 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Graph Reasoning Transformer for Image Parsing
Sep 20, 2022
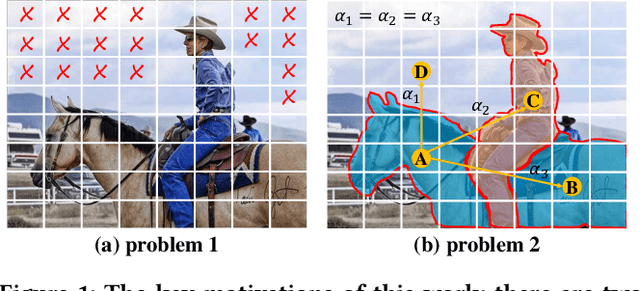
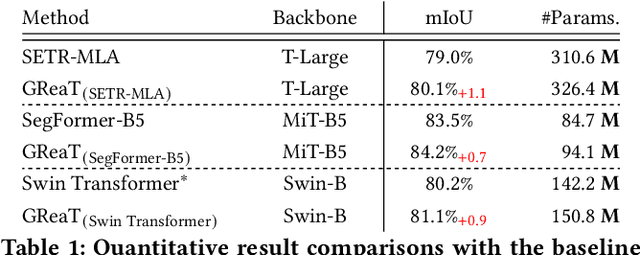
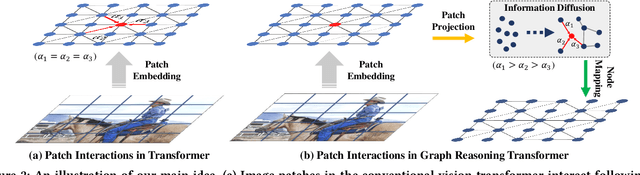
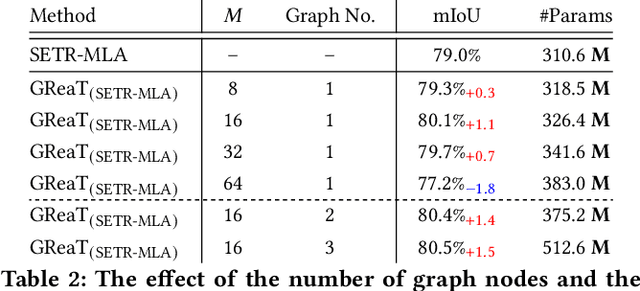
Capturing the long-range dependencies has empirically proven to be effective on a wide range of computer vision tasks. The progressive advances on this topic have been made through the employment of the transformer framework with the help of the multi-head attention mechanism. However, the attention-based image patch interaction potentially suffers from problems of redundant interactions of intra-class patches and unoriented interactions of inter-class patches. In this paper, we propose a novel Graph Reasoning Transformer (GReaT) for image parsing to enable image patches to interact following a relation reasoning pattern. Specifically, the linearly embedded image patches are first projected into the graph space, where each node represents the implicit visual center for a cluster of image patches and each edge reflects the relation weight between two adjacent nodes. After that, global relation reasoning is performed on this graph accordingly. Finally, all nodes including the relation information are mapped back into the original space for subsequent processes. Compared to the conventional transformer, GReaT has higher interaction efficiency and a more purposeful interaction pattern. Experiments are carried out on the challenging Cityscapes and ADE20K datasets. Results show that GReaT achieves consistent performance gains with slight computational overheads on the state-of-the-art transformer baselines.
