 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UniCT DMI Solution for 3rd COV19D Competition on COVID-19 Detection through attention-based CNN for CT Scan
Mar 22, 2023
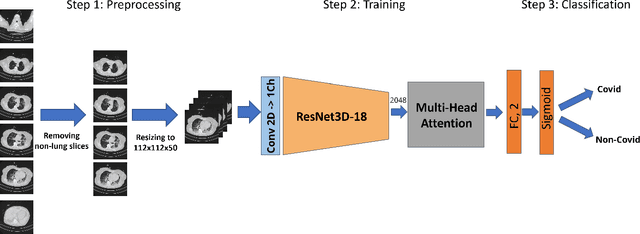
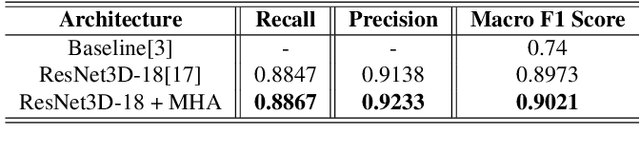
This paper presents our solution for the first challenge of the 3rd Covid-19 competition, which is part of the "AI-enabled Medical Image Analysis Workshop" organized by IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) 2023. Our proposed solution is based on a Resnet as a backbone network with the addition of attention mechanisms. The Resnet provides an effective feature extractor for the classification task, while the attention mechanisms improve the model's ability to focus on important regions of interest within the images. We conducted extensive experiments on the provided dataset and achieved promising results. Our proposed approach has the potential to assist in the accurate diagnosis of Covid-19 from chest computed tomography images, which can aid in the early detection and management of the disease.
You Only Train Once: Learning a General Anomaly Enhancement Network with Random Masks for Hyperspectral Anomaly Detection
Mar 31, 2023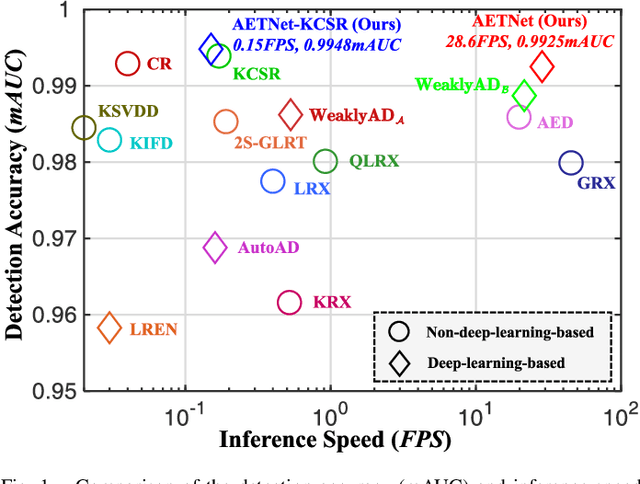
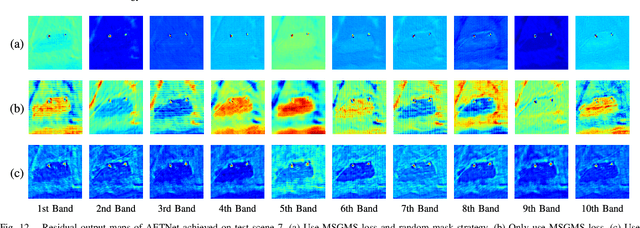
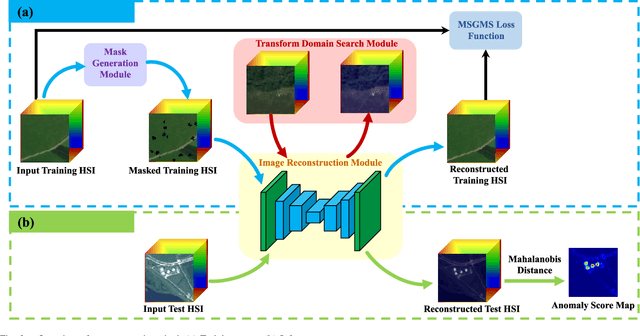
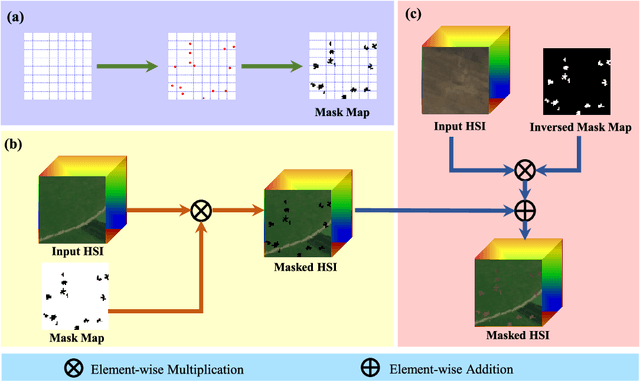
In this paper, we introduce a new approach to address the challenge of generalization in hyperspectral anomaly detection (AD). Our method eliminates the need for adjusting parameters or retraining on new test scenes as required by most existing methods. Employing an image-level training paradigm, we achieve a general anomaly enhancement network for hyperspectral AD that only needs to be trained once. Trained on a set of