 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Event-based Human Pose Tracking by Spiking Spatiotemporal Transformer
Mar 31, 2023

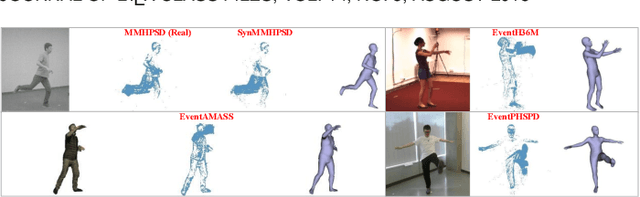

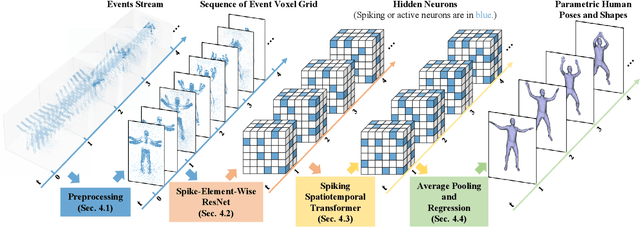
Event camera, as an emerging biologically-inspired vision sensor for capturing motion dynamics, presents new potential for 3D human pose tracking, or video-based 3D human pose estimation. However, existing works in pose tracking either require the presence of additional gray-scale images to establish a solid starting pose, or ignore the temporal dependencies all together by collapsing segments of event streams to form static event frames. Meanwhile, although the effectiveness of Artificial Neural Networks (ANNs, a.k.a. dense deep learning) has been showcased in many event-based tasks, the use of ANNs tends to neglect the fact that compared to the dense frame-based image sequences, the occurrence of events from an event camera is spatiotemporally much sparser. Motivated by the above mentioned issues, we present in this paper a dedicated end-to-end sparse deep learning approach for event-based pose tracking: 1) to our knowledge this is the first time that 3D human pose tracking is obtained from events only, thus eliminating the need of accessing to any frame-based images as part of input; 2) our approach is based entirely upon the framework of Spiking Neural Networks (SNNs), which consists of Spike-Element-Wise (SEW) ResNet and a novel Spiking Spatiotemporal Transformer; 3) a large-scale synthetic dataset is constructed that features a broad and diverse set of annotated 3D human motions, as well as longer hours of event stream data, named SynEventHPD. Empirical experiments demonstrate that, with superior performance over the state-of-the-art (SOTA) ANNs counterparts, our approach also achieves a significant computation reduction of 80% in FLOPS. Furthermore, our proposed method also outperforms SOTA SNNs in the regression task of human pose tracking. Our implementation is available at https://github.com/JimmyZou/HumanPoseTracking_SNN and dataset will be released upon paper acceptance.