Explainable Image Quality Assessments in Teledermatological Photography
Sep 10, 2022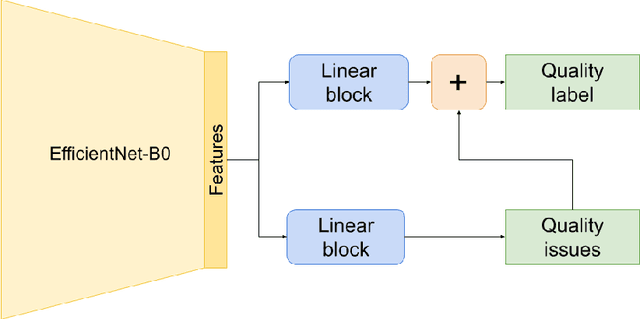
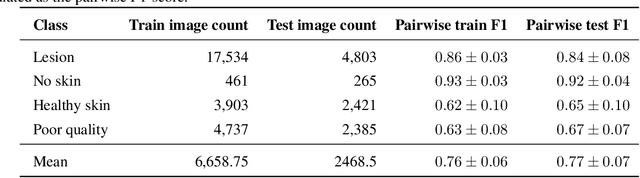
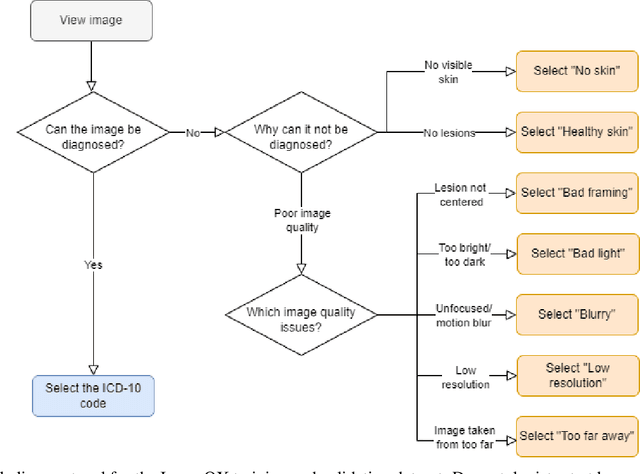
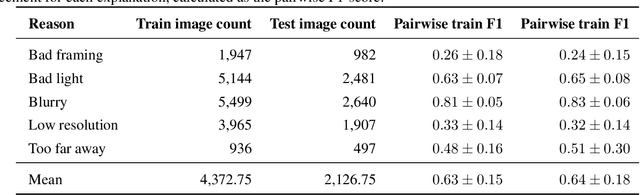
Image quality is a crucial factor in the success of teledermatological consultations. However, up to 50% of images sent by patients have quality issues, thus increasing the time to diagnosis and treatment. An automated, easily deployable, explainable method for assessing image quality is necessary to improve the current teledermatological consultation flow. We introduce ImageQX, a convolutional neural network trained for image quality assessment with a learning mechanism for identifying the most common poor image quality explanations: bad framing, bad lighting, blur, low resolution, and distance issues. ImageQX was trained on 26635 photographs and validated on 9874 photographs, each annotated with image quality labels and poor image quality explanations by up to 12 board-certified dermatologists. The photographic images were taken between 2017-2019 using a mobile skin disease tracking application accessible worldwide. Our method achieves expert-level performance for both image quality assessment and poor image quality explanation. For image quality assessment, ImageQX obtains a macro F1-score of 0.73 which places it within standard deviation of the pairwise inter-rater F1-score of 0.77. For poor image quality explanations, our method obtains F1-scores of between 0.37 and 0.70, similar to the inter-rater pairwise F1-score of between 0.24 and 0.83. Moreover, with a size of only 15 MB, ImageQX is easily deployable on mobile devices. With an image quality detection performance similar to that of dermatologists, incorporating ImageQX into the teledermatology flow can reduce the image evaluation burden on dermatologists, while at the same time reducing the time to diagnosis and treatment for patients. We introduce ImageQX, a first of its kind explainable image quality assessor which leverages domain expertise to improve the quality and efficiency of dermatological care in a virtual setting.
