 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Masked Image Generation with Token-Critic
Sep 09, 2022
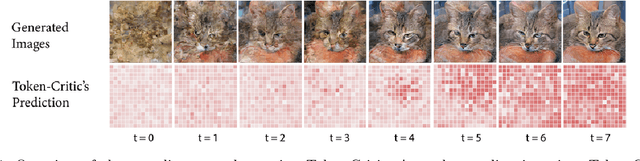
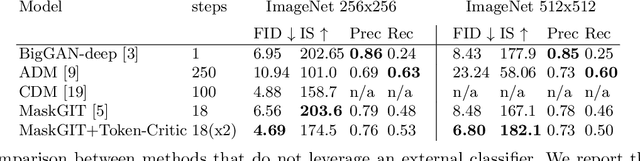
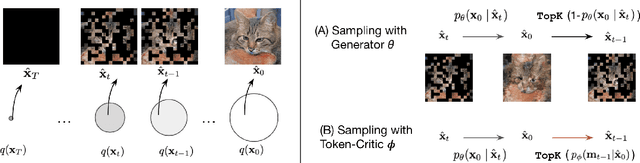
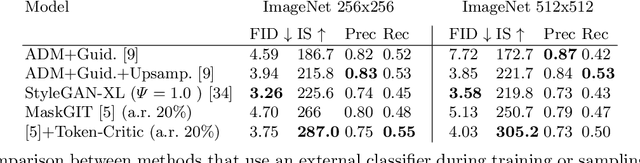
Non-autoregressive generative transformers recently demonstrated impressive image generation performance, and orders of magnitude faster sampling than their autoregressive counterparts. However, optimal parallel sampling from the true joint distribution of visual tokens remains an open challenge. In this paper we introduce Token-Critic, an auxiliary model to guide the sampling of a non-autoregressive generative transformer. Given a masked-and-reconstructed real image, the Token-Critic model is trained to distinguish which visual tokens belong to the original image and which were sampled by the generative transformer. During non-autoregressive iterative sampling, Token-Critic is used to select which tokens to accept and which to reject and resample. Coupled with Token-Critic, a state-of-the-art generative transformer significantly improves its performance, and outperforms recent diffusion models and GANs in terms of the trade-off between generated image quality and diversity, in the challenging class-conditional ImageNet generation.
UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers
Jan 31, 2023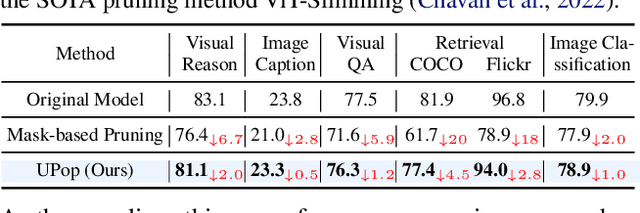
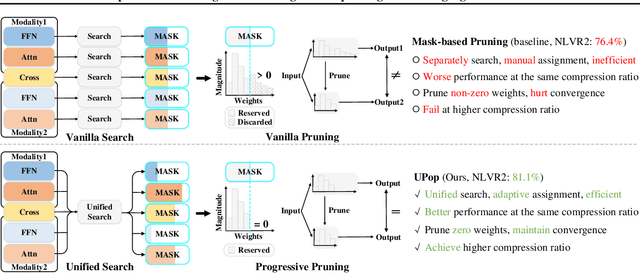

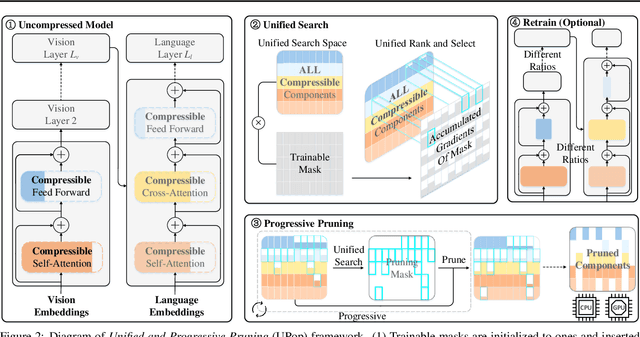
Real-world data contains a vast amount of multimodal information, among which vision and language are the two most representative modalities. Moreover, increasingly heavier models, e.g., Transformers, have attracted the attention of researchers to model compression. However, how to compress multimodal models, especially vison-language Transformers, is still under-explored. This paper proposes the \textbf{U}nified and \textbf{P}r\textbf{o}gressive \textbf{P}runing (UPop) as a universal vison-language Transformer compression framework, which incorporates 1) unifiedly searching multimodal subnets in a continuous optimization space from the original model, which enables automatic assignment of pruning ratios among compressible modalities and structures; 2) progressively searching and retraining the subnet, which maintains convergence between the search and retrain to attain higher compression ratios. Experiments on multiple generative and discriminative vision-language tasks, including Visual Reasoning, Image Caption, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, and Image Classification, demonstrate the effectiveness and versatility of the proposed UPop framework.
