 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual Dependency Transformers: Dependency Tree Emerges from Reversed Attention
Apr 06, 2023
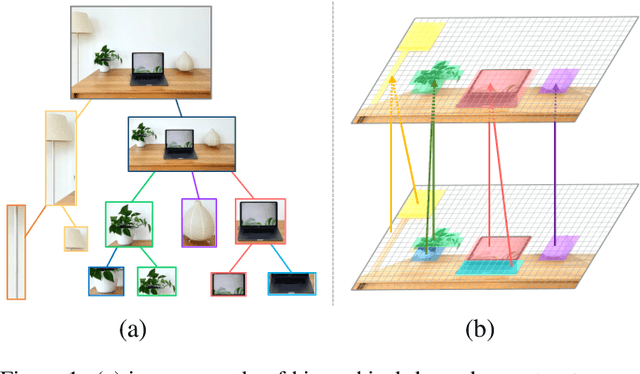
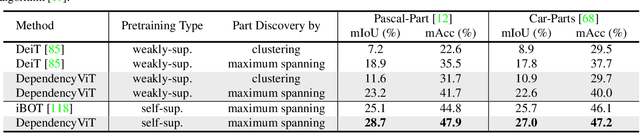
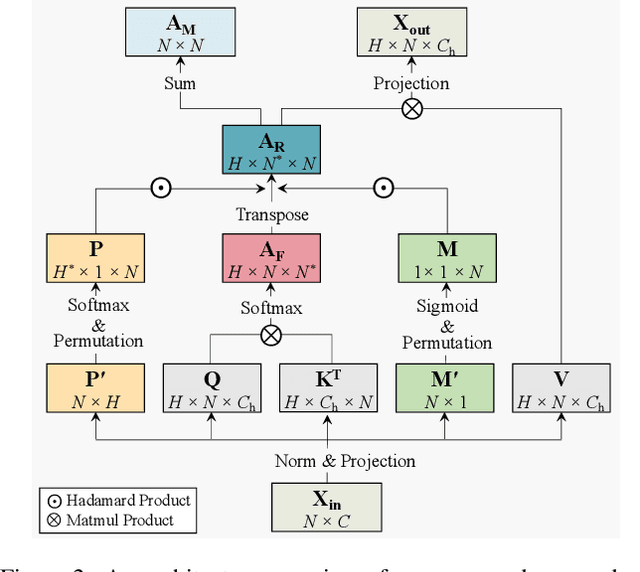
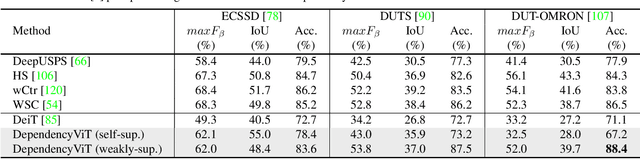
Humans possess a versatile mechanism for extracting structured representations of our visual world. When looking at an image, we can decompose the scene into entities and their parts as well as obtain the dependencies between them. To mimic such capability, we propose Visual Dependency Transformers (DependencyViT) that can induce visual dependencies without any labels. We achieve that with a novel neural operator called \emph{reversed attention} that can naturally capture long-range visual dependencies between image patches. Specifically, we formulate it as a dependency graph where a child token in reversed attention is trained to attend to its parent tokens and send information following a normalized probability distribution rather than gathering information in conventional self-attention. With such a design, hierarchies naturally emerge from reversed attention layers, and a dependency tree is progressively induced from leaf nodes to the root node unsupervisedly. DependencyViT offers several appealing benefits. (i) Entities and their parts in an image are represented by different subtrees, enabling part partitioning from dependencies; (ii) Dynamic visual pooling is made possible. The leaf nodes which rarely send messages can be pruned without hindering the model performance, based on which we propose the lightweight DependencyViT-Lite to reduce the computational and memory footprints; (iii) DependencyViT works well on both self- and weakly-supervised pretraining paradigms on ImageNet, and demonstrates its effectiveness on 8 datasets and 5 tasks, such as unsupervised part and saliency segmentation, recognition, and detection.