CHiLS: Zero-Shot Image Classification with Hierarchical Label Sets
Feb 07, 2023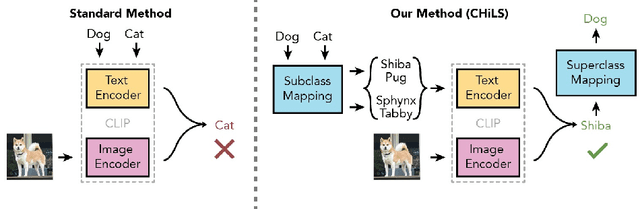
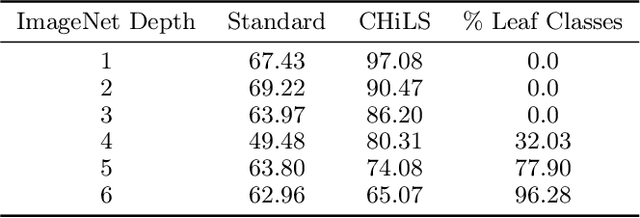

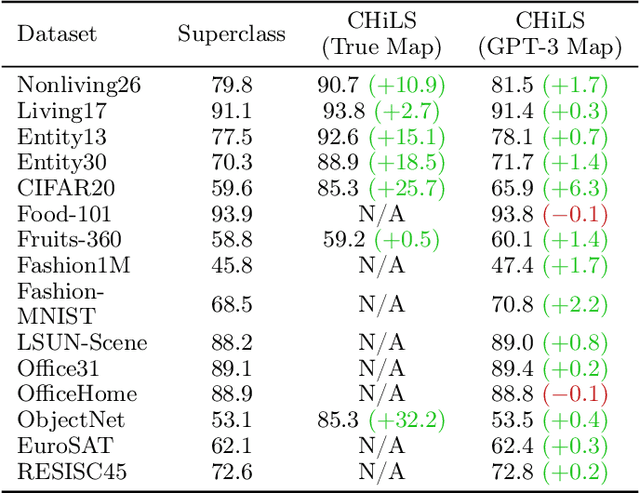
Open vocabulary models (e.g. CLIP) have shown strong performance on zero-shot classification through their ability generate embeddings for each class based on their (natural language) names. Prior work has focused on improving the accuracy of these models through prompt engineering or by incorporating a small amount of labeled downstream data (via finetuning). However, there has been little focus on improving the richness of the class names themselves, which can pose issues when class labels are coarsely-defined and uninformative. We propose Classification with Hierarchical Label Sets (or CHiLS), an alternative strategy for zero-shot classification specifically designed for datasets with implicit semantic hierarchies. CHiLS proceeds in three steps: (i) for each class, produce a set of subclasses, using either existing label hierarchies or by querying GPT-3; (ii) perform the standard zero-shot CLIP procedure as though these subclasses were the labels of interest; (iii) map the predicted subclass back to its parent to produce the final prediction. Across numerous datasets with underlying hierarchical structure, CHiLS leads to improved accuracy in situations both with and without ground-truth hierarchical information. CHiLS is simple to implement within existing CLIP pipelines and requires no additional training cost. Code is available at: https://github.com/acmi-lab/CHILS.
Hospital Length of Stay Prediction Based on Multi-modal Data towards Trustworthy Human-AI Collaboration in Radiomics
Mar 17, 2023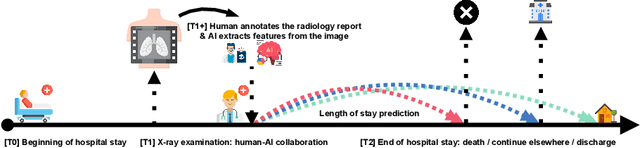
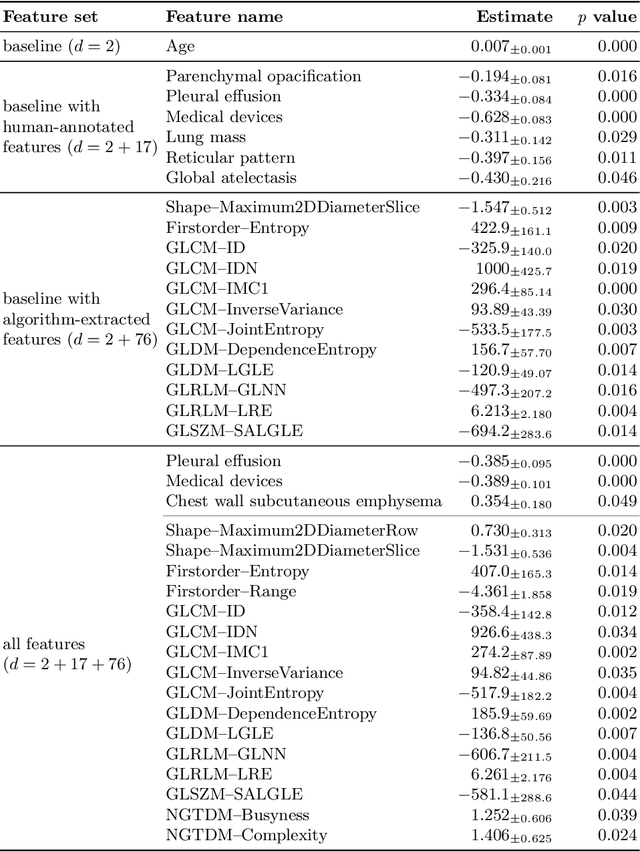
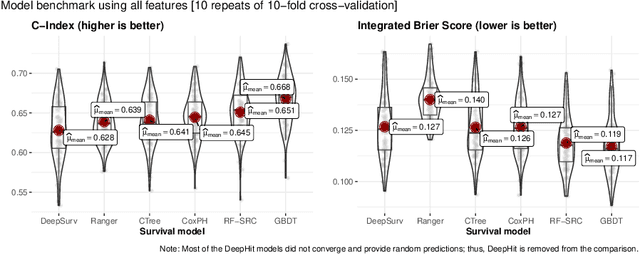
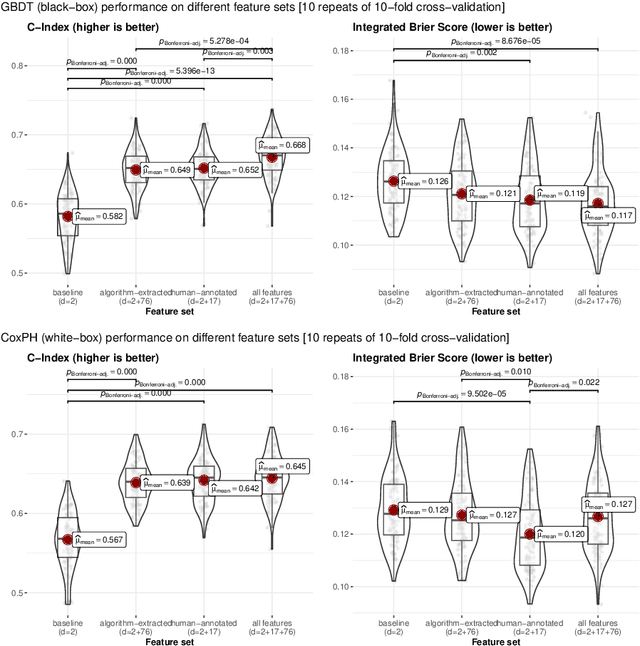