How precise are performance estimates for typical medical image segmentation tasks?
Nov 01, 2022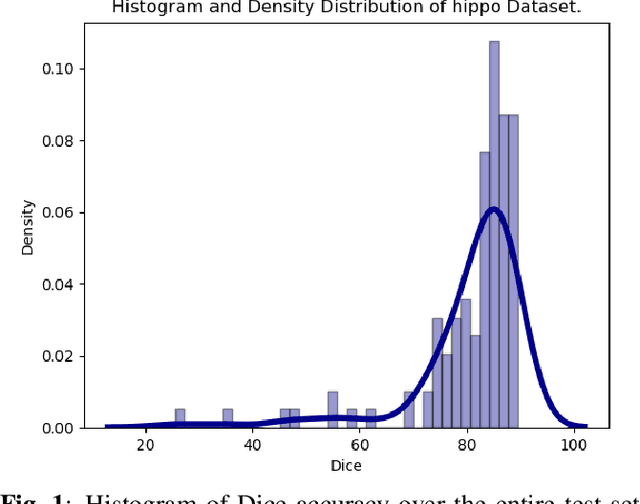


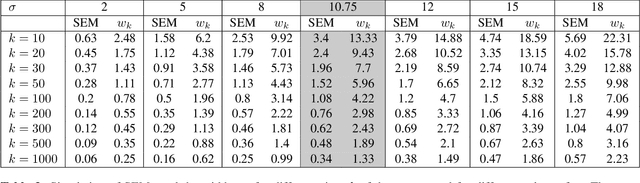
An important issue in medical image processing is to be able to estimate not only the performances of algorithms but also the precision of the estimation of these performances. Reporting precision typically amounts to reporting standard-error of the mean (SEM) or equivalently confidence intervals. However, this is rarely done in medical image segmentation studies. In this paper, we aim to estimate what is the typical confidence that can be expected in such studies. To that end, we first perform experiments for Dice metric estimation using a standard deep learning model (U-net) and a classical task from the Medical Segmentation Decathlon. We extensively study precision estimation using both Gaussian assumption and bootstrapping (which does not require any assumption on the distribution). We then perform simulations for other test set sizes and performance spreads. Overall, our work shows that small test sets lead to wide confidence intervals (e.g. $\sim$8 points of Dice for 20 samples with $\sigma \simeq 10$).