WSSL: Weighted Self-supervised Learning Framework For Image-inpainting
Nov 25, 2022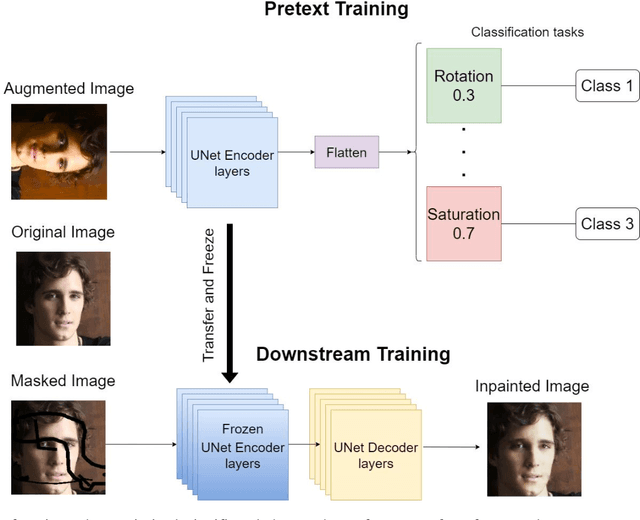
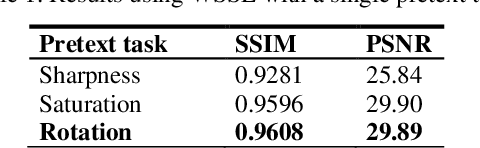
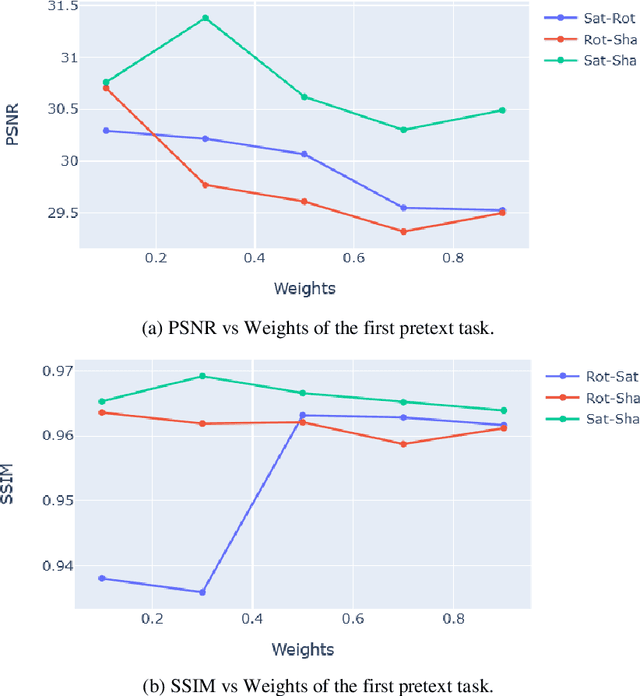
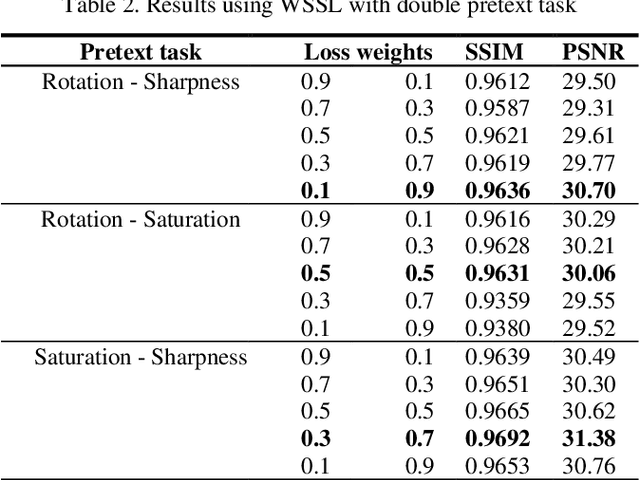
Image inpainting is the process of regenerating lost parts of the image. Supervised algorithm-based methods have shown excellent results but have two significant drawbacks. They do not perform well when tested with unseen data. They fail to capture the global context of the image, resulting in a visually unappealing result. We propose a novel self-supervised learning framework for image-inpainting: Weighted Self-Supervised Learning (WSSL) to tackle these problems. We designed WSSL to learn features from multiple weighted pretext tasks. These features are then utilized for the downstream task, image-inpainting. To improve the performance of our framework and produce more visually appealing images, we also present a novel loss function for image inpainting. The loss function takes advantage of both reconstruction loss and perceptual loss functions to regenerate the image. Our experimentation shows WSSL outperforms previous methods, and our loss function helps produce better results.