Pose Guided Human Image Synthesis with Partially Decoupled GAN
Oct 07, 2022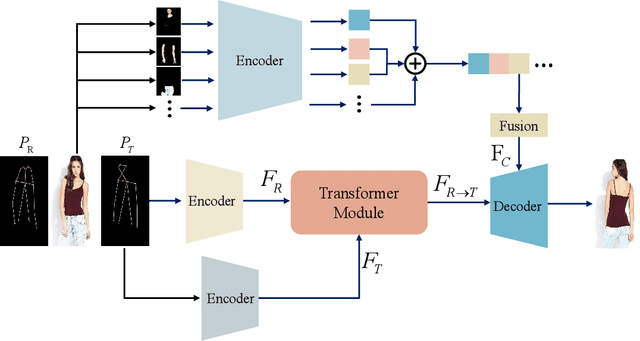
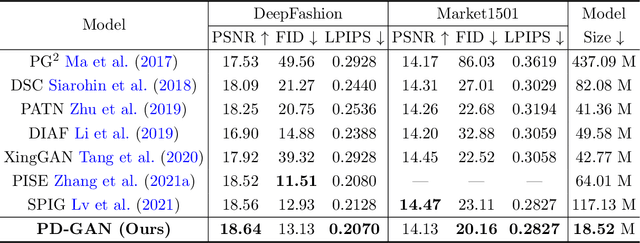
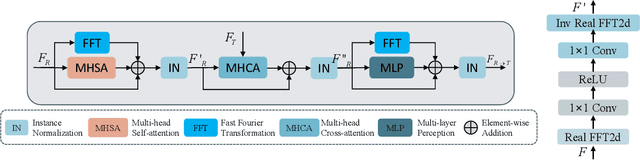

Pose Guided Human Image Synthesis (PGHIS) is a challenging task of transforming a human image from the reference pose to a target pose while preserving its style. Most existing methods encode the texture of the whole reference human image into a latent space, and then utilize a decoder to synthesize the image texture of the target pose. However, it is difficult to recover the detailed texture of the whole human image. To alleviate this problem, we propose a method by decoupling the human body into several parts (\eg, hair, face, hands, feet, \etc) and then using each of these parts to guide the synthesis of a realistic image of the person, which preserves the detailed information of the generated images. In addition, we design a multi-head attention-based module for PGHIS. Because most convolutional neural network-based methods have difficulty in modeling long-range dependency due to the convolutional operation, the long-range modeling capability of attention mechanism is more suitable than convolutional neural networks for pose transfer task, especially for sharp pose deformation. Extensive experiments on Market-1501 and DeepFashion datasets reveal that our method almost outperforms other existing state-of-the-art methods in terms of both qualitative and quantitative metrics.
Deformable Proposal-Aware P2PNet: A Universal Network for Cell Recognition under Point Supervision
Mar 05, 2023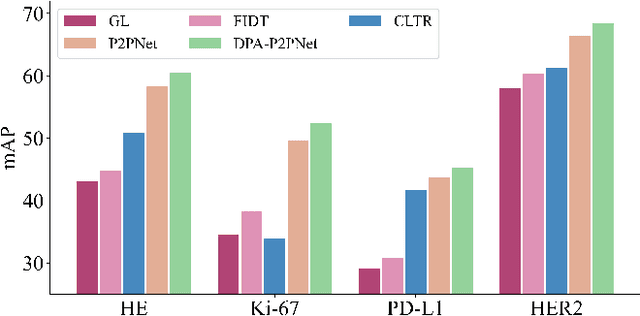

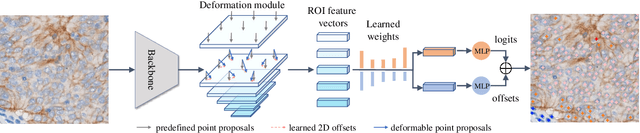
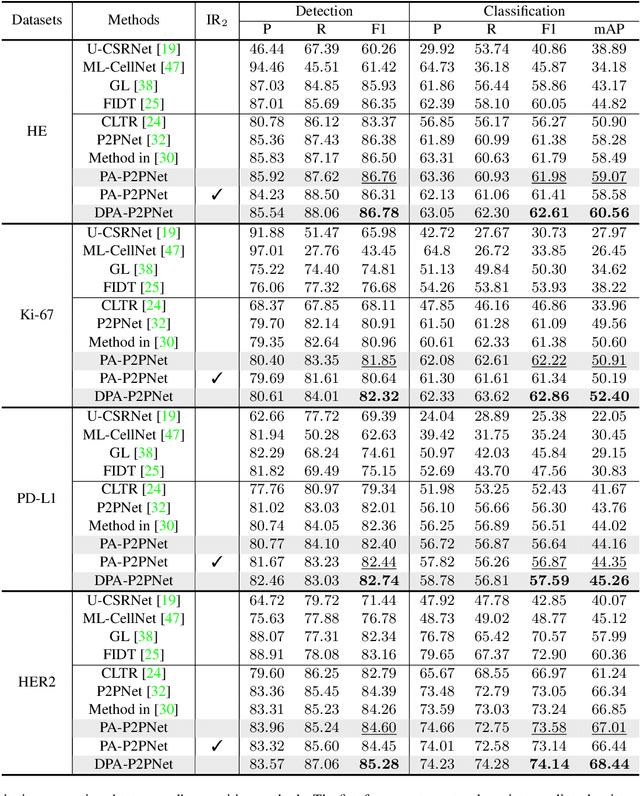
Point-based cell recognition, which aims to localize and classify cells present in a pathology image, is a fundamental task in digital pathology image analysis. The recently developed point-to-point network (P2PNet) has achieved unprecedented cell recognition accuracy and efficiency compared to methods that rely on intermediate density map representations. However, P2PNet could not leverage multi-scale information since it can only decode a single feature map. Moreover, the distribution of predefined point proposals, which is