To what extent can the patient's length of stay in a hospital be predicted using only an X-ray image? We answer this question by comparing the performance of machine learning survival models on a novel multi-modal dataset created from 1235 images with textual radiology reports annotated by humans. Although black-box models predict better on average than interpretable ones, like Cox proportional hazards, they are not inherently understandable. To overcome this trust issue, we introduce time-dependent model explanations into the human-AI decision making process. Explaining models built on both: human-annotated and algorithm-extracted radiomics features provides valuable insights for physicians working in a hospital. We believe the presented approach to be general and widely applicable to other time-to-event medical use cases. For reproducibility, we open-source code and the TLOS dataset at https://github.com/mi2datalab/xlungs-trustworthy-los-prediction.
A Dynamic Multi-Scale Voxel Flow Network for Video Prediction
Mar 17, 2023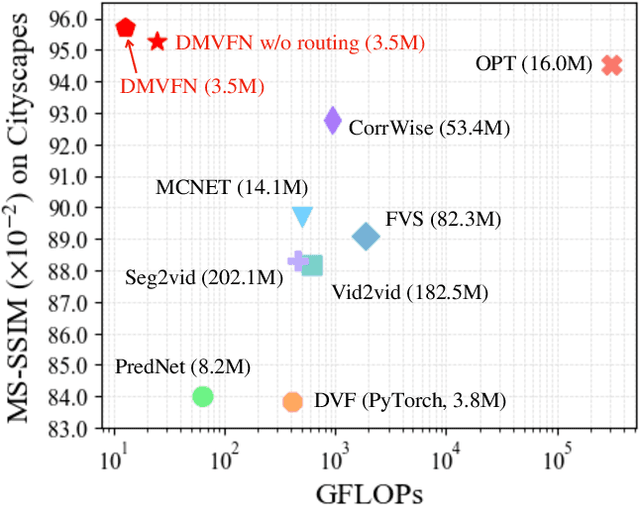
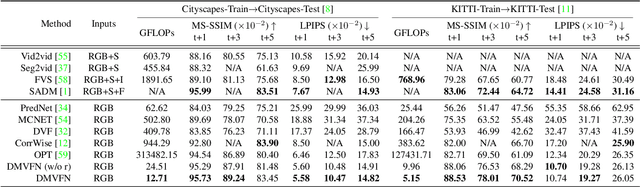
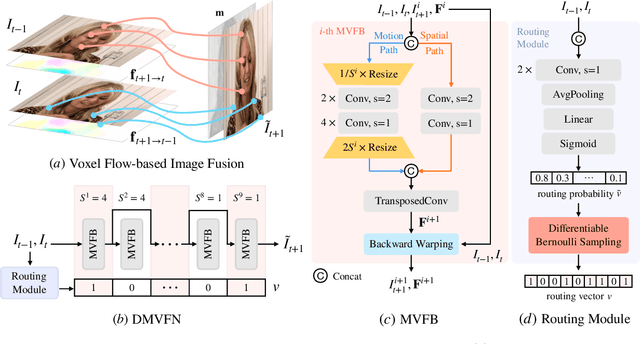
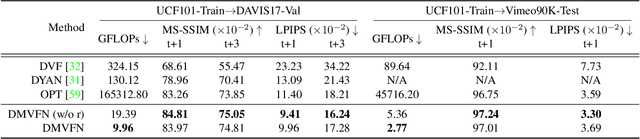
The performance of video prediction has been greatly boosted by advanced deep neural networks. However, most of the current methods suffer from large model sizes and require extra inputs, e.g., semantic/depth maps, for promising performance. For efficiency consideration, in this paper, we propose a Dynamic Multi-scale Voxel Flow Network (DMVFN) to achieve better video prediction performance at lower computational costs with only RGB images, than previous methods. The core of our DMVFN is a differentiable routing module that can effectively perceive the motion scales of video frames. Once trained, our DMVFN selects adaptive sub-networks for different inputs at the inference stage. Experiments on several benchmarks demonstrate that our DMVFN is an order of magnitude faster than Deep Voxel Flow and surpasses the state-of-the-art iterative-based OPT on generated image quality. Our code and demo are available at https://huxiaotaostasy.github.io/DMVFN/.