Instruct 3D-to-3D: Text Instruction Guided 3D-to-3D conversion
Mar 28, 2023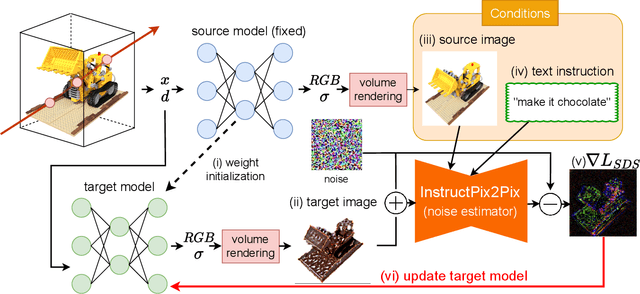
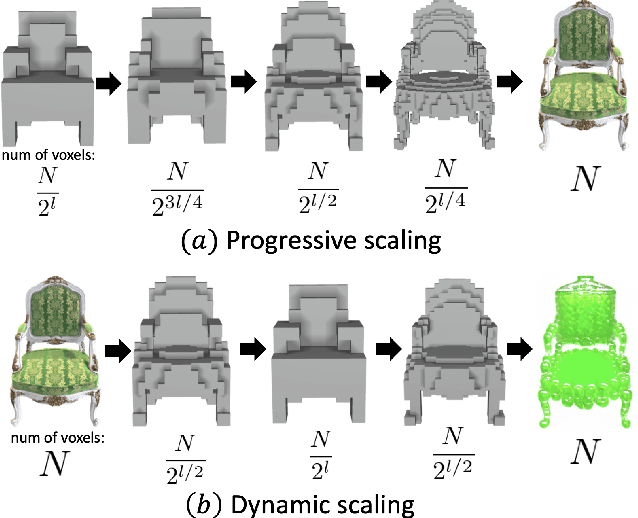

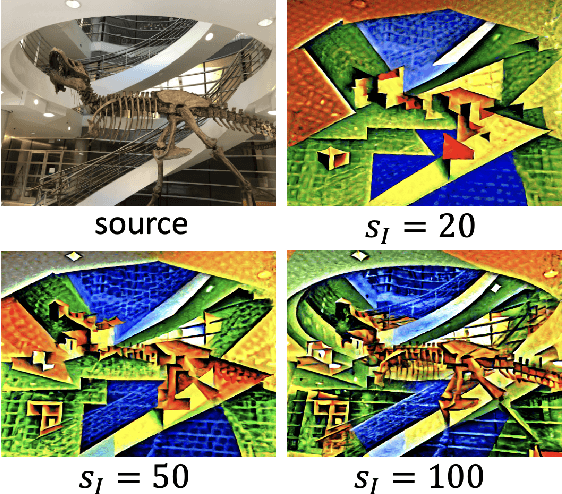
We propose a high-quality 3D-to-3D conversion method, Instruct 3D-to-3D. Our method is designed for a novel task, which is to convert a given 3D scene to another scene according to text instructions. Instruct 3D-to-3D applies pretrained Image-to-Image diffusion models for 3D-to-3D conversion. This enables the likelihood maximization of each viewpoint image and high-quality 3D generation. In addition, our proposed method explicitly inputs the source 3D scene as a condition, which enhances 3D consistency and controllability of how much of the source 3D scene structure is reflected. We also propose dynamic scaling, which allows the intensity of the geometry transformation to be adjusted. We performed quantitative and qualitative evaluations and showed that our proposed method achieves higher quality 3D-to-3D conversions than baseline methods.
Certified Zeroth-order Black-Box Defense with Robust UNet Denoiser
Apr 13, 2023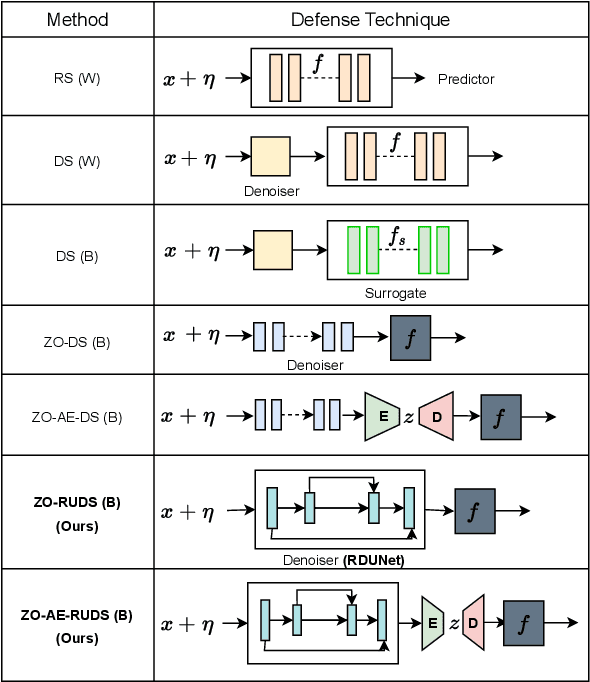
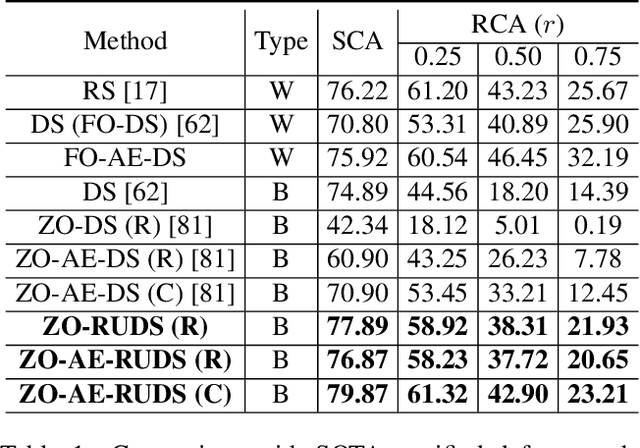
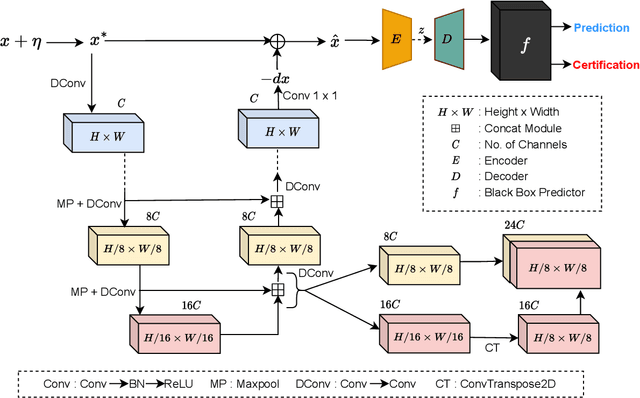
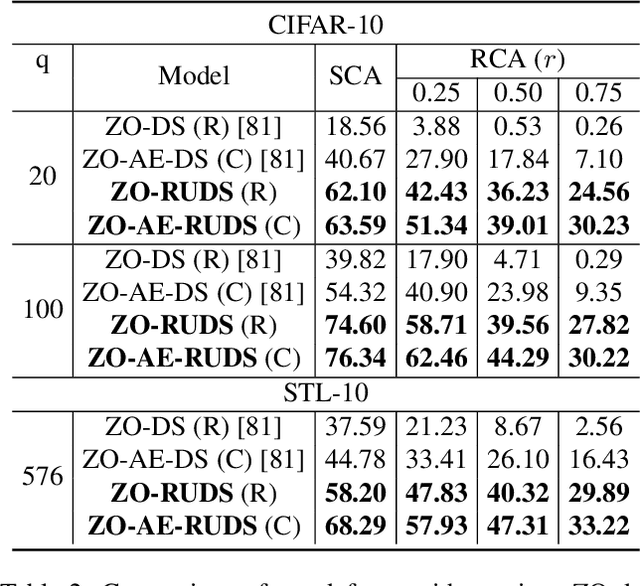
Certified defense methods against adversarial perturbations have been recently investigated in the black-box setting with a zeroth-order (ZO) perspective. However, these methods suffer from high model variance with low performance on high-dimensional datasets