determined by data properties, restricts the resolution of the feature map to decode, i.e., the encoder design. To lift these limitations, we propose a variant of P2PNet named deformable proposal-aware P2PNet (DPA-P2PNet) in this study. The proposed method uses coordinates of point proposals to directly extract multi-scale region-of-interest (ROI) features for feature enhancement. Such a design also opens up possibilities to exploit dynamic distributions of proposals. We further devise a deformation module to improve the proposal quality. Extensive experiments on four datasets with various staining styles demonstrate that DPA-P2PNet outperforms the state-of-the-art methods on point-based cell recognition, which reveals the high potentiality in assisting pathologist assessments.
Deep Active Learning in the Presence of Label Noise: A Survey
Feb 22, 2023
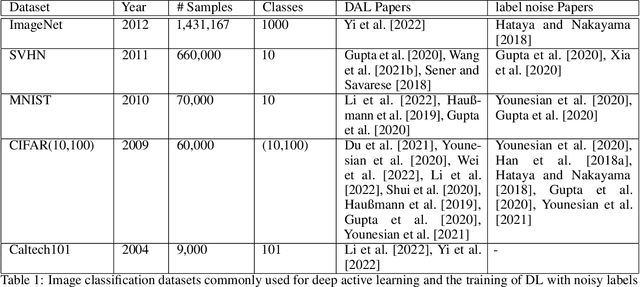
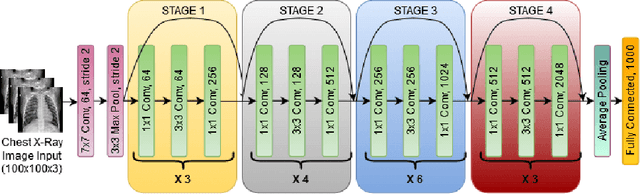
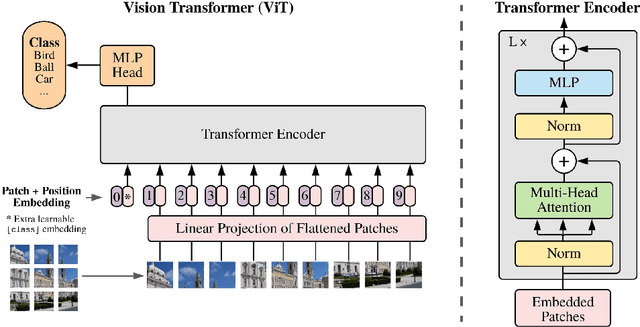
Deep active learning has emerged as a powerful tool for training deep learning models within a predefined labeling budget. These models have achieved performances comparable to those trained in an offline setting. However, deep active learning faces substantial issues when dealing with classification datasets containing noisy labels. In this literature review, we discuss the current state of deep active learning in the presence of label noise, highlighting unique approaches, their strengths, and weaknesses. With the recent success of vision transformers in image classification tasks, we provide a brief overview and consider how the transformer layers and attention mechanisms can be used to enhance diversity, importance, and uncertainty-based selection in queries sent to an oracle for labeling. We further propose exploring contrastive learning methods to derive good image representations that can aid in selecting high-value samples for labeling in an active learning setting. We also highlight the need for creating unified benchmarks and standardized datasets for deep active learning in the presence of label noise for image classification to promote the reproducibility of research. The review concludes by suggesting avenues for future research in this area.