MDAESF: Cine MRI Reconstruction Based on Motion-Guided Deformable Alignment and Efficient Spatiotemporal Self-Attention Fusion
Mar 09, 2023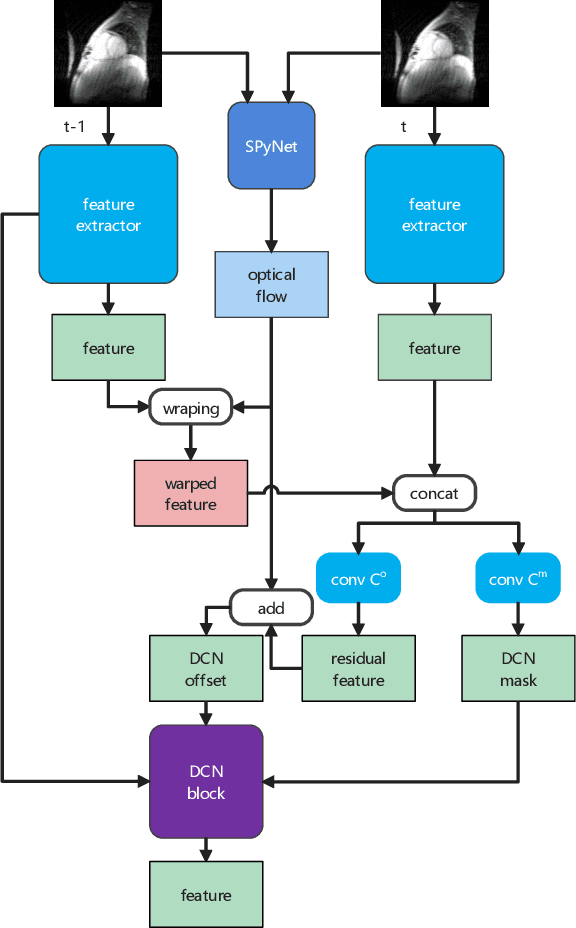

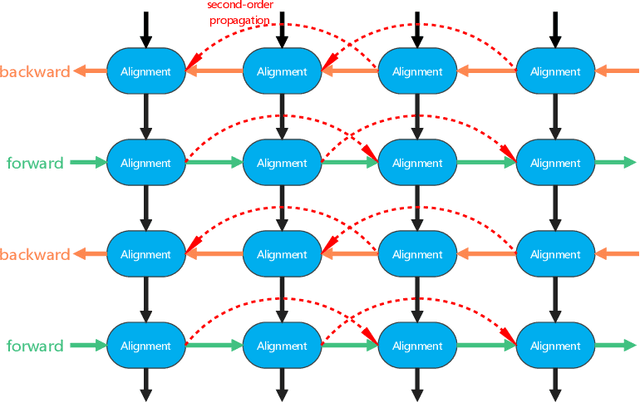

Cine MRI can jointly obtain the continuous influence of the anatomical structure and physiological and pathological mechanisms of organs in the two dimensions of time domain and space domain. Compared with ordinary two-dimensional static MRI images, the information in the time dimension of cine MRI contains many important information. But the information in the temporal dimension is not well utilized in past methods. To make full use of spatiotemporal information and reduce the influence of artifacts, this paper proposes a cine MRI reconstruction model based on second-order bidirectional propagation, motion-guided deformable alignment, and efficient spatiotemporal self-attention fusion. Compared to other advanced methods, our proposed method achieved better image reconstruction quality in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) metrics as well as visual effects. The source code will be made available on https://github.com/GtLinyer/MDAESF.
Decision-BADGE: Decision-based Adversarial Batch Attack with Directional Gradient Estimation
Mar 09, 2023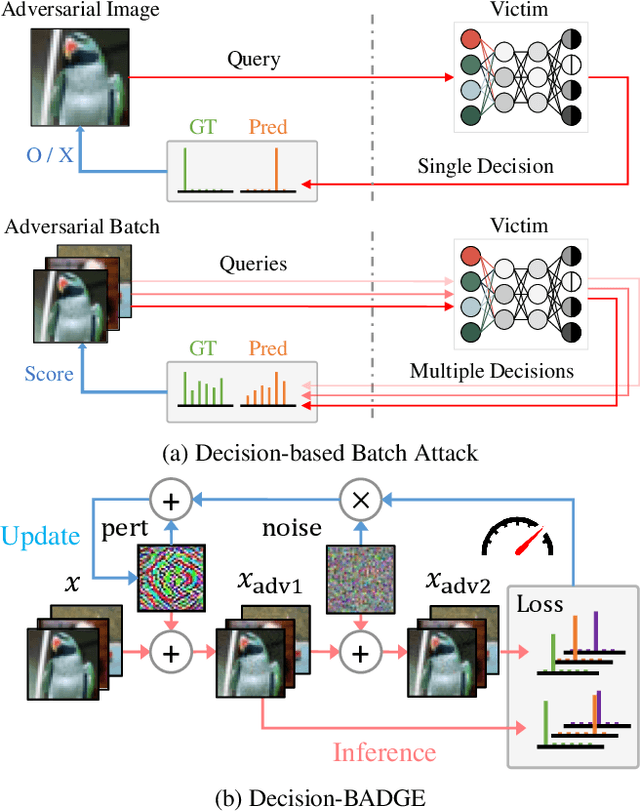

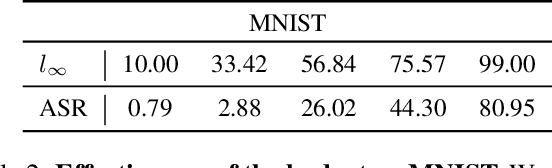
The vulnerability of deep neural networks to adversarial examples has led to the rise in the use of adversarial attacks. While various decision-based and universal attack methods have been proposed, none have attempted to create a decision-based universal adversarial attack. This research proposes Decision-BADGE, which uses random gradient-free optimization and batch attack to generate universal adversarial perturbations for decision-based attacks. Multiple adversarial examples are combined to optimize a single universal perturbation, and the accuracy metric is reformulated into a continuous Hamming distance form. The effectiveness of accuracy metric as a loss function is demonstrated and mathematically proven. The combination of Decision-BADGE and the accuracy loss function performs better than both score-based image-dependent attack and white-box universal attack methods in terms of attack time efficiency. The research also shows that Decision-BADGE can successfully deceive unseen victims and accurately target specific classes.
