 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWSSL: Weighted Self-supervised Learning Framework For Image-inpainting
Nov 25, 2022



Image inpainting is the process of regenerating lost parts of the image. Supervised algorithm-based methods have shown excellent results but have two significant drawbacks. They do not perform well when tested with unseen data. They fail to capture the global context of the image, resulting in a visually unappealing result. We propose a novel self-supervised learning framework for image-inpainting: Weighted Self-Supervised Learning (WSSL) to tackle these problems. We designed WSSL to learn features from multiple weighted pretext tasks. These features are then utilized for the downstream task, image-inpainting. To improve the performance of our framework and produce more visually appealing images, we also present a novel loss function for image inpainting. The loss function takes advantage of both reconstruction loss and perceptual loss functions to regenerate the image. Our experimentation shows WSSL outperforms previous methods, and our loss function helps produce better results.
Robustness to Augmentations as a Generalization metric
Jan 16, 2021

Generalization is the ability of a model to predict on unseen domains and is a fundamental task in machine learning. Several generalization bounds, both theoretical and empirical have been proposed but they do not provide tight bounds .In this work, we propose a simple yet effective method to predict the generalization performance of a model by using the concept that models that are robust to augmentations are more generalizable than those which are not. We experiment with several augmentations and composition of augmentations to check the generalization capacity of a model. We also provide a detailed motivation behind the proposed method. The proposed generalization metric is calculated based on the change in the output of the model after augmenting the input. The proposed method was the first runner up solution for the NeurIPS competition on Predicting Generalization in Deep Learning.
Transfer Learning using Neural Ordinary Differential Equations
Jan 21, 2020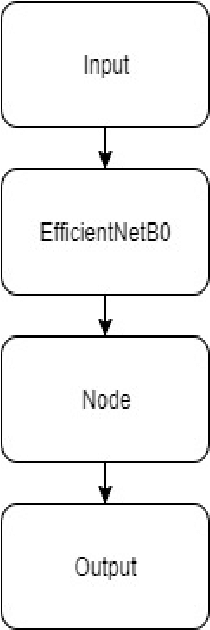
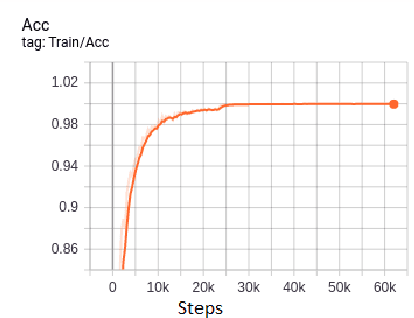
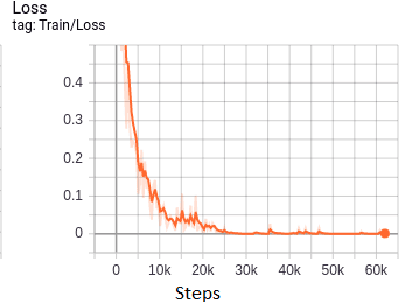
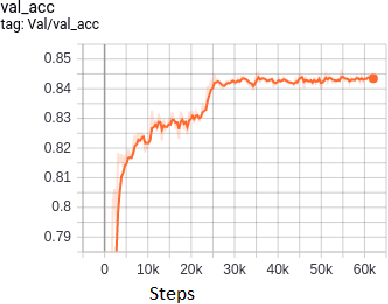
A concept of using Neural Ordinary Differential Equations(NODE) for Transfer Learning has been introduced. In this paper we use the EfficientNets to explore transfer learning on CIFAR-10 dataset. We use NODE for fine-tuning our model. Using NODE for fine tuning provides more stability during training and validation.These continuous depth blocks can also have a trade off between numerical precision and speed .Using Neural ODEs for transfer learning has resulted in much stable convergence of the loss function.