Steerable Equivariant Representation Learning
Feb 22, 2023



Pre-trained deep image representations are useful for post-training tasks such as classification through transfer learning, image retrieval, and object detection. Data augmentations are a crucial aspect of pre-training robust representations in both supervised and self-supervised settings. Data augmentations explicitly or implicitly promote invariance in the embedding space to the input image transformations. This invariance reduces generalization to those downstream tasks which rely on sensitivity to these particular data augmentations. In this paper, we propose a method of learning representations that are instead equivariant to data augmentations. We achieve this equivariance through the use of steerable representations. Our representations can be manipulated directly in embedding space via learned linear maps. We demonstrate that our resulting steerable and equivariant representations lead to better performance on transfer learning and robustness: e.g. we improve linear probe top-1 accuracy by between 1% to 3% for transfer; and ImageNet-C accuracy by upto 3.4%. We further show that the steerability of our representations provides significant speedup (nearly 50x) for test-time augmentations; by applying a large number of augmentations for out-of-distribution detection, we significantly improve OOD AUC on the ImageNet-C dataset over an invariant representation.
OSRE: Object-to-Spot Rotation Estimation for Bike Parking Assessment
Mar 01, 2023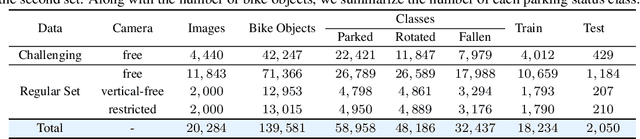

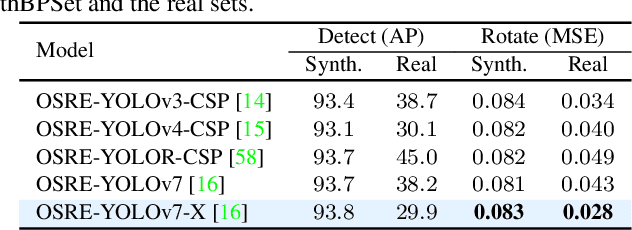
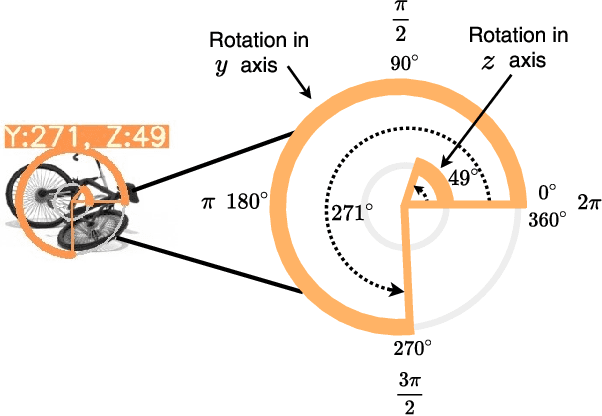
Current deep models provide remarkable object detection in terms of object classification and localization. However, estimating object rotation with respect to other visual objects in the visual context of an input image still lacks deep studies due to the unavailability of object datasets with rotation annotations. This paper tackles these two challenges to solve the rotation estimation of a parked bike with respect to its parking area. First, we leverage the power of 3D graphics to build a camera-agnostic well-annotated Synthetic Bike Rotation Dataset (SynthBRSet). Then, we propose an object-to-spot rotation estimator (OSRE) by extending the object detection task to further regress the bike rotations in two axes. Since our model is purely trained on synthetic data, we adopt image smoothing techniques when deploying it on real-world images. The proposed OSRE is evaluated on synthetic and real-world data providing promising results. Our data and code are available at \href{https://github.com/saghiralfasly/OSRE-Project}{https://github.com/saghiralfasly/OSRE-Project}.