anomaly-free hyperspectral images with random masks, our network can learn the spatial context characteristics between anomalies and background in an unsupervised way. Additionally, a plug-and-play model selection module is proposed to search for a spatial-spectral transform domain that is more suitable for AD task than the original data. To establish a unified benchmark to comprehensively evaluate our method and existing methods, we develop a large-scale hyperspectral AD dataset (HAD100) that includes 100 real test scenes with diverse anomaly targets. In comparison experiments, we combine our network with a parameter-free detector and achieve the optimal balance between detection accuracy and inference speed among state-of-the-art AD methods. Experimental results also show that our method still achieves competitive performance when the training and test set are captured by different sensor devices. Our code is available at https://github.com/ZhaoxuLi123/AETNet.
The First Comprehensive Dataset with Multiple Distortion Types for Visual Just-Noticeable Differences
Mar 08, 2023
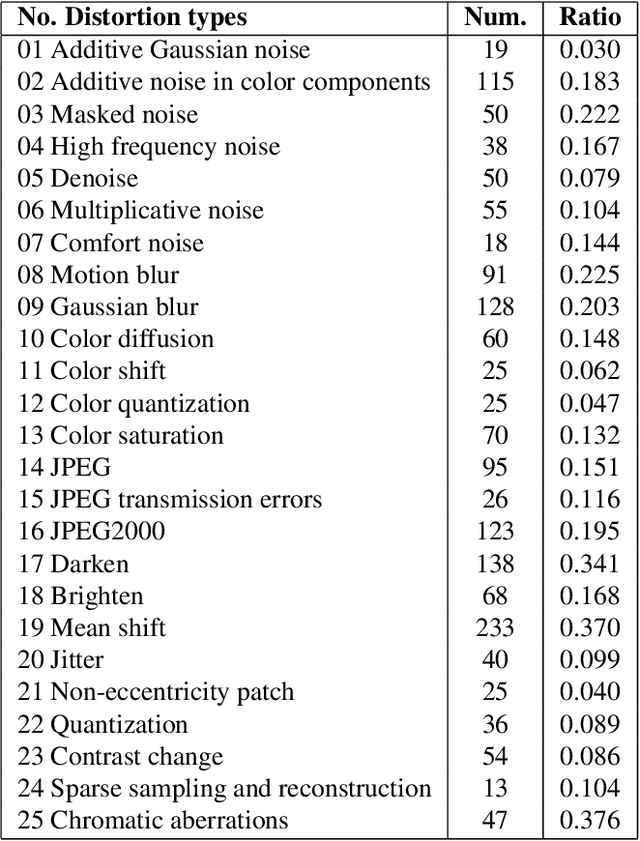
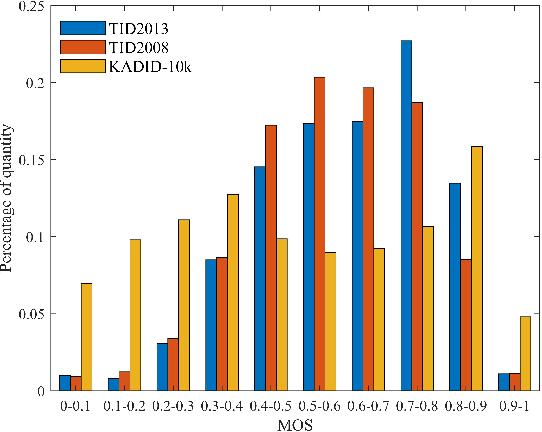
Recently, with the development of deep learning, a number of Just Noticeable Difference (JND) datasets have been built for JND modeling. However, all the existing JND datasets only label the JND points based on the level of compression distortion. Hence, JND models learned from such datasets can only be used for image/video compression. As known, JND is a major characteristic of the human visual system (HVS), which reflects the maximum visual distortion that the HVS can tolerate. Hence, a generalized JND modeling should take more kinds of distortion types into account. To benefit JND modeling, this work establishes a generalized