 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing: Belief-Space Planning with Foundation Models as Uncertainty Estimators
Apr 04, 2025Generalizable robotic mobile manipulation in open-world environments poses significant challenges due to long horizons, complex goals, and partial observability. A promising approach to address these challenges involves planning with a library of parameterized skills, where a task planner sequences these skills to achieve goals specified in structured languages, such as logical expressions over symbolic facts. While vision-language models (VLMs) can be used to ground these expressions, they often assume full observability, leading to suboptimal behavior when the agent lacks sufficient information to evaluate facts with certainty. This paper introduces a novel framework that leverages VLMs as a perception module to estimate uncertainty and facilitate symbolic grounding. Our approach constructs a symbolic belief representation and uses a belief-space planner to generate uncertainty-aware plans that incorporate strategic information gathering. This enables the agent to effectively reason about partial observability and property uncertainty. We demonstrate our system on a range of challenging real-world tasks that require reasoning in partially observable environments. Simulated evaluations show that our approach outperforms both vanilla VLM-based end-to-end planning or VLM-based state estimation baselines by planning for and executing strategic information gathering. This work highlights the potential of VLMs to construct belief-space symbolic scene representations, enabling downstream tasks such as uncertainty-aware planning.
Practice Makes Perfect: Planning to Learn Skill Parameter Policies
Feb 22, 2024One promising approach towards effective robot decision making in complex, long-horizon tasks is to sequence together parameterized skills. We consider a setting where a robot is initially equipped with (1) a library of parameterized skills, (2) an AI planner for sequencing together the skills given a goal, and (3) a very general prior distribution for selecting skill parameters. Once deployed, the robot should rapidly and autonomously learn to improve its performance by specializing its skill parameter selection policy to the particular objects, goals, and constraints in its environment. In this work, we focus on the active learning problem of choosing which skills to practice to maximize expected future task success. We propose that the robot should estimate the competence of each skill, extrapolate the competence (asking: "how much would the competence improve through practice?"), and situate the skill in the task distribution through competence-aware planning. This approach is implemented within a fully autonomous system where the robot repeatedly plans, practices, and learns without any environment resets. Through experiments in simulation, we find that our approach learns effective parameter policies more sample-efficiently than several baselines. Experiments in the real-world demonstrate our approach's ability to handle noise from perception and control and improve the robot's ability to solve two long-horizon mobile-manipulation tasks after a few hours of autonomous practice.
Steerable Equivariant Representation Learning
Feb 22, 2023



Pre-trained deep image representations are useful for post-training tasks such as classification through transfer learning, image retrieval, and object detection. Data augmentations are a crucial aspect of pre-training robust representations in both supervised and self-supervised settings. Data augmentations explicitly or implicitly promote invariance in the embedding space to the input image transformations. This invariance reduces generalization to those downstream tasks which rely on sensitivity to these particular data augmentations. In this paper, we propose a method of learning representations that are instead equivariant to data augmentations. We achieve this equivariance through the use of steerable representations. Our representations can be manipulated directly in embedding space via learned linear maps. We demonstrate that our resulting steerable and equivariant representations lead to better performance on transfer learning and robustness: e.g. we improve linear probe top-1 accuracy by between 1% to 3% for transfer; and ImageNet-C accuracy by upto 3.4%. We further show that the steerability of our representations provides significant speedup (nearly 50x) for test-time augmentations; by applying a large number of augmentations for out-of-distribution detection, we significantly improve OOD AUC on the ImageNet-C dataset over an invariant representation.
Learning Operators with Ignore Effects for Bilevel Planning in Continuous Domains
Aug 16, 2022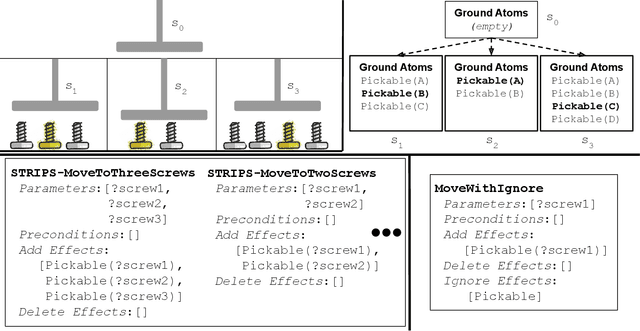
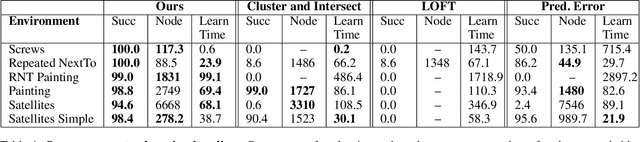
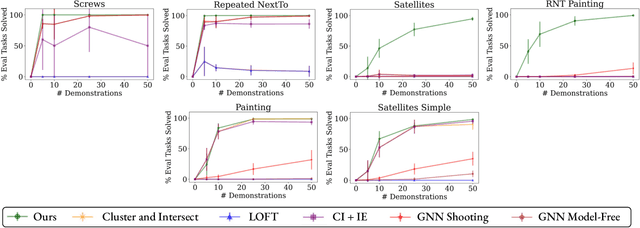
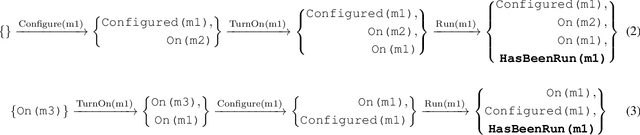
Bilevel planning, in which a high-level search over an abstraction of an environment is used to guide low-level decision making, is an effective approach to solving long-horizon tasks in continuous state and action spaces. Recent work has shown that action abstractions that enable such bilevel planning can be learned in the form of symbolic operators and neural samplers given symbolic predicates and demonstrations that achieve known goals. In this work, we show that existing approaches fall short in environments where actions tend to cause a large number of predicates to change. To address this issue, we propose to learn operators with ignore effects. The key idea motivating our approach is that modeling every observed change in the predicates is unnecessary; the only changes that need be modeled are those that are necessary for high-level search to achieve the specified goal. Experimentally, we show that our approach is able to learn operators with ignore effects across six hybrid robotic domains that enable an agent to solve novel variations of a task, with different initial states, goals, and numbers of objects, significantly more efficiently than several baselines.
Inventing Relational State and Action Abstractions for Effective and Efficient Bilevel Planning
Mar 17, 2022