RIFT2: Speeding-up RIFT with A New Rotation-Invariance Technique
Mar 01, 2023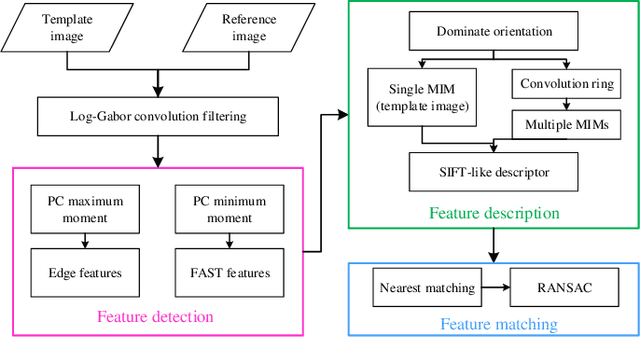
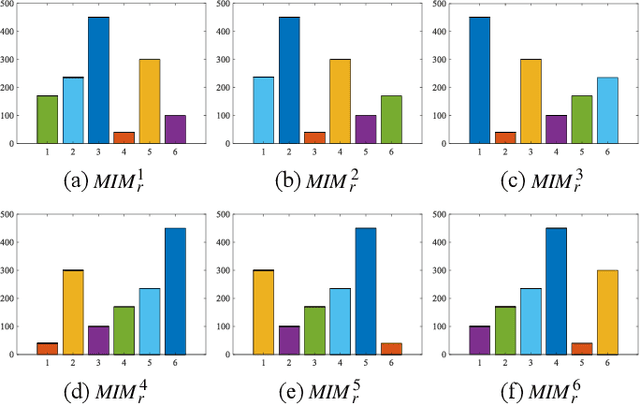

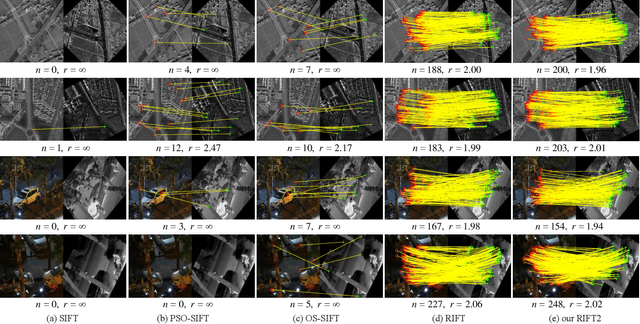
Multimodal image matching is an important prerequisite for multisource image information fusion. Compared with the traditional matching problem, multimodal feature matching is more challenging due to the severe nonlinear radiation distortion (NRD). Radiation-variation insensitive feature transform (RIFT)~\cite{li2019rift} has shown very good robustness to NRD and become a baseline method in multimodal feature matching. However, the high computational cost for rotation invariance largely limits its usage in practice. In this paper, we propose an improved RIFT method, called RIFT2. We develop a new rotation invariance technique based on dominant index value, which avoids the construction process of convolution sequence ring. Hence, it can speed up the running time and reduce the memory consumption of the original RIFT by almost 3 times in theory. Extensive experiments show that RIFT2 achieves similar matching performance to RIFT while being much faster and having less memory consumption. The source code will be made publicly available in \url{https://github.com/LJY-RS/RIFT2-multimodal-matching-rotation}
NeuroDAVIS: A neural network model for data visualization
Apr 01, 2023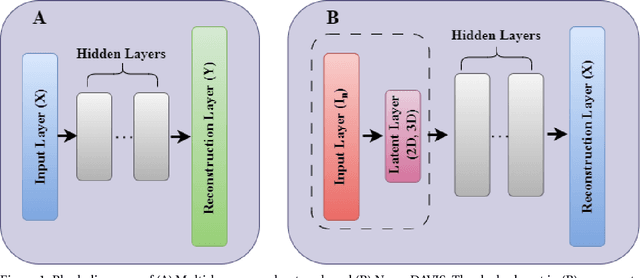
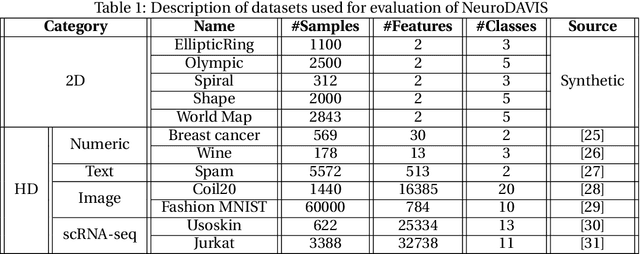
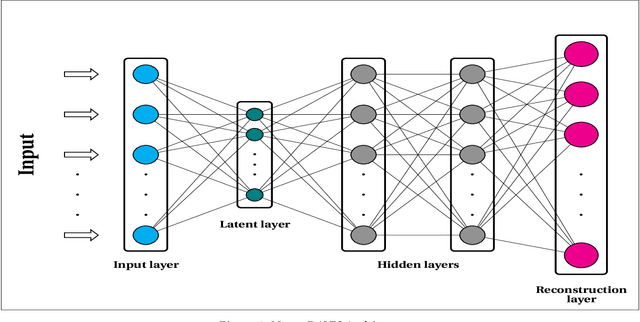
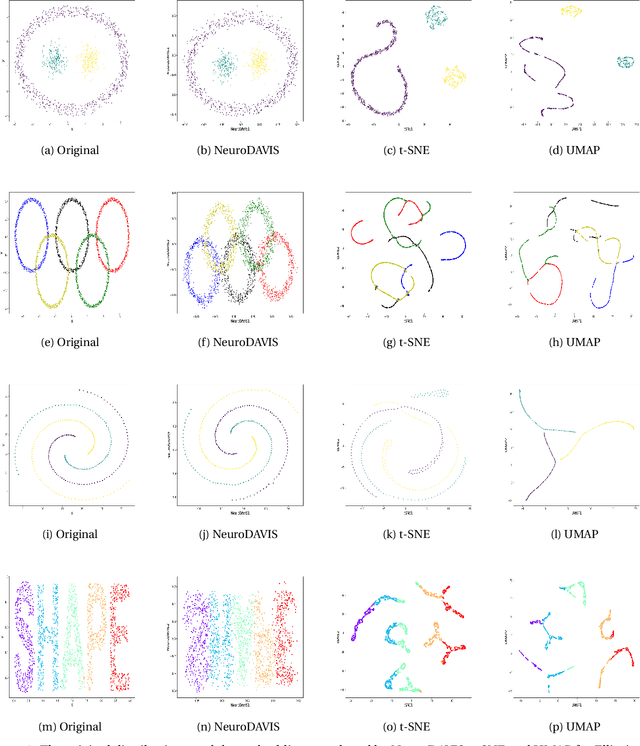