JND dataset with a coarse-to-fine JND selection, which contains 106 source images and 1,642 JND maps, covering 25 distortion types. To this end, we proposed a coarse JND candidate selection scheme to select the distorted images from the existing Image Quality Assessment (IQA) datasets as JND candidates instead of generating JND maps ourselves. Then, a fine JND selection is carried out on the JND candidates with a crowdsourced subjective assessment.
Corner Detection Based on Multi-directional Gabor Filters with Multi-scales
Mar 08, 2023

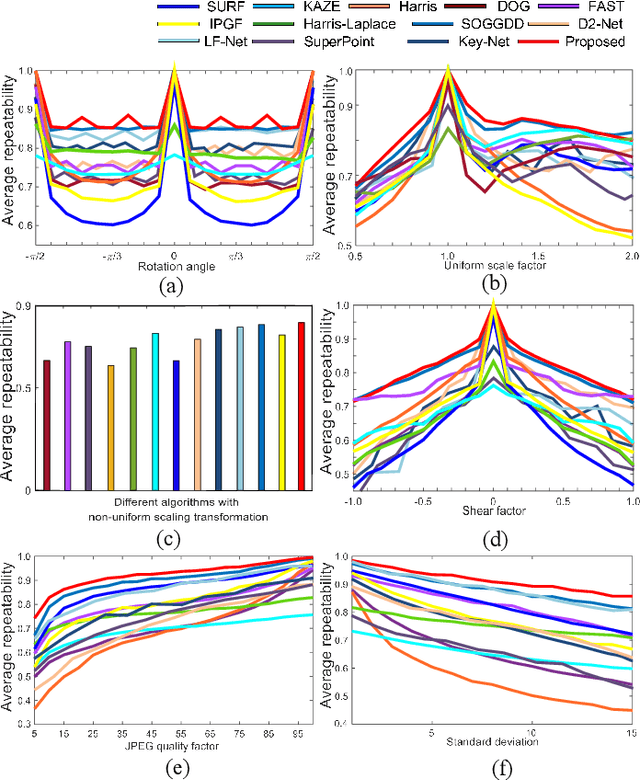
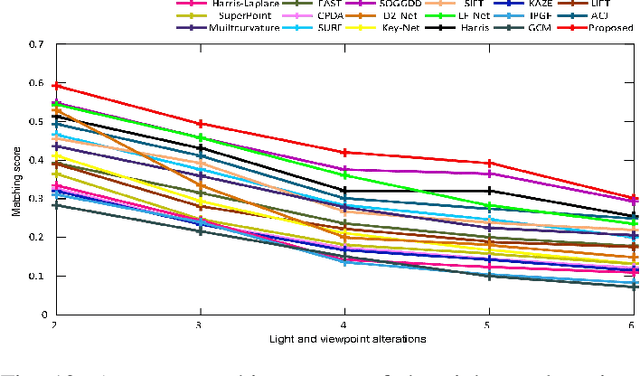
Gabor wavelet is an essential tool for image analysis and computer vision tasks. Local structure tensors with multiple scales are widely used in local feature extraction. Our research indicates that the current corner detection method based on Gabor wavelets can not effectively apply to complex scenes. In this work, the capability of the Gabor function to discriminate the intensity changes of step edges, L-shaped corners, Y-shaped or T-shaped corners, X-shaped corners, and star-shaped corners are investigated. The properties of Gabor wavelets to suppress affine image transformation are investigated and obtained. Many properties for edges and corners were discovered, which prompted us to propose a new corner extraction method. To fully use the structural information from the tuned Gabor filters, a novel multi-directional structure tensor is constructed for corner detection, and a multi-scale corner measurement function is proposed to remove false candidate corners. Furthermore, we compare the proposed method with twelve current state-of-the-art methods, which exhibit optimal performance and practical application to 3D reconstruction with good application potential.