due to the ineffective design of the denoiser and are limited in their utilization of ZO techniques. To this end, we propose a certified ZO preprocessing technique for removing adversarial perturbations from the attacked image in the black-box setting using only model queries. We propose a robust UNet denoiser (RDUNet) that ensures the robustness of black-box models trained on high-dimensional datasets. We propose a novel black-box denoised smoothing (DS) defense mechanism, ZO-RUDS, by prepending our RDUNet to the black-box model, ensuring black-box defense. We further propose ZO-AE-RUDS in which RDUNet followed by autoencoder (AE) is prepended to the black-box model. We perform extensive experiments on four classification datasets, CIFAR-10, CIFAR-10, Tiny Imagenet, STL-10, and the MNIST dataset for image reconstruction tasks. Our proposed defense methods ZO-RUDS and ZO-AE-RUDS beat SOTA with a huge margin of $35\%$ and $9\%$, for low dimensional (CIFAR-10) and with a margin of $20.61\%$ and $23.51\%$ for high-dimensional (STL-10) datasets, respectively.
Efficient 3-D Near-Field MIMO-SAR Imaging for Irregular Scanning Geometries
May 03, 2023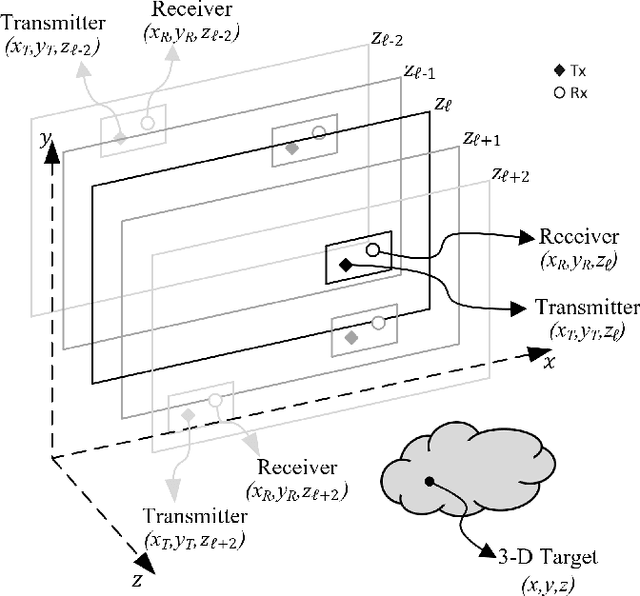
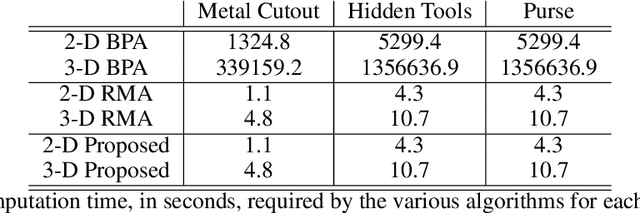
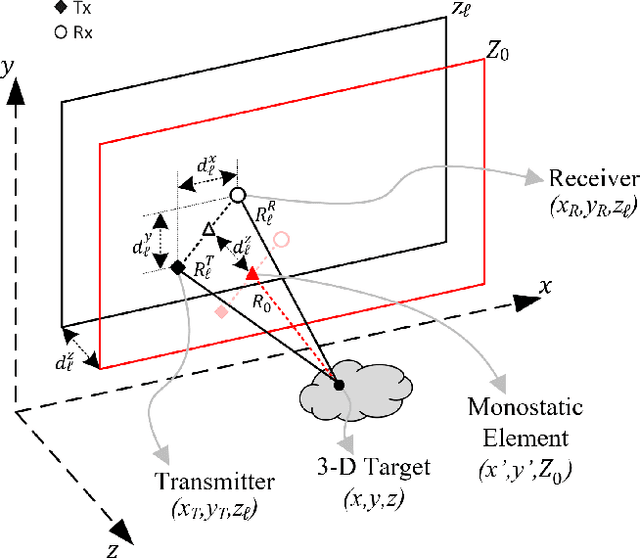
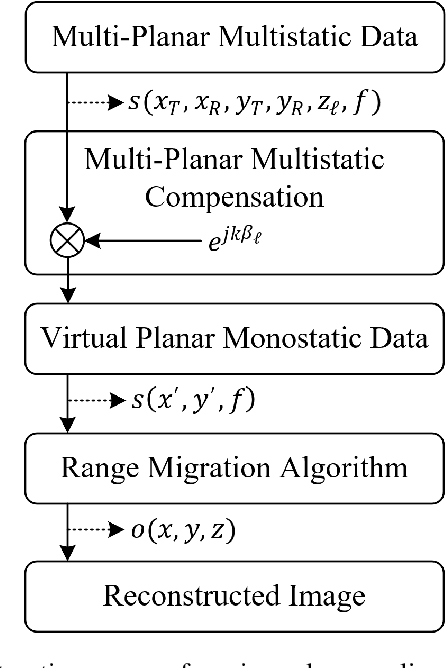