Exploring Weakly Supervised Semantic Segmentation Ensembles for Medical Imaging Systems
Mar 16, 2023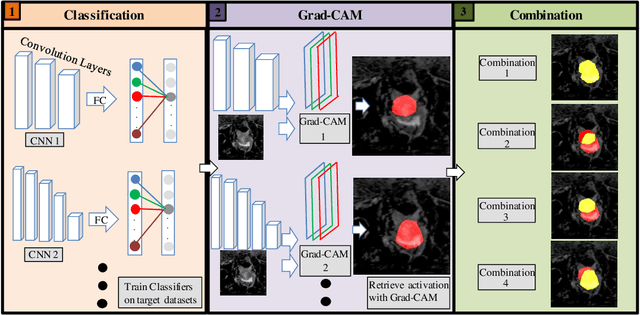
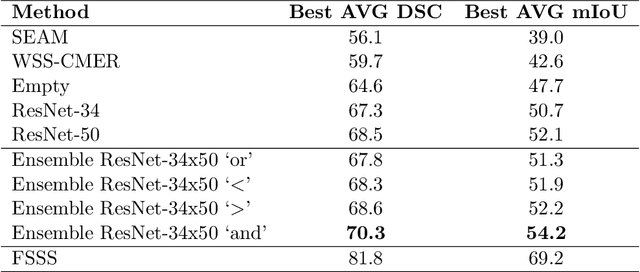
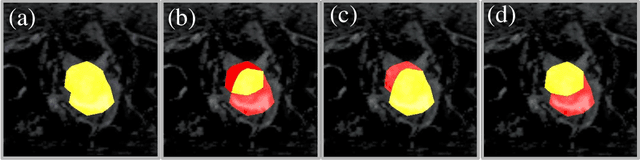
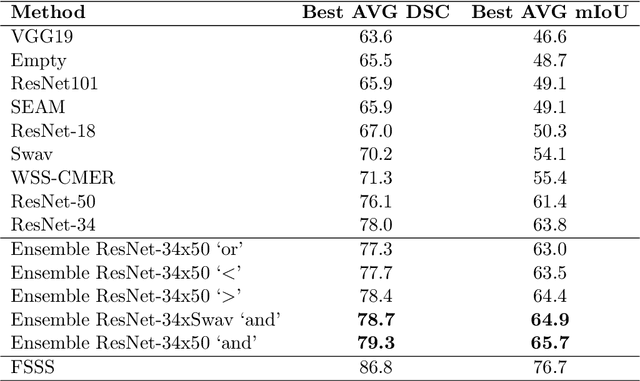
Reliable classification and detection of certain medical conditions, in images, with state-of-the-art semantic segmentation networks, require vast amounts of pixel-wise annotation. However, the public availability of such datasets is minimal. Therefore, semantic segmentation with image-level labels presents a promising alternative to this problem. Nevertheless, very few works have focused on evaluating this technique and its applicability to the medical sector. Due to their complexity and the small number of training examples in medical datasets, classifier-based weakly supervised networks like class activation maps (CAMs) struggle to extract useful information from them. However, most state-of-the-art approaches rely on them to achieve their improvements. Therefore, we propose a framework that can still utilize the low-quality CAM predictions of complicated datasets to improve the accuracy of our results. Our framework achieves that by first utilizing lower threshold CAMs to cover the target object with high certainty; second, by combining multiple low-threshold CAMs that even out their errors while highlighting the target object. We performed exhaustive experiments on the popular multi-modal BRATS and prostate DECATHLON segmentation challenge datasets. Using the proposed framework, we have demonstrated an improved dice score of up to 8% on BRATS and 6% on DECATHLON datasets compared to the previous state-of-the-art.