4D iRIOM: 4D Imaging Radar Inertial Odometry and Mapping
Apr 03, 2023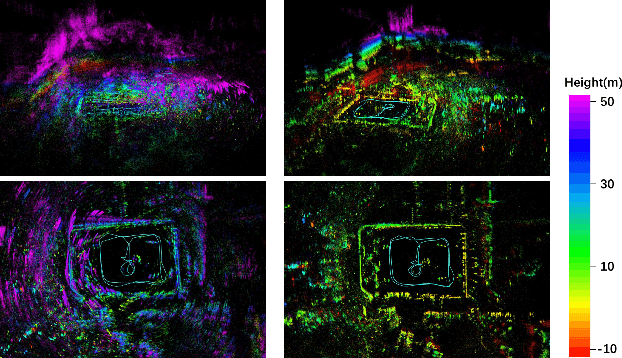
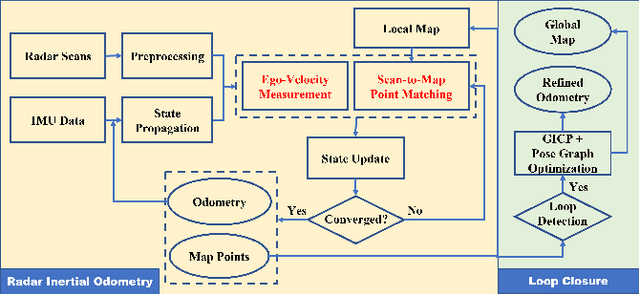

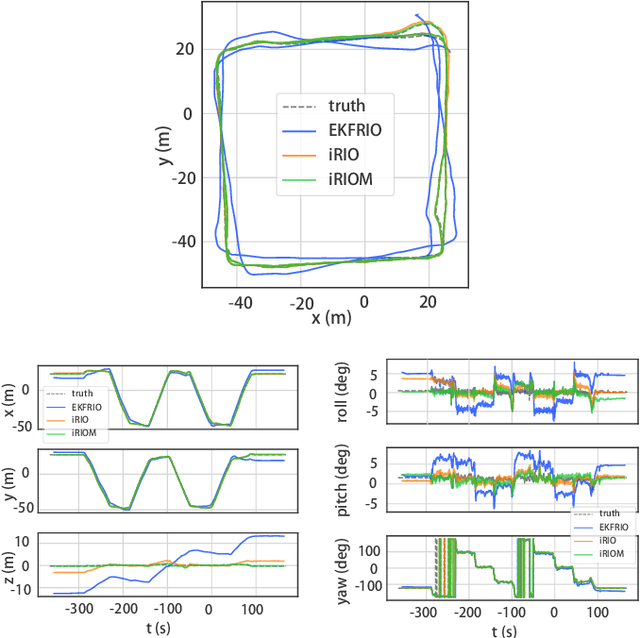
Millimeter wave radar can measure distances, directions, and Doppler velocity for objects in harsh conditions such as fog. The 4D imaging radar with both vertical and horizontal data resembling an image can also measure objects' height. Previous studies have used 3D radars for ego-motion estimation. But few methods leveraged the rich data of imaging radars, and they usually omitted the mapping aspect, thus leading to inferior odometry accuracy. This paper presents a real-time imaging radar inertial odometry and mapping method, iRIOM, based on the submap concept. To deal with moving objects and multipath reflections, we use the graduated non-convexity method to robustly and efficiently estimate ego-velocity from a single scan. To measure the agreement between sparse non-repetitive radar scan points and submap points, the distribution-to-multi-distribution distance for matches is adopted. The ego-velocity, scan-to-submap matches are fused with the 6D inertial data by an iterative extended Kalman filter to get the platform's 3D position and orientation. A loop closure module is also developed to curb the odometry module's drift. To our knowledge, iRIOM based on the two modules is the first 4D radar inertial SLAM system. On our and third-party data, we show iRIOM's favorable odometry accuracy and mapping consistency against the FastLIO-SLAM and the EKFRIO. Also, the ablation study reveal the benefit of inertial data versus the constant velocity model, and scan-to-submap matching versus scan-to-scan matching.