In this article, we introduce a novel algorithm for efficient near-field synthetic aperture radar (SAR) imaging for irregular scanning geometries. With the emergence of fifth-generation (5G) millimeter-wave (mmWave) devices, near-field SAR imaging is no longer confined to laboratory environments. Recent advances in positioning technology have attracted significant interest for a diverse set of new applications in mmWave imaging. However, many use cases, such as automotive-mounted SAR imaging, unmanned aerial vehicle (UAV) imaging, and freehand imaging with smartphones, are constrained to irregular scanning geometries. Whereas traditional near-field SAR imaging systems and quick personnel security (QPS) scanners employ highly precise motion controllers to create ideal synthetic arrays, emerging applications, mentioned previously, inherently cannot achieve such ideal positioning. In addition, many Internet of Things (IoT) and 5G applications impose strict size and computational complexity limitations that must be considered for edge mmWave imaging technology. In this study, we propose a novel algorithm to leverage the advantages of non-cooperative SAR scanning patterns, small form-factor multiple-input multiple-output (MIMO) radars, and efficient monostatic planar image reconstruction algorithms. We propose a framework to mathematically decompose arbitrary and irregular sampling geometries and a joint solution to mitigate multistatic array imaging artifacts. The proposed algorithm is validated through simulations and an empirical study of arbitrary scanning scenarios. Our algorithm achieves high-resolution and high-efficiency near-field MIMO-SAR imaging, and is an elegant solution to computationally constrained irregularly sampled imaging problems.
