results indicate that existing MIAs designed for GANs or VAE are largely ineffective on diffusion models, either due to inapplicable scenarios (e.g., requiring the discriminator of GANs) or inappropriate assumptions (e.g., closer distances between synthetic images and member images). To address this gap, we propose Step-wise Error Comparing Membership Inference (SecMI), a black-box MIA that infers memberships by assessing the matching of forward process posterior estimation at each timestep. SecMI follows the common overfitting assumption in MIA where member samples normally have smaller estimation errors, compared with hold-out samples. We consider both the standard diffusion models, e.g., DDPM, and the text-to-image diffusion models, e.g., Stable Diffusion. Experimental results demonstrate that our methods precisely infer the membership with high confidence on both of the two scenarios across six different datasets
Exploring Invariant Representation for Visible-Infrared Person Re-Identification
Feb 02, 2023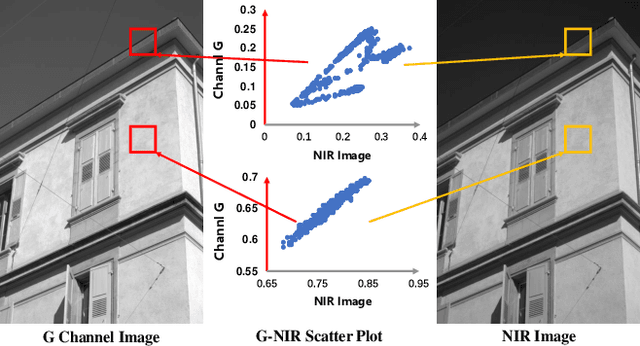

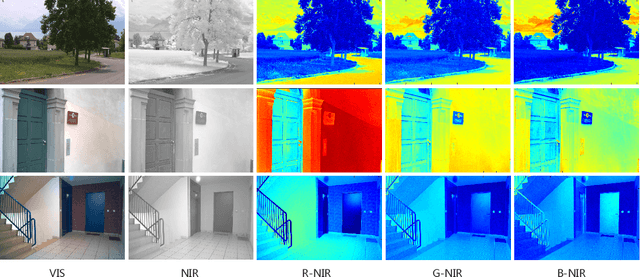

Cross-spectral person re-identification, which aims to associate identities to pedestrians across different spectra, faces a main challenge of the modality discrepancy. In this paper, we address the problem from both image-level and feature-level in an end-to-end hybrid learning framework named robust feature mining network (RFM). In particular, we observe that the reflective intensity of the same surface in photos shot in different wavelengths could be transformed using a linear model. Besides, we show the variable linear factor across the different surfaces is the main culprit which initiates the modality discrepancy. We integrate such a reflection observation into an image-level data augmentation by proposing the linear transformation generator (LTG). Moreover, at the feature level, we introduce a cross-center loss to explore a more compact intra-class distribution and modality-aware spatial attention to take advantage of textured regions more efficiently. Experiment results on two standard cross-spectral person re-identification datasets, i.e., RegDB and SYSU-MM01, have demonstrated state-of-the-art performance.
NBD-GAP: Non-Blind Image Deblurring Without Clean Target Images
Sep 20, 2022

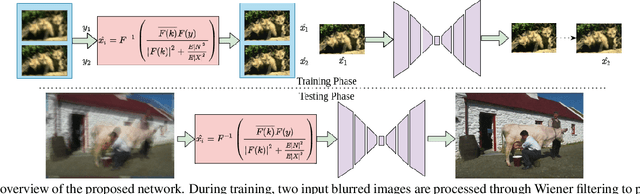

In recent years, deep neural network-based restoration methods have achieved state-of-the-art results in various image deblurring tasks. However, one major drawback of deep learning-based deblurring networks is that large amounts of blurry-clean image pairs are required for training to achieve good performance. Moreover, deep networks often fail to perform well when the blurry images and the blur kernels during testing are very different from the ones used during training. This happens mainly because of the overfitting of the network parameters on the training data. In this work, we present a method that addresses these issues. We view the non-blind image deblurring problem as a denoising problem. To do so, we perform Wiener filtering on a pair of blurry images with the corresponding blur kernels. This results in a pair of images with colored noise. Hence, the deblurring problem is translated into a denoising problem. We then solve the denoising problem without using explicit clean target images. Extensive experiments are conducted to show that our method achieves results that are on par to the state-of-the-art non-blind deblurring works.