FinderNet: A Data Augmentation Free Canonicalization aided Loop Detection and Closure technique for Point clouds in 6-DOF separation
Apr 03, 2023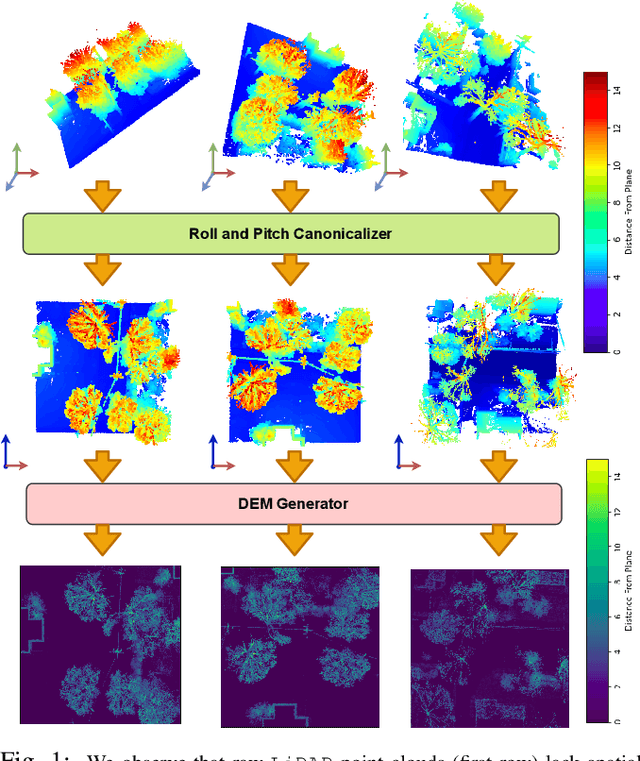
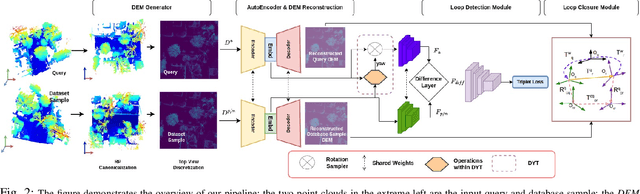
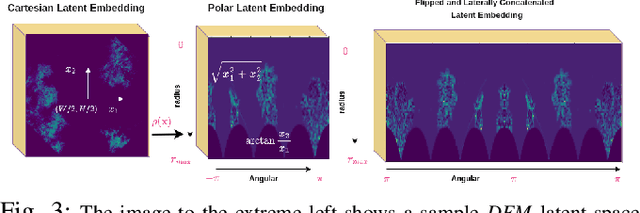
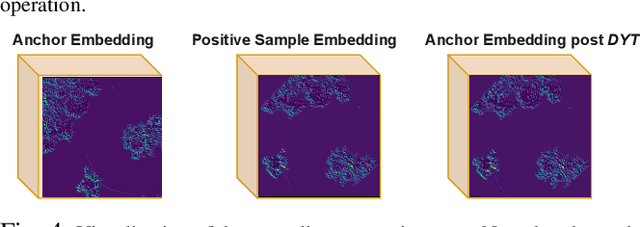
We focus on the problem of LiDAR point cloud based loop detection (or Finding) and closure (LDC) in a multi-agent setting. State-of-the-art (SOTA) techniques directly generate learned embeddings of a given point cloud, require large data transfers, and are not robust to wide variations in 6 Degrees-of-Freedom (DOF) viewpoint. Moreover, absence of strong priors in an unstructured point cloud leads to highly inaccurate LDC. In this original approach, we propose independent roll and pitch canonicalization of the point clouds using a common dominant ground plane. Discretization of the canonicalized point cloud along the axis perpendicular to the ground plane leads to an image similar to Digital Elevation Maps (DEMs), which exposes strong spatial priors in the scene. Our experiments show that LDC based on learnt embeddings of such DEMs is not only data efficient but also significantly more robust, and generalizable than the current SOTA. We report significant performance gain in terms of Average Precision for loop detection and absolute translation/rotation error for relative pose estimation (or loop closure) on Kitti, GPR and Oxford Robot Car over multiple SOTA LDC methods. Our encoder technique allows to compress the original point cloud by over 830 times. To further test the robustness of our technique we create and opensource a custom dataset called Lidar-UrbanFly Dataset (LUF) which consists of point clouds obtained from a LiDAR mounted on a quadrotor.