The task of dimensionality reduction and visualization of high-dimensional datasets remains a challenging problem since long. Modern high-throughput technologies produce newer high-dimensional datasets having multiple views with relatively new data types. Visualization of these datasets require proper methodology that can uncover hidden patterns in the data without affecting the local and global structures within the data. To this end, however, very few such methodology exist, which can realise this task. In this work, we have introduced a novel unsupervised deep neural network model, called NeuroDAVIS, for data visualization. NeuroDAVIS is capable of extracting important features from the data, without assuming any data distribution, and visualize effectively in lower dimension. It has been shown theoritically that neighbourhood relationship of the data in high dimension remains preserved in lower dimension. The performance of NeuroDAVIS has been evaluated on a wide variety of synthetic and real high-dimensional datasets including numeric, textual, image and biological data. NeuroDAVIS has been highly competitive against both t-Distributed Stochastic Neighbor Embedding (t-SNE) and Uniform Manifold Approximation and Projection (UMAP) with respect to visualization quality, and preservation of data size, shape, and both local and global structure. It has outperformed Fast interpolation-based t-SNE (Fit-SNE), a variant of t-SNE, for most of the high-dimensional datasets as well. For the biological datasets, besides t-SNE, UMAP and Fit-SNE, NeuroDAVIS has also performed well compared to other state-of-the-art algorithms, like Potential of Heat-diffusion for Affinity-based Trajectory Embedding (PHATE) and the siamese neural network-based method, called IVIS. Downstream classification and clustering analyses have also revealed favourable results for NeuroDAVIS-generated embeddings.