M3AE: Multimodal Representation Learning for Brain Tumor Segmentation with Missing Modalities
Mar 09, 2023
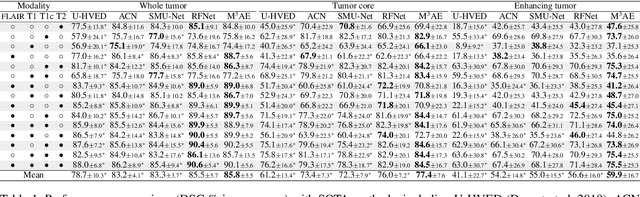
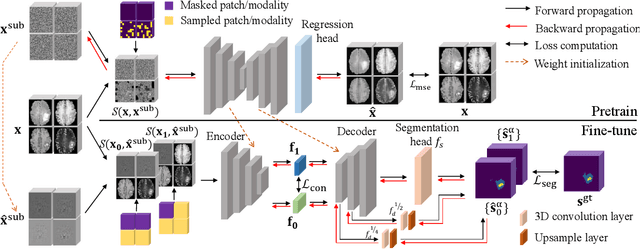
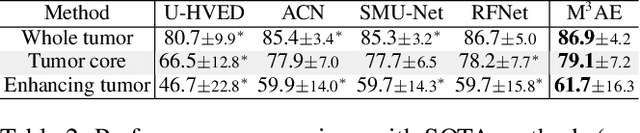
Multimodal magnetic resonance imaging (MRI) provides complementary information for sub-region analysis of brain tumors. Plenty of methods have been proposed for automatic brain tumor segmentation using four common MRI modalities and achieved remarkable performance. In practice, however, it is common to have one or more modalities missing due to image corruption, artifacts, acquisition protocols, allergy to contrast agents, or simply cost. In this work, we propose a novel two-stage framework for brain tumor segmentation with missing modalities. In the first stage, a multimodal masked autoencoder (M3AE) is proposed, where both random modalities (i.e., modality dropout) and random patches of the remaining modalities are masked for a reconstruction task, for self-supervised learning of robust multimodal representations against missing modalities. To this end, we name our framework M3AE. Meanwhile, we employ model inversion to optimize a representative full-modal image at marginal extra cost, which will be used to substitute for the missing modalities and boost performance during inference. Then in the second stage, a memory-efficient self distillation is proposed to distill knowledge between heterogenous missing-modal situations while fine-tuning the model for supervised segmentation. Our M3AE belongs to the 'catch-all' genre where a single model can be applied to all possible subsets of modalities, thus is economic for both training and deployment. Extensive experiments on BraTS 2018 and 2020 datasets demonstrate its superior performance to existing state-of-the-art methods with missing modalities, as well as the efficacy of its components. Our code is available at: https://github.com/ccarliu/m3ae.