Spatial-Spectral Transformer for Hyperspectral Image Denoising
Nov 25, 2022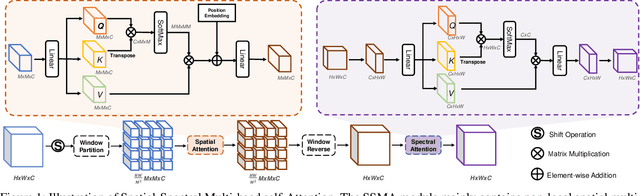
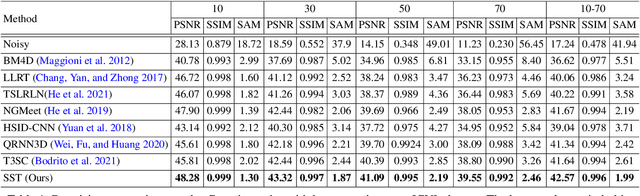
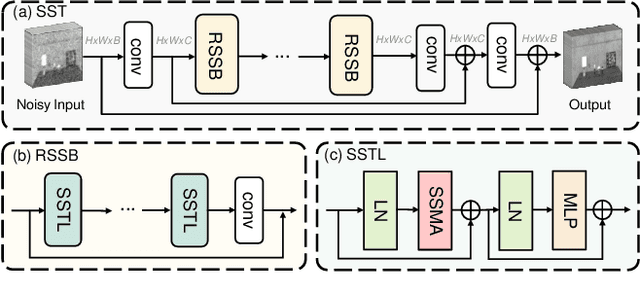
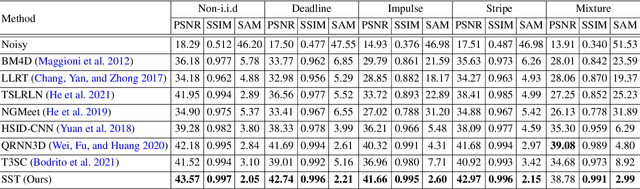
Hyperspectral image (HSI) denoising is a crucial preprocessing procedure for the subsequent HSI applications. Unfortunately, though witnessing the development of deep learning in HSI denoising area, existing convolution-based methods face the trade-off between computational efficiency and capability to model non-local characteristics of HSI. In this paper, we propose a Spatial-Spectral Transformer (SST) to alleviate this problem. To fully explore intrinsic similarity characteristics in both spatial dimension and spectral dimension, we conduct non-local spatial self-attention and global spectral self-attention with Transformer architecture. The window-based spatial self-attention focuses on the spatial similarity beyond the neighboring region. While, spectral self-attention exploits the long-range dependencies between highly correlative bands. Experimental results show that our proposed method outperforms the state-of-the-art HSI denoising methods in quantitative quality and visual results.