Prompting Large Language Models with Answer Heuristics for Knowledge-based Visual Question Answering
Mar 16, 2023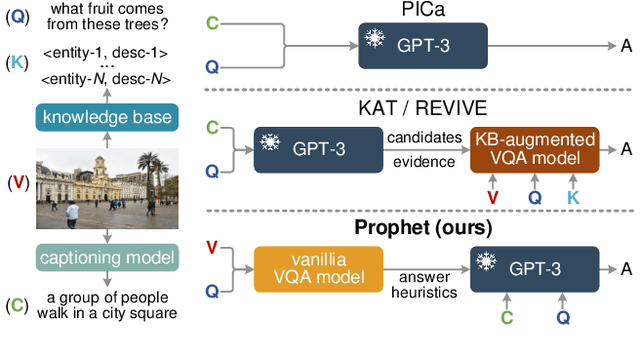

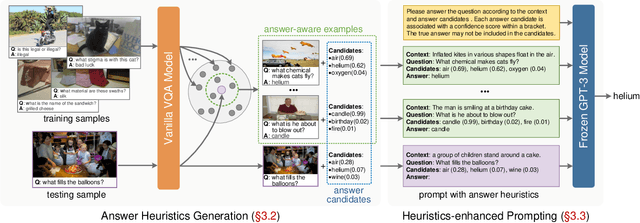
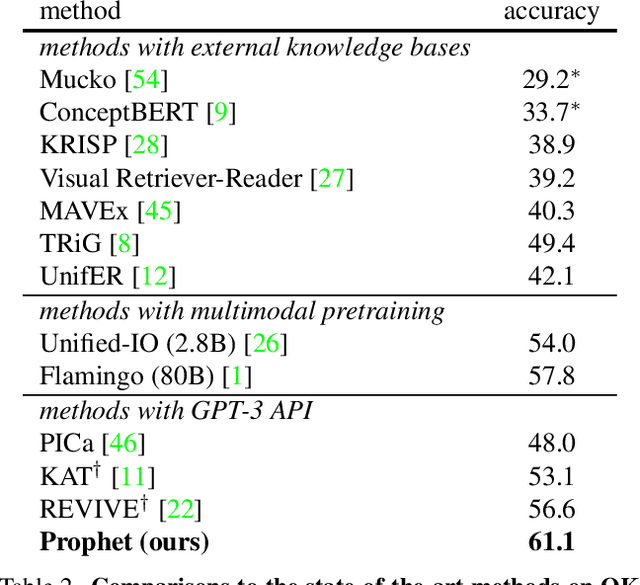
Knowledge-based visual question answering (VQA) requires external knowledge beyond the image to answer the question. Early studies retrieve required knowledge from explicit knowledge bases (KBs), which often introduces irrelevant information to the question, hence restricting the performance of their models. Recent works have sought to use a large language model (i.e., GPT-3) as an implicit knowledge engine to acquire the necessary knowledge for answering. Despite the encouraging results achieved by these methods, we argue that they have not fully activated the capacity of GPT-3 as the provided input information is insufficient. In this paper, we present Prophet -- a conceptually simple framework designed to prompt GPT-3 with answer heuristics for knowledge-based VQA. Specifically, we first train a vanilla VQA model on a specific knowledge-based VQA dataset without external knowledge. After that, we extract two types of complementary answer heuristics from the model: answer candidates and answer-aware examples. Finally, the two types of answer heuristics are encoded into the prompts to enable GPT-3 to better comprehend the task thus enhancing its capacity. Prophet significantly outperforms all existing state-of-the-art methods on two challenging knowledge-based VQA datasets, OK-VQA and A-OKVQA, delivering 61.1% and 55.7% accuracies on their testing sets, respectively.