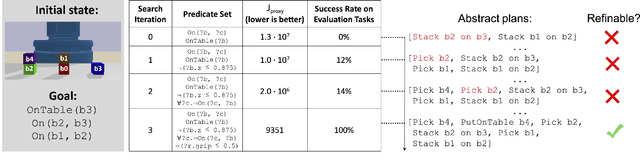

Effective and efficient planning in continuous state and action spaces is fundamentally hard, even when the transition model is deterministic and known. One way to alleviate this challenge is to perform bilevel planning with abstractions, where a high-level search for abstract plans is used to guide planning in the original transition space. In this paper, we develop a novel framework for learning state and action abstractions that are explicitly optimized for both effective (successful) and efficient (fast) bilevel planning. Given demonstrations of tasks in an environment, our data-efficient approach learns relational, neuro-symbolic abstractions that generalize over object identities and numbers. The symbolic components resemble the STRIPS predicates and operators found in AI planning, and the neural components refine the abstractions into actions that can be executed in the environment. Experimentally, we show across four robotic planning environments that our learned abstractions are able to quickly solve held-out tasks of longer horizons than were seen in the demonstrations, and can even outperform the efficiency of abstractions that we manually specified. We also find that as the planner configuration varies, the learned abstractions adapt accordingly, indicating that our abstraction learning method is both "task-aware" and "planner-aware." Code: https://tinyurl.com/predicators-release
HAC Explore: Accelerating Exploration with Hierarchical Reinforcement Learning
Aug 12, 2021
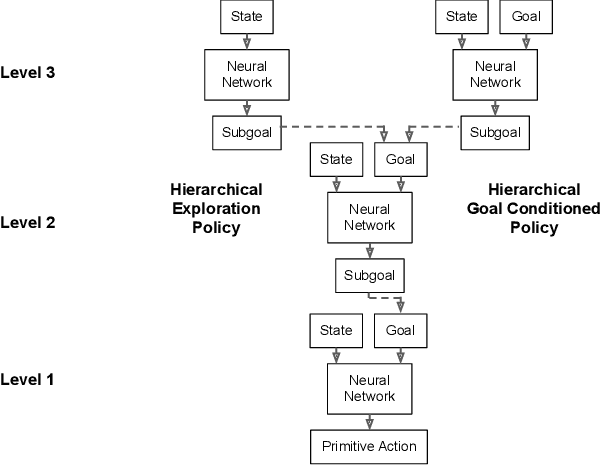
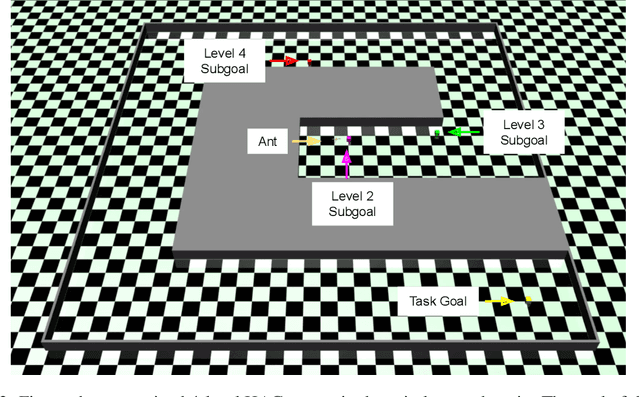
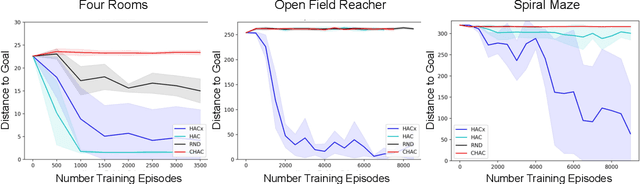
Sparse rewards and long time horizons remain challenging for reinforcement learning algorithms. Exploration bonuses can help in sparse reward settings by encouraging agents to explore the state space, while hierarchical approaches can assist with long-horizon tasks by decomposing lengthy tasks into shorter subtasks. We propose HAC Explore (HACx), a new method that combines these approaches by integrating the exploration bonus method Random Network Distillation (RND) into the hierarchical approach Hierarchical Actor-Critic (HAC). HACx outperforms either component method on its own, as well as an existing approach to combining hierarchy and exploration, in a set of difficult simulated robotics tasks. HACx is the first RL method to solve a sparse reward, continuous-control task that requires over 1,000 actions.