Synthetic aperture radar imaging below a random rough surface
Mar 23, 2023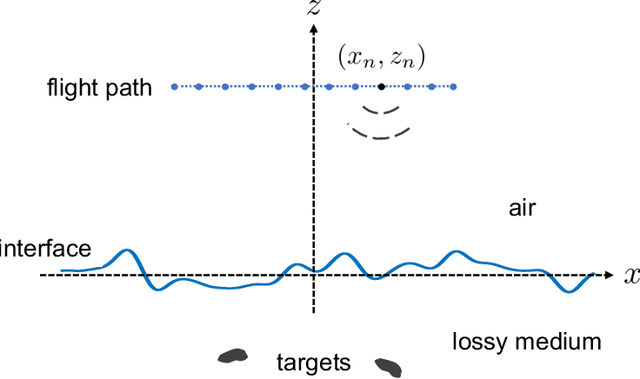
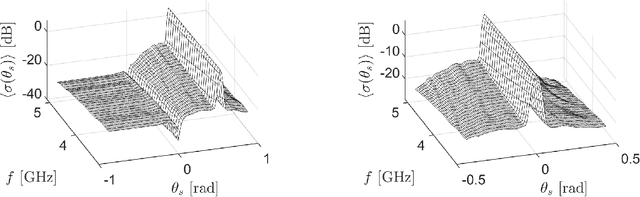
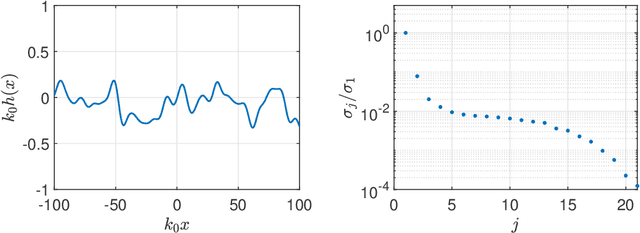
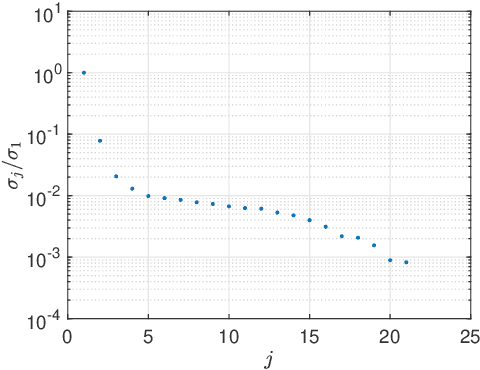
Motivated by applications in unmanned aerial based ground penetrating radar for detecting buried landmines, we consider the problem of imaging small point like scatterers situated in a lossy medium below a random rough surface. Both the random rough surface and the absorption in the lossy medium significantly impede the target detection and imaging process. Using principal component analysis we effectively remove the reflection from the air-soil interface. We then use a modification of the classical synthetic aperture radar imaging functional to image the targets. This imaging method introduces a user-defined parameter, $\delta$, which scales the resolution by $\sqrt{\delta}$ allowing for target localization with sub wavelength accuracy. Numerical results in two dimensions illustrate the robustness of the approach for imaging multiple targets. However, the depth at which targets are detectable is limited due to the absorption in the lossy medium.