Inverse Image Frequency for Long-tailed Image Recognition
Sep 11, 2022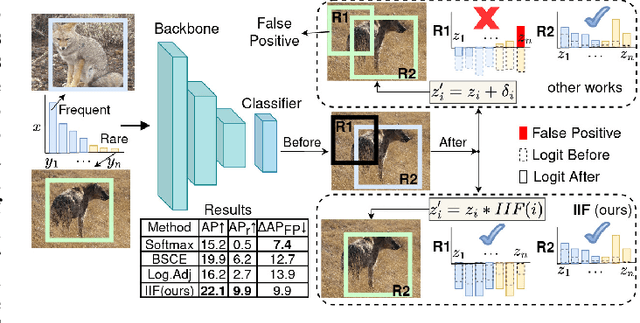
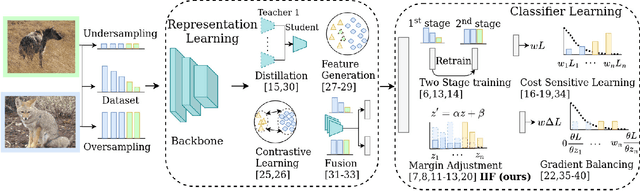
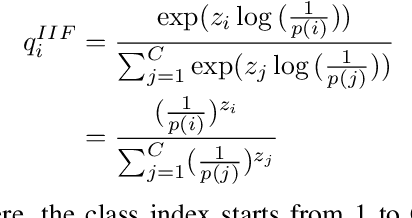
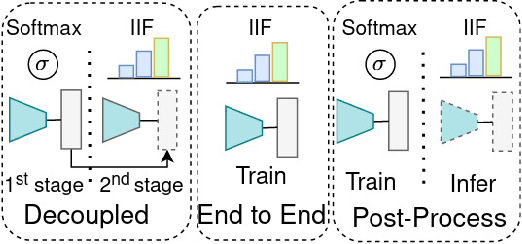
The long-tailed distribution is a common phenomenon in the real world. Extracted large scale image datasets inevitably demonstrate the long-tailed property and models trained with imbalanced data can obtain high performance for the over-represented categories, but struggle for the under-represented categories, leading to biased predictions and performance degradation. To address this challenge, we propose a novel de-biasing method named Inverse Image Frequency (IIF). IIF is a multiplicative margin adjustment transformation of the logits in the classification layer of a convolutional neural network. Our method achieves stronger performance than similar works and it is especially useful for downstream tasks such as long-tailed instance segmentation as it produces fewer false positive detections. Our extensive experiments show that IIF surpasses the state of the art on many long-tailed benchmarks such as ImageNet-LT, CIFAR-LT, Places-LT and LVIS, reaching 55.8% top-1 accuracy with ResNet50 on ImageNet-LT and 26.2% segmentation AP with MaskRCNN on LVIS. Code available at https://github.com/kostas1515/iif