* Accepted to IEEE Access
Your Diffusion Model is Secretly a Zero-Shot Classifier
Mar 29, 2023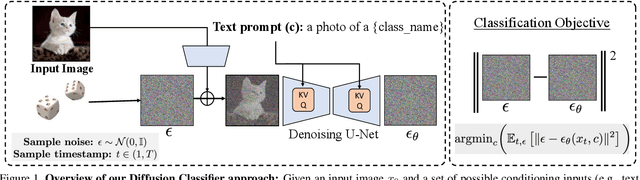

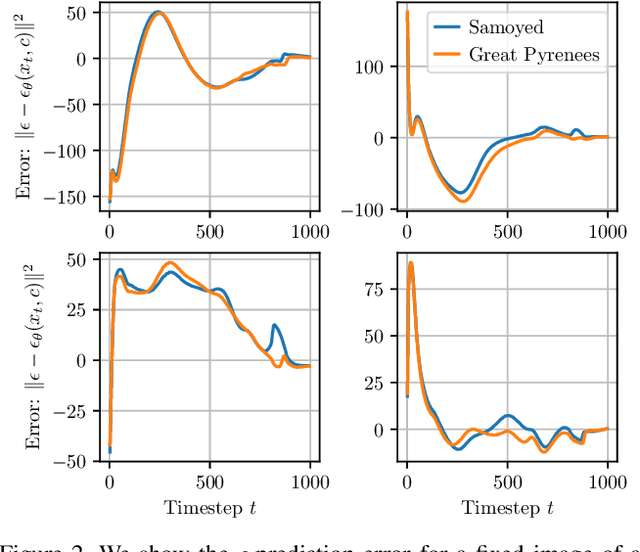
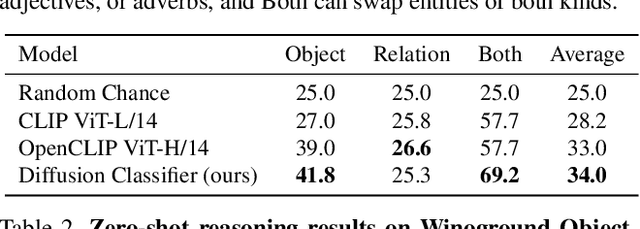
The recent wave of large-scale text-to-image diffusion models has dramatically increased our text-based image generation abilities. These models can generate realistic images for a staggering variety of prompts and exhibit impressive compositional generalization abilities. Almost all use cases thus far have solely focused on sampling; however, diffusion models can also provide conditional density estimates, which are useful for tasks beyond image generation. In this paper, we show that the density estimates from large-scale text-to-image diffusion models like Stable Diffusion can be leveraged to perform zero-shot classification without any additional training. Our generative approach to classification, which we call Diffusion Classifier, attains strong results on a variety of benchmarks and outperforms alternative methods of extracting knowledge from diffusion models. Although a gap remains between generative and discriminative approaches on zero-shot recognition tasks, we find that our diffusion-based approach has stronger multimodal relational reasoning abilities than competing discriminative approaches. Finally, we use Diffusion Classifier to extract standard classifiers from class-conditional diffusion models trained on ImageNet. Even though these models are trained with weak augmentations and no regularization, they approach the performance of SOTA discriminative classifiers. Overall, our results are a step toward using generative over discriminative models for downstream tasks. Results and visualizations at https://diffusion-classifier.github.io/
Enhancing Medical Image Segmentation with TransCeption: A Multi-Scale Feature Fusion Approach
Jan 25, 2023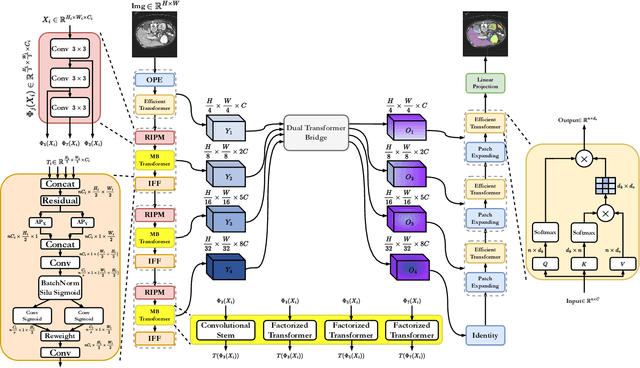
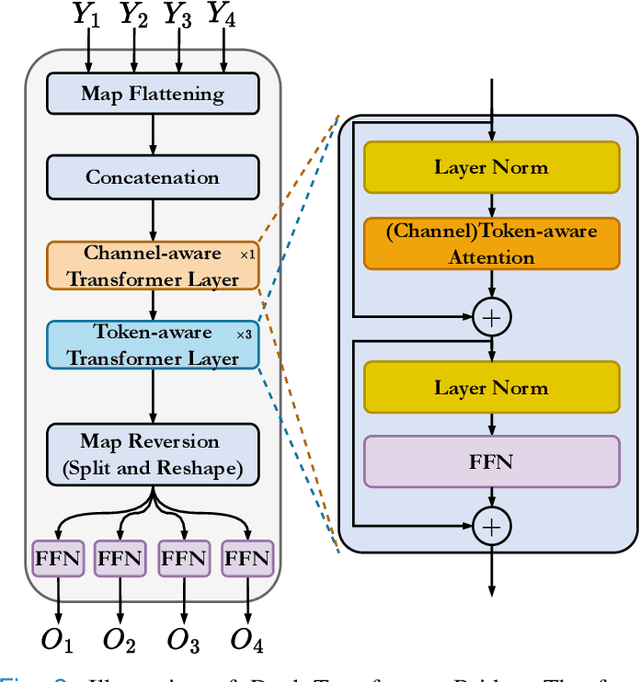
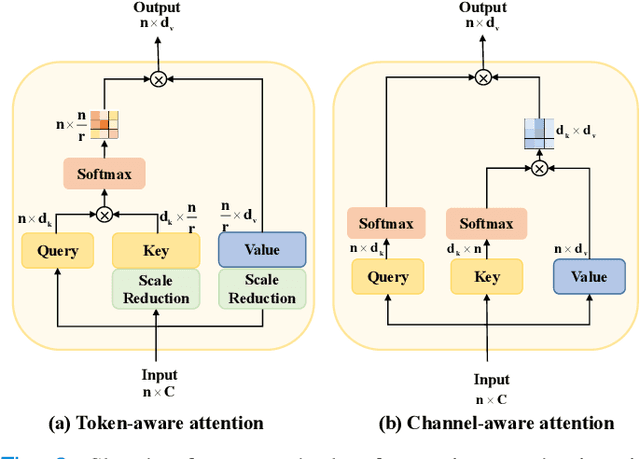
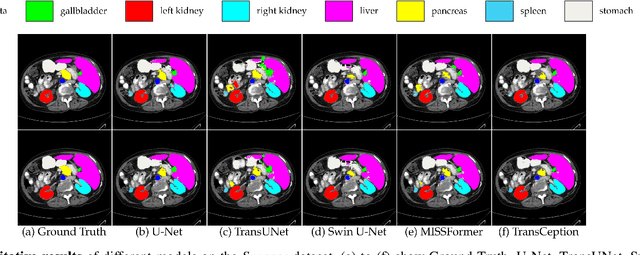
While CNN-based methods have been the cornerstone of medical image segmentation due to their promising performance and robustness, they suffer from limitations in capturing long-range dependencies. Transformer-based approaches are currently prevailing since they enlarge the reception field to model global contextual correlation. To further extract rich representations, some extensions of the U-Net employ multi-scale feature extraction and fusion modules and obtain improved performance. Inspired by this idea, we propose TransCeption for medical image segmentation, a pure transformer-based U-shape network featured by incorporating the inception-like module into