Frequency-domain Blind Quality Assessment of Blurred and Blocking-artefact Images using Gaussian Process Regression model
Mar 05, 2023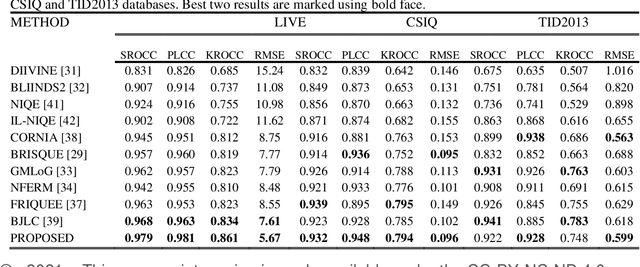
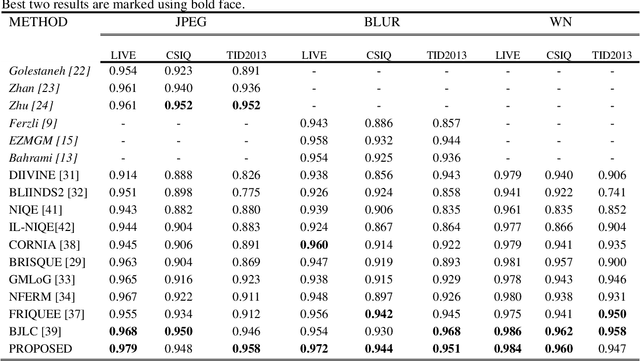

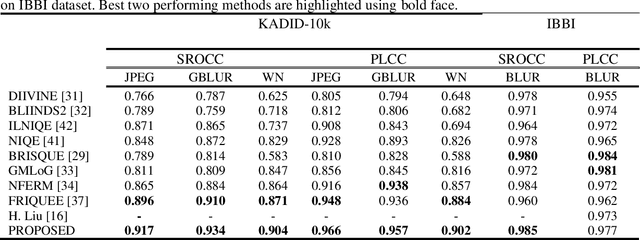
Most of the standard image and video codecs are block-based and depending upon the compression ratio the compressed images/videos suffer from different distortions. At low ratios, blurriness is observed and as compression increases blocking artifacts occur. Generally, in order to reduce blockiness, images are low-pass filtered which leads to more blurriness. Also, in bokeh mode images they are commonly seen: blurriness as a result of intentional blurred background while blocking artifact and global blurriness arising due to compression. Therefore, such visual media suffer from both blockiness and blurriness distortions. Along with this, noise is also commonly encountered distortion. Most of the existing works on quality assessment quantify these distortions individually. This paper proposes a methodology to blindly measure overall quality of an image suffering from these distortions, individually as well as jointly. This is achieved by considering the sum of absolute values of low and high-frequency Discrete Frequency Transform (DFT) coefficients defined as sum magnitudes. The number of blocks lying in specific ranges of sum magnitudes including zero-valued AC coefficients and mean of 100 maximum and 100 minimum values of these sum magnitudes are used as feature vectors. These features are then fed to the Machine Learning (ML) based Gaussian Process Regression (GPR) model, which quantifies the image quality. The simulation results show that the proposed method can estimate the quality of images distorted with the blockiness, blurriness, noise and their combinations. It is relatively fast compared to many state-of-art methods, and therefore is suitable for real-time quality monitoring applications.
Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing
Mar 02, 2023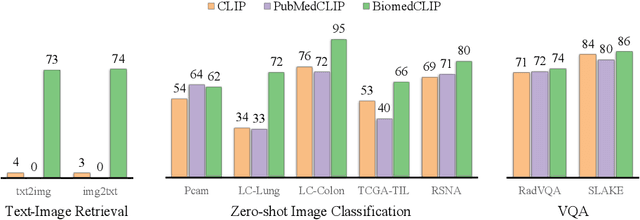



Contrastive pretraining on parallel image-text data has attained great success in vision-language processing (VLP), as exemplified by CLIP and related methods. However, prior explorations tend to focus on general domains in the web. Biomedical images and text are rather different, but publicly available datasets are small and skew toward chest X-ray, thus severely limiting progress. In this paper, we conducted by far the largest study on biomedical VLP, using 15 million figure-caption pairs extracted from biomedical research articles in PubMed Central. Our dataset (PMC-15M) is two orders of magnitude larger than existing biomedical image-text datasets such as MIMIC-CXR, and spans a diverse range of biomedical images. The standard CLIP method is suboptimal for the biomedical domain. We propose BiomedCLIP with domain-specific adaptations tailored to biomedical VLP. We conducted extensive experiments and ablation studies on standard biomedical imaging tasks from retrieval to classification to visual question-answering (VQA). BiomedCLIP established new state of the art in a wide range of standard datasets, substantially outperformed prior VLP approaches. Surprisingly, BiomedCLIP even outperformed radiology-specific state-of-the-art models such as BioViL on radiology-specific tasks such as RSNA pneumonia detection, thus highlighting the utility in large-scale pretraining across all biomedical image types. We will release our models at https://aka.ms/biomedclip to facilitate future research in biomedical VLP.