CSSL-MHTR: Continual Self-Supervised Learning for Scalable Multi-script Handwritten Text Recognition
Mar 16, 2023
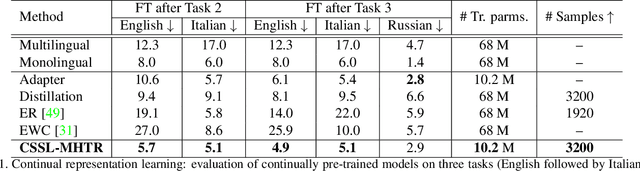
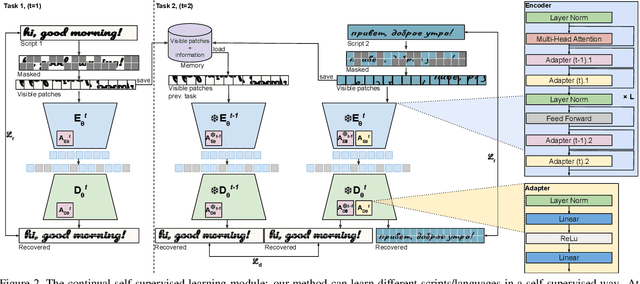
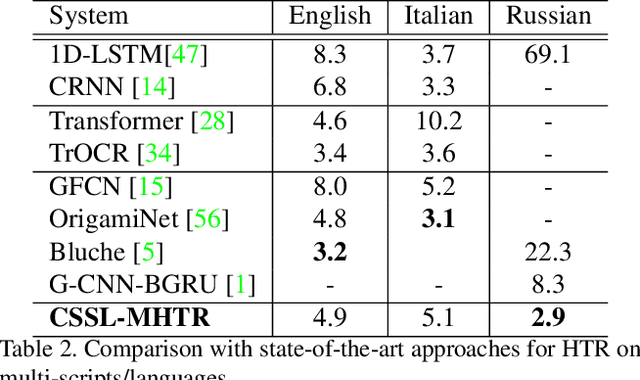
Self-supervised learning has recently emerged as a strong alternative in document analysis. These approaches are now capable of learning high-quality image representations and overcoming the limitations of supervised methods, which require a large amount of labeled data. However, these methods are unable to capture new knowledge in an incremental fashion, where data is presented to the model sequentially, which is closer to the realistic scenario. In this paper, we explore the potential of continual self-supervised learning to alleviate the catastrophic forgetting problem in handwritten text recognition, as an example of sequence recognition. Our method consists in adding intermediate layers called adapters for each task, and efficiently distilling knowledge from the previous model while learning the current task. Our proposed framework is efficient in both computation and memory complexity. To demonstrate its effectiveness, we evaluate our method by transferring the learned model to diverse text recognition downstream tasks, including Latin and non-Latin scripts. As far as we know, this is the first application of continual self-supervised learning for handwritten text recognition. We attain state-of-the-art performance on English, Italian and Russian scripts, whilst adding only a few parameters per task. The code and trained models will be publicly available.