Soft Augmentation for Image Classification
Nov 09, 2022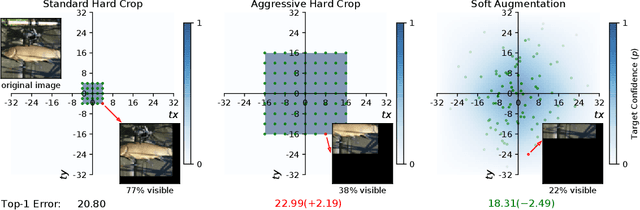
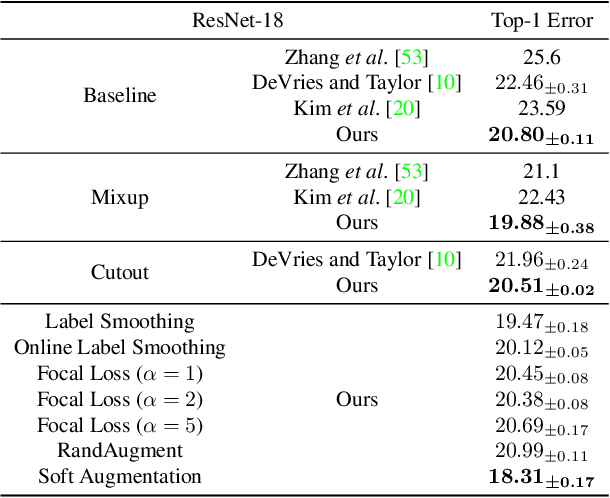

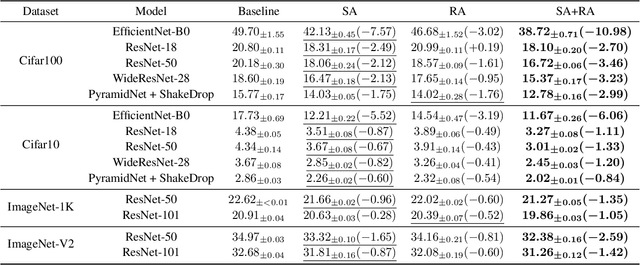
Modern neural networks are over-parameterized and thus rely on strong regularization such as data augmentation and weight decay to reduce overfitting and improve generalization. The dominant form of data augmentation applies invariant transforms, where the learning target of a sample is invariant to the transform applied to that sample. We draw inspiration from human visual classification studies and propose generalizing augmentation with invariant transforms to soft augmentation where the learning target softens non-linearly as a function of the degree of the transform applied to the sample: e.g., more aggressive image crop augmentations produce less confident learning targets. We demonstrate that soft targets allow for more aggressive data augmentation, offer more robust performance boosts, work with other augmentation policies, and interestingly, produce better calibrated models (since they are trained to be less confident on aggressively cropped/occluded examples). Combined with existing aggressive augmentation strategies, soft target 1) doubles the top-1 accuracy boost across Cifar-10, Cifar-100, ImageNet-1K, and ImageNet-V2, 2) improves model occlusion performance by up to $4\times$, and 3) halves the expected calibration error (ECE). Finally, we show that soft augmentation generalizes to self-supervised classification tasks.
Unproportional mosaicing
Mar 06, 2023
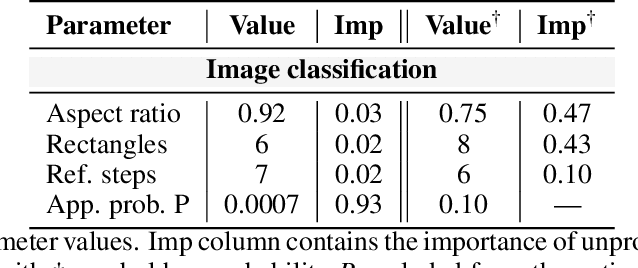

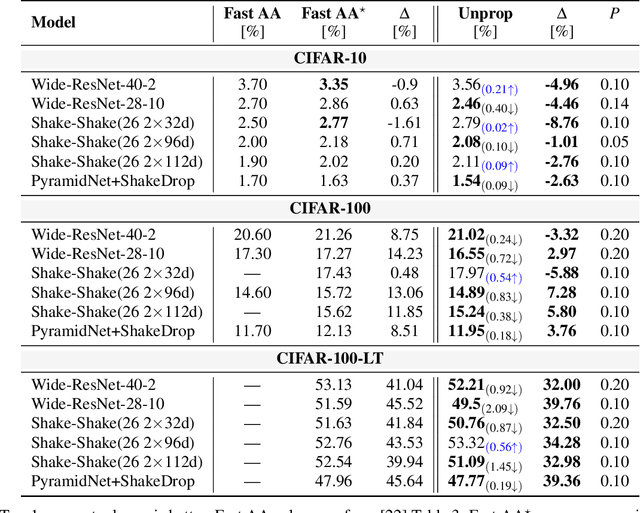
Data shift is a gap between data distribution used for training and data distribution encountered in the real-world. Data augmentations help narrow the gap by generating new data samples, increasing data variability, and data space coverage. We present a new data augmentation: Unproportional mosaicing (Unprop). Our augmentation randomly splits an image into various-sized blocks and swaps its content (pixels) while maintaining block sizes. Our method achieves a lower error rate when combined with other state-of-the-art augmentations.