the encoder and adopting a contextual bridge for better feature fusion. The design proposed in this work is based on three core principles: (1) The patch merging module in the encoder is redesigned with ResInception Patch Merging (RIPM). Multi-branch transformer (MB transformer) adopts the same number of branches as the outputs of RIPM. Combining the two modules enables the model to capture a multi-scale representation within a single stage. (2) We construct an Intra-stage Feature Fusion (IFF) module following the MB transformer to enhance the aggregation of feature maps from all the branches and particularly focus on the interaction between the different channels of all the scales. (3) In contrast to a bridge that only contains token-wise self-attention, we propose a Dual Transformer Bridge that also includes channel-wise self-attention to exploit correlations between scales at different stages from a dual perspective. Extensive experiments on multi-organ and skin lesion segmentation tasks present the superior performance of TransCeption compared to previous work. The code is publicly available at \url{https://github.com/mindflow-institue/TransCeption}.
Open-Vocabulary Point-Cloud Object Detection without 3D Annotation
Apr 03, 2023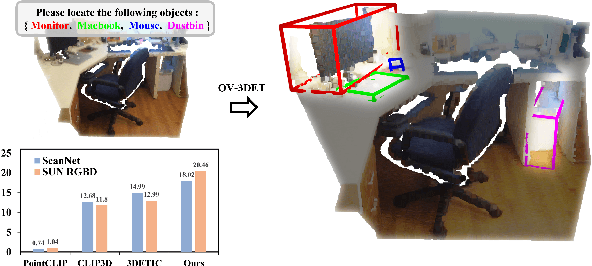
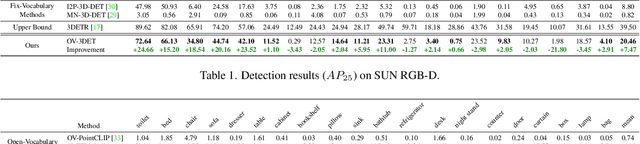
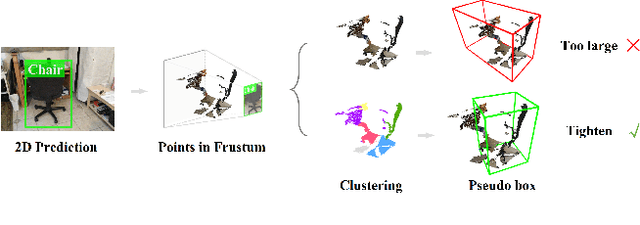

The goal of open-vocabulary detection is to identify novel objects based on arbitrary textual descriptions. In this paper, we address open-vocabulary 3D point-cloud detection by a dividing-and-conquering strategy, which involves: 1) developing a point-cloud detector that can learn a general representation for localizing various objects, and 2) connecting textual and point-cloud representations to enable the detector to classify novel object categories based on text prompting. Specifically, we resort to rich image pre-trained models, by which the point-cloud detector learns localizing objects under the supervision of predicted 2D bounding boxes from 2D pre-trained detectors. Moreover, we propose a novel de-biased triplet cross-modal contrastive learning to connect the modalities of image, point-cloud and text, thereby enabling the point-cloud detector to benefit from vision-language pre-trained models,i.e.,CLIP. The novel use of image and vision-language pre-trained models for point-cloud detectors allows for open-vocabulary 3D object detection without the need for 3D annotations. Experiments demonstrate that the proposed method improves at least 3.03 points and 7.47 points over a wide range of baselines on the ScanNet and SUN RGB-D datasets, respectively. Furthermore, we provide a comprehensive analysis to explain why our approach works.