UniCLIP: Unified Framework for Contrastive Language-Image Pre-training
Sep 27, 2022
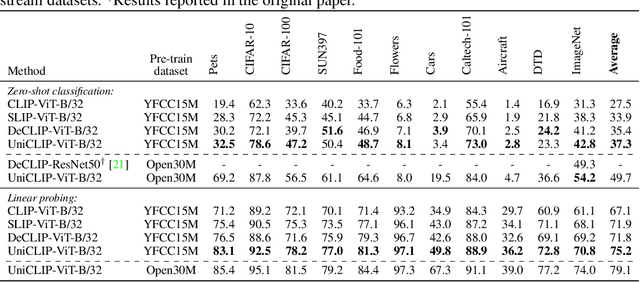
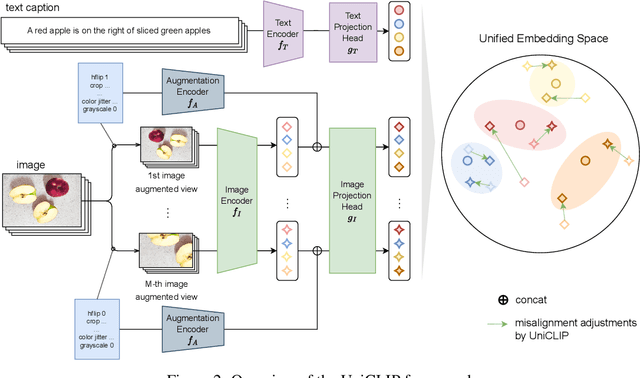
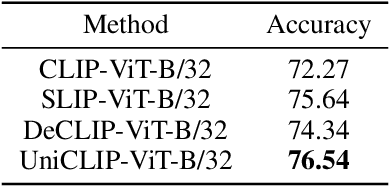
Pre-training vision-language models with contrastive objectives has shown promising results that are both scalable to large uncurated datasets and transferable to many downstream applications. Some following works have targeted to improve data efficiency by adding self-supervision terms, but inter-domain (image-text) contrastive loss and intra-domain (image-image) contrastive loss are defined on individual spaces in those works, so many feasible combinations of supervision are overlooked. To overcome this issue, we propose UniCLIP, a Unified framework for Contrastive Language-Image Pre-training. UniCLIP integrates the contrastive loss of both inter-domain pairs and intra-domain pairs into a single universal space. The discrepancies that occur when integrating contrastive loss between different domains are resolved by the three key components of UniCLIP: (1) augmentation-aware feature embedding, (2) MP-NCE loss, and (3) domain dependent similarity measure. UniCLIP outperforms previous vision-language pre-training methods on various single- and multi-modality downstream tasks. In our experiments, we show that each component that comprises UniCLIP contributes well to the final performance.
A Multi-scale Video Denoising Algorithm for Raw Image
Sep 05, 2022
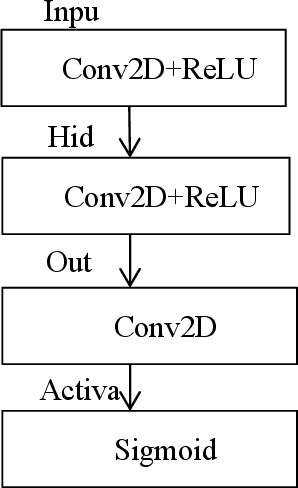
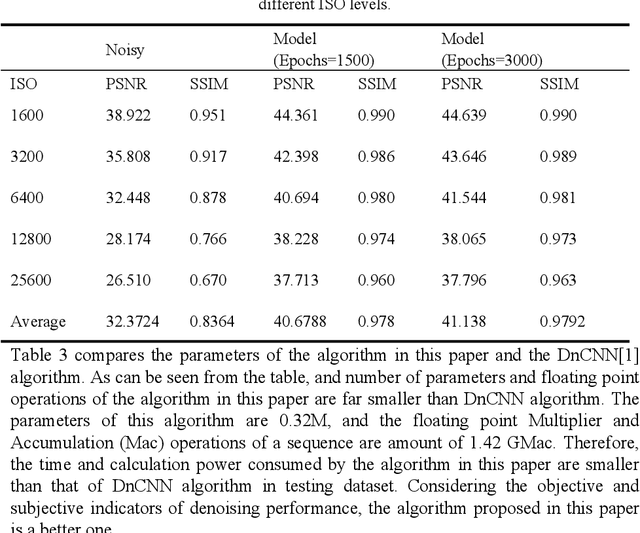
Video denoising for raw image has always been the difficulty of camera image processing. On the one hand, image denoising performance largely determines the image quality, moreover denoising effect in raw image will affect the accuracy of the following operations of ISP processing flow. On the other hand, compared with image, video have motion information in time sequence, thus motion estimation which is complex and computationally expensive is needed in video denoising. In view of the above problems, this paper proposes a video denoising algorithm for raw image, performing multiple cascading processing stages on raw-RGB image based on convolutional neural network, and carries out implicit motion estimation in the network. The denoising performance is far superior to that of traditional algorithms with minimal computation and bandwidth, and has computational advantages compared with most deep learning algorithms.