Meta-Learning Initializations for Interactive Medical Image Registration
Oct 27, 2022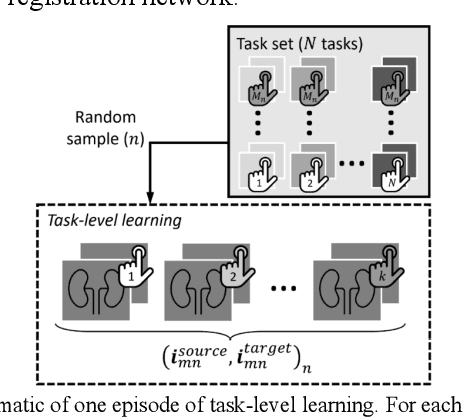
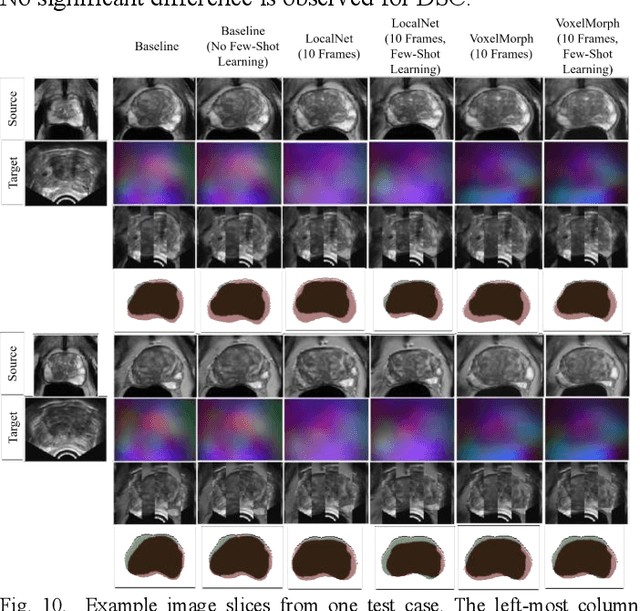
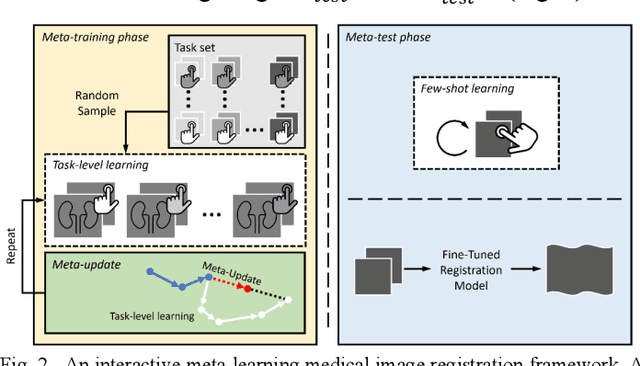
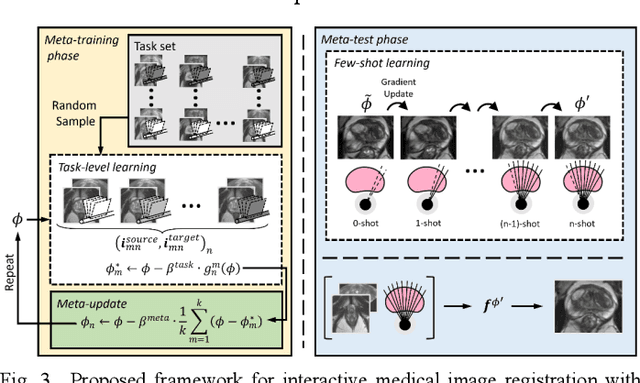
We present a meta-learning framework for interactive medical image registration. Our proposed framework comprises three components: a learning-based medical image registration algorithm, a form of user interaction that refines registration at inference, and a meta-learning protocol that learns a rapidly adaptable network initialization. This paper describes a specific algorithm that implements the registration, interaction and meta-learning protocol for our exemplar clinical application: registration of magnetic resonance (MR) imaging to interactively acquired, sparsely-sampled transrectal ultrasound (TRUS) images. Our approach obtains comparable registration error (4.26 mm) to the best-performing non-interactive learning-based 3D-to-3D method (3.97 mm) while requiring only a fraction of the data, and occurring in real-time during acquisition. Applying sparsely sampled data to non-interactive methods yields higher registration errors (6.26 mm), demonstrating the effectiveness of interactive MR-TRUS registration, which may be applied intraoperatively given the real-time nature of the adaptation process.