A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion
Apr 03, 2023



Despite the record-breaking performance in Text-to-Image (T2I) generation by Stable Diffusion, less research attention is paid to its adversarial robustness. In this work, we study the problem of adversarial attack generation for Stable Diffusion and ask if an adversarial text prompt can be obtained even in the absence of end-to-end model queries. We call the resulting problem 'query-free attack generation'. To resolve this problem, we show that the vulnerability of T2I models is rooted in the lack of robustness of text encoders, e.g., the CLIP text encoder used for attacking Stable Diffusion. Based on such insight, we propose both untargeted and targeted query-free attacks, where the former is built on the most influential dimensions in the text embedding space, which we call steerable key dimensions. By leveraging the proposed attacks, we empirically show that only a five-character perturbation to the text prompt is able to cause the significant content shift of synthesized images using Stable Diffusion. Moreover, we show that the proposed target attack can precisely steer the diffusion model to scrub the targeted image content without causing much change in untargeted image content. Our code is available at https://github.com/OPTML-Group/QF-Attack.
CRN: Camera Radar Net for Accurate, Robust, Efficient 3D Perception
Apr 03, 2023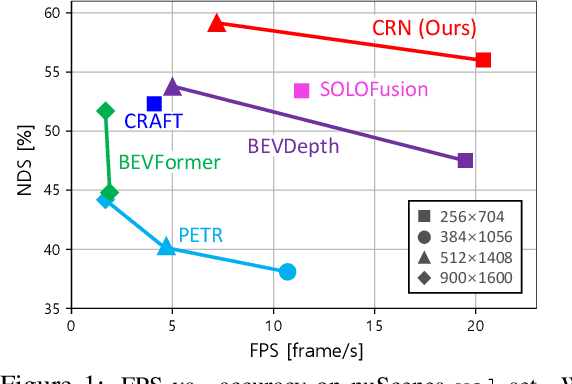
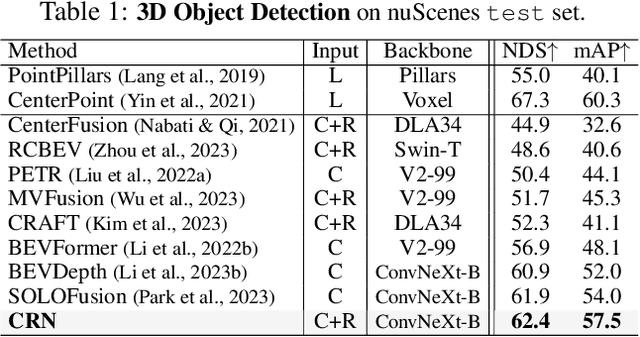
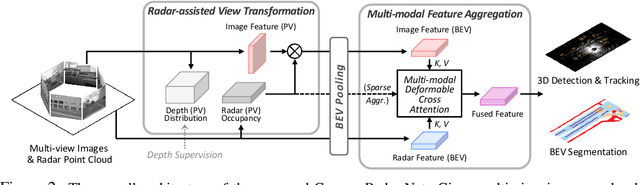
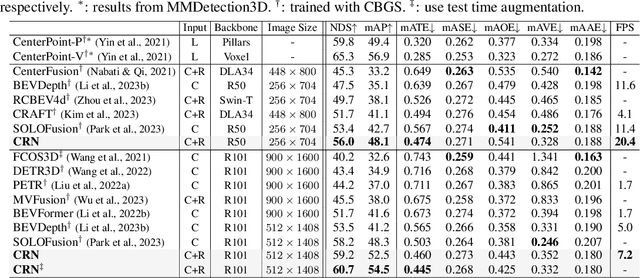
Autonomous driving requires an accurate and fast 3D perception system that includes 3D object detection, tracking, and segmentation. Although recent low-cost camera-based approaches have shown promising results, they are susceptible to poor illumination or bad weather conditions and have a large localization error. Hence, fusing camera with low-cost radar, which provides precise long-range measurement and operates reliably in all environments, is promising but has not yet been thoroughly investigated. In this paper, we propose Camera Radar Net (CRN), a novel camera-radar fusion framework that generates a semantically rich and spatially accurate bird's-eye-view (BEV) feature map for various tasks. To overcome the lack of spatial information in an image, we transform perspective view image features to BEV with the help of sparse but accurate radar points. We further aggregate image and radar feature maps in BEV using multi-modal deformable attention designed to tackle the spatial misalignment between inputs. CRN with real-time setting operates at 20 FPS while achieving comparable performance to LiDAR detectors on nuScenes, and even outperforms at a far distance on 100m setting. Moreover, CRN with offline setting yields 62.4% NDS, 57.5% mAP on nuScenes test set and ranks first among all camera and camera-radar 3D object detectors.