FAME-ViL: Multi-Tasking Vision-Language Model for Heterogeneous Fashion Tasks
Mar 04, 2023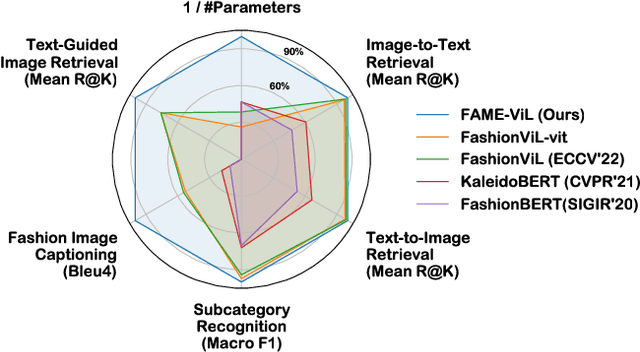
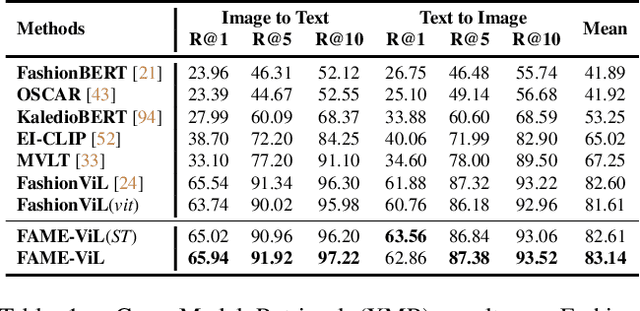

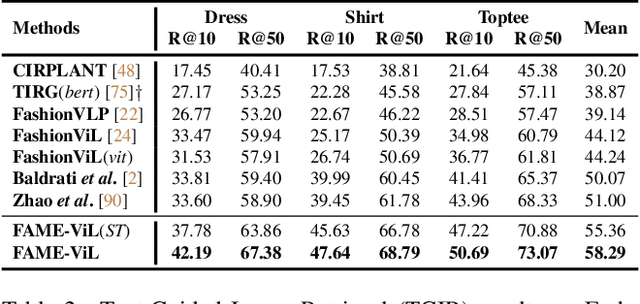
In the fashion domain, there exists a variety of vision-and-language (V+L) tasks, including cross-modal retrieval, text-guided image retrieval, multi-modal classification, and image captioning. They differ drastically in each individual input/output format and dataset size. It has been common to design a task-specific model and fine-tune it independently from a pre-trained V+L model (e.g., CLIP). This results in parameter inefficiency and inability to exploit inter-task relatedness. To address such issues, we propose a novel FAshion-focused Multi-task Efficient learning method for Vision-and-Language tasks (FAME-ViL) in this work. Compared with existing approaches, FAME-ViL applies a single model for multiple heterogeneous fashion tasks, therefore being much more parameter-efficient. It is enabled by two novel components: (1) a task-versatile architecture with cross-attention adapters and task-specific adapters integrated into a unified V+L model, and (2) a stable and effective multi-task training strategy that supports learning from heterogeneous data and prevents negative transfer. Extensive experiments on four fashion tasks show that our FAME-ViL can save 61.5% of parameters over alternatives, while significantly outperforming the conventional independently trained single-task models. Code is available at https://github.com/BrandonHanx/FAME-ViL.
Self-distillation for surgical action recognition
Mar 22, 2023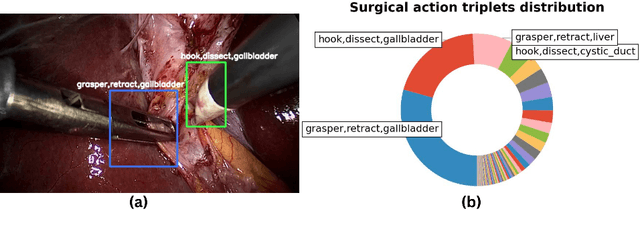
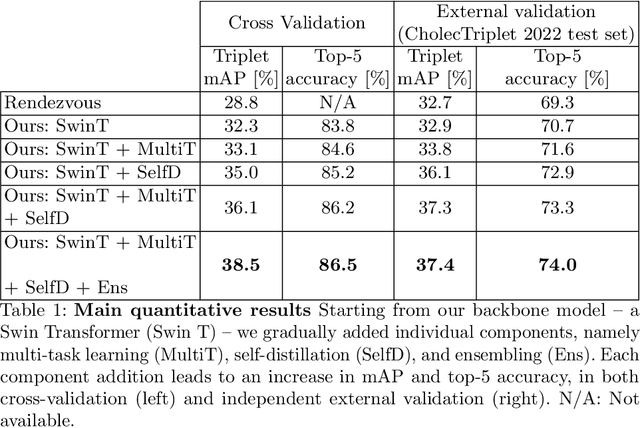
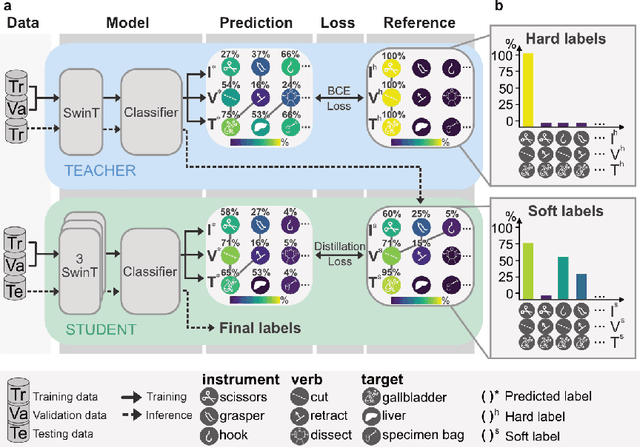
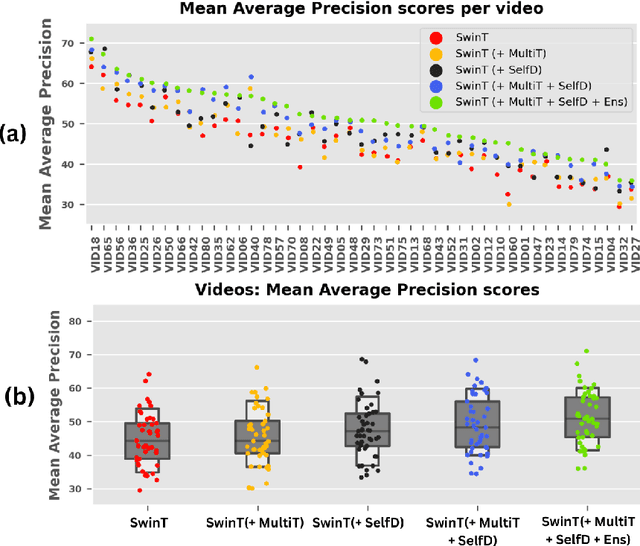
Surgical scene understanding is a key prerequisite for contextaware decision support in the operating room. While deep learning-based approaches have already reached or even surpassed human performance in various fields, the task of surgical action recognition remains a major challenge. With this contribution, we are the first to investigate the concept of self-distillation as a means of addressing class imbalance and potential label ambiguity in surgical video analysis. Our proposed method is a heterogeneous ensemble of three models that use Swin Transfomers as backbone and the concepts of self-distillation and multi-task learning as core design choices. According to ablation studies performed with the CholecT45 challenge data via cross-validation, the biggest performance boost is achieved by the usage of soft labels obtained by self-distillation. External validation of our method on an independent test set was achieved by providing a Docker container of our inference model to the challenge organizers. According to their analysis, our method outperforms all other solutions submitted to the latest challenge in the field. Our approach thus shows the potential of self-distillation for becoming an important tool